FM&FFM理解(初版)- FFM部分
FM&FFM理解(初版)- FFM部分
- 同理本文仅作为一个简单介绍,关于推理和代码部分可以见参考资料,较为详细,此文也可仅当作一个目录,完整部分见参考资料呦~
FFM部分:(Field Factorization Machine)
FFM模型与FM模型不同之处:
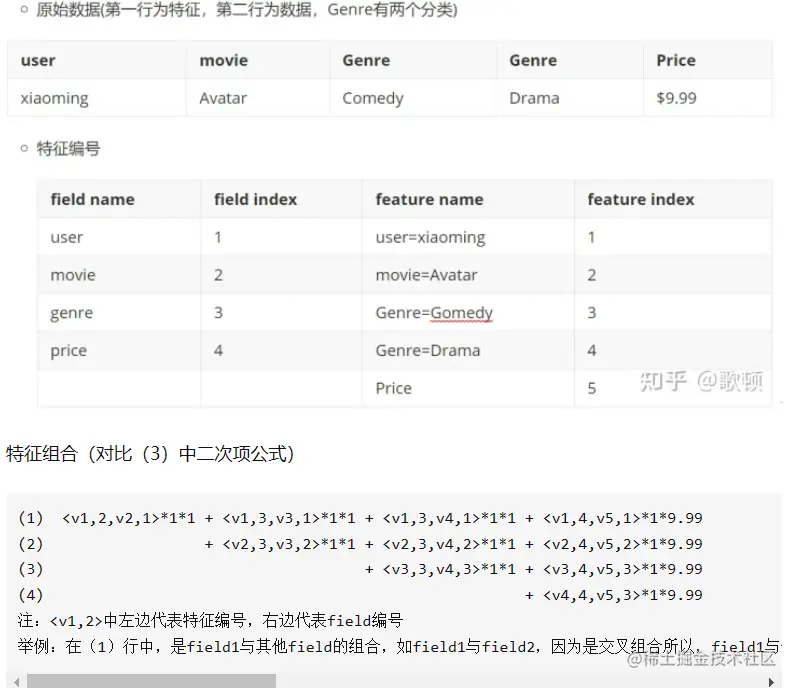
- 1 FFM模型在FM的基础上引入了field概念,即每一个特征又属于哪个field,field和feature是一对多,如下表格展示:

- 2 FM模型亦可以看成FFM模型的一个特例,即所有特诊同属于一个field。FFM与FM的区别在于隐向量由原来的 Vi变成了Vi,fj,这意味着每个特征对应的不是唯一的一个隐向量,而是一组隐向量。当Xi特征与Xj特征进行交叉时,Xi特征会从Xi的一组隐向量种选择出与特征Xj的域fj对应的隐向量Vifj进行交叉。同理,Xj也会选择与Xi的域fi对应的隐向量Vjfi进行交叉
2 FFM模型公式与FM模型公式的区别
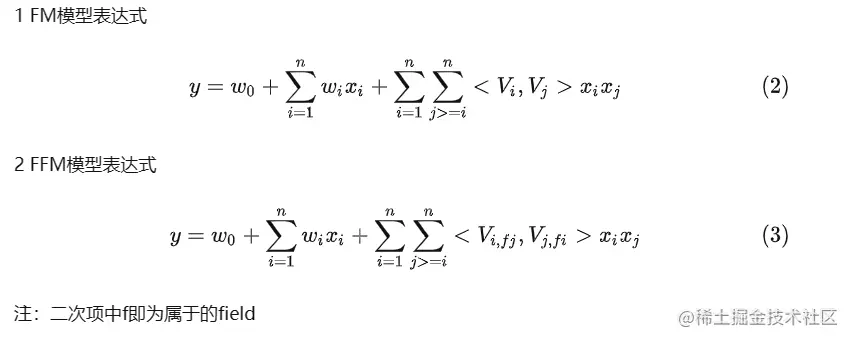
3 FFM模型组合方式实例详解:
4 FFM模型化简问题:
- 由于FFM模型中隐向量与dield相关,那么FFM二次项并不能够化简,所以FFM模型的时间复杂度与FM模型化简前一样为O(kn^2)
5 关于训练FFM时的一些注意事项:
- 第一,样本归一化。FFM默认是进行样本数据的归一化的 。若不进行归一化,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
- 第二,特征归一化。比如在CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到[0,1]是非常必要的。
- 第三,省略零值特征。从FFM模型的表达式(3)可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
6 FFM模型实现代码:(未测试,见参考资料)
参考资料


