

ECG--它是心电图的缩写,是一种记录心跳的电图。心电图测试是检测心脏问题和监测心脏健康最常用的测试之一:仅在美国,每年就有超过1亿次的检查。
产生的图形是由放置在病人皮肤上的电极记录的电压的时间序列。电极检测到心肌 去极化活动的轻微变化,然后在每个心动周期中进行复极化 。信号模式的变化与各种心脏异常、通过心脏的血流不足或电解质失衡相对应。图1显示了心电图读数样本的各个导联。
在这篇博文中,我想给大家介绍一个KNIME工作流程的例子,它使用深度学习对正常和异常信号进行心电图分类。这些信号来自Physionet的心电图数据库,该数据库由Physikalisch-Technische Bundesanstalt(PTB)提供。该数据集的预处理版本可在Kaggle上找到。在我这里的例子中,我使用了 "ptbdb_abnormal.csv "和 "ptbdb_normal.csv "文件。
图1 一位年轻的气短患者的[心电图读数]
心电图信号的预处理
在我们进一步深入分析之前,我将谈谈作者Mohammad Kachuee、Shayan Fazeli和Majid Sarrafzadeh为提供完整的综合CSV文件所使用的预处理技术。他们应用了一种有效的方法对信号进行预处理并从中提取节拍。
首先,心电图信号被分割成10秒的窗口,其振幅值在0和1之间进行归一化处理 。然后识别R峰,并为每个窗口提取R-R时间间隔的中位数(T )。R峰本质上是心电图信号的最高峰。它使用小波变换进行识别,是QRS复合物的一部分,是一种分别对应于心室和心房收缩和扩张的振荡(图2)。
对于每个R峰,选择一个长度为1.2T 的信号,并用零填充,以产生一个固定长度的完整信号。图3中显示了样本数据。
有两个由作者提供的PTB心电图数据集的文件。一个包含类变量1的异常读数,被命名为 "ptbdb_abnormal.csv",另一个包含类变量0的正常读数,被命名为 "ptbdb_normal.csv"。每个文件有188列;最后一列是类别变量,其余的代表信号长度,用零填充固定长度。每一列中都没有缺失的值。然而,数据集总的来说是不平衡的,其中异常读数为10,506,正常读数为4,046。
探索性数据分析
两个数据集都被串联起来,洗成一个表。KNIME在其KNIME统计节点扩展中提供了一个 "统计 "节点。这个节点用来描述每一列及其各自的特征.如图 4 所示, 可以确认表中没有缺失值.每一行的直方图显示了各自列中的数值分布。在图的下半部分也可以看到类的不平衡。
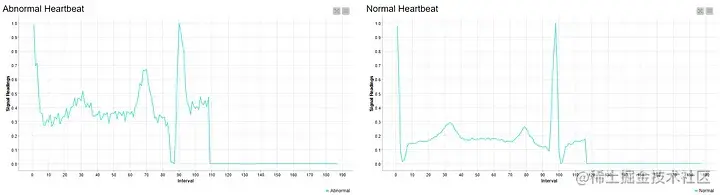
从每个类中取样的两个节拍也被可视化为线图,一个是正常信号,另一个是异常信号。与正常节拍相比,异常读数的峰值很短,而且波动很大,而正常节拍则相对稳定和平稳。(图5)
 建模
建模
正如该数据集的作者在研究论文 中所描述的,一个一维卷积神经网络(CNN)架构被训练来对心电图节拍进行分类。提出的原始架构相当深,在8GB的NVIDIA GPU上花了近两个小时来训练。在这个例子中,我使用了拟议架构的一个小子集,在输入和输出层之间有三个隐藏堆栈。该神经网络是使用KNIME深度学习--Keras集成创建的。
深度神经网络
输入层的大小为(1,187),代表187列和一维序列,即作为输入的时间序列和对应于每个类别的两个单元的输出。
隐性堆栈1
如图6所示,在输入层之后,第一个堆栈中加入了三个隐藏层。第一层是Keras Conv1D层,使用RELU作为其激活函数,64个滤波器,核大小为6,步长为1,填充设置为 "相同"。接下来是一个Keras Batch Normalization Layer节点,以加快训练过程,然后是Keras Max Pooling Layer,池大小为3,步长为2。
隐性堆栈2
如图7所示,在图6的第一个隐藏堆栈之后,第二个堆栈中加入了三个隐藏层。第一层是Keras Conv1D层,使用RELU作为其激活函数,64个滤波器,内核大小为3,步长为1,填充设置为 "相同"。接下来是一个Keras Batch Normalization Layer节点,然后是Keras Max Pooling Layer,池大小为3,步长为2。
隐蔽堆栈3
对于第三个也是最后一个隐藏堆栈(图8),没有再添加1D卷积层。取而代之的是一个扁平化的层,接着是一个64个单元的密集层,然后是输出层之前的32个单元的密集层。
模型训练
在我描述训练过程之前,要知道KNIME中的数据是经过轻微预处理的。这包括通过对少数群体的超额采样来调整类的不平衡。之后,阶级变量为模型的一个热编码,数据被划分为80%用于训练,20%用于测试。
Keras网络学习者节点被用来训练模型。由于我们有一个二元分类问题,所以使用的损失度量是 "二元交叉熵"。如图9所示,该模型用Adam优化器的相关参数共训练了10个epochs。整个训练过程耗时1分22秒。
模型打分
预测是使用Keras执行器节点进行的。使用 "多对一 "节点挑选出与每个类别有关的最大概率的预测。最后使用 "评分器 "节点对模型性能进行评估。如图10所示,该模型的准确率为94.7%,有3,979行被正确识别,224行被错误识别。
用KNIME进行心电图分类
心电图分类是使用由一维卷积层组成的深度神经网络,以及批量归一化层和最大池化层进行的。所提供的数据是从Kaggle挑选的,并且作者已经进行了预处理,所以在这方面不需要做太多的工作。完整的工作流程可以在KNIME社区中心的公共数字健康空间中找到。KNIME Hub上包含PTB分类的工作流程组是"ECG PTB和MIT-BIH数据分析与建模 "。 图11显示了使用PTB数据集进行心电图分类的主要工作流程。
