

hi,我是蛋挞,一个初出茅庐的后端开发,希望可以和大家共同努力、共同进步!
开启掘金成长之旅!这是我参与「掘金日新计划 · 4 月更文挑战」的第 2 天,点击查看活动详情
- 起始标记->分布式特性及分布式搜索的机制(8讲):「41 | 剖析分布式查询及相关性算分」
- 结尾标记->分布式特性及分布式搜索的机制(8讲):「44 | 处理并发读写操作」
剖析分布式查询及相关性算分
分布式搜索的运行机制
- Elasticsearch 的搜索,会分两阶段进行
- 第一阶段 - Query
- 第二阶段-Fetch
- Query-then-Fetch
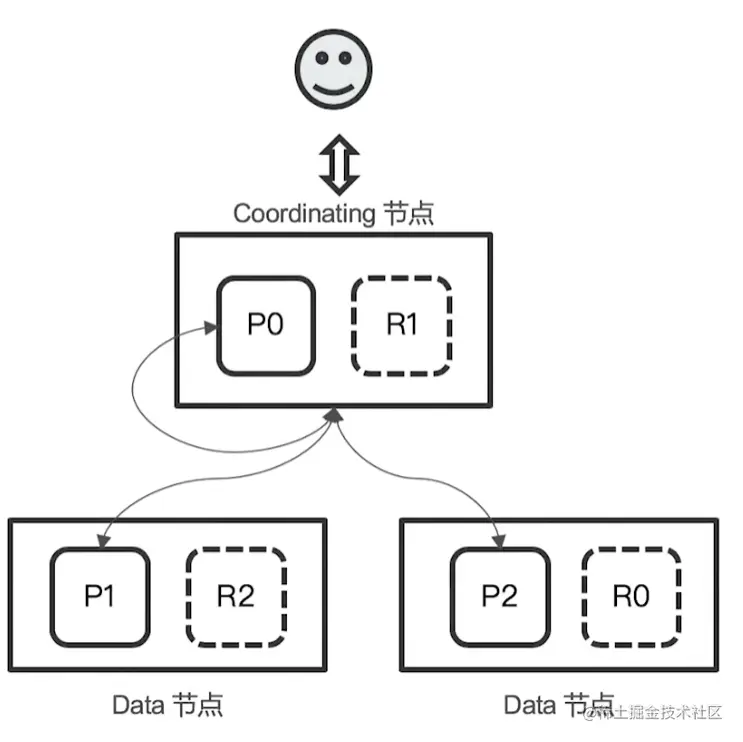
Query阶段
- 用户发出搜索请求到 ES 节点。节点收到请求后,会以 Coordinating 节点的身份,在6个主副分片中随机选择 3 个分片,发送查询请求
- 被选中的分片执行查询,进行排序。然后,每个分片都会返回 From + Size 个排序后的文档ld 和排序值 给 Coordinating 节点
 Fetch阶段
Fetch阶段
- Coordinating Node 会将 Query 阶段,从从每个分片获取的排序后的文档id 列表重新进行排序。选取 From 到 From + Size个文档的ld
- 以multi get 请求的方式,到相应的分片获取详细的文档数据
Query Then Fetch 潜在的问题
- 性能问题
- 每个分片上需要查的文档个数 = from + size
- 最终协调节点需要处理: number_of_shard *( from+size)
- 深度分页
- 相关性算分
- 每个分片都基于自己的分片上的数据进行相关度计算。这会导致打分偏离的情况,特别是数据量很少时。相关性算分在分片之间是相互独立。当文档总数很少的情况下,如果主片大于 1,主分片数越多,相关性算分会越不准
解决算分不准的方法
- 数据量不大的时候,可以将主分片数设置为 1
- 当数据量足够大时候,只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差
- 使用 DFS Query Then Fetch
- 搜索的URL 中指定参数“_search?search_type=dfs_query_then_fetch’
- 到每个分片把各分片的词频和文档频率进行搜集,然后完整的进行一次相关性算分耗费更加多的CPU和内存,执行性能低下,一般不建议使用
CodeDemo
DELETE message PUT message { "settings": { "number_of_shards": 20 } }
GET message
POST message/_doc?routing=1 { "content":"good" }
POST message/_doc?routing=2 { "content":"good morning" }
POST message/_doc?routing=3 { "content":"good morning everyone" }
POST message/_search { "explain": true, "query": { "match_all": {} } }
POST message/_search { "explain": true, "query": { "term": { "content": { "value": "good" } } } }
POST message/_search?search_type=dfs_query_then_fetch {
"query": { "term": { "content": { "value": "good" } } } }
本节知识回顾
介绍了分布式搜索Query Then Fetch的机制,阐述了为什么Query Then Fetch会引起深度分页的性能问题,为什么在数据量很少的时候要把elasticsearch的分页设置成一的原因。
排序及Doc Values&Fielddata
排序
- Elasticsearch 默认采用相关性算分对结果进行降序排序
- 可以通过设定 sorting 参数,自行设定排序
- 如果不指定_score,算分为 Null
排序的过程
- 排序是针对字段原始内容进行的。倒排索引无法发挥作用
- 需要用到正排索引。通过文档 ld 和字段快速得到字段原始内容
- Elasticsearch 有两种实现方法
- Fielddata
- Doc Values(列式存储,对 Text 类型无效)
Dov Values vs Field Data
关闭Dov Values
- 默认启用,可以通过 Mapping 设置关闭
- 增加索引的速度/减少磁盘空间
- 如果重新打开,需要重建索引
- 什么时候需要关闭
- 明确不需要做排序及聚合分析
本节知识回顾
学习了Elasticsearch的排序的功能,Elasticsearch一个字段的排序和多个功能的排序,了解了Doc Values&Fielddata 的优缺点的对比,也了解了Doc Values&Fielddata如何进行设定。
CodeDemo
#单字段排序 POST /kibana_sample_data_ecommerce/_search { "size": 5, "query": { "match_all": {
}}, "sort": [ {"order_date": {"order": "desc"}} ] }
#多字段排序 POST /kibana_sample_data_ecommerce/_search { "size": 5, "query": { "match_all": {
}}, "sort": [ {"order_date": {"order": "desc"}}, {"_doc":{"order": "asc"}}, {"_score":{ "order": "desc"}} ] }
GET kibana_sample_data_ecommerce/_mapping
#对 text 字段进行排序。默认会报错,需打开fielddata POST /kibana_sample_data_ecommerce/_search { "size": 5, "query": { "match_all": {
}}, "sort": [ {"customer_full_name": {"order": "desc"}} ] }
#打开 text的 fielddata PUT kibana_sample_data_ecommerce/_mapping { "properties": { "customer_full_name" : { "type" : "text", "fielddata": true, "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }
#关闭 keyword的 doc values PUT test_keyword PUT test_keyword/_mapping { "properties": { "user_name":{ "type": "keyword", "doc_values":false } } }
DELETE test_keyword
PUT test_text PUT test_text/_mapping { "properties": { "intro":{ "type": "text", "doc_values":true } } }
DELETE test_text
DELETE temp_users PUT temp_users PUT temp_users/_mapping { "properties": { "name":{"type": "text","fielddata": true}, "desc":{"type": "text","fielddata": true} } }
Post temp_users/_doc {"name":"Jack","desc":"Jack is a good boy!","age":10}
#打开fielddata 后,查看 docvalue_fields数据 POST temp_users/_search { "docvalue_fields": [ "name","desc" ] }
#查看整型字段的docvalues POST temp_users/_search { "docvalue_fields": [ "age" ] }
分页与遍历:From, Size, Search After & Scroll API
From / Size
- 默认情况下,查询按照相关度算分排序,返回前10条记录
- 容易理解的分页方案
- From: 开始位置
- Size:期望获取文档的总数
分布式系统中深度分页的问题
- ES 天生就是分布式的。查询信息,但是数据分别保存在多个分片,多台机器上,ES 天生就需要满足排序的需要(按照相关性算分)
- 当一个查询: From =990, Size =10
- 会在每个分片上先都获取 1000 个文档。然后通过 Coordinating Node 聚合所有结果。最后再通过排序选取前 1000个文档
- 页数越深,占用内存越多。为了避免深度分页带来的内存开销。ES有一个设定,默认限定到10000个文档
- ndex.max.result window
Search After 避免深度分页的问题
- 避免深度分页的性能问题,可以实时获取下一页文档信息
- 不支持指定页数(From)
- 只能往下翻
- 第一步搜索需要指定 sort,并且保证值是唯一的(可以通过加入_id 保证唯一性)
- 然后使用上一次,最后一个文档的 sort 值进行查询
Search After 是如何解决深度分页的问题
- 假定 Size 是 10
- 当查询 990-1000
- 通过唯一排序值定位,将每次要处理的文档数都控制在10
Scroll API
- 创建一个快照,有新的数据写入以后,无法被查到
- 每次查询后,输入上一次的 Scroll ld
不同的搜索类型和使用场景
- Regular
- 需要实时获取顶部的部分文档。例如查询最新的订单
- Scroll
- 需要全部文档,例如导出全部数据
- Pagination
- From和 Size
- 如果需要深度分页,则选用 Search After
本节知识回顾
学习了From, Size, Search After 的分页方式,同时也学习了Scroll API的使用方法,如果希望把数据从es导出,可以选择使用Scroll API。
CodeDemo
POST tmdb/_search { "from": 10000, "size": 1, "query": { "match_all": {
}} }
#Scroll API DELETE users
POST users/_doc {"name":"user1","age":10}
POST users/_doc {"name":"user2","age":11}
POST users/_doc {"name":"user2","age":12}
POST users/_doc {"name":"user2","age":13}
POST users/_count
POST users/_search { "size": 1, "query": { "match_all": {} }, "sort": [ {"age": "desc"} , {"_id": "asc"}
] }POST users/_search { "size": 1, "query": { "match_all": {} }, "search_after": [ 10, "ZQ0vYGsBrR8X3IP75QqX"], "sort": [ {"age": "desc"} , {"_id": "asc"}
] }#Scroll API DELETE users POST users/_doc {"name":"user1","age":10}
POST users/_doc {"name":"user2","age":20}
POST users/_doc {"name":"user3","age":30}
POST users/_doc {"name":"user4","age":40}
POST /users/_search?scroll=5m { "size": 1, "query": { "match_all" : { } } }
POST users/_doc {"name":"user5","age":50} POST /_search/scroll { "scroll" : "1m", "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAWAWbWdoQXR2d3ZUd2kzSThwVTh4bVE0QQ==" }
处理并发读写操作
并发控制的必要性
- 两个 Web 程序同时更新某个文档,如果缺乏有效的并发,会导致更改的数据丢失
- 悲观并发控制
- 假定有变更冲突的可能。会对资源加锁,防止冲突。例如数据库行锁
- 乐观并发控制
- 假定冲突是不会发生的,不会阻塞正在尝试的操作。如果数据在读写中被修改,更新将会失败。应用程序决定如何解决冲突,例如重试更新,使用新的数据,或者将错误报告给用户
- ES采用的是乐观并发控制
ES的乐观并发控制
- ES 中的文档是不可变更的。如果你更新一个文档,会将就文档标记为删除,同时增加一个全新的文档。同时文档的 version 字段加1
- 内部版本控制
- If_seq_no +lf_primary_term
- 使用外部版本(使用其他数据库作为主要数据存储
- version + version_type=externa
本节知识回顾
介绍了Elasticsearch是如何控制并发的,在Elasticserach当中采用乐观锁的机制,当我们需要处理一个并发冲突的检测时可以通过传入seq_no + primary_term 的方式来检测是否已经产生了版本的冲突。
CodeDemo
DELETE products PUT products
PUT products/_doc/1 { "title":"iphone", "count":100 }
GET products/_doc/1
PUT products/_doc/1?if_seq_no=1&if_primary_term=1 { "title":"iphone", "count":100 }
PUT products/_doc/1?version=30000&version_type=external { "title":"iphone", "count":100 }
此文章为4月Day2学习笔记,内容来源于极客时间《Elasticsearch 核心技术与实战》
