

SNet论文全解读——轻量级升点神器
写在前面:SENet是ImageNet最后一届(ImageNet 2017)的图像识别冠军,全称是Squeeze-and-Excitation Networks,由自动驾驶公司Momenta在2017年公布的一种图像的模块结构,相比前一年的图像识别top5错误率降低了25%。论文的结论中提出在Inception和Resnet中插入SE模块后效果有了显著的提升,而近年RegNet的实验中也得出的相同的结论。
论文标题:Squeeze-and-Excitation Networks
论文地址:[1709.01507v4.pdf (arxiv.org)](arxiv.org/pdf/2003.13…)
论文代码:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Networks
文章主体结构如下:
注:这里列出的文章主体架构是按内容层次的理解划分,与文章的各级标题并不相同
-
介绍
1.1 学习机制
1.2 SENet
1.3 轻量的SE块
-
相关工作
-
SE块
3.1 压缩(Squeeze):全局信息嵌入
3.2 激励(Excitation):自适应重新校准
3.3 实例
-
网络模型的计算和复杂性
-
实验
一、介绍
-
学习机制
在网络的每个卷积层,一组滤波器表示(卷积核)沿着输入信道的邻近空间连接模式——将局部接受域内的空间和通道信息融合在一起。通过将一系列卷积层与非线性激活函数和降采样算子相结合,CNN能够产生全局接受域的图像表示。计算机视觉研究的一个中心主题是寻找更强大的表示,只捕捉对给定任务最显著的图像属性,从而提高性能。最近的研究表明,通过将学习机制整合到网络中,帮助捕获特征之间的空间相关性,可以增强CNN产生的表征。
-
SENet
本文研究了网络设计时信道之间的关系。引入了挤压和激发(SE)块,目的是通过显式地建模其卷积特征的通道之间的相互依赖关系来提高网络的表示的质量。为此,还提出了一种机制,允许网络执行特征重新校准,该机制可以学习使用全局信息来有选择地强调信息特征,并抑制不太有用的特征。
-
SENet架构
SENet的网络结构如下图所示
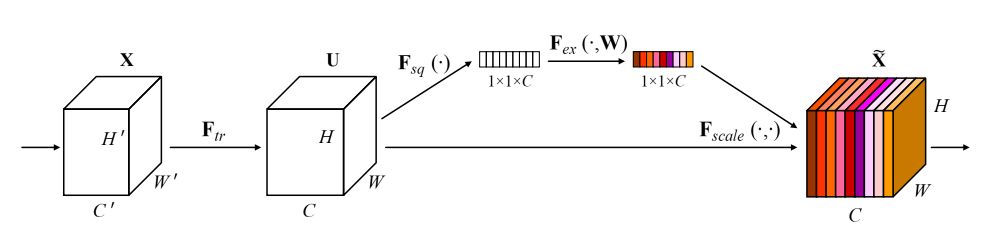
输入XXX映射到特征UUU,其中U∈RH×W×CU \in \mathbb{R}^H\times W\times CU∈RH×W×C。
SENet可以怎么使用呢?
例如:
存在一个卷积,那么就可以使用一个SE模块来执行特征的重新校准。特征UUU首先通过挤压操作,该操作通过聚合其空间维度(H×WH\times WH×W)的特征映射产生信道描述符。这个描述符的功能是产生一个通道级特征响应的全局分布的嵌入,允许来自网络的全局接受域的信息被网络的所有层使用。聚合之后是一个激励操作,它采取了一个简单的自门控机制的形式,以嵌入作为输入,并产生一个每通道调制权值的集合。这些权重应用于特征映射UUU,以生成SE块的输出,这些块可以直接输入到网络的后续层中。
通过简单地堆叠一组SE块,就可以构建一个SE网络(SENet)。此外,这些SE块还可以替换网络体系结构中一定深度范围内的原始块结构(第6.4节)。虽然构建块的模板是通用的,但它在整个网络中不同深度执行的角色是不同的。在早期的层中,它以类不可知的方式激发信息特征,加强了共享的低级表示。在后面的层中,SE块变得越来越专门化,并以一种高度类特定的方式响应不同的输入(第7.2节)。因此,由SE块执行的特征重新校准的好处可以通过网络来积累起来。
-
轻量的SE块
新的CNN架构的设计和开发是一项困难的工程任务,通常需要选择许多新的超参数和图层配置。相比之下,SE块的结构很简单,可以直接用于现有的最先进的架构中,通过使用SE对应的组件,这样可以有效地提高性能。SE块在计算上也是轻量级的,并且只会略微增加模型的复杂性和计算负担。
为了证明其效果,文中使用几种不同的SENet对ImageNet数据集进行了广泛的评估。还展示了在ImageNet之外的结果,表明其方法的好处并不局限于特定的数据集或任务。利用SENets,作者在2017年ILSVRC分类竞赛中排名第一。SE的最佳模型集成在测试集1上达到了2.251%的top5误差。与前一年的获胜者进入组相比相对提高了25%(前5名的误差为2.991%)。
二、相关工作
作者在此章节简单介绍了深度学习模型框架的发展历程,并对多种不同的卷积以及1×11\times 11×1卷积做出了分析。此外还对神经网络的算法框架搜索的相关工作做出了分析。最后作者总结了注意力机制的应用。若有兴趣可以详细阅读论文
三、SE块
-
X——>U
这部分实质上就是一个卷积操作,由W′×H′×C′W'\times H'\times C'W′×H′×C′变为W×H×CW\times H\times CW×H×C
3.1 压缩(Squeeze):全局信息嵌入
通道依赖性问题:每个卷积都有其固定的局部感受野,因此下一级无法对该区域之外的上下文信息加以利用。
为了解决通道依赖性问题,作者先将全局空间信息压缩(Squeeze):
zc=Fsq(uc)=1H×W∑i=1H∑j=1Wuc(i,j)z_{c}=\mathbf{F}_{s q}\left(\mathbf{u}_{c}\right)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} u_{c}(i, j) zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
实际上就是一个全局平均池化(Global Average Pooling)。作者解释对其操作可以理解为局部描述的压缩,也可以选择更复杂的策略。
3.2 激励(Excitation):自适应重新校准
作者提到这一步骤的目的是为了完全捕获通道级的依赖关系(其实让输出向量学习通道间的全局信息),为了实现这一目标必须满足以下两个标准:
- 它必须是灵活的(它必须能够学习一个非线性通道之间的交互)
- 它必须学习一个非互斥的关系,意思就是让重要的信息可以相互增强的激活。
基于以上标准,作者提出了两层全连接构成的门机制(gate mechanism):
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))\mathbf{s}=\mathbf{F}_{e x}(\mathbf{z}, \mathbf{W})=\sigma(g(\mathbf{z}, \mathbf{W}))=\sigma\left(\mathbf{W}_{2} \delta\left(\mathbf{W}_{1} \mathbf{z}\right)\right) s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
其中δ\deltaδ是ReLU激活函数,σ\sigmaσ是sigmoid激活函数。W1 W2W_1\ \ W_2W1 W2是两个全连接层的权值矩阵。
最终的输出如下:
\widetilde{X} =F_{scale}(u_c,s_c) = s_c·u_c
讨论:SE块本质上引入了基于输入的动力学,这可以看作是通道上的自注意函数,这些通道的关系不局限于卷积滤波器响应的局部接受域。
注:SE块其实就是通道上的注意力函数,而且该注意力函数关注了全局通道信息
3.3 实例
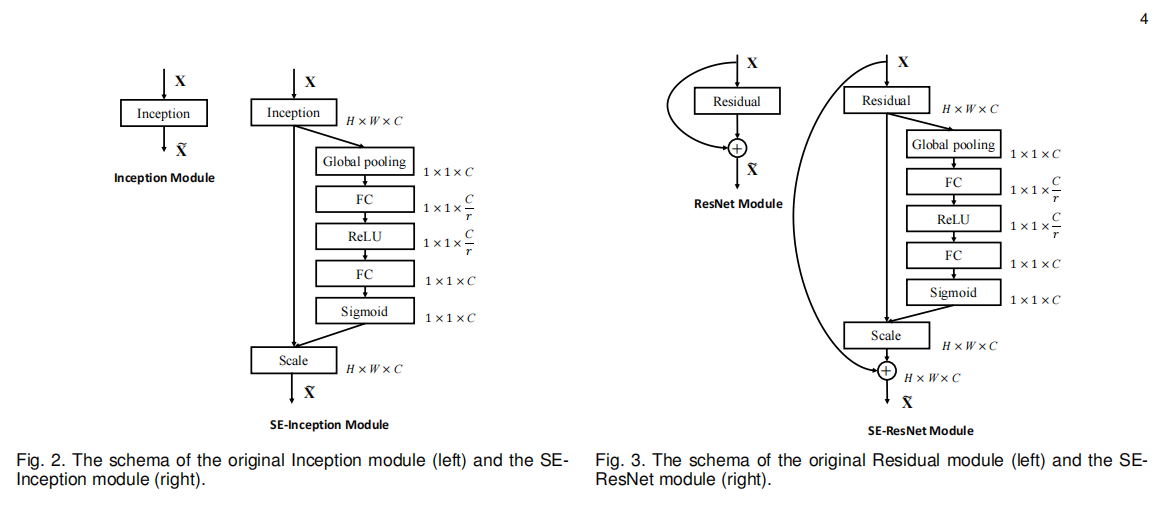
作者考虑了Inception和ResNet,其结构如下图所示(图左是SE-Inception,图右是SE-ResNet),除此之外, ResNeXt, Inception-ResNet, MobileNet and ShufflfleNet都可以用类似的方法。
四、网络模型的计算和复杂性
In aggregate,SE-ResNet-50 requires∼3.87GFLOPs, corresponding to a 0.26%relative increase over the original ResNet-50.In practice, with a training mini-batch of256images, a single pass forwards and backwards through ResNet-50 takes190ms, compared to209ms for SE-ResNet-50 (both timings are performed on a server with 8 NVIDIA Titan X GPUs).
我们认为,这是一个合理的开销,特别是因为在现有的GPU库中,全局池和小型内部产品操作的优化程度较低。此外,由于其对于嵌入式设备应用的重要性,我们还对每个模型的CPU推理时间进行了基准测试:对于224×224像素的输入图像,ResNet-50需要164毫秒,而SE-ResNet-50只需要167毫秒。SE块所需的少量额外计算开销因其对模型性能的贡献而被证明是合理的。
SE-ResNet-50引入了多250万参数量,相比原来包含了2500万参数量的ResNet-50而言。
五、实验

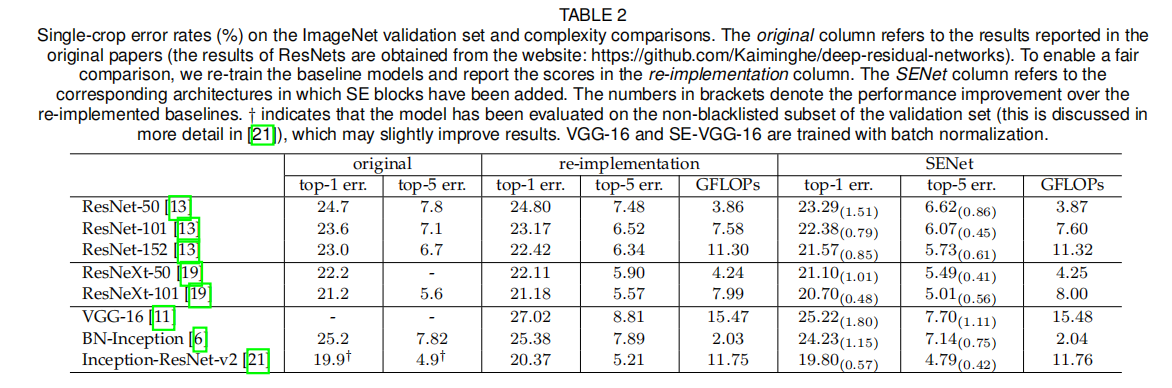
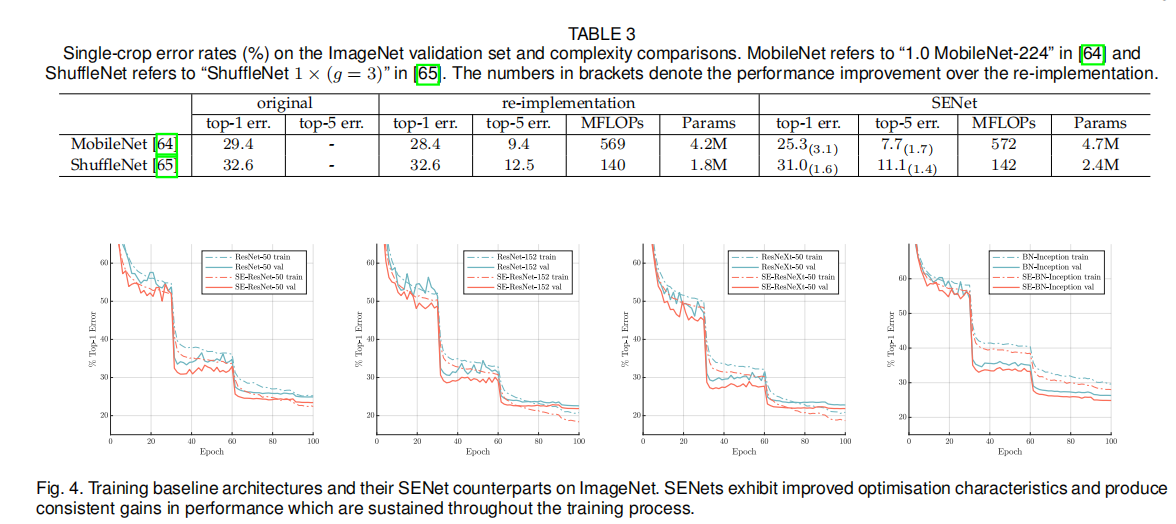
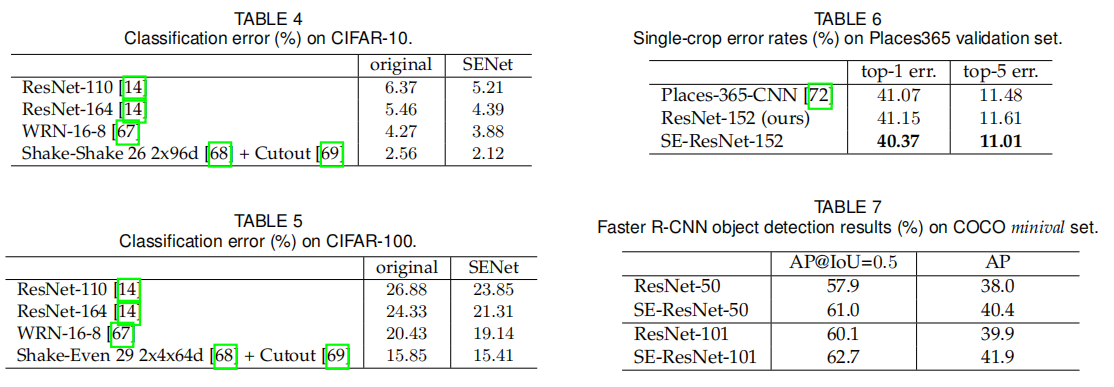
-
Reference
解读Squeeze-and-Excitation Networks(SENet) - 知乎 (zhihu.com)
Squeeze-and-Excitation Networks - 知乎 (zhihu.com)
[《Squeeze-and-Excitation Networks》SE-Net通道注意力机制_小哈蒙德的博客-CSDN博客](
