

hi,我是蛋挞,一个初出茅庐的后端开发,希望可以和大家共同努力、共同进步!
开启掘金成长之旅!这是我参与「掘金日新计划 · 4 月更文挑战」的第 10 天,点击查看活动详情
- 起始标记->水平扩展Elasticsearch(6讲):「62 | 如何对集群进行容量规划」
- 结尾标记->水平扩展Elasticsearch(6讲):「64 | 在公有云上管理与部署Elasticsearch集群」
如何对集群进行容量规划
容量规划
- 一个集群总共需要多少个节点? 一个索引需要设置几个分片?
- 规划上需要保持一定的余量,当负载出现波动,节点出现丢失时,还能正常运行
- 做容量规划时,一些需要考虑的因素
- 机器的软硬件配置
- 单条文档的尺寸/文档的总数据量 /索引的总数据量 (Time base 数据保留的时间)/副本分片数
- 文档是如何写入的(Bulk的尺寸)
- 文档的复杂度,文档是如何进行读取的 (怎么样的查询和聚合)
评估业务的性能需求
- 数据吞吐及性能需求
- 数据写入的吞吐量,每秒要求写入多少数据?
- 查询的吞吐量?
- 单条查询可接受的最大返回时间?
- 了解你的数据
- 数据的格式和数据的Mapping
- 实际的查询和聚合长的是什么样的
常见用例
- 搜索:固定大小的数据集
- 搜索的数据集增长相对比较缓慢
- 日志:基于时间序列的数据
- 使用 ES存放日志与性能指标。数据每天不断写入,增长速度较快
- 结合 Warm Node 做数据的老化处理
硬件配置
- 选择合理的硬件,数据节点尽可能使用 SSD
- 搜索等性能要求高的场景,建议 SSD
- 按照1:10的比例配置内存和硬盘
- 日志类和查询并发低的场景,可以考虑使用机械硬盘存储
- 按照1:50的比例配置内存和硬盘
- 单节点数据建议控制在2TB 以内,最大不建议超过5 TB
- JVM 配置机器内存的一半,JVM 内存配置不建议超过 32G
部署方式
- 按需选择合理的部署方式
- 如果需要考虑可靠性高可用,建议部署 3台dedicated 的 Master 节点
- 如果有复杂的查询和聚合,建议设置 Coordinating 节点
容量规划案例 1:固定大小的数据集
- 一些案例: 唱片信息库产品信息
- 一些特性
- 被搜索的数据集很大,但是增长相对比较慢(不会有大量的写入)。更关心搜索和聚合的读取性能
- 数据的重要性与时间范围无关。关注的是搜索的相关度
- 估算索引的的数据量,然后确定分片的大小
- 单个分片的数据不要超过 20 GB
- 可以通过增加副本分片,提高查询的吞吐量
拆分索引
- 如果业务上有大量的查询是基于一个字段进行 Filter,该字段又是一个数量有限的枚举值
- 例如订单所在的地区
- 如果在单个索引有大量的数据,可以考虑将索引拆分成多个索引
- 查询性能可以得到提高
- 如果要对多个索引进行查询,还是可以在查询中指定多个索引得以实现
- 如果业务上有大量的查询是基于一个字段进行 Filter,该字段数值并不固定
- 可以启用 Routing 功能,按照 filter 字段的值分布到集群中不同的 shard,降低查询时相关的 shard,提高CPU利用率
容量规划案例 2:基于时间序列的数据
- 相关的用案
- 日志 /指标/安全相关的 Events
- 舆情分析
- 一些特性
- 每条数据都有时间戳;文档基本不会被更新(日志和指标数据)
- 用户更多的会查询近期的数据;对旧的数据查询相对较少
- 对数据的写入性能要求比较高
创建基于时间序列的索引
- 创建 time-based 索引
- 在索引的名字中增加时间信息
- 按照每天/每周/每月的方式进行划分
- 带来的好处
- 更加合理的组织索引,例如随着时间推移,便于对索引做的老化处理
- 利用Hot & Warm Architecture
- 备份和删除以及删除的效率高。( Delete By Query 执行速度慢,底层不也不会立刻释放空间,而 Merge 时又很消耗资源)
- 更加合理的组织索引,例如随着时间推移,便于对索引做的老化处理
写入时间序列的数据: 基于 Date Math 的方式
- 容易使用
- 如果时间发生变化,需要重新部署代码
写入时间序列的数据- 基于 lndex Alias
- Time-based 索引
- 创建索引,每天/每周/每月
- 在索引的名字中增加时间信息
集群扩容
- 增加 Coordinating /Ingest Node
- 解决 CPU 和内存开销的问题
- 增加数据节点
- 解决存储的容量的问题
- 为避免分片分布不均的问题,要提前监控磁盘空间,提前清理数据或增加节点 (70%)
CodeDemo
PUT logs_2019-06-27
PUT logs_2019-06-26
POST _aliases
{
"actions": [
{
"add": {
"index": "logs_2019-06-27",
"alias": "logs_write"
}
},
{
"remove": {
"index": "logs_2019-06-26",
"alias": "logs_write"
}
}
]
}
# POST /<logs-{now/d}/_search
POST /%3Clogs-%7Bnow%2Fd%7D%3E/_search
# POST /<logs-{now/w}/_search
POST /%3Clogs-%7Bnow%2Fw%7D%3E/_search
相关阅读
本节知识小结
介绍了一些容量规划相关的知识,建议在做容量规划之前要对业务数据有一个清楚的了解,将搜索类和日志类部署在不同的Elasticsearch节点上,对于数据大量写入的应用,使用ssd,如果需要保存长时间的数据用Hot & Warm Architecture架构。集群上线以后要时刻监控集群的使用状况,及时的做出一些扩容相关的行动。
在私有云上管理Elasticsearch集群的一些方法
管理单个集群
- 集群容量不够时,需手工增加节点
- 有节点丢失时,手工修复或更换节点
- 确保 Rack Awareness
- 集群版本升级;数据备份;滚动升级
- 完全手动,管理成本高
- 无法统一管理,例如整合变更管
ECE,帮助你管理多个 Elasticsearch 集群
- ECE -Elastic Cloud Enterprise
- 通过单个控制台,管理多个集群
- 支持不同方式的集群部署(支持各类部署)跨数据中心/部署 Anti Affinity
- 统一监控所有集群的状态
- 图形化操作
- 增加删除节点
- 升级集群/滚动更新/自动数据备份
基于 Kubernetes 的方案
- 基于容器技术,使用 Operator 模式进行编排管理
- 配置,管理监控多个集群
- 支持 Hot &Warm
- 数据快照和恢复
Kubernetes CRD
构建自己的管理系统
- 基于虚拟机的编排管理方式
- Puppet Infrastructure (Puppet / Elasticsearch Puppet Module / Foreman)0
- Workflow based Provision & Managemento
- 基于Kubernetes 的容器化编排管理方式
- 基于 Operator 模式
- Kubernetes - Customer Resource Definition
将 Elasticsearch 部署在 Kubernetes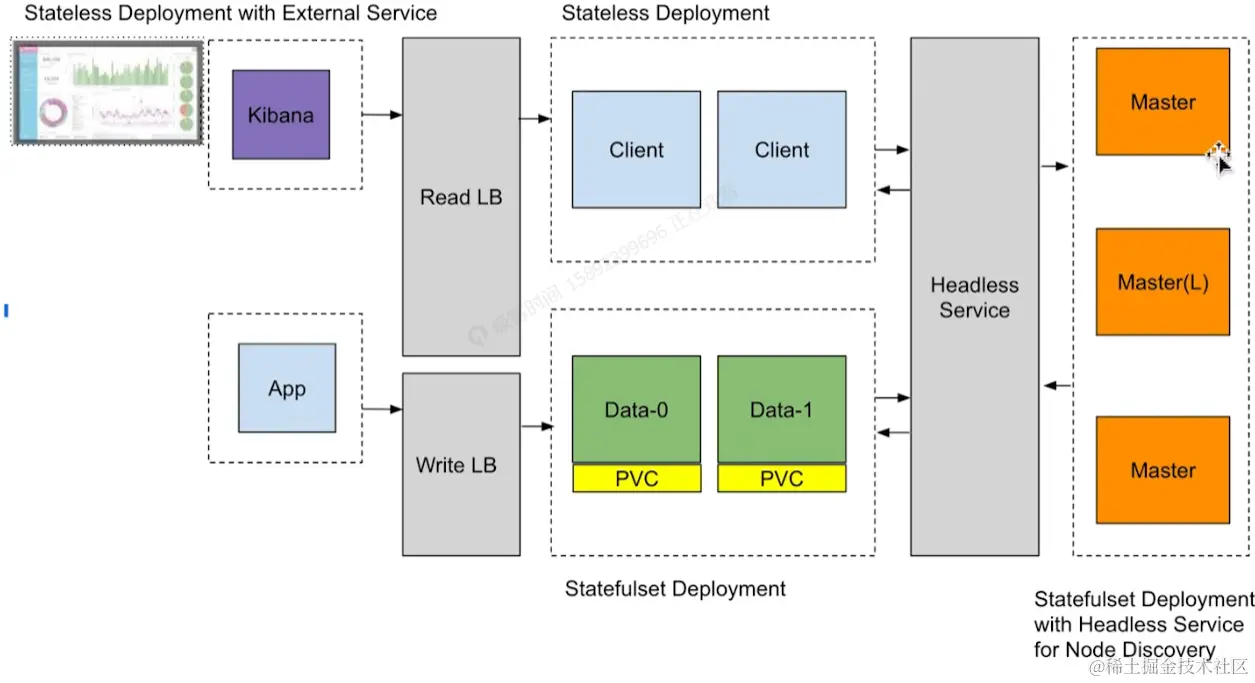
什么是 Kubernetes Operator 模式
Operator SDK
相关阅读
- www.elastic.co/cn/blog/int…
- www.elastic.co/blog/introd…
- github.com/operator-fr…
- github.com/upmc-enterp…
本节知识小结
介绍了如何在云环境去管理一个到多个Elasticsearch集群,以及一些商业和免费的方案。
在公有云上管理与部署Elasticsearch集群
Elastic Cloud
相关阅读
本节知识小结
介绍了如何在公有云上部署Elasticsearch集群,如果客户在海外可以用Elastic自营的。
此文章为4月Day10学习笔记,内容来源于极客时间《Elasticsearch 核心技术与实战》
