开启掘金成长之旅!这是我参与「掘金日新计划 · 2 月更文挑战」的第 30 天,点击查看活动详情
3. HMM参数介绍和求解方法
观测序列:观测概率矩阵B(状态生成观测的概率)
未观测的状态序列:初始状态概率向量π(处于状态的概率) + 状态转移概率矩阵A
λ=(A,B,π)
HMM:P(O∣λ)=I∑P(O,I∣λ)=I∑P(O∣I,λ)P(I∣λ)(其中I为标注序列)
- 训练,已知O求λ:其中I为标注序列,在公式中是隐变量,因此可用EM算法1求解上式的模型参数λ。具体步骤:
- 初始化λ
- 观测变量和隐变量的对数似然函数:logP(O,I∣λ)=πi1bi1(o1)ai1i2bi2(o2)⋯aiT−1iTbiT(oT)(初始状态×生成观测的概率×状态转移概率×生成观测的概率…)
- E:对隐变量求期望 Q(λ,λ)=I∑logP(O,I∣λ)P(O,I∣λ)=I∑logπi1P(O,I∣λ)+I∑(t=1∑T−1logaitit+1)P(O,I∣λ)+I∑(t=1∑Tlogbit(ot))P(O,I∣λ)
- M:求使Q取极大值的λ=(A,B,π)
求偏导数并使其等于0,有:∂πi∂Q(λ,λ)=∂aij∂Q(λ,λ)=∂bj(k)∂Q(λ,λ)0
约束条件为初始状态概率分布的和等于1,即:i=1∑Nπi=1
状态已知的情况下,观测概率分布的和等于1,即:k=1∑Mbj(k)=1
得到πi,aij,bj(k)的值,即更新λ
- 重复步骤3、4
- 计算观测序列出现的概率(N是总的状态数)
- 枚举法:O(TNT)
- 递推法:O(TN2)
状态为qi的前向概率αt(i)(生成给定长度为t的观测序列,且t状态是qi的概率):αt(i)=P(o1,o2,…,ot,it=qi∣λ)
t=1时:α1(i)=πibi(o1),i=1,2,…,N(初始得到该状态×该状态生出该观测)
P(o1∣λ)=i=1∑Nα1(i)(在所有状态下生成该观测的概率加总)
递推,对于t=1,2,…,T−1
αt+1(i)=[j=1∑Nαt(j)aji]bi(ot+1),i=1,2,…,N(上一次生成状态j,状态j转移为状态i,状态i生成观测的概率)
P(o1,o2,…,ot+1∣λ)=i=1∑Nαt+1(i)
当t=T时:
P(O∣λ)=i=1∑NαT(i)
算法复杂度(感觉图把i写成j了):
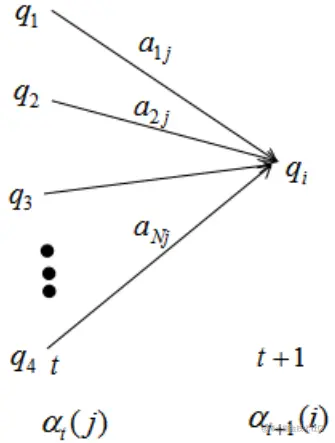
αt+1(i)=j=1∑Nαt(j)aji(a是状态转移概率)
因此从t到t+1时刻的计算量为O(N2)
对于观测序列长度为T:O(TN2)
- 模式匹配中的维特比算法(动态规划)
给定λ(模型参数)和O(观测序列),预测最有可能的状态序列
算法思想:若 t 时刻最有可能的状态序列I=(i1,i2,…,it∗)通过it∗,则从t时刻到T时刻的最优路径一定包括it∗。我们利用这一思想确定了最优状态序列的最后一个时刻的状态iT,然后利用该状态回溯时刻t=1,2,…,T−1的最优状态
示例:
已知模型λ=(A,B,π),观测集合V={O1,O2},状态集合Q={1,2,3}
A=⎣⎡0.5,0.2,0.30.3,0.5,0.20.2,0.3,0.5⎦⎤,B=⎣⎡0.5,0.50.4,0.60.7,0.3⎦⎤,π=(0.2,0.4,0.2)T
若观测序列O=(O1,O2,O1),求最优状态序列I=(i1∗,i2∗,i3∗)
解:
定义δt(i)是所有长度为t、最终状态为i的、能得到指定观测序列的路径中,概率最大的路径的概率。
定义Ψt(i)是所有长度为t、最终状态为i的、能得到指定观测序列的路径中,最有可能的倒数第二个节点(倒数第二个时间点概率最大的状态):Ψt(i)=i≤j≤Nargmax[δt−1(j)aji]
根据维特比算法的核心思想,我们计算观测序列下的最优路径:
1. t=1时,δ1(i)是观测为o1、状态为i的概率:
δ1(i)=πibi(O1), i=1,2,3
得δ1(1)=0.2∗0.5=0.1,δ1(2)=0.16,δ1(3)=0.28
记Ψ1(i)=0, i=1,2,3
2. t=2时:
δ2(i)=1≤j≤3max[δ1(j)aji]bi(o2)
Ψ2(i)=1≤j≤3argmax[δ1(j)aji],i=1,2,3
δ2(1)=jmax{0.1∗0.5,0.16∗0.3,0.28∗0.2},Ψ2(1)=3
类似:δ2(2)=0.0504,Ψ2(2)=3,δ2(3)=0.042,Ψ2(3)=3
3. t=3时:
δ3(i)=1≤j≤3max[δ2(j)aji]bi(o3)
Ψ3(i)=1≤j≤3argmax[δ2(j)aji],i=1,2,3
δ3(1)=0.00756,Ψ3(1)=2,δ3(2)=0.01008,Ψ3(2)=2,δ3(3)=0.0147,Ψ3(3)=3
最有可能的路径以i3∗=argmaxi[δ3(i)]为最终状态
4. 回溯其他时刻的最优节点:
t=2时,i2∗=Ψ3(i3∗)=Ψ3(3)=3
t=1时,i1∗=Ψ2(i2∗)=Ψ2(3)=3
因此最优状态序列是:I=(i1∗,i2∗,i3∗)=(3,3,3)
4. HMM用法
-
标注学习/序列标注 sequence tagging:对已观测到的数据序列O进行标注,标注序列I相当于隐变量
-
语音识别:waveform是输出序列,匹配音素(状态)序列
-
词性标注
-
文本分析
5. 其他正文及脚注未提及的参考资料
- Natural language processing: an introduction
- 初学者也能看懂的隐马尔科夫模型介绍
-
可参考我撰写的博文:变分推断(variational inference)/variational EM_诸神缄默不语的博客-CSDN博客


