前言:
本篇内容记录笔者学习深度学习的学习过程,如果你有任何想询问的问题,欢迎在以下任何平台提问!
个人博客:conqueror712.github.io/
知乎:www.zhihu.com/people/soeu…
Bilibili:space.bilibili.com/57089326
掘金:juejin.cn/user/129787…
注:本文将会随着笔者的学习过程随时补充。
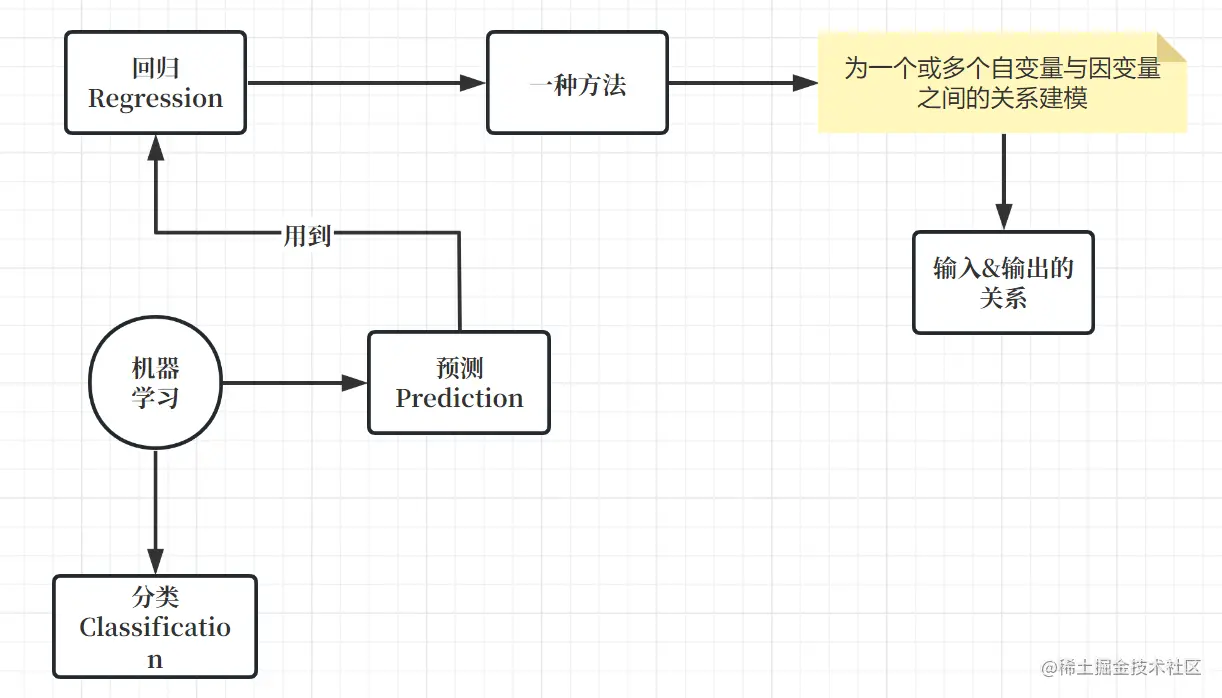
线性回归:
线性模型:
n维输入:x=[x1,x2,...,xn]T
有:
- n维权重:w=[w1,w2,...,wn]T
- 标量偏差b
输出是输入的加权和:y=<w,x>+b
如此,线性模型(有显式解)可以看作单层的神经网络(带权的层为1)
损失函数:
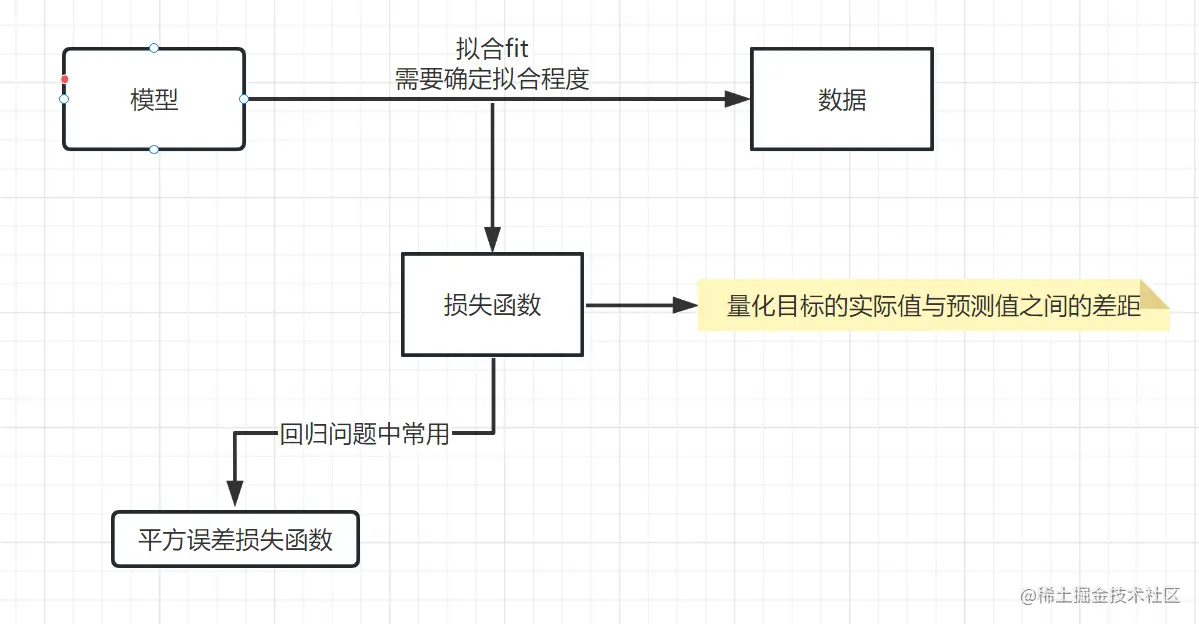
平方误差损失函数:l(i)(w,b)=21(y^(i)−y(i))2
其中,y^(i)是预测值,y(i)是真实标签
随机梯度下降:
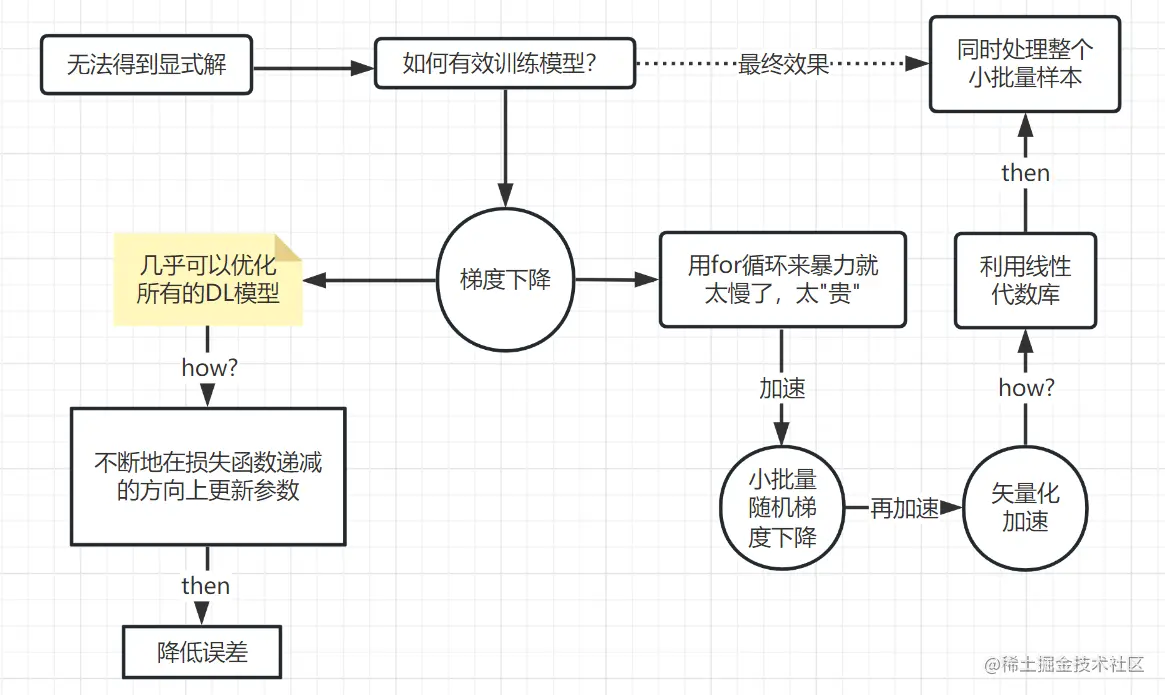
最小化目标函数 <=> 执行极大似然估计
梯度下降中的参数更新公式:wt=wt−1−η∂wt−1∂l
其中:η是学习率(步长的超参数),∂wt−1∂l是梯度
Softmax回归:
Softmax实际上是一个分类问题;
回归:估计一个连续值
分类:预测一个离散类别
- 通常多个输出
- 输出i是预测为第i类的置信度(对分类问题,只关心对于正确类的置信度是否足够大)
一些数据集:
MNIST:手写数字识别(10类)
ImageNet:自然物品分类(1000类)
回归→分类:
全连接层的开销:
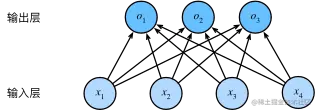
像这样的二分图,对于d个输入和q个输出:
原本:参数开销O(dq),这实在是太高了!
优化:O(ndq),n为超参数,可以灵活指定,用以平衡参数节约和模型有效性。
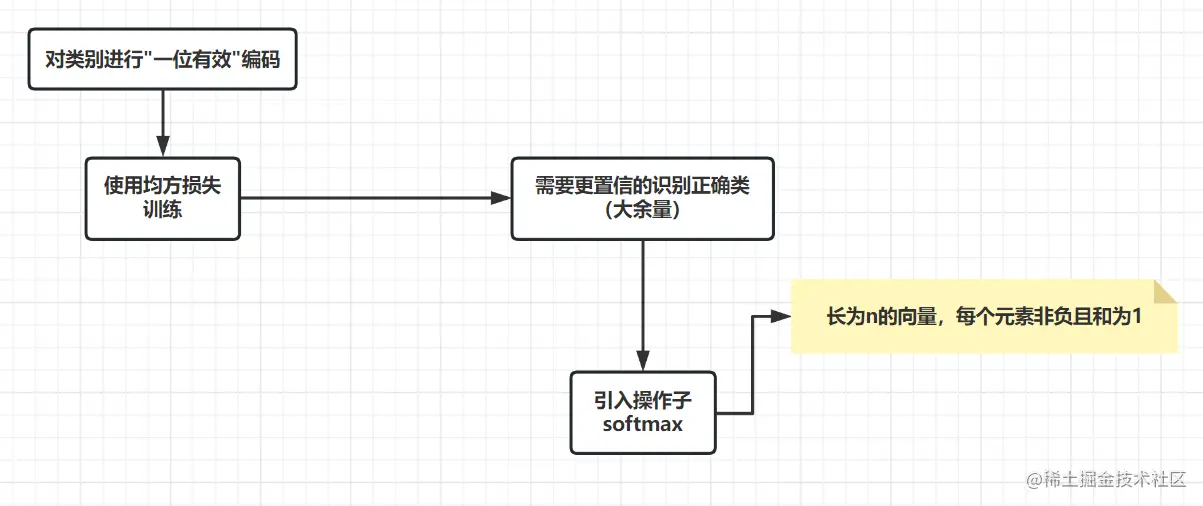
交叉熵损失:
交叉熵,衡量2个概率的区别,原始公式如下:
H(p,q)=Σi−pilog(qi)
以此作为损失,有损失函数:
l(y,y^)=−Σiyilogyi^=−logyy^
其梯度是真实概率和预测概率的区别:
σoil(y,y^)=softmax(o)i−yi(o是置信度)
本文正在参加 人工智能创作者扶持计划


