

活动安排
每场活动都要求使用同一资源, 且同一时间内只有一个活动能使用资源, 如果活动的活跃区间不相交, 则两个活动是 相容的
问题描述
为 项活动, 分别为活动 的开始时间和结束时间, 求最大的两两相容的活动集
时间复杂度(排序+活动选择):
class Task:
def __init__(self, s, f):
self.id = None
self.s = s
self.f = f
self.active = False
def select(s, f):
n = len(s)
tasks = []
for i in range(n):
tasks.append(Task(s[i], f[i]))
tasks.sort(key=lambda x: x.f)
for id, task in enumerate(tasks):
task.id = id
tasks[0].active = True
count = 1
j = 1
for i in range(1, n):
# 总是选择具有最早结束时间且相容的活动
if tasks[i].s >= tasks[j].f:
tasks[i].active = True
j = i
count += 1
return count, [x.id + 1 for x in sorted(tasks, key=lambda x: x.id) if x.active]
s = [1, 3, 0, 5, 3, 5, 6, 8, 8, 2] # 各活动开始时间
f = [4, 5, 6, 7, 8, 9, 10, 11, 12, 13] # 各活动结束时间
# (4, [1, 4, 8, 11])
print(select(s, f))
正确性证明
算法 执行到第 步, 选择 项活动 ( 活动按 升序 ) , 那么最优解 包含
意思是执行到第 k 步那么最优解肯定包含前 k 个活动, 符合贪心思想
当 时, 令 是一个最优解, 设 是 的 第一个 活动, 且令 , 由于 , 因此选择更早结束的活动 时各活动也是相容的, 且 和 活动数相同, 是最优的, 那么 也是最优的, 且含有活动
执行到第 步时, 有最优解 , 令 , 即剩余活动集合, 从中找到容量为 的最优解 , 那么这个解必然包含活动 ( 即第一个活动, 若不包含, 做法同 ) , 也就是说, 第 步时的解为
背包问题
0-1 背包 物品要么装入背包, 要么不装, 使装入的物品价值最大 ( 不能用贪心 )
但有一个特殊情况:
在 0-1 背包问题中, 若各物品依重量递增序排列时, 其价值恰好依递减序排列
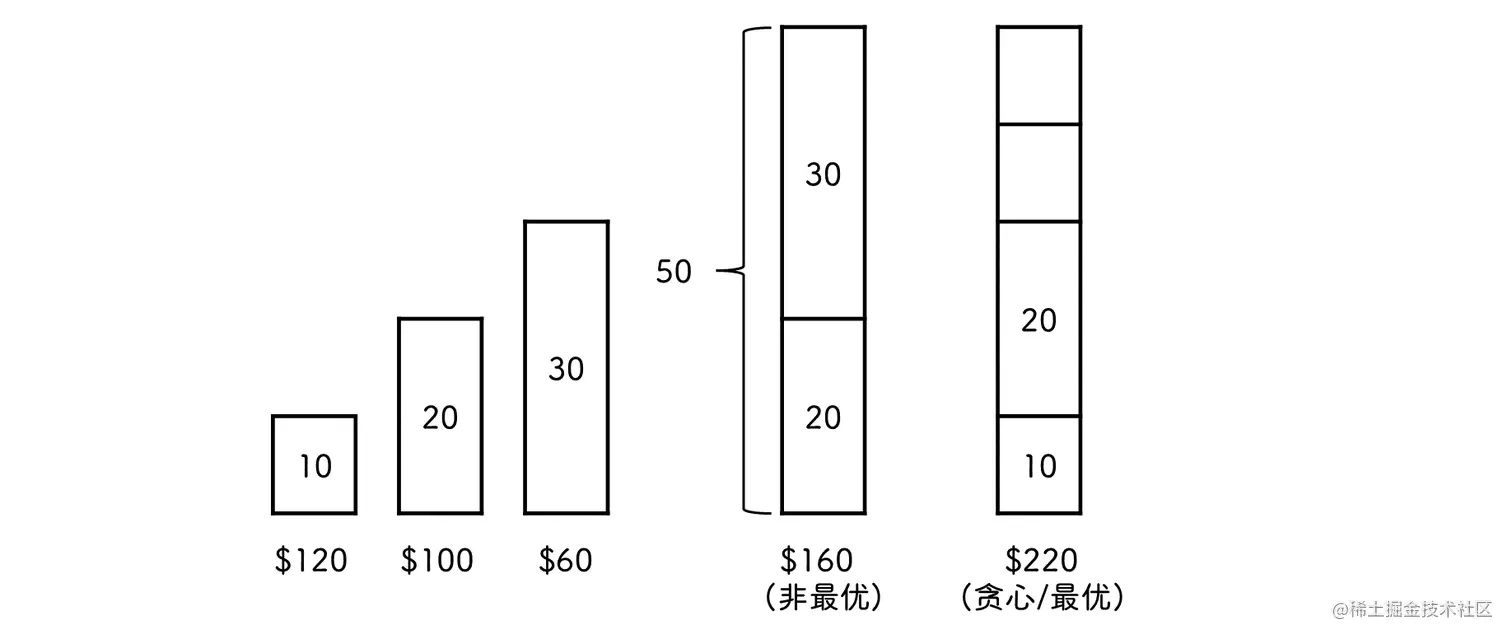
背包问题 物品可以选一部分装入背包(即不要求 100% 装入)
def knapsack(c, weights, v):
w = enumerate(weights)
# 根据单位重量价值降序, 每次选取单位重量价值最大的物品
d = sorted(zip(w, v), key=lambda x: x[1] / x[0][1], reverse=True)
opt = 0
# 记录装入比例
x = [0 for _ in range(len(weights))]
for (i, w), v in d:
if c >= w:
# 能完全装入背包时
opt += v
c -= w
x[i] = 1 # 代表装入 100%
else:
# 物品不能完全装入, 把部分装入填满背包
opt += c * (v / w)
x[i] = c / w
break
return opt, x
weights = [2, 2, 6, 5, 4]
values = [6, 3, 5, 4, 6]
capacity = 10
# (16.666666666666668, [1, 1, 0.3333333333333333, 0, 1])
print(knapsack(capacity, weights, values))
时间复杂度
最优装载
问题描述
一批集装箱要装到限重 的轮船上, 体积不受限制, 要求尽可能多的集装箱装到轮船上
def loading(c, weights):
# 根据重量升序
d = sorted(enumerate(weights), key=lambda x: x[1])
# 记录集装箱装入情况
x = [0 for _ in range(len(weights))]
opt = 0
for i, w in d:
if c >= w:
# 总是选取质量较小的货物
opt += w
c -= w
x[i] = 1
else:
break
return opt, x
weights = [2, 2, 6, 5, 4]
capacity = 10
# (8, [1, 1, 0, 0, 1])
print(loading(capacity, weights))
正确性证明
对装载问题任何规模为 的输入, “轻者优先”贪心法都可以得到最优解
时, 只有一个货箱, 最优解为
问题规模为 时, 集装箱集合为 , 限重 , 令 为规模为 的装载问题, , 假设命题成立, 则可以得到一个最优解 , 原问题为 , 令 , 那么 即为最优解
若存在一个更优解 且包含箱子 (不包含则可以使用箱子 替换 中最轻的箱子), 那么箱子数 , 则为关于 的一个解, , 与 为最优矛盾
哈夫曼编码
前缀码
用 0-1 字符串作为代码表示字符, 要求任何字符的代码都不能作为其它字符代码的前缀
平均位数
最优前缀码
import heapq
class Node:
def __init__(self, weight, id="", left=None, right=None):
self.weight = weight
self.left = left
self.right = right
self.id = id
def __lt__(self, other):
return self.weight < other.weight
def __eq__(self, other):
return self.weight == other.weight
def __str__(self):
return self.id
def huffman(freqs):
nodes = [Node(v, id=k) for k, v in freqs.items()]
heapq.heapify(nodes) # 最小堆
while len(nodes) > 1:
# 获取两个最小编码长度的结点
left = heapq.heappop(nodes)
right = heapq.heappop(nodes)
parent = Node(left.weight + right.weight, left=left, right=right)
# 将合成的新节点重新放入堆中
heapq.heappush(nodes, parent)
return nodes[0]
# 前序遍历
def preorder(root):
if root is None:
return
print(root.weight, root.id)
preorder(root.left)
preorder(root.right)
def main():
freqs = {"a": 45, "b": 13, "c": 12, "d": 16, "e": 9, "f": 5}
# 100
# 45 a
# 55
# 25
# 12 c
# 13 b
# 30
# 14
# 5 f
# 9 e
# 16 d
preorder(huffman(freqs))
if __name__ == "__main__":
main()
引理一
设 是字符集, , 为频率 , , 、 频率最小, 那么存在最优二元前缀码使得 的码字等长, 且仅在最后一位不同
频率相同, 那么就会在树的同一深度, 那么编码长度也是一样的
引理二
设 是二元前缀码所对应的二叉树, , , 是树叶兄弟, 是 , 的父亲, 令 , 且令 的频率 , 是对应于二元前缀码 的二叉树, 那么
正确性证明
哈夫曼算法对 任意 规模为 的字符集 都能得到关于 的最优前缀码的二叉树
时, 字符集 , 编码为 和 , 是最优前缀码
对 规模的字符集 , 且 是频率最小的两个字符, 令
那么假设 时命题成立, 则可得到一棵最优前缀码二叉树
将 的 节点替换成 , 得到的树 即最优前缀码二叉树
假如存在一个更优的 , 即 , 它们都去掉 , 则
这与 是最优的矛盾
单源最短路径
Dijkstra 算法
带权有向图 , 设置一个顶点集合 , 一个顶点属于集合 当且仅当从源到该点得最短路径已知
def dijkstra(graph, start):
n = len(graph)
dist = [float("inf") for _ in range(n)]
visited = [False for _ in range(n)]
path = [-1 for _ in range(n)]
dist[start] = 0
for i in range(n):
min = float("inf")
u = -1
# 从未访问过的顶点中找出一条最短路径
for j in range(n):
if not visited[j] and dist[j] < min:
min = dist[j]
u = j
# 没找到则说明已经到头了
if u == -1:
break
visited[u] = True
# 遍历与 u 邻接的所有顶点, 找到最短路径上 u 的下一个顶点
for v in range(n):
if graph[u][v] != 0 and not visited[v]:
alt = dist[u] + graph[u][v]
# 如果该点离起点的距离大于以 u 作为前驱时离起点的距离, 则更新最小距离
if alt < dist[v]:
dist[v] = alt
path[v] = u
return dist, path
# 邻接矩阵
graph = [
[0, 10, 0, 0, 0, 3],
[0, 0, 7, 5, 0, 0],
[0, 0, 0, 0, 0, 0],
[0, 0, 4, 0, 7, 0],
[0, 0, 0, 0, 0, 0],
[0, 2, 0, 6, 1, 0],
]
start = 0
dist, path = dijkstra(graph, start)
# dist: [0, 5, 12, 9, 4, 3]
print("dist:", dist)
# path: [-1, 5, 1, 5, 5, 0]
print("path:", path)
def get_path(path, end):
res = [end]
p = path[end]
while p != -1:
res.append(p)
p = path[p]
return res
# [2, 1, 5, 0]
print(get_path(path, 2))
正确性证明
说明为什么从 (源点)到 最短路径一定是从 到 且仅经过 中的顶点?
时间复杂度
无法处理负权边
从 出发最短路径 , 标记访问, 继续从 出发最短路径 , 由于 已经被访问, 因此 会被忽略, 然而其才是 的最短路径
最小生成树
无向连通带权图, 具有最小权的生成树
Prim 算法
原理: 每次都访问权最小的边
时间复杂度
def find_min(graph, visit):
min = float("inf")
v1 = v2 = 0 # 最小权对应的点
for i, row in enumerate(graph):
if visit[i]: # 从访问过的点中查找最小权边
for j, col in enumerate(row):
# 点未访问过且权重最小
if not visit[j] and col != 0 and col < min:
min = col
v1 = i
v2 = j
return v1, v2, min
def prim(graph):
n = len(graph) # 节点个数
visit = [False for _ in range(n)] # 记录访问过的点
visit[0] = True
res = [[0 for _ in range(n)] for _ in range(n)]
for i in range(1, n):
v1, v2, weight = find_min(graph, visit)
visit[v2] = True
res[v1][v2] = res[v2][v1] = weight
return res
# 邻接矩阵
graph = [
[0, 6, 1, 5, 0, 0],
[6, 0, 5, 0, 3, 0],
[1, 5, 0, 5, 6, 4],
[5, 0, 5, 0, 0, 2],
[0, 3, 6, 0, 0, 6],
[0, 0, 4, 2, 6, 0],
]
# [0, 0, 1, 0, 0, 0]
# [0, 0, 5, 0, 3, 0]
# [1, 5, 0, 0, 0, 4]
# [0, 0, 0, 0, 0, 2]
# [0, 3, 0, 0, 0, 0]
# [0, 0, 4, 2, 0, 0]
for i in prim(graph):
print(i)
正确性证明
, 存在一棵最小生成树包含 , 其中 的权最小
假设 是一棵最小生成树且不包含 , 那么 必存在一条回路, 回路中与节点 相连的边为 , 那么 也是一棵生成树, 并且 , 是一棵最小的生成树
当执行到第 步时, 最小生成树 的边 , 这些边的端点组成集合 , 中包含最小生成树的全部边
当执行到第 步时, 选择了点 , 到已访问点集 的权最小, 对应边 , 假设最小生成树不包含 , 那么将 加入 中并删除 , 那么 是一棵最小生成树的边集
也就是说最小生成树的边集一定包含前 个权最小边, 符合贪心原则
Kruskal 算法
原理: 将节点看作独立的连通分支, 边按权重排序, 依次查看, 若边连接的两个节点处于不同的连通分支, 则加入边, 若边连接的两个节点处于同一连通分支, 则跳过
时间复杂度:
当边较多时, 如 , Kruskal 的复杂度为 , 较 prim 差, 当边数较少时, 如 , Kruskal 的复杂度为 , 较 prim 优
class UnionFind:
def __init__(self, n):
self.parent = list(range(n))
self.rank = [1] * n
def find(self, x):
if self.parent[x] != x:
# 将路径上的节点的父节点都改成其祖先(根)
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
px, py = self.find(x), self.find(y)
# 祖先相同, 形成回路
if px == py:
return False
# 秩大的做父节点
if self.rank[px] < self.rank[py]:
px, py = py, px
self.parent[py] = px
self.rank[px] += self.rank[py]
return True
def kruskal(n, edges):
uf = UnionFind(n)
edges.sort(key=lambda x: x[2]) # 边按权重排序
res = [[0 for _ in range(n)] for _ in range(n)]
m = 0 # 已选边数
for u, v, w in edges:
# 树的边数等于点树减一, 此时已经生成一棵树了
if m == n - 1:
break
if uf.union(u, v):
m += 1
res[u][v] = w
res[v][u] = w
return res
# 邻接矩阵
graph = [
[0, 6, 1, 5, 0, 0],
[6, 0, 5, 0, 3, 0],
[1, 5, 0, 5, 6, 4],
[5, 0, 5, 0, 0, 2],
[0, 3, 6, 0, 0, 6],
[0, 0, 4, 2, 6, 0],
]
n = len(graph)
edges = []
for i in range(n):
for j in range(i + 1, n):
if graph[i][j] != 0:
edges.append((i, j, graph[i][j]))
# [0, 0, 1, 0, 0, 0]
# [0, 0, 5, 0, 3, 0]
# [1, 5, 0, 0, 0, 4]
# [0, 0, 0, 0, 0, 2]
# [0, 3, 0, 0, 0, 0]
# [0, 0, 4, 2, 0, 0]
for i in kruskal(n, edges):
print(i)
正确性证明
时, 只有一条边, 命题成立
当 个顶点构成图 时, 存在最小权边 , 将 和 短接, 得到图 , 若命题成立, 那么能得到一棵最小生成树 , 令 , 那么 是 的最小生成树
若不是, 说明存在一棵更小的生成树 使得 , , 与 是最小生成树相互矛盾
调度问题
多机调度
m 台机器, n 个作业, 每个作业处理时间 , 要求在尽可能短的时间内完成全部作业
思路: 最长处理时间优先
def job(m, t):
n = len(t)
if n <= m:
# 机器数多于作业数, 为每个作业分配机器
# 完成时间为最大作业时间
return max(t)
# 处理时间从大到小排序
times = sorted(enumerate(t), key=lambda x: x[1], reverse=True)
consumes = [0 for _ in range(m)] # 记录每个机器的耗时
machines = [[] for _ in range(m)] # 记录机器的分配情况
for i, t in times:
# 找到总时间消耗最小的机器
min_cons = min(consumes)
idx = consumes.index(min_cons)
# 将当前作业分配给该机器
consumes[idx] += t
machines[idx].append(i + 1)
return max(consumes), machines
def main():
times = [2, 14, 4, 16, 6, 5, 3]
job_num = 3
# (17, [[4], [2, 7], [5, 6, 3, 1]])
print(job(job_num, times))
if __name__ == "__main__":
main()
最小延迟调度
给定客户集合 A, , 为服务时间, 为完成时间, , 为正整数, 一个调度是函数 , 为客户 i 的开始时间, 求最大延迟达到最小的调度
意思是即使不能按时结束服务, 也要尽量使这个延迟减小
其中 指最大延迟
如上图所示, 服务 2 的服务时长为 8, 结束时间为 12, 对于调度 1 来说, 晚结束了 1, 对于调度 2 来说, 晚结束了 15
思路: 按完成时间从早到晚安排任务
def schedule(T, D):
n = len(D)
d = sorted(enumerate(D), key=lambda x: x[1]) # 完成时间升序
f = [0 for _ in range(n)] # 记录各任务开始时间
late = [0 for _ in range(n)] # 记录各任务延时
pre = d[0][0] # 第一个任务编号
s = [pre + 1] # 记录第一个任务
# 记录第一个任务延时
late[0] = 0 if T[pre] <= D[pre] else T[pre] - D[pre]
for id, item in d[1:]:
# 计算当前任务开始时间
f[id] = f[pre] + T[pre]
# 当前任务结束时间比预期结束时间多多长时间
dT = f[id] + T[id] - item
# 如果超时则记录超时时间
if dT > 0:
late[id] = dT
# 插入当前作业
s.append(id + 1)
pre = id
return {
"max_late": max(late),
"late": late,
"schedule": s,
"start_time": f,
}
def main():
T = [5, 8, 4, 10, 3]
D = [10, 12, 15, 11, 20]
# {
# "max_late": 12,
# "late": [0, 11, 12, 4, 10],
# "schedule": [1, 4, 2, 3, 5],
# "start_time": [0, 15, 23, 5, 27],
# }
print(schedule(T, D))
if __name__ == "__main__":
main()
引理一
所有没有逆序、没有空闲时间的调度具有相同的最大延迟
逆序指 且 , 即开始的早, 预计结束的又晚
具有相同结束时间 ( 即没有逆序 )的活动必被连续安排, 那么这些活动中最大延迟必是最后一个被安排的活动
因此这些活动的调度(排序)方式不会影响最大延迟, 因此解是等价的
定理一
在一个没有空闲时间的最优解中, 最大延迟是 , 如果仅对具有相邻逆序的客户进行交换, 得到的解的最大延迟不会超过
交换相邻逆序 (i, j) 不影响最优性
交换 对其他客户的延迟时间没影响
由于 ( 逆序性质 ), 根据
因此
不会超过原来的延迟, 因此不断交换两个相邻逆序( 实际上是将结束时间早的活动提前 )不会导致最大延迟增加, 符合贪心原则
贪心与最优解判断条件(不考)
定理一
对每个正整数 , 假设对所有非负整数 有 , 那么
指贪心算法的解, 指动态规划的解
定理二
对每个正整数 , 假设对所有非负整数 有 , 且存在 和 满足 , 其中 , , 为正整数, 则下列命题等价
, , , , ,
对一切 有 , , 验证
取 , , 有
根据 可得
