

Netty框架是业内非常优秀的网络通信框架,本系列主要是通过介绍Netty里面优秀的组件设计,学一下高手的操作
ByteBuf的大致分类
Netty为了能让ByteBuf在各种场景下都能发挥其优秀的性能,设计了许多独具特点的ByteBuf
粗略地可以从2个维度进行区分:内存分布和内存回收
-
按照内存分布维度:堆内存字节缓冲区、直接内存字节缓冲区
-
按照内存回收维度:基于对象池,普通缓冲区
具体的实现:
堆内存的回收速度和分配内存速度会比堆外速度要快,但是如果进行
Socket的IO读写,就需要从用户态复制到内核态,多一次复制,复制到内核的Channel
-
HeapByteBuf:堆内存字节缓冲区 -
DireactByteBuf:直接内存字节缓冲区,内存的分配和回收速度会慢,但是方便进行IO读写等。 -
PooledByteBuf:基于对象池,类似线程池等,减少创建和销毁的性能消耗,但是编码会很复杂 -
UnpooledByteBuf:普通的ByteBufer,生命周期由程序员自行管理
首先先了解最基本的ByteBuf设计,后面再介绍其子实现类:AbstractReferenceCountedByteBuf、 UnpooledHeapByteBuf
ByteBuf的设计
缓冲区,无论是读取数据还是写数据,都要作用到
ByteBufBuffer是一个对象,通常是ByteBuffer类型
在NIO库里,任何时候操作NIO中的数据,都需要经过缓冲区。
- 读取数据时,是直接读到缓冲区中(这里并没有直接读到某个地方,而是都放到缓冲区中)
- 写入数据时,写入到缓冲区
在Java种7大基础类型除了Boolean没有自己的缓冲区,其他都有自己的,比如:
ByteBufferIntBufferLongBuffercharBufferflotBuffer- ….
那为什么Netty不用Java自带的ByteBuffer,而是要自己实现了一个ByteBuf呢?
JDK的ByteBuffer
首先ByteBuffer有自己缺点:
- ButeBuffer长度固定:一旦分配完成,容量不能动态扩展和收缩
- ByteBuffer的Api不好用:读写的时候需要手动调用
flip,rewind等
那么究竟ByteBuffer有多难用呢?,我们细嗦!
JDK ByteBuffer只有用一个位置position指针用来记录读写位置。
position:读写位置limit:最少读取偏移量capacity:容器容量
由于只有一个position位置,所以每次进行读写的时候都需要进行
flip、clear方法
- flip:反转,将模式转换成写模式
读取byteBuffer的内容,是读写position到capacity之间的数据。
所以当需要读取内容的时候,需要进行flip,将position的位置置为0,limit置为position,这样才能读取到正确的内容。
ByteBuf的双指针
readIndex:读指针 writeIndex:写指针
ByteBuf则是通过两个位置指针来协助缓冲区的读写操作,读操作使用readerIndex、写操作使用writerIndex。
- 读操作的时候:readIndex++,读取的内容为,readIndex - writeIndex,但是不会超过writeIndex。 之后0~readIndex的数据视为
discard无用,调用discardReadBytes方法可以释放掉。 - 写操作的时候:writeIndex++,write ~ capacity之间的数据都是可以写的。
用2个变量来存储读写位置可以简化我们去调用API。像Mysql里面的redo log底层环形结构,也是用2个变量,write pos和check point。
ByteBuf的空间复用
0 到 readIndex部分数据是已经读过数据,i相当于没有用了discard,可以丢掉,然后就会腾出这部分空间来用读后面的数据
- 0~readIndex:组成
discardable,表明数据已经被读取,没有用了,可以被丢弃掉,调用discardReadBytes可以释放这部分空间(慎用) - readIndex~writeIndex:组成content,表明实际读取到的数据
- writeIndex~capacity:是剩下可以进行写入的空间
这部分空间也称为:Discardable bytes
释放
discardable bytes空间可以提高空间利用率,减少ByteBuf动态扩容带来的性能损耗
相比起其他的Java对象,缓冲区的分配和释放是一个耗时的操作。
缓冲区的动态扩张需要进行字节数组的复制,这是一个非常耗时的操作,所以我们为了提高性能,往往需要尽最大努力去提升缓冲区的重用率。
调用discardReadBytes会发生字节数组的内存复制,也会带来性能消耗,所以需要确认真的需要进行dis这部分的内存,才进行这样的操作。
具体就是调整writeIndex和readIndex的指针。
- 将
readIndex指针往左移到0 - 将
writeIndex指针向左移动readIndex个单位
ByteBuf的动态平滑扩容
动态、平滑,都是ByteBuf扩容的优点
ByteBufefer在put操作的时候都会进行空间判断,防止内存溢出OOM情况。
当剩下的空间不能满足写入数据的时候,就会重新生成一个更大的容器,把旧的数据装进去,再把新的数据装进去。
这些都是程序员自己实现的,并不是包里面已经帮我们实现的,这里也有线程并发的问题,所以还是很危险的。
- 在往ByteBuf写入数据的时候(
writeBytes),先判断是否能写入(ensureWritable) - 如果能写入,则直接写入,如果不能写入则进行计算扩容的容量(
calculateCapacity) - 经过算法计算好了之后,进行数据复制,主要是生成新的扩容后的容器(
capacity) - 此时ByteBuf的字节数组引用已经替换成扩容后的ByteBuf,最后再把需要写入的数据,写入到新的字节数组即可(
setBytes)
写入数据的时候会进行ensureWritable,
判断剩余的容量是否可以写入,如果不行,则动态进行扩容。
计算扩容多大的数组:calculateCapacity
注意这里有个细节:这里进行扩容的时候并不是以双倍的方式来扩容,而是通过增加阈值的方式来进行扩容
应该是考虑到如果多次扩容,后面每扩一次,若是浪费空间,那么就是浪费很大一块空间的考虑把,会出现内存膨胀和浪费的情况?这样扩会比较平滑
如果只是以minNewCapacity作为扩容后的容量,那么这次扩完,然后塞数据进去,下一次又要进行一次扩容了,频繁地扩容复制数据也是很浪费性能。
- 如果容量是超过阈值
threshold,则以阈值为步长进行扩容。 - 如果没有超过阈值,则以
64倍增,因为内存比较小的时候,倍增还是可以接受的。
这种扩容的方式称为倍增或者是步进算法。
UnpooledHeapByteBuf
非池化的堆内ByteBuf
相对的DirectByteBuf是堆外的
特点:HeapByteBuf,是堆内存分配的,所以对象回收管理那一块,是比DirectByteBuf性能更优秀的
这个是最普通,也是最通用的ByteBuf,如果在满足性能的情况下,官方是推荐使用UnpooledHeapByteBuf

ByteBufAllocator:是用来分配内存的array:实际的字节数组缓冲区tmpNioBuf:用来把ByteBuf转化成ByteBuffer给JDK NIO用的
非常的精简,直接看他的动态扩展缓冲区
动态扩展缓冲区
前面我们已经提到了,ByteBuf在写入数据的时候,如果容量不够,会自己进行动态扩展
我们来看看动态扩展在UnpooledHeapByteBuf的实际操作

这里是capacity那一步了,可以看到他,底层都是调用System.arraycopy,进行字节数组的拷贝
AbstractReferenceCountedByteBuf
用来左对象引用计数的ByteBuf
作用是:用来跟踪对象的分配和销毁,做自动内存回收
retain函数,引用计数器加一
通过
CAS对引用计数器进行加一操作

我们可以看到这里的refCnt初始值明显不是0开始的,如果是0的话,那么一进行retain,就会抛异常
实际上,reCnt也是是从1开始计数的。
- 当被释放和被申请的次数相等时,就会调用回收方法回收当前的ByteBuf对象
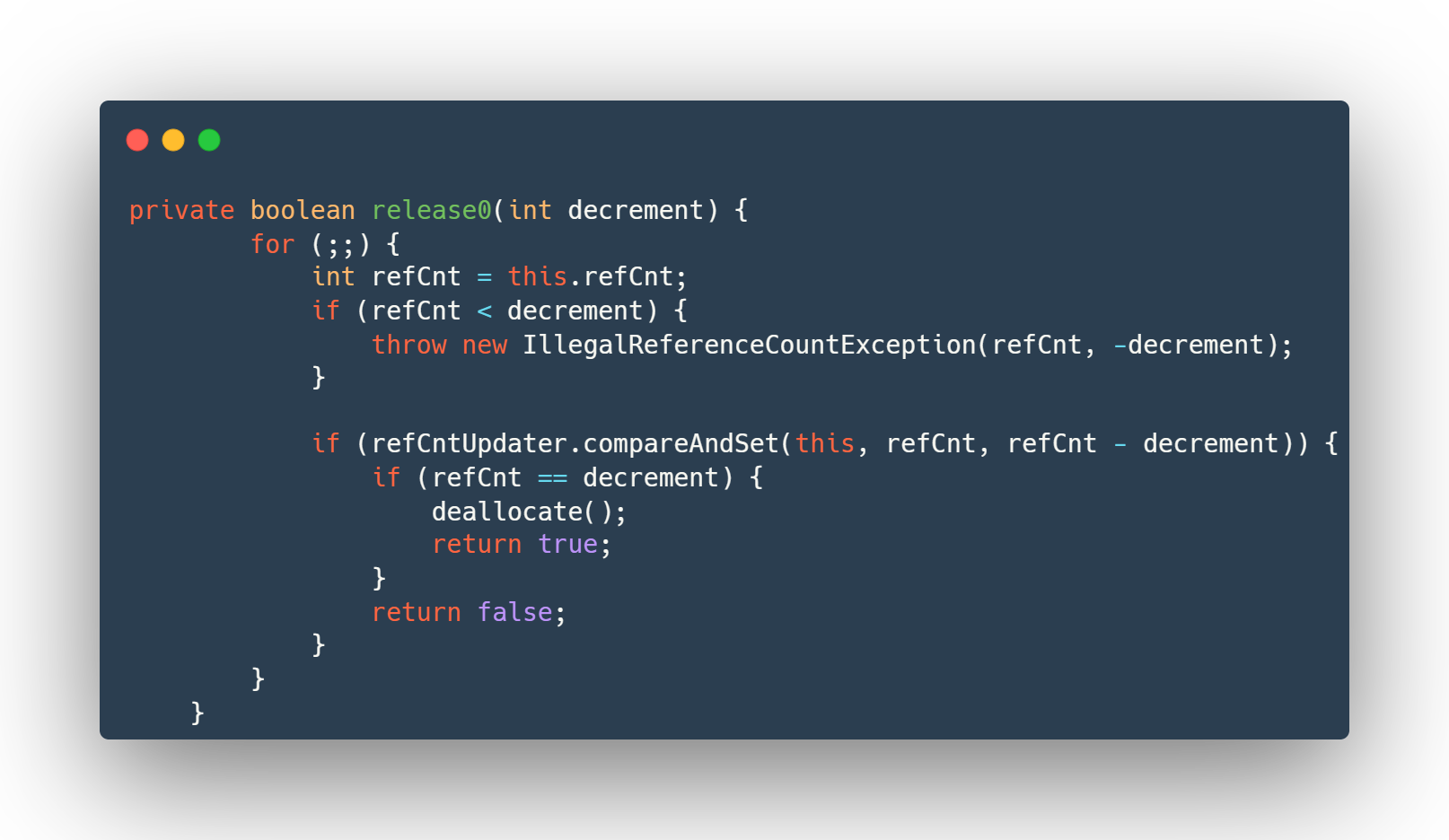
release函数,释放引用计数器
同样也是通过
CAS进行释放
也是放在一个自旋循环里面进行判断并且更新refCnt的值
这里同样也透露了一个知识点:
CAS自旋的其实就是通过一个循环来实现的,之前听着自旋好像很高端的样子,其实就是一个循环语句
不过在《Java开发手册》中提到过,CAS自旋,最少要保证3次的尝试,所以这个我们可以在开发的时候注意一下。
总结
JDK自带的ByteBuff,由于是以字节数组实现,所以定好数组长度之后不方便进行扩容,并且由于只有单个指针记录偏移量位置,所以需要程序员自己去调用API,增加了编码的难度。
但是Java NIO里面的返回值和参数都是ByteBuffer形式,所以没办法,难受也得顶着。
Netty实现了ByteBuf,同样也是以字节数组的形式来存数据,但是在框架的层面上帮我们封装了很多不必要的操作,并且支持了动态平滑扩容、空间复用等操作
并且还实现了许多不同场景下性能优秀的ByteBuf比如堆外的ByteBuf(DirectByteBufe),基于池化的(PoolByteBuf)
同样Netty提供了ByteBuf转化成ByteBuffer,所以可以直接使用
彦祖来都来了,看到这里就点个赞吧!这对于我来说真的非常重要👍
