一、概述
粒子滤波(Particle Filter)是动态模型的非线性,非高斯的版本,也就是说zt和zt−1、xt和zt的关系是非线性的,其噪声也是非高斯的:
zt=g(zt−1,μ,ε)xt=h(zt,μ,δ)
卡尔曼滤波的概率分布可以直接通过高斯分布的性质解得,然而,对于粒子滤波,由于其状态转移概率和发射概率是任意的,我们无法直接得到其概率分布。因此,我们需要采用采样的方法进行估计。在实际应用中,我们通常更关注的是概率分布关于某函数的期望,而非概率分布本身。因此,本文将主要介绍如何通过采样的方法来求某个函数依概率分布的期望。
二、序列重要性采样
对于分布p(z),要求期望Ep(z)[f(z)],重要性采样(Importance Sampling)的方法是引入一个新的分布q(z),然后对q(z)进行采样,其做法如下:
Ep(z)[f(z)]=∫f(z)⋅p(z)dz=∫f(z)⋅q(z)p(z)⋅q(z)dz≈N1i=1∑Nf(zi)⋅权重q(zi)p(zi)zi∼q(z),i=1,2,⋯,N
在滤波问题中,关心的概率分布是p(zt∣x1:t),权重就是:
wt(i)=q(zt(i)∣x1:t)p(zt(i)∣x1:t),i=1,2,⋯,N
使用重要性采样的一个挑战是计算量过大。在每个时刻,我们都需要进行N次采样,而权重的分子这一项的计算是非常复杂的。因此,我们希望找到一个wt(i)与wt−1(i)之间的递推关系来简化这个过程。这就引出了序列重要性采样(Sequential Importance Sampling,SIS) 的概念。
在SIS中,我们并不直接使用p(zt(i)∣x1:t)进行采样,而是使用p(z1:t(i)∣x1:t)。这样做的目的是为了简化计算。我们可以使用p(z1:t(i)∣x1:t)进行采样,是因为它满足一定的条件:
wt(i)∝q(z1:t(i)∣x1:t)p(z1:t(i)∣x1:t)
现在我们首先要找到p(z1:t∣x1:t)与p(z1:t−1∣x1:t−1)之间的递推关系:
p(z1:t∣x1:t)=p(x1:t)p(z1:t,x1:t)=C1p(z1:t,x1:t)=C1p(xt∣z1:t,x1:t−1)⋅p(z1:t,x1:t−1)=C1p(xt∣zt)⋅p(zt∣z1:t−1,x1:t−1)⋅p(z1:t−1,x1:t−1)=C1p(xt∣zt)⋅p(zt∣zt−1)⋅p(z1:t−1∣x1:t−1)⋅Dp(x1:t−1)=CDp(xt∣zt)⋅p(zt∣zt−1)⋅p(z1:t−1∣x1:t−1)
由于q(z1:t∣x1:t)是我们指定的,因此可以指定:
q(z1:t∣x1:t)=q(zt∣z1:t−1,x1:t)⋅q(z1:t−1∣x1:t−1)
所以有:
wt(i)∝q(z1:t(i)∣x1:t)p(z1:t(i)∣x1:t)∝q(zt(i)∣z1:t−1(i),x1:t)⋅q(z1:t−1(i)∣x1:t−1)p(xt∣zt(i))⋅p(zt(i)∣zt−1(i))⋅p(z1:t−1(i)∣x1:t−1)=q(zt(i)∣z1:t−1(i),x1:t)p(xt∣zt(i))⋅p(zt(i)∣zt−1(i))⋅wt−1(i)
总结一下,SIS的迭代过程如下:
前提:
t−1时刻完成采样并计算得到权重
t时刻:fori=1,...,N
①根据q(zt∣z1:t−1(i),x1:t)完成采样得到zt(i),并且计算权重wt(i);
②对权重进行归一化,wt(i)→w^t(i),∑i=1Nw^t(i)=1。
三、重要性重采样
为了解决权值退化的问题,我们引入了重要性重采样(Sampling Importance Resampling,SIR)算法。这是在SIS的基础上进行改进的算法,它增加了两个部分:一个是重采样,另一个是特定的q(zt∣z1:t−1,x1:t)概率分布。
- 重采样
SIS算法可能会出现权值退化的现象,即在一段时间后,大部分权重都接近于0。这主要是由于维度灾难的问题,在高维空间中需要大量的样本。通过使用重采样,我们可以缓解这一现象。
下面我们以N=3为例来解释重采样的过程。在下表中,我们展示了3个采样粒子的权重(归一化后的权重可以理解为pdf),并且计算了pdf的cdf:
| z(1) | z(2) | z(3) |
|---|
| pdf | 0.1 | 0.1 | 0.8 |
| cdf | 0.1 | 0.2 | 1 |
画出例子的cdf图像如下:
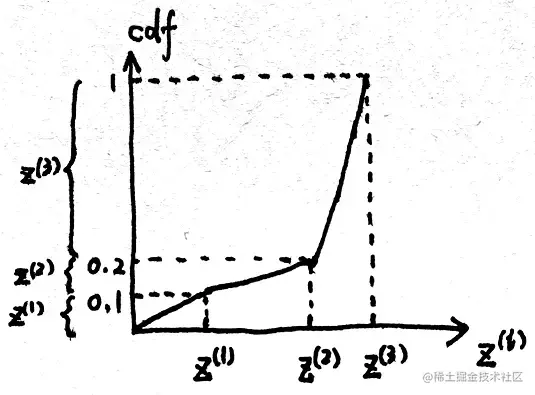
重采样是指在均匀分布u∼U(0,1)上进行采样,然后依照cdf找到对应的新的粒子z(i),意味着将原有的概率值重新变为等面积的样本点,另外,重采样以后的新的权重w^^=N1。
在SIS的基础上加上重采样,就是基本的粒子滤波算法(Basic Particle Filter)。
- 选择合适的提议分布
选择恰当的提议分布也是一种解决权重衰减的方法。这里一个常用的选择就是:
q(zt∣z1:t−1,x1:t)=p(zt∣zt−1)
则此时的权重wt(i)的计算公式就变为了:
wt(i)=q(zt(i)∣z1:t−1(i),x1:t)p(xt∣zt(i))⋅p(zt(i)∣zt−1(i))⋅wt−1(i)=p(zt(i)∣zt−1(i))p(xt∣zt(i))⋅p(zt(i)∣zt−1(i))⋅wt−1(i)=p(xt∣zt(i))⋅wt−1(i)
这个策略被称为生成与测试策略。在生成阶段,我们通过 p(zt∣zt−1(i)) 产生一个 p(xt∣zt(i)),然后将它们相乘以计算新的权重 wt(i)。随后,在测试阶段,如果生成的样本 z(i) 对应的 p(xt∣zt(i)) 较大,那么新的权重 wt(i) 也会相应增大,这表明样本 z(i) 是一个较好的选择。
- 算法
在SIS的基础上加上重采样和上述特定的提议分布就得到了SIR算法,其迭代的流程是这样的:
前提:t−1时刻完成采样并计算得到权重
t时刻:
①根据q(zt∣z1:t−1(i),x1:t)=p(zt∣zt−1(i))完成采样得到zt(i),并且计算权重wt(i)=p(xt∣zt(i))⋅wt−1(i);
②对权重进行归一化,wt(i)→w^t(i),∑i=1Nw^t(i)=1。
③重采样
“开启掘金成长之旅!这是我参与「掘金日新计划 · 2 月更文挑战」的第 15 天,点击查看活动详情”


