

前言 本文提出了一种新的预训练模型架构(iTPN ),该架构由多个金字塔形的Transformer层组成。每个层都包含多个子层,其中一些是普通的self-attention和feed-forward层,而另一些则是新的pyramid层。Pyramid层是一种新的层类型,它被设计为对输入进行多粒度的表示学习。此外,iTPN 还使用了一些其他的技巧,以提高模型的鲁棒性和泛化能力。
iTPN 在 ImageNet-1K 上达到了top-1 准确率,在使用 Mask RCNN 进行 1× 训练计划的 COCO 目标检测上达到了高精度的APmIoU ,在使用 UPerHead 的 ADE20K 语义分割上——所有这些结果都创下了新记录。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文出发点
大多数现有的预训练任务都是基于ViT。即使使用了分层结构的ViT(例如,SimMIM、ConvMAE 和 GreenMIM ),但预训练任务只会影响backbone,不会影响到neck(例如,特征金字塔)。对下游任务进行预训练模型微调,只会把backbone和参数进行迁移。由此,优化从随机初始化的neck开始,不能保证与预训练的backbone共同作用,这对下游任务进行微调而言是不利的。因此,本文提出一个完整的预训练框架来减轻这种风险。
创新思路
首先,通过将特征金字塔插入预训练阶段(用于重建)并在微调阶段重用权重(用于识别)来统一上游和下游的neck(将预训练的backbone和neck共同迁移到下游任务)。其次,为了更好地预训练特征金字塔,提出一个新的掩蔽特征建模 (MFM) 任务,以提高了重建和识别的准确性。同时,使得Backbone 在与 neck 的联合优化过程中变得更加强大。
方法
整体架构
在本文中,预训练任务是掩蔽图像建模 (MIM),微调任务可以是图像分类、对象检测和实例/语义分割。现有方法假设它们共享相同的backbone ,但需要不同的neck和head。
在数学上,预训练和微调目标写为:
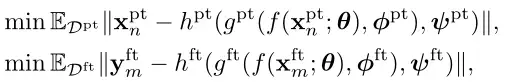
模型架构如下图所示,传统预训练(左)与建议的整体预训练框架(右)之间的比较。本文使用特征金字塔作为统一的neck模块,并应用掩码特征建模来预训练特征金字塔。绿色和红色块分别表示网络权重是经过预训练和未训练的(即随机初始化以进行微调)。
Unifying Reconstruction and Recognition
分层Transformer模型包含 S 个阶段,每个阶段都有几个转换器块。大多数情况下,backbone(也称为编码器)逐渐对输入信号进行下采样并生成 S + 1 个特征图。通过在微调中重复使用一些参数,以大大缩小传输差距:在预训练和微调之间唯一保持独立的模块是head。Masked
Feature Modeling
为了获得捕获多阶段特征的能力,我们在每个阶段添加一个重建head,并优化以下多阶段损失:
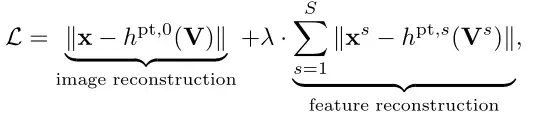
借鉴知识蒸馏的想法,利用教师backbone来生成中间目标。教师模型被选择为移动平均编码器(没有引入外部知识)或另一个预训练模型(如CLIP,即在图像文本对的大型数据集上进行了预训练)。在前一种情况下,只将蒙版块提供给教师模型进行加速。在后一种情况下,按照 BEiT将整个图像提供给预训练的 CLIP 模型。
结果
作者在分类、检测、分割三个下游任务上进行对比实验。其中,分类任务在ImageNet-1K数据集上对iTPN与现有方法进行对比:
对预训练的neck进行迁移的iTPN方法在COCO数据集上进行了检测和实例分割的对比实验:
生成的注意力图对比效果:
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
