

hi,我是蛋挞,一个初出茅庐的后端开发,希望可以和大家共同努力、共同进步!
开启掘金成长之旅!这是我参与「掘金日新计划 · 4 月更文挑战」的第 11 天,点击查看活动详情
- 起始标记->生产环境中的集群运维(10讲):「65 | 生产环境常用配置与上线清单」
- 结尾标记->生产环境中的集群运维(10讲):「67 | 诊断集群的潜在问题」
生产环境常用配置与上线清单
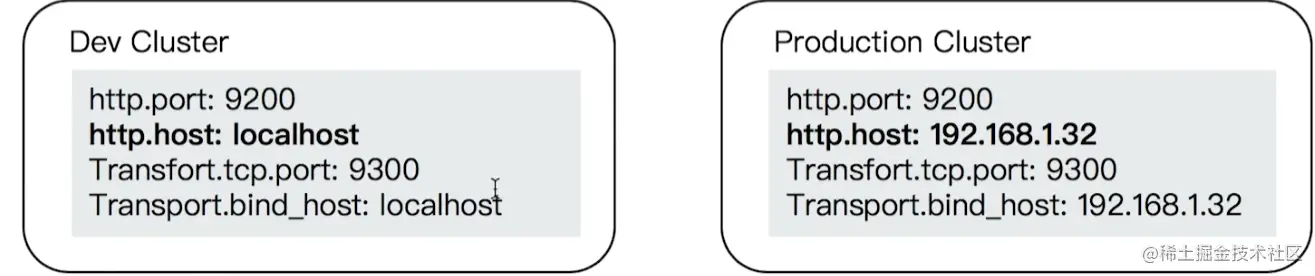 Development vs.Production Mode
Development vs.Production Mode
- 从 ES 5 开始,支持 Development 和 Production 两种运行模式
- 开发模式
- 生产模式
Bootstrap Checks
- 一个集群在 Production Mode 时,启动时必须通过所有 Bootstrap 检测,否则会启动失败
- Bootstrap Checks 可以分为两类: JVM& Linux Checks。Linux Checks 只针对 Linux 系统
JVM 设定
- 从ES6开始,只支持64 位的JVM
- 配置 config /jvm.options
- 避免修改默认配置
- 将内存Xms 和Xmx 设置成一样,避免 heap resize 时引发停顿0
- Xmx 设置不要超过物理内存的 50%;单个节点上,最大内存建议不要超过 32G内存
- 生产环境,JVM 必须使用 Server 模式
- 关闭JVM Swapping
集群的API设定
- 静态设置和动态设定
- 静态配置文件尽量简洁: 按照文档设置所有相关系统参数。 elasticsearch.yml 配置文件中尽量只写必备参数
- 其他的设置项可以通过 AP动态进行设定动态设定分 transient 和 persistent 两种,都会覆盖 elasticsearch.yaml 中的设置
- Transient 在集群重启后会丢失
- Persistent 在集群中重启后不会丢失
系统设置
- 参照文档“Setup Elasticsearch > Important System Configuration"
- Disable Swapping ,Increase file descriptor,虚拟内存,number of thread
最佳实践:网络
- 单个集群不要跨数据中心进行部署 (不要使用WAN)
- 节点之间的 hops 越少越好
- 如果有多块网卡,最好将 transport 和 http 绑定到不同的网卡,并设置不同的防火墙 Rules
- 按需为 Coordinating Node 或 ingest Node 配置负载均衡
最佳实践:内存设定计算实例
- 内存大小要根据 Node 需要存储的数据来进行估算
- 搜索类的比例建议: 1:160
- 日志类: 1:48 -1:96 之间
- 总数据量1T,设置一个副本 = 2T 总数据量
- 如果搜索类的项目,每个节点 31*16 = 496 G,加上预留空间。所以每个节点最多 400 G 数据,至少需要5个数据节点
- 如果是日志类项目,每个节点 31*50 = 1550 GB,2个数据节点 即可
最佳实践:存储
- 推荐使用 SSD,使用本地存储 (Local Disk)。避免使用 SAN NFS /AWS /AZure filesystem
- 可以在本地指定多个“path.data”,以支持使用多块磁盘
- ES本身提供了很好的 HA 机制;无需使用 RAID 1/5/10
- 可以在 Warm 节点上使用 Spinning Disk,但是需要关闭 Concurrent Merges
- Index.merge.scheduler.max thread count: 1
- Trim 你的 SSD
最佳实践:服务器硬件
- 建议使用中等配置的机器,不建议使用过于强劲的硬件配置
- Medium machine over large machine
- 不建议在一台服务器上运行多个节点
集群设置: Throttles 限流
- 避免过多任务对集群产生性能影响为 Relocation 和 Recovery 设置限流,
- Recovery
- Cluster.routing.allocation.node_concurrent_recoveries: 2
- Relocation
- Cluster.routing.allocation.cluster_concurrent_rebalance: 2
集群设置:关闭 Dynamic Indexes
- 可以考虑关闭动态索引创建的功能
- 或者通过模版设置白名单
本节知识总结
学习了在生产环境当中如何对Elasticsearch集群进行一些设定,也学习了在ES 5.0以后Production Mode情况下ES会对ES系统和JVM一些必要的检测,如果没有遵循ES的推荐检测就会失败,集群也不能正常的启动,也分享了一些关于网络和存储的最佳实践,也建议对生产环境需要进行一些必要的限定,比如说进行Dynamic Indexes这样的功能,这样才可以确保用户在使用ES集群的时候对数据进行很好的建模。
监控Elasticsearch集群
Elasticsearch Stats 相关的 AP
- Elasticsearch 提供了多个监控相关的 AP
- Node Stats: _nodes/stats
- Cluster Stats:_cluster/stats
- Index Stats: indexname/_stats
Elasticsearch Task AP
- 查看 Task 相关的AP
- Pending Cluster Tasks API: GET _cluster/pending_tasks
- Task Management API :GET tasks (可以用来 Cancel 一个 Task)
- 监控 Thread Pools
- GET nodes/thread_pool
- GET_nodes/stats/thread_pool
- GET_cat/thread_pool?v
- nodes/hot threads
The Index & Query Slow Log
- 支持将分片上,Search 和 Fetch 阶段的慢查询写入文件
- 支持为 Query 和 Fetch 分别定义闽值
- 索引级的动态设置,可以按需设置,或者通过Index Template 统一设定
- Slog log 文件通过 log4j2.properties 配置
如何创建监控 Dashboard
- 开发 Elasticsearch plugin,通过读取相关的监控 API,将数据发送到 ES,或者 TSDB
- 使用Metricbeats 搜集相关指标
- 使用 Kibana 或Graffna 创建 Dashboard
- 可以开发 Elasticsearch Exporter,通过 Prometheus 监控 Elasticsearch 集群
CodeDemo
# Node Stats:
GET _nodes/stats
#Cluster Stats:
GET _cluster/stats
#Index Stats:
GET kibana_sample_data_ecommerce/_stats
#Pending Cluster Tasks API:
GET _cluster/pending_tasks
# 查看所有的 tasks,也支持 cancel task
GET _tasks
GET _nodes/thread_pool
GET _nodes/stats/thread_pool
GET _cat/thread_pool?v
GET _nodes/hot_threads
GET _nodes/stats/thread_pool
# 设置 Index Slowlogs
# the first 1000 characters of the doc's source will be logged
PUT my_index/_settings
{
"index.indexing.slowlog":{
"threshold.index":{
"warn":"10s",
"info": "4s",
"debug":"2s",
"trace":"0s"
},
"level":"trace",
"source":1000
}
}
# 设置查询
DELETE my_index
//"0" logs all queries
PUT my_index/
{
"settings": {
"index.search.slowlog.threshold": {
"query.warn": "10s",
"query.info": "3s",
"query.debug": "2s",
"query.trace": "0s",
"fetch.warn": "1s",
"fetch.info": "600ms",
"fetch.debug": "400ms",
"fetch.trace": "0s"
}
}
}
GET my_index
本节知识总结
介绍了Elasticsearch一些基本的的monitor的API,我们可以基于这些monitor的API构建一些功能丰富的Dashboard。
诊断集群的潜在问题
集群运维所面临的挑战
- 用户集群数量多,业务场景差异大
- 使用与配置不当,优化不够
- 如何让用户更加高效和正确的使用ES0
- 如何让用户更全面的了解自己的集群的使用状况0
- 发现问题滞后,需要防患于未然
- 需要“有迹可循”,做到“有则改之,无则加勉
- Elastic 有提供 Support Diagnostics Tool - github.com/elastic/sup…
集群绿色,是否意味着足够好
- 绿色只是其中一项指标。显示分片是否都已正常分配
- 监控指标多并且分散
- 指标的含义不够明确直观
- 问题分析定位的门槛较高
- 需要具备专业知识
为什么要诊断集群的潜在问题
- 防患于未然,避免集群奔溃
- Master 节点/数据节点当机一负载过高,导致节点失联
- 副本丢失,导致数据可靠性受损
- 集群压力过大,数据写入失败
- 提升集群性能
- 数据节点负载不均衡 (避免单节点瓶颈) / 优化分片,segmento
- 规范操作方式(利用别名 /避免 Dynamic Mapping 引发过多字段,对索引的合理性进行管控)
eBay Diagnostic Tool
- 集群健康状态,是否有节点丢失
- 索引合理性
- 索引总数不能过大/副本分片尽量不要设置为 0/主分片尺寸检测/索引的字段总数 (Dyamic Mapping 关闭)/索引是否分配不均衡 /索引 segment 大小诊断分析
- 资源使用合理性
- CPU内存和磁盘的使用状况分析/是否存在节点负载不平衡是否需要增加节点
- 业务操作合理性
- 集群状态变更频率,是否在业务高峰期有频繁操作
- 慢查询监控与分析
集群中索引的诊断
- 索引的总数是否过大
- 是否存在字段过多的情况
- 索引的分片个数是否设置合理
- 单个节点的分片数是否过多
- 数据节点之间的负载偏差是否过大
- 冷热数据分配是否正确 (例如,Cold 节点上的索引是否设置成只读)
阿里云-EYOU 智能运维工具
每天凌晨定时诊断,也可以自主诊断。每次诊断耗时 3 分钟 - help.aliyun.com/document detail/90391.htm
诊断 Shard 数
磁盘容量估算
多维度检测,构建自己的诊断工具
相关阅读
- elasticsearch.cn/slides/162
- yq.aliyun.com/articles/65…
- yq.aliyun.com/articles/65…
- help.aliyun.com/document_de…
本节知识总结
介绍了对ES集群进行诊断的潜在问题的重要性,可以结合最后的脑图对诊断的归类,结合自身业务对集群的使用状况开发出符合实际需求的诊断工具。
解决集群Yellow与Red的问题
集群健康度
- 分片健康
- 红:至少有一个主分片没有分配
- 黄:至少有一个副本没有分配
- 绿:主副本分片全部正常分配
- 索引健康:最差的分片的状态
- 集群健康:最差的索引的状态
Health 相关的 API
案例1
- 症状:集群变红
- 分析: 通过 Allocation Explain API 发现 创建索引失败,因为无法找到标记了相应 box type 的节点
- 解决: 删除索引,集群变绿。重新创建索引,并且指定正确的 routing box type,索引创建成功集群保持绿色状态
案例2
- 症状:集群变黄
- 分析:通过 Allocation Explain API 发现无法在相同的节点上创建副本
- 解决:将索引的副本数设置为 0,或者通过增加节点解决
分片没有被分配的一些原因
- INDEX CREATE: 创建索引导致。在索引的全部分片分配完成之前,会有短暂的 Red,不一定代表有问题
- CLUSTER_RECOVER: 集群重启阶段,会有这个问题
- INDEX_REOPEN: Open 一个之前 Close 的索引
- DANGLING_INDEX_IMPORTED:一个节点离开集群期间,有索引被删除。这个节点重新返回时,会导致 Dangling 的问题
常见问题与解决方法
- 集群变红,需要检查是否有节点离线。如果有,通常通过重启离线的节点可以解决问题由于配置导致的问题,需要修复相关的配置(例如错误的 box_type,错误的副本数)
- 如果是测试的索引,可以直接删除0
- 因为磁盘空间限制,分片规则 (Shard Filtering)引发的,需要调整规则或者增加节点
- 对于节点返回集群,导致的 dangling 变红,可直接删除 dangling 索引
集群 Red &Yellow 问题的总结
- Red & Yellow 是集群运维中常见的问题
- 除了集群故障,一些创建,增加副本等操作都会导致集群短暂的 Red 和 Yellow,所以监控和报警时需要设置一定的延时
- 通过检查节点数,使用 ES 提供的相关 AP找到真正的原因
- 可以指定 Move 或者 Reallocate 分片
CodeDemo
#案例1
DELETE mytest
PUT mytest
{
"settings":{
"number_of_shards":3,
"number_of_replicas":0,
"index.routing.allocation.require.box_type":"hott"
}
}
# 检查集群状态,查看是否有节点丢失,有多少分片无法分配
GET /_cluster/health/
# 查看索引级别,找到红色的索引
GET /_cluster/health?level=indices
#查看索引的分片
GET _cluster/health?level=shards
# Explain 变红的原因
GET /_cluster/allocation/explain
GET /_cat/shards/mytest
GET _cat/nodeattrs
DELETE mytest
GET /_cluster/health/
PUT mytest
{
"settings":{
"number_of_shards":3,
"number_of_replicas":0,
"index.routing.allocation.require.box_type":"hot"
}
}
GET /_cluster/health/
#案例2, Explain 看 hot 上的 explain
DELETE mytest
PUT mytest
{
"settings":{
"number_of_shards":2,
"number_of_replicas":1,
"index.routing.allocation.require.box_type":"hot"
}
}
GET _cluster/health
GET _cat/shards/mytest
GET /_cluster/allocation/explain
PUT mytest/_settings
{
"number_of_replicas": 0
}
本节知识小节
分享了一些Elasticsearch集群变黄或变红的原因,根据一些实例帮助我们分析原因以及如何解决这样的问题。
提升集群写性能
提高写入性能的方法
- 写性能优化的目标: 增大写吞吐量 (Events Per Second)越高越好
- 客户端:多线程,批量写
- 可以通过性能测试,确定最佳文档数量
- 多线程: 需要观察是否有 HTTP 429 返回,实现 Retry 以及线程数量的自动调节
- 服务器端:单个性能问题,往往是多个因素造成的。需要先分解问题,在单个节点上进行调整并且结合测试,尽可能压榨硬件资源,以达到最高吞吐量
- 使用更好的硬件。观察 CPU / IO Block
- 线程切换 / 堆栈状况
服务器端优化写入性能的一些手段
- 降低IO 操作
- 使用 ES 自动生成的文档ld/一些相关的 ES 配置,如 Refresh Interval
- 降低CPU和存储开销
- 减少不必要分分词 /避免不需要的 doc values /文档的字段尽量保证相同的顺序,可以提高文档的压缩率
- 尽可能做到写入和分片的均衡负载,实现水平扩展
- Shard Filtering / Write Load Balancer
- 调整 Bulk 线程池和队列
优化写入性能
- ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性质,写入速度,一般不要盲目修改
- 一切优化,都要基于高质量的数据建模
关闭无关的功能
- 只需要聚合不需要搜索, index 设置成 false
- 不需要算分,Norms 设置成 false
- 不要对字符串使用默认的 dynamic mapping。字段数量过多,会对性能产生比较大的影响
- Index_options 控制在创建倒排索引时,哪些内容会被添加到倒排索引中。优化这些设置,一定程度可以节约 CPU
- 关闭_source,减少10 操作;(适合指标型数据)
针对性能的取舍
- 如果需要追求极致的写入速度,可以牺牲数据可靠性及搜索实时性以换取性能
- 牺牲可靠性: 将副本分片设置为 0,写入完毕再调整回去
- 牺牲搜索实时性:增加 Refresh interval 的时间
- 牺牲可靠性:修改 Translog 的配置
数据写入的过程
- Refresh
- 将文档先保存在Index buffer 中,以 refresh _interval 为间隔时间,定期清空 buffer,生成 segment,借助文件系统缓存的特性,先将 segment 放在文件系统缓存中,并开放查询,以提升搜索的实时性
- Translog
- Segment 没有写入磁盘,即便发生了当机,重启后,数据也能恢复,默认配置是每次请求都会落盘
- Flush
- 删除日的 translog 文件
- 生成 Segment 并写入磁盘 /更新 commit point 并写入磁盘。** ES 自动完成,可优化点不多**
Refresh Interva
- 降低Refresh 的频率
- 增加 refresh interval 的数值。默认为s ,如果设置成-1,会禁止自动 refresh
- 避免过于频繁的 refresh,而生成过多的 segment 文件
- 但是会降低搜索的实时性
- 增大静态配置参数 indices.memory.index buffer size
- 默认是 10%,会导致自动触发 refresh
- 增加 refresh interval 的数值。默认为s ,如果设置成-1,会禁止自动 refresh
Translog
- 降低写磁盘的频率,但是会降低容灾能力
- Index.translog.durability: 默认是 request,每个请求都落盘。设置成 async,异步写入
- Index.translog.sync interval 设置为 60s,每分钟执行一次
- Index.translog.flush_threshod size: 默认 512 mb,可以适当调大。当translog 超过该值,会触发 flush
分片设定
- 副本在写入时设为 0,完成后再增加
- 合理设置主分片数,确保均匀分配在所有数据节点上
- Indexrouting.allocation.total_share_per_node: 限定每个索引在每个节点上可分配的主分片数
- 5 个节点的集群。 索引有 5 个主分片,1个副本,应该如何设置?
- (5+5) /5=2
- 生产环境中要适当调大这个数字,避免有节点下线时,分片无法正常迁移
Bulk,线程池和队列大小
- 客户端
- 单个 bulk 请求体的数据量不要太大,官方建议大约5-15mb
- 写入端的 bulk 请求超时需要足够长,建议60s 以上
- 写入端尽量将数据轮询打到不同节点
- 服务器端
- 索引创建属于计算密集型任务,应该使用固定大小的线程池来配置。来不及处理的放入队列,线程数应该o配置成CPU 核心数+1,避免过多的上下文切换
- 队列大小可以适当增加,不要过大,否则占用的内存会成为 GC 的负担
一个索引设定的例子
CodeDemo
DELETE myindex
PUT myindex
{
"settings": {
"index": {
"refresh_interval": "30s",
"number_of_shards": "2"
},
"routing": {
"allocation": {
"total_shards_per_node": "3"
}
},
"translog": {
"sync_interval": "30s",
"durability": "async"
},
"number_of_replicas": 0
},
"mappings": {
"dynamic": false,
"properties": {}
}
}
相关阅读
本节知识小节
分享了一些Elasticsearch文档性能优化,一切性能的优化都建立于良好的数据建模的基础上,同时也可以通过新增搜索的实时性等等达到性能的提升。
此文章为4月Day11学习笔记,内容来源于极客时间《Elasticsearch 核心技术与实战》
