Python爬虫实战之酷狗音乐爬取:想下载歌曲,但又要开启“人上人”服务,士可忍孰不可忍!
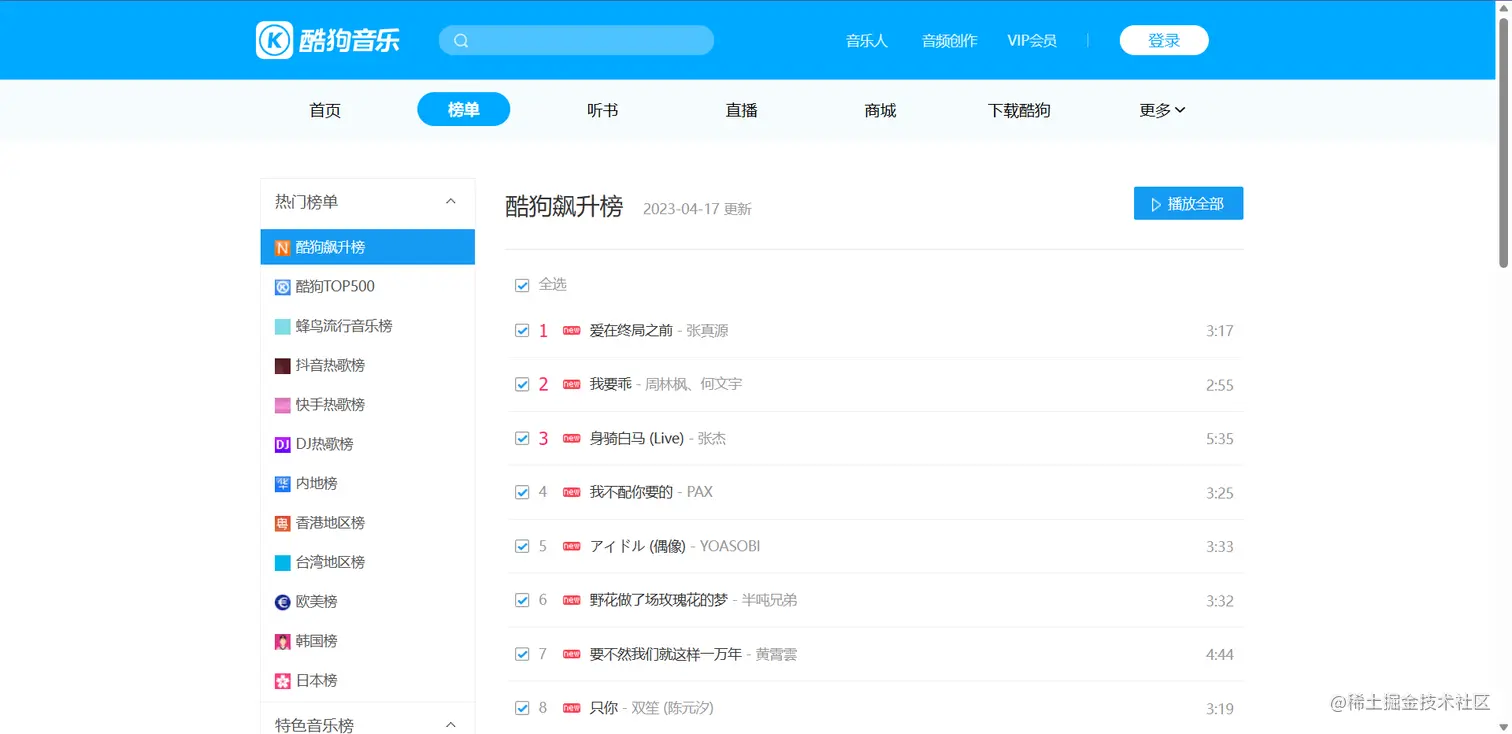
废话不多说直接上代码:
import requests
import re
from pprint import pprint
import os
import time
import tqdm
headers = {
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 14_3 like Mac OS X) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30',
'cookie': 'kg_mid=2d94fc2f6b14d23d5a9d31c5bbbb6d18; kg_dfid=3x87US2eiEz443jt7n29R06x; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e'
}
def request(url):
html_id = requests.get(url, headers=headers)
music_id = re.findall('data-eid="(.*?)">', html_id.text)
name = re.findall('<li class=" " title="(.*?)"', html_id.text)
date = zip(name, music_id)
for name, music_id in date:
html_rexe = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id=' + music_id
html_jiexi = requests.get(url=html_rexe, headers=headers)
album_name = html_jiexi.json()['data']['audio_name']
mice_url = html_jiexi.json()['data']['play_backup_url']
lyrics = html_jiexi.json()['data']['lyrics']
song_info_cleaned = re.sub("\[(.*?)\]","", lyrics)
print(name, mice_url, song_info_cleaned)
save(album_name, mice_url, song_info_cleaned)
def save(album_name, mice_url, song_info_cleaned):
with open(f'酷狗音乐\\{album_name}.mp3', 'wb') as f:
music = requests.get(url=mice_url, headers=headers)
f.write(music.content)
with open(f'酷狗音乐\\{album_name}.txt', 'w+',encoding="utf-8")as a:
a.write(song_info_cleaned)
print(f'{album_name}下载完成')
if __name__ == '__main__':
url = 'https://www.kugou.com/yy/rank/home/1-6666.html?from=rank'
request(url)
'''
酷狗飙升榜: https://www.kugou.com/yy/rank/home/1-6666.html?from=rank
酷狗top500:https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
'''
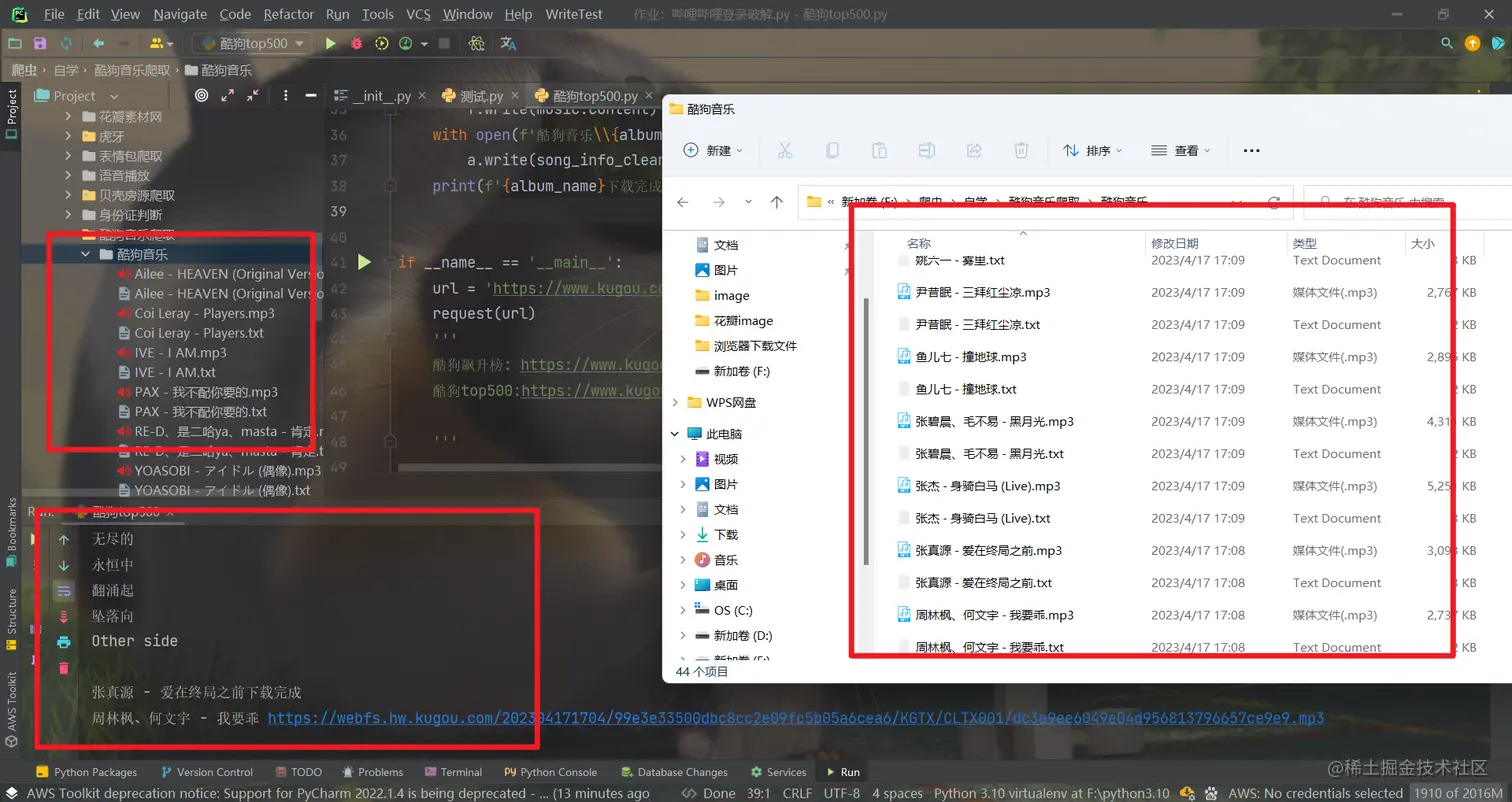
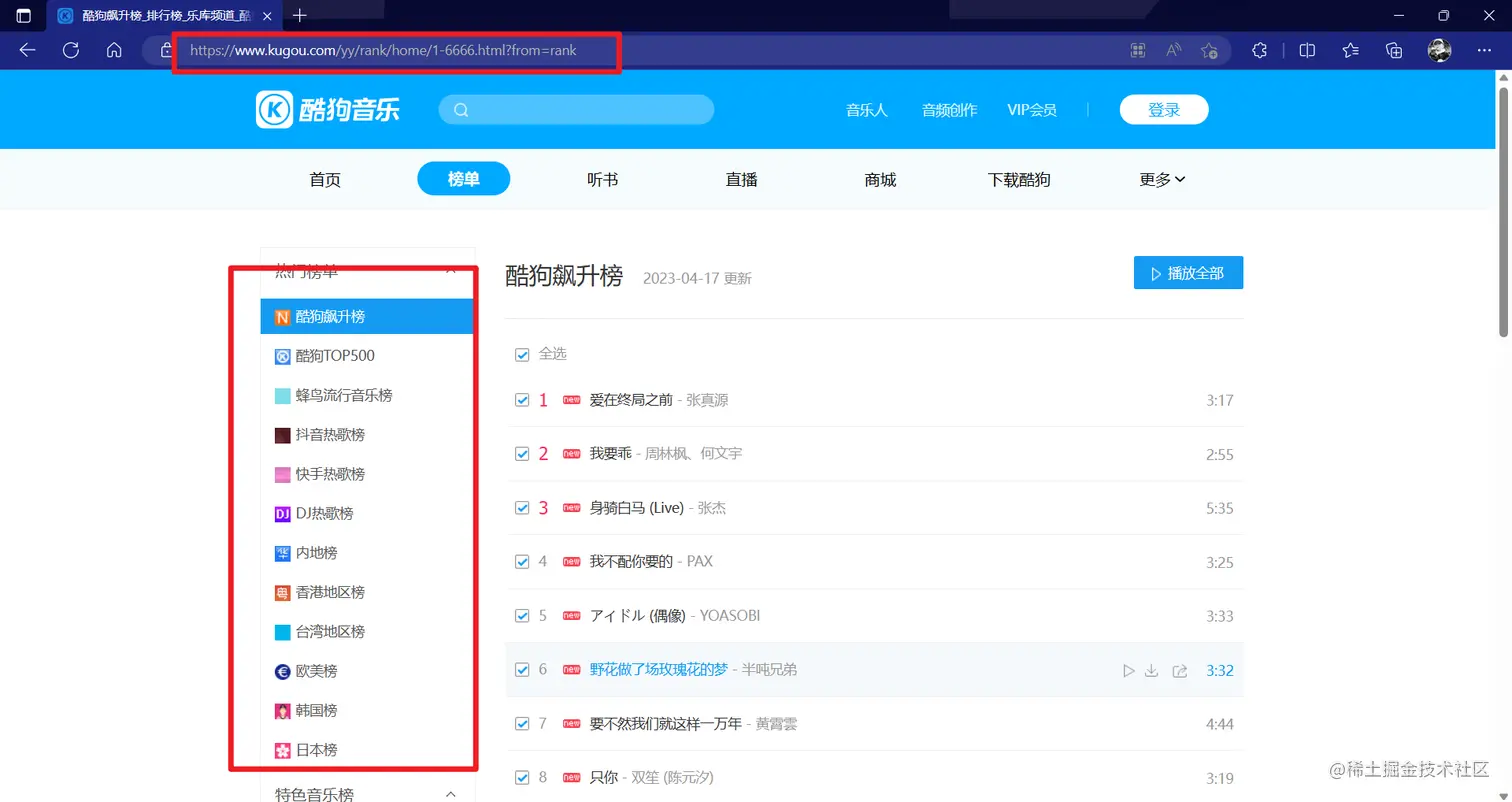
可以替换网址链接来爬取你想要爬取的音乐:
制作不易,点个赞再走吧~


