

来自大型模型的高质量数据集可以提高小型模型的性能,有可能让它们在未来与大型闭源模型相媲美。
近年来,大型语言模型(LLMs)已经彻底改变了自然语言处理(NLP)领域。尤其是聊天机器人,由于ChatGPT、Bing Chat和Bard等强大的LLMs的发展,已经取得了巨大的进步。然而,这些模型往往需要巨大的计算资源和专有的数据集,引起了人们对可及性和控制的担忧。另一方面,像LLaMA这样的开源模型提供了一个更容易获得和透明的选择,但它们的能力往往是有限的。
在这篇博文中,我们将讨论伯克利大学的考拉,一个使用Meta的LaMA对来自网络的对话数据进行微调的研究原型聊天机器人。我们详细介绍了我们模型的数据集策划和训练过程,并介绍了Koala与ChatGPT和斯坦福大学的Alpaca进行比较的用户研究结果。结果显示,Koala能够有效地回应一系列的用户查询,产生的回应往往比Alpaca更受欢迎,在某些情况下,与ChatGPT并列。
3个模型在训练数据集、使用的代码、权重、微调和评估方法方面的比较。
数据集:专注于小型的高质量数据集
建立对话模型的一个重要挑战是策划训练数据。像ChatGPT这样流行的聊天模型依赖于专有的数据集,其注释成本很高。为了建立Koala,我们收集了来自网络和公共数据集的对话数据,包括与ChatGPT等其他大型语言模型的对话。
我们并没有收集尽可能多的网络数据(报废),而是把重点放在收集一个小型的高质量数据集上。公共数据集被用于问题回答、人类反馈以及与现有语言模型的对话。数据集包括
- 公共ChatGPT数据
- ShareGPT - 公共用户与ChatGPT的共享对话(30k)
- 人类ChatGPT比较语料库-HC3(87k)。 - 开放源码数据:
- 开放指令通则-OIG(30k)
- 斯坦福大学羊驼(52k)
- 人类HH(160k)
- OpenAI WebGPT(20k)
- OpenAI总结(93k)。
微调
Koala是在EasyLM中使用JAX/Flax实现的,EasyLM是一个开源框架,简化了大型语言模型的预训练、微调、服务和评估。EasyLLM能够将LLM训练扩展到数百个TPU/GPU加速器上,这使得模型权重和训练数据可以在多个加速器上分片。
在一台有8个A100 GPU的Nvidia DGX服务器上,Koala模型的训练需要6个小时来完成2个epochs。在公共云计算平台上使用可抢占的实例,这样的训练运行成本低于100美元。
初步评估
在实验中,对Koala-Distill(仅用公共ChatGPT数据训练)和Koala-All(用公共ChatGPT数据和开源数据训练)这两个模型进行了评估,以比较它们的性能以及提炼和开源数据集对最终结果的影响。
在羊驼测试集和考拉测试集上进行了人类评估,这些测试集由真实的用户查询组成。在Koala测试集上,Koala-All在近一半的情况下表现得比Alpaca好,这表明来自用户在网上发布的LLM交互的数据对类似助手的应用是有效的。此外,研究发现,除了蒸馏数据之外,在开源数据上的训练并没有带来明显的改善。
这表明,只要使用的提示是代表用户会问的问题,助理模型可以 通过使用更大和更强大的模型数据来改进。此外,它支持这样的观点:好的对话模型来自于多样化的、高质量的对话数据,而不仅仅是重新格式化现有的数据。
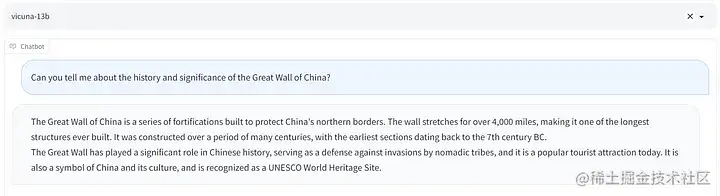
提示语/输出示例
下面是使用考拉与维库纳和阿普拉卡的输出示例。我更喜欢考拉的回答。
 结论
结论
从伯克利大学的这个新模型中,企业有两个重要的收获。
语言模型的民主化,以及小型企业和初创公司有更多机会开发自己的人工智能驱动的聊天机器人。 结果表明,精心采购的数据可以使较小的开源模型接近较大的闭源模型的性能,从而减少对专有数据集或巨大计算资源的依赖。
像ChatGPT和Bard这样的闭源聊天机器人的开源替代品是由Koala提供的。 这使研究人员和企业能够根据他们的具体使用情况修改和改进模型。例如,企业可以根据其行业或使用情况的特定数据集对Koala进行微调,使该模型能够对客户的询问提供更准确和相关的回应。
