

题是公司面试题,答案是网上抄的
1.Js的数据类型
值类型(基本类型) :字符串(String)、数字(Number)、布尔(Boolean)、空(Null)、未定义(Undefined)、Symbol。
引用数据类型(对象类型) :对象(Object)、数组(Array)、函数(Function),还有两个特殊的对象:正则(RegExp)和日期(Date)。
2.箭头函数和普通函数的区别
1、语法更加简洁、清晰
从上面的基本语法示例中可以看出,箭头函数的定义要比普通函数定义简洁、清晰得多,很快捷。
2、箭头函数不会创建自己的this(重要!!深入理解!!)
我们先来看看MDN上对箭头函数this的解释。
箭头函数不会创建自己的this,所以它没有自己的this,它只会从自己的作用域链的上一层继承this。
箭头函数没有自己的this,它会捕获自己在定义时(注意,是定义时,不是调用时)所处的外层执行环境的this,并继承这个this值。所以,箭头函数中this的指向在它被定义的时候就已经确定了,之后永远不会改变。
来看个例子:
var id = 'Global';
function fun1() {
// setTimeout中使用普通函数
setTimeout(function(){
console.log(this.id);
}, 2000);
}
function fun2() {
// setTimeout中使用箭头函数
setTimeout(() => {
console.log(this.id);
}, 2000)
}
fun1.call({id: 'Obj'}); // 'Global'
fun2.call({id: 'Obj'}); // 'Obj'
上面这个例子,函数fun1中的setTimeout中使用普通函数,2秒后函数执行时,这时函数其实是在全局作用域执行的,所以this指向Window对象,this.id就指向全局变量id,所以输出'Global'。
但是函数fun2中的setTimeout中使用的是箭头函数,这个箭头函数的this在定义时就确定了,它继承了它外层fun2的执行环境中的this,而fun2调用时this被call方法改变到了对象{id: 'Obj'}中,所以输出'Obj'。
var id = 'GLOBAL';
var obj = {
id: 'OBJ',
a: function(){
console.log(this.id);
},
b: () => {
console.log(this.id);
}
};
obj.a(); // 'OBJ'
obj.b(); // 'GLOBAL'
上面这个例子,对象obj的方法a使用普通函数定义的,普通函数作为对象的方法调用时,this指向它所属的对象。所以,this.id就是obj.id,所以输出'OBJ'。
但是方法b是使用箭头函数定义的,箭头函数中的this实际是继承的它定义时所处的全局执行环境中的this,所以指向Window对象,所以输出'GLOBAL'。(这里要注意,定义对象的大括号{}是无法形成一个单独的执行环境的,它依旧是处于全局执行环境中!! )
3、箭头函数继承而来的this指向永远不变(重要!!深入理解!!)
上面的例子,就完全可以说明箭头函数继承而来的this指向永远不变。对象obj的方法b是使用箭头函数定义的,这个函数中的this就永远指向它定义时所处的全局执行环境中的this,即便这个函数是作为对象obj的方法调用,this依旧指向Window对象。
4、.call()/.apply()/.bind()无法改变箭头函数中this的指向
.call()/.apply()/.bind()方法可以用来动态修改函数执行时this的指向,但由于箭头函数的this定义时就已经确定且永远不会改变。所以使用这些方法永远也改变不了箭头函数this的指向,虽然这么做代码不会报错。
再来看另一个例子:
var id = 'Global';
// 箭头函数定义在全局作用域
let fun1 = () => {
console.log(this.id)
};
fun1(); // 'Global'
// this的指向不会改变,永远指向Window对象
fun1.call({id: 'Obj'}); // 'Global'
fun1.apply({id: 'Obj'}); // 'Global'
fun1.bind({id: 'Obj'})(); // 'Global'
5、箭头函数不能作为构造函数使用
我们先了解一下构造函数的new都做了些什么?简单来说,分为四步:
① JS内部首先会先生成一个对象;
② 再把函数中的this指向该对象;
③ 然后执行构造函数中的语句;
④ 最终返回该对象实例。
但是!!因为箭头函数没有自己的this,它的this其实是继承了外层执行环境中的this,且this指向永远不会随在哪里调用、被谁调用而改变,所以箭头函数不能作为构造函数使用,或者说构造函数不能定义成箭头函数,否则用new调用时会报错!
let Fun = (name, age) => {
this.name = name;
this.age = age;
};
// 报错
let p = new Fun('cao', 24);
6、箭头函数没有自己的arguments
箭头函数没有自己的arguments对象。在箭头函数中访问arguments实际上获得的是外层局部(函数)执行环境中的值。
// 例子一
let fun = (val) => {
console.log(val); // 111
// 下面一行会报错
// Uncaught ReferenceError: arguments is not defined
// 因为外层全局环境没有arguments对象
console.log(arguments);
};
fun(111);
// 例子二
function outer(val1, val2) {
let argOut = arguments;
console.log(argOut); // ①
let fun = () => {
let argIn = arguments;
console.log(argIn); // ②
console.log(argOut === argIn); // ③
};
fun();
}
outer(111, 222);
上面例子二,①②③处的输出结果如下:
很明显,普通函数outer内部的箭头函数fun中的arguments对象,其实是沿作用域链向上访问的外层outer函数的arguments对象。
可以在箭头函数中使用rest参数代替arguments对象,来访问箭头函数的参数列表!!
7、箭头函数没有原型prototype
let sayHi = () => {
console.log('Hello World !')
};
console.log(sayHi.prototype); // undefined
8、箭头函数不能用作Generator函数,不能使用yeild关键字
3.this 指向
1.在全局作用域中
=>this -> window
<script>
console.log(this); //this->window
</script>
2.在普通函数中
=>this取决于谁调用,谁调用我,this就指向谁,跟如何定义无关
var obj = {
fn1:function() {
console.log(this);
},
fn2:function(){
fn3()
}
}
function fn3() {
console.log(this);
}
fn3();//this->window
obj.fn1();//this->obj
obj.fn2();//this->window
3.箭头函数中的this
箭头函数没有自己的this,箭头函数的this就是上下文中定义的this,因为箭头函数没有自己的this所以不能用做构造函数。
var div = document.querySelector('div');
var o={
a:function(){
var arr=[1];
//就是定义所在对象中的this
//这里的this—>o
arr.forEach(item=>{
//所以this -> o
console.log(this);
})
},
//这里的this指向window o是定义在window中的对象
b:()=>{
console.log(this);
},
c:function() {
console.log(this);
}
}
div.addEventListener('click',item=>{
console.log(this);//this->window 这里的this就是定义上文window环境中的this
});
o.a(); //this->o
o.b();//this->window
o.c();//this->o 普通函数谁调用就指向谁
4.事件绑定中的this
事件源.onclik = function(){ } //this -> 事件源
事件源.addEventListener(function(){ }) //this->事件源
var div = document.querySelector('div');
div.addEventListener('click',function() {
console.log(this); //this->div
});
div.onclick = function() {
console.log(this) //this->div
}
5.定时器中的this
定时器中的this->window,因为定时器中采用回调函数作为处理函数,而回调函数的this->window
setInterval(function() {
console.log(this); //this->window
},500)
setTimeout(function() {
console.log(this); //this->window
},500)
6.构造函数中的this
构造函数配合new使用, 而new关键字会将构造函数中的this指向实例化对象,所以构造函数中的this->实例化对象
new关键字会在内部发生什么
//第一行,创建一个空对象obj。
var obj ={};
//第二行,将这个空对象的__proto__成员指向了构造函数对象的prototype成员对象.
obj.__proto__ = CO.prototype;
//第三行,将构造函数的作用域赋给新对象,因此CA函数中的this指向新对象obj,然后再调用CO函数。于是我们就给obj对象赋值了一个成员变量p,这个成员变量的值是” I’min constructed object”。
CO.call(obj);
//第四行,返回新对象obj。
return obj;
function Person(name,age) {
this.name = name;
this.age = age;
}
var person1 = new Person();
person1.name = 'andy';
person1.age = 18;
console.log(person1);//Person {name: "andy", age: 18}
var person2 = new Person();
person2.name = 'huni';
person2.age = 20;
console.log(person2);// Person {name: "huni", age: 20
4.闭包
什么是闭包
闭包就是每次调用外层函数时,临时创建的函数作用域对象。
因为内层函数作用域链中包含外层函数的作用域对象,且内层函数被引用,导致内层函数不会被释放,同时它又保持着对父级作用域的引用,这个时候就形成了闭包。
所以闭包通常是在函数嵌套中形成的。
例如下面的代码,就形成了闭包:
function foo (){
var name = 'snail'
return function(){
console.log('my name is '+name)
}
}
var bar = foo();
bar();
复制代码
闭包并不是一个需要学习新的语法或模式才能使用的工具或技巧,它是基于词法作用域编写代码时自然产生的结果。你甚至不需要为了闭包而创建闭包,了解了闭包,你会发现,代码中闭包随处可见。
了解闭包是为了可以根据自己的意愿来识别和影响闭包的使用。接下来我们看一下闭包常见的应用场景。
应用场景
实现块级作用域
首先我们来看这样一段代码:
function foo(){
var result = [];
for(var i = 0;i<10;i++){
result[i] = function(){
console.log(i)
}
}
return result;
}
var result = foo();
result[0](); // 10
result[1](); // 10
复制代码
可以看到,每个函数并不像我们期待的那样 result[0]() 打印 0,result[1]() 打印 1,以此类推。
因为 var 声明的 i 不只是属于当前的每一次循环,甚至不只是属于当前的 for 循环,因为没有块级作用域,变量 i 被提升到了函数 foo 的作用域中。所以每个函数的作用域链中都保存着同一个变量 i,而当我们执行数组中的子函数时,此时 foo 内部的循环已经结束,此时 i = 10,所以每个函数调用都会打印 10。
接下来我们对 for 循环内部添加一层即时函数(又叫立即执行函数 IIFE),形成一个新的闭包环境,这样即时函数内部就保存了本次循环的 i,所以再次执行数组中子函数时,结果就像我们期望的那样 result[0]() 打印 0,result[1]() 打印 1 ...
function foo(){
var result = [];
for(var i = 0;i<10;i++){
(function(i){
result[i] = function(){
console.log(i)
}
})(i)
}
return result;
}
var result = foo();
result[0](); // 0
result[1](); // 1
复制代码
当然,ES6 中引入 let 声明变量方式,让 JavaScript 拥有了块级作用域,可以更方便的解决这样的一个问题。
保存内部状态
首先我们来看这样一段代码:
function cacheCalc(){
var cache = new Map()
return function (i){
if(!cache.has(i)) cache.set(i,i*10)
return cache.get(i)
}
}
var calc = cacheCalc()
console.log(calc(2)) // 20
复制代码
可以看到,函数内部会使用 Map 保存已经计算过的结果(当然也可以是其他的数据结构),只有当输入数字没有被计算过时,才会计算,否则会返回之前的计算结果,这样就会避免重复计算。
而这样的技巧在 Vue3源码 中同样有使用到。代码地址
这里我在阅读源码的过程中加了一些注释,导致截图中代码行号和源文件中的不一致,但是代码并未进行任何修改。
这里的 compileToFunction 函数会将我们编写的模板进行编译生成 render 函数,而为了避免重复编译,这里在内部创建了一个 compileCache 对象保存编译过的数据。
函数柯里化
首先说一下什么是函数柯里化?
柯里化是把接收多个参数的函数变成接收单一参数(最初函数的第一个参数)的函数,并且返回接收余下的参数且返回结果的新函数。
翻译成人话就是可以将一个接受多个参数的函数分解成多个接收单个参数的函数的技术,直到接收的参数满足了原来所需的数量后,才执行原函数的逻辑。
例如一个非常经典的面试题 => 实现 add(x)(y)(z) = x+y+z 中就用到了函数柯里化。代码如下:
function add(x){
return function(y){
return function(z){
return x+y+z
}
}
}
console.log(add(1)(2)(3)) // 6
复制代码
再比如我们有一个函数 foo,可以将输入的数字保留两位小数。此时我们需要一个函数,可以把输入数字保留两位小数并每隔三位添加一个逗号,这个时候就可以把函数 foo 引入进来,并在之前结果的基础上添加每隔三位添加逗号的功能。
模块模式
首先我们来看这样一段代码:
function create(){
var name = 'snail',
hobby = ['eat','sleep','codeing']
function say(){
console.log('my name is '+name+'.')
}
function showHobby(){
console.log(name+' like '+hobby.join(',')+'!')
}
return {
say,
showHobby
}
}
var instance = create();
instance.say(); // my name is snail.
instance.showHobby(); // snail like eat,sleep,codeing!
复制代码
这个模式在 JavaScript 被称为模块。这里我们调用了 create 函数创建了一个模块实例,实例中含有对内部函数的引用,这样保证了内部数据变量是隐藏和私有状态,而返回值则可以看做是模块暴露出的 API。当然这里也可以直接返回方法作为模块的公共 API,·就像 JQuery 中返回的 $。
缺点
因为闭包会携带包含它的函数的作用域,所以哪怕外部函数执行完成,因为内部函数保存了外部函数中变量的引用,所以外部函数依然不会被释放,所以过度使用闭包会造成内存占用过多。
作者:前端_奔跑的蜗牛
链接:juejin.cn/post/705420…
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
5.JQ查找兄弟节点
一、jQuery的父节点查找方法
$(selector).parent(selector):获取父节点
$(selector).parentNode:以node[]的形式存放父节点,如果没有父节点,则返回空数组
$(selector).parents(selector):获取祖先元素
二、jQuery的兄弟节点查找方法
$(selector).prev() / $(selector).previousSibling():获取上一个兄弟节点
$(selector).prevAll():获取之前所用的兄弟节点
$(selector).next() / $(selector).nextSibling():获取下一个兄弟节点
$(selector).nextAll():获取之后所有的兄弟节点
$(selector).siblings():获取所有的兄弟节点
三、jQuery的子节点查找方法
$(selector).children():获取所有直接子节点
$(selector).childNodes:以node[]的形式存放子节点,如果没有子节点,则返回空数组
$(selector).firstChild:获取第一个子节点
$(selector).lastChild:获取最后一个子节点
$(selector).contents():获取包含的所有内容,包括空文本
$(selector).removeChild(selector):删除并返回指定的子节点
$$(selector).replaceChild(selector):替换并返回指定的子节点
jquery查找子节点的方法总结
通过jquery强大的选择器功能,你可以随意的用jquery选中你想要的那个元素,jquery查找子节点的方法很多,只要掌握了jquery选择器的使用,jquery查找子节点都不是难事
jquery查找子节点的方法有很多,重点是要掌握 jquery 对象选择器的使用,我们就jquery查找节点这一方面给出,jquey查找子节点的各种方法,首先我们要选择父节点,比如是一个 id 为 test 的 div元素,我们这样选中,$('#test'),我们要查找这个div下的一个class为demo的span元素,有一下几种方法
1、使用筛选条件
$('#test span.demo')
2、使用find()函数
$('#test').find('span.demo')
3、使用children()函数
$('#test').children('span.demo')
6.路由 如何监听hash变化
我们在使用 Vue 或者 React 等前端渲染时,通常会有 hash 路由和 history 路由两种路由方式。
- hash 路由:监听 url 中 hash 的变化,然后渲染不同的内容,这种路由不向服务器发送请求,不需要服务端的支持;
- history 路由:监听 url 中的路径变化,需要客户端和服务端共同的支持;
我们一步步实现这两种路由,来深入理解下底层的实现原理。我们主要实现以下几个简单的功能:
- 监听路由的变化,当路由发生变化时,可以作出动作;
- 可以前进或者后退;
- 可以配置路由;
1. hash 路由
当页面中的 hash 发生变化时,会触发hashchange事件,因此我们可以监听这个事件,来判断路由是否发生了变化。
window.addEventListener(
'hashchange',
function (event) {
const oldURL = event.oldURL; // 上一个URL
const newURL = event.newURL; // 当前的URL
console.log(newURL, oldURL);
},
false
);
1.1 实现的过程
对 oldURL 和 newURL 进行拆分后,就能获取到更详细的 hash 值。我们这里从创建一个 HashRouter 的 class 开始一步步写起:
class HashRouter {
currentUrl = ''; // 当前的URL
handlers = {};
getHashPath(url) {
const index = url.indexOf('#');
if (index >= 0) {
return url.slice(index + 1);
}
return '/';
}
}
事件hashchange只会在 hash 发生变化时才能触发,而第一次进入到页面时并不会触发这个事件,因此我们还需要监听load事件。这里要注意的是,两个事件的 event 是不一样的:hashchange 事件中的 event 对象有 oldURL 和 newURL 两个属性,但 load 事件中的 event 没有这两个属性,不过我们可以通过 location.hash 来获取到当前的 hash 路由:
class HashRouter {
currentUrl = ''; // 当前的URL
handlers = {};
constructor() {
this.refresh = this.refresh.bind(this);
window.addEventListener('load', this.refresh, false);
window.addEventListener('hashchange', this.refresh, false);
}
getHashPath(url) {
const index = url.indexOf('#');
if (index >= 0) {
return url.slice(index + 1);
}
return '/';
}
refresh(event) {
let curURL = '',
oldURL = null;
if (event.newURL) {
oldURL = this.getHashPath(event.oldURL || '');
curURL = this.getHashPath(event.newURL || '');
} else {
curURL = this.getHashPath(window.location.hash);
}
this.currentUrl = curURL;
}
}
到这里已经可以实现获取当前的 hash 路由,但路由发生变化时,我们的页面应该进行切换,因此我们需要监听这个变化:
class HashRouter {
currentUrl = ''; // 当前的URL
handlers = {};
// 暂时省略上面的代码
refresh(event) {
// 当hash路由发生变化时,则触发change事件
this.emit('change', curURL, oldURL);
}
on(evName, listener) {
this.handlers[evName] = listener;
}
emit(evName, ...args) {
const handler = this.handlers[evName];
if (handler) {
handler(...args);
}
}
}
const router = new HashRouter();
rouer.on('change', (curUrl, lastUrl) => {
console.log('当前的hash:', curUrl);
console.log('上一个hash:', lastUrl);
});
1.2 调用的方式
到这里,我们把基本的功能已经完成了。来配合一个例子就更形象了:
// 先定义几个路由
const routes = [
{
path: '/',
name: 'home',
component: <Home />,
},
{
path: '/about',
name: 'about',
component: <About />,
},
{
path: '*',
name: '404',
component: <NotFound404 />,
},
];
const router = new HashRouter();
// 监听change事件
router.on('change', (currentUrl, lastUrl) => {
let route = null;
// 匹配路由
for (let i = 0, len = routes.length; i < len; i++) {
const item = routes[i];
if (currentUrl === item.path) {
route = item;
break;
}
}
// 若没有匹配到,则使用最后一个路由
if (!route) {
route = routes[routes.length - 1];
}
// 渲染当前的组件
ReactDOM.render(route.component, document.getElementById('app'));
});
查看【hash 路由的样例】。
2. history 路由
在 history 路由中,我们一定会使用window.history中的方法,常见的操作有:
- back():后退到上一个路由;
- forward():前进到下一个路由,如果有的话;
- go(number):进入到任意一个路由,正数为前进,负数为后退;
- pushState(obj, title, url):前进到指定的 URL,不刷新页面;
- replaceState(obj, title, url):用 url 替换当前的路由,不刷新页面;
调用这几种方式时,都会只是修改了当前页面的 URL,页面的内容没有任何的变化。但前 3 个方法只是路由历史记录的前进或者后退,无法跳转到指定的 URL;而pushState和replaceState可以跳转到指定的 URL。如果有面试官问起这个问题“如何仅修改页面的 URL,而不发送请求”,那么答案就是这 5 种方法。
如果服务端没有新更新的 url 时,一刷新浏览器就会报错,因为刷新浏览器后,是真实地向服务器发送了一个 http 的网页请求。因此若要使用 history 路由,需要服务端的支持。
2.1 应用的场景
pushState 和 replaceState 两个方法跟 location.href 和 location.replace 两个方法有什么区别呢?应用的场景有哪些呢?
- location.href 和 location.replace 切换时要向服务器发送请求,而 pushState 和 replace 仅修改 url,除非主动发起请求;
- 仅切换 url 而不发送请求的特性,可以在前端渲染中使用,例如首页是服务端渲染,二级页面采用前端渲染;
- 可以添加路由切换的动画;
- 在浏览器中使用类似抖音的这种场景时,用户滑动切换视频时,可以静默修改对应的 URL,当用户刷新页面时,还能停留在当前视频。
2.2 无法监听路由的变化
当我们用 history 的路由时,必然要能监听到路由的变化才行。全局有个popstate事件,别看这个事件名称中有个 state 关键词,但pushState和replaceState被调用时,是不会触发触发 popstate 事件的,只有上面列举的前 3 个方法会触发。可以点击【popState 不会触发 popstate 事件】查看。
针对这种情况,我们可以使用window.dispatchEvent添加事件:
const listener = function (type) {
var orig = history[type];
return function () {
var rv = orig.apply(this, arguments);
var e = new Event(type);
e.arguments = arguments;
window.dispatchEvent(e);
return rv;
};
};
window.history.pushState = listener('pushState');
window.history.replaceState = listener('replaceState');
然后就可以添加对这两个方法的监听了:
window.addEventListener('pushState', this.refresh, false);
window.addEventListener('replaceState', this.refresh, false);
2.3 完整的代码
完整的代码如下:
class HistoryRouter {
currentUrl = '';
handlers = {};
constructor() {
this.refresh = this.refresh.bind(this);
this.addStateListener();
window.addEventListener('load', this.refresh, false);
window.addEventListener('popstate', this.refresh, false);
window.addEventListener('pushState', this.refresh, false);
window.addEventListener('replaceState', this.refresh, false);
}
addStateListener() {
const listener = function (type) {
var orig = history[type];
return function () {
var rv = orig.apply(this, arguments);
var e = new Event(type);
e.arguments = arguments;
window.dispatchEvent(e);
return rv;
};
};
window.history.pushState = listener('pushState');
window.history.replaceState = listener('replaceState');
}
refresh(event) {
this.currentUrl = location.pathname;
this.emit('change', location.pathname);
document.querySelector('#app span').innerHTML = location.pathname;
}
on(evName, listener) {
this.handlers[evName] = listener;
}
emit(evName, ...args) {
const handler = this.handlers[evName];
if (handler) {
handler(...args);
}
}
}
const router = new HistoryRouter();
router.on('change', function (curUrl) {
console.log(curUrl);
});
使用方法与上面的 hash 路由一样,这里就不多赘述了。点击查看【history 路由的实现应用】
我们腾讯新闻中的抢金达人活动,就是采用的这种路由方式,页面的首次渲染采用服务端直出,二级跳转页面,使用前端 history 路由的前端渲染方式。
7.vue的父子传参
Vue2父子传参:props
首先在父组件中引入子组件,然后以属性的方式将数据传递给子组件
父组件:
<template>
<div class="home">
<!-- 在子组件中使用 :变量名=value 的方式向子组件传递数据,子组件通过 props 接收-->
<HelloWorld :msg="fatchData" ref="childEl"/>
</div>
</template>
<script>
// @ is an alias to /src
import HelloWorld from '@/components/HelloWorld.vue'
export default {
name: 'Home',
components: {
HelloWorld
},
data () {
return {
fatchData: '我是父组件通过props传递给子组件的文字'
}
}
}
</script>
然后在子组件中使用props接收,props里定义的名字要和父组件定义的一致
子组件:
<template>
<div>
<span>{{ msg }}</span>
</div>
</template>
<script>
export default {
name: 'HelloWorld',
// 子组件通过使用 props 接收父组件传递过来的数据
props: {
msg: String
}
}
</script>
Vue2父子传参之父传子:$refs
在父组件中给子组件的标签上添加 ref 等于一个变量,然后通过使用 $refs 可以获取子组件的实例,以及调用子组件的方法和传递参数
父组件:
<template>
<div class="home">
<!-- 在子组件中使用 :变量名=value 的方式向子组件传递数据,子组件通过 props 接收-->
<HelloWorld :msg="fatchData" ref="childEl"/>
<div>
父组件
</div>
<div>
<button @click="changeChildMsg">父组件按钮</button>
</div>
</div>
</template>
<script>
import HelloWorld from '@/components/HelloWorld.vue'
export default {
name: 'Home',
components: {
HelloWorld
},
data () {
return {
fatchData: '我是父组件通过props传递给子组件的文字'
}
},
methods: {
// 点击父组件的按钮修改子组件中显示的文字
changeChildMsg () {
this.fatchData = '通过按钮修改了子组件中显示的问题'
// 父组件调用子组件的方法并传递参数
this.$refs.childEl.showText('我来自父组件')
}
}
}
</script>
然后在子组件中定义相同的方法名,在父组件使用 $refs 调用后触发在子组件中定义的同名方法
子组件:
<template>
<div class="hello">
<b>子组件</b>
<div>
<span>{{ msg }}</span>
</div>
<div>
<button>子组件按钮</button>
</div>
</div>
</template>
<script>
export default {
name: 'HelloWorld',
// 子组件通过使用 props 接收父组件传递过来的数据
props: {
msg: String
},
methods: {
// 这个方法由父组件通过 this.$refs.childEl.showText('我来自父组件') 调用触发
showText (text) {
alert(text)
}
}
}
</script>
Vue2父子传参之子传父:$emit
在子组件中我们也可以调用父组件的方法向父组件传递参数,通过$emit来实现
子组件:
<button @click="childClick">子组件按钮</button>
<script>
export default {
name: 'HelloWorld',
methods: {
// 子组件通过 $emit 调用父组件中的方法
childClick () {
this.$emit('setValueName', '我是通过子组件传递过来的')
}
}
}
</script>
然后在父组件中定义并绑定子组件传递的 setValueName 事件,事件名称要和子组件定义的名称一样
父组件:
<HelloWorld @setValueName="setValueName" />
<script>
import HelloWorld from '@/components/HelloWorld.vue'
export default {
name: 'Home',
components: {
HelloWorld
},
methods: {
// 该方法是由子组件触发的
setValueName (data) {
alert(data) //= > 我是通过子组件传递过来的
}
}
}
</script>
Vue2父子传参:parent/children
- 父组件通过
$children获取子组件的实例数组 - 子组件通过
$parent获取的父组件实例
父组件中可以存在多个子组件,所以this.$children获取到的是子组件的数组
父组件:
<HelloWorld />
<button @click="getSon">children/parent</button>
<script>
import HelloWorld from '@/components/HelloWorld.vue'
export default {
name: 'Home',
components: {
HelloWorld
},
data () {
return {
parentTitle: '我是父组件'
}
},
methods: {
// 子组件调用这个方法
parentHandle () {
console.log('我是父组件的方法')
},
// 通过 this.$children 获取子组件实例
getSon () {
console.log(this.$children)
console.log(this.$children[0].sonTitle) //= > 我是子组件
this.$children[0].sonHandle() //= > 我是子组件的方法
}
}
}
</script>
子组件:
<button @click="getParent">获取父组件的方法和值</button>
<script>
export default {
name: 'HelloWorld',
data () {
return {
sonTitle: '我是子组件'
}
},
methods: {
// 父组件通过 this.$children 来调用
sonHandle () {
console.log('我是子组件的方法')
},
// 调用父组件的方法和获取父组件的值
getParent () {
console.log(this.$parent)
console.log(this.$parent.parentTitle) //= > 我是父组件
this.$parent.parentHandle() //= > 我是父组件的方法
}
}
}
</script>
Vue2兄弟传参:bus.js
首先新建 bus.js 文件,初始化如下代码:
import Vue from 'vue'
export default new Vue()
然后在需要通信的组件中都引入该 bus 文件,其中一个文件用来发送,一个文件监听接收。派发事件使用 bus.$emit。
下面组件派发了一个叫setYoungerBrotherData的事件
<template>
<div>
哥哥组件:<button @click="setYoungerBrotherData">给弟弟传参</button>
</div>
</template>
<script>
import bus from '../assets/bus'
export default {
methods: {
setYoungerBrotherData () {
// 通过 bus.$emit 派发一个事件
bus.$emit('setYoungerBrotherData', '给弟弟传参')
}
}
}
</script>
在另一个页面中使用 bus.$on('setYoungerBrotherData',()=>{}) 监听
<template>
<div>弟弟组件:{{ msg }}</div>
</template>
<script>
import bus from '../assets/bus'
export default {
data () {
return {
msg: ''
}
},
mounted () {
// 通过 bus.$on 监听兄弟组件派发的方法
bus.$on('setYoungerBrotherData', (res) => {
this.msg = res
})
}
}
</script>
Vue2跨级传参:provide/inject
provide和inject是vue生命周期上的两个函数,这对选项需要一起使用,以允许一个祖先组件向其所有子孙后代注入一个依赖,不论组件层次有多深,并在其上下游关系成立的时间里始终生效。
提示:provide 和 inject 绑定并不是可响应的。这是刻意为之的。然而,如果你传入了一个可监听的对象,那么其对象的 property 还是可响应的。
祖先组件:
<script>
export default {
name: 'Home',
// 通过 provide 提供的数据可以在该组件层次之下的任何组件使用
provide () {
return {
// 可以传递普通字符串
provideName: '祖先',
// 也可以传递一个异步方法
getOrderInfo: () => {
return this.getOrderList()
}
}
},
methods: {
// 传递一个异步方法获取数据,用来模拟接口请求
getOrderList () {
return new Promise((resolve, reject) => {
// 倒计时两秒模拟请求延迟
setTimeout(() => {
resolve({
code: 'WX15485613548',
name: '农夫安装工单'
})
}, 2000)
})
}
}
}
</script>
孙子组件:
<template>
<div>
{{ bar }}
<button @click="getOrder">异步获取数据</button>
</div>
</template>
<script>
export default {
// 使用 inject 接收祖先生成的数据
inject: ['provideName', 'getOrderInfo'],
data () {
return {
// inject 接收的数据可以作为数据的入口
bar: this.provideName
}
},
mounted () {
console.log(this.provideName) //= >祖先
},
methods: {
getOrder () {
// 调用的是父组件的方法,延迟两秒获取数据
this.getOrderInfo().then(res => {
console.log(res) //= > {code: "WX15485613548", name: "农夫安装工单"}
})
}
}
}
</script>
使用 provide/inject的好处是父组件不需要知道是哪个自组件使用了我的数据,子组件也不需要关心数据从何而来
总结
- 父子通信:父向子传递数据通过
props,子向父传递数据通过$emit事件,父链子链使用$parent/$children,直接访问子组件实例使用$refs - 兄弟通信:
bus,Vuex - 跨级通信:
bus,Vuex,provide/inject
8.Nexttick
使用场景:
在我们开发项目的时候,总会碰到一些场景:当我们使用vue操作更新dom后,需要对新的dom做一些操作时,但是这个时候,我们往往会获取不到跟新后的DOM.因为这个时候,dom还没有重新渲染,所以我们就要使用vm.$nextTick方法。
用法:
nextTick接受一个回调函数作为参数,它的作用将回调延迟到下次DOM跟新周期之后执行。
methods:{
example:function(){
//修改数据
this.message='changed'
//此时dom还没有跟新,不能获取新的数据
this.$nextTick(function(){
//dom现在跟新了
//可以获取新的dom数据,执行操作
this.doSomeThing()
})
}
}
复制代码
小思考:
在用法中,我们发现,什么是下次DOM更新周期之后执行,具体是什么时候,所以,我们要明白什么是DOM更新周期。 在Vue当中,当视图状态发生变化时,watcher会得到通知,然后触发虚拟DOM的渲染流程,渲染这个操作不是同步的,是异步。Vue中有一个队列,每当渲染时,会将watcher推送这个队列,在下一次事件循环中,让watcher触发渲染流程。
为什么Vue使用异步更新队列?
简单来说,就是提升性能,提升效率。 我们知道Vue2.0使用虚拟dom来进行渲染,变化侦测的通知只发送到组件上,组件上的任意一个变化都会通知到一个watcher上,然后虚拟DOM会对整个组件进行比对(diff算法,以后有时间我会详细研究一下),然后更新DOM.如果在同一轮事件循环中有两个数据发生变化了,那么组件的watcher会收到两次通知,从而进行两次渲染(同步跟新也是两次渲染),事实上我们并不需要渲染这么多次,只需要等所有状态都修改完毕后,一次性将整个组件的DOM渲染到最新即可。
如何解决一次事件循环组件多次状态改变只需要一次渲染更新?
其实很简单,就是将收到的watcher实例加入队列里缓存起来,并且再添加队列之前检查这个队列是否已存在相同watcher。不存在时,才将watcher实例添加到队列中。然后再下一次事件循环中,Vue会让这个队列中的watcher触发渲染并清空队列。这样就保证一次事件循环组件多次状态改变只需要一次渲染更新。
什么是事件循环?
我们知道js是一门单线程非阻塞的脚本语言,意思是执行js代码时,只有一个主线程来处理所有任务。非阻塞是指当代码需要处理异步任务时,主线程会挂起(pending),当异步任务处理完毕,主线程根据一定的规则去执行回调。事实上,当任务执行完毕,js会将这个事件加入一个队列(事件队列)。被放入队列中的事件不会立刻执行其回调,而是当前执行栈中所有任务执行完毕后,主线程会去查找事件队列中是否有任务。
异步任务有两种类型,微任务和宏任务。不同类型的任务会被分配到不同的任务队列中。
执行栈中所有任务执行完毕后,主线程会去查找事件队列中是否有任务,如果存在,依次执行所有队列中的回调,只到为空。然后再去宏任务队列中取出一个事件,把对应的回调加入当前执行栈,当前执行栈中所有任务都执行完毕,检查微任务队列是否有事件。无线循环此过程,叫做事件循环。
常见的微任务
- Promise.then
- Object.observe
- MutationObserver
常见的宏任务
- setTimeout
- setInterval
- setImmediate
- UI交互事件
在我们使用vm.$nextTick中获取跟新后DOM时,一定要在更改数据的后面使用nextTick注册回调。
methods:{
example:function(){
//修改数据
this.message='changed'
//此时dom还没有跟新,不能获取新的数据
this.$nextTick(function(){
//dom现在跟新了
//可以获取新的dom数据,执行操作
this.doSomeThing()
})
}
}
复制代码
如果是先使用nextTick注册回调,然后修改数据,在微任务队列中先执行使用nextTick注册的回调,然后才执行跟新DOM的回调,所以回调中得不到新的DOM,因为还没有更新。
methods:{
example:function(){
//此时dom还没有跟新,不能获取新的数据
this.$nextTick(function(){
//dom没有跟新,不能获取新的dom
this.doSomeThing()
})
//修改数据
this.message='changed'
}
}
复制代码
我们知道,添加微任务队列中的任务执行机制要高于宏任务的执行机制(下面代码必须理解)
methods:{
example:function(){
//先试用setTimeout向宏任务中注册回调
setTimeout(()=>{
//现在DOM已经跟新了,可以获取最新DOM
})
//然后修改数据
this.message='changed'
}
}
复制代码
setTimeout属于宏任务,使用它注册回调会加入宏任务中,宏任务执行要比微任务晚,所以即便是先注册,也是先跟新DOM后执行setTineout中设置回调。
理解nextTick的作用后,我们以下来介绍实现原理
实现原理剖析:
由于nextTick会将回调添加到任务队列中延迟执行,所以在回调执行之前,如果反复使用nextTick,Vue并不会将回调添加到任务队列中,只会添加一个任务。Vue内部有一个列表来存储nextTick参数中提供的回调,当任务触发时,以此执行列表里的所有回调并清空列表,其代码如下(简易版):
const callbacks=[]
let pending=false
function flushCallBacks(){
pending=false
const copies=callbacks.slice(0)
callbacks.length=0
for(let i=0;i<copies.length;i++){
copies[i]()
}
}
let microTimeFun
const p=Promise.resolve()
microTimeFun=()=>{
p.then(flushCallBacks)
}
export function nextTick(cb,ctx){
callbacks.push(()=>{
if(cb){
cb.call(ctx)
}
})
if(!pending){
pending=true
microTimeFun()
}
}
复制代码
理解相关变量:
- callbacks:用来存储用户注册的回调函数(获得了更新后DOM所进行的操作)
- pending:用来标记是否向任务队列添加任务,pending为false,表示任务队列没有nextTIck任务,需要添加nextTick任务,当添加一个nextTick任务时,pending为ture,在回调执行之前还有nextTick时,并不会重复添加任务到任务队列,当回调函数开始执行时,pending为flase,进行新的一轮事件循环。
- flushCallbacks:就是我们所说的被注册在任务队列中的任务,当这个函数执行,callbacks中所有函数依次执行,然后清空callbacks,并重置pending为false,所以说,一轮事件循环中,flushCallbacks只会执行一次。
- microTimerFunc:它的作用就是使用Promise.then将flushCallbacks添加到微任务队列中。
下图给出nextTick内部注册流程和执行流程。
官方文档里面还有这么一句话,如果没有提供回调且支持Promise的环境下,则返回一个Promise。也就是说。可以这样使用nextTick
this.$nextTick().then(function(){
//dom跟新了
})
复制代码
要实现这个功能,只需要在nextTIck中判断,如果没有提供回调且当前支持Promise,那么返回Promise,并且在callbacks中添加一个函数,当这个函数执行时,执行Promise的resolve,即可,代码如下
function nextTick (cb, ctx) {
var _resolve;
callbacks.push(function () {
if (cb) {
cb.call(ctx);
} else if (_resolve) {
_resolve(ctx);
}
});
if (!pending) {
pending = true;
timerFunc();
}
if (!cb && typeof Promise !== 'undefined') {
return new Promise(function (resolve) {
_resolve = resolve;
})
}
}
复制代码
nextTick源码查看
到此,nextTick原理基本上已经讲完了。那我们现在可以看看真正vue中关于nextTick中的源码,大概我们都能理解的过来了,源码如下。
var timerFunc;
// The nextTick behavior leverages the microtask queue, which can be accessed
// via either native Promise.then or MutationObserver.
// MutationObserver has wider support, however it is seriously bugged in
// UIWebView in iOS >= 9.3.3 when triggered in touch event handlers. It
// completely stops working after triggering a few times... so, if native
// Promise is available, we will use it:
/* istanbul ignore next, $flow-disable-line */
if (typeof Promise !== 'undefined' && isNative(Promise)) {
var p = Promise.resolve();
timerFunc = function () {
p.then(flushCallbacks);
// In problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) { setTimeout(noop); }
};
isUsingMicroTask = true;
} else if (!isIE && typeof MutationObserver !== 'undefined' && (
isNative(MutationObserver) ||
// PhantomJS and iOS 7.x
MutationObserver.toString() === '[object MutationObserverConstructor]'
)) {
// Use MutationObserver where native Promise is not available,
// e.g. PhantomJS, iOS7, Android 4.4
// (#6466 MutationObserver is unreliable in IE11)
var counter = 1;
var observer = new MutationObserver(flushCallbacks);
var textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true
});
timerFunc = function () {
counter = (counter + 1) % 2;
textNode.data = String(counter);
};
isUsingMicroTask = true;
} else if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
// Fallback to setImmediate.
// Technically it leverages the (macro) task queue,
// but it is still a better choice than setTimeout.
timerFunc = function () {
setImmediate(flushCallbacks);
};
} else {
// Fallback to setTimeout.
timerFunc = function () {
setTimeout(flushCallbacks, 0);
};
}
function nextTick (cb, ctx) {
var _resolve;
callbacks.push(function () {
if (cb) {
try {
cb.call(ctx);
} catch (e) {
handleError(e, ctx, 'nextTick');
}
} else if (_resolve) {
_resolve(ctx);
}
});
if (!pending) {
pending = true;
timerFunc();
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(function (resolve) {
_resolve = resolve;
})
}
}
作者:前端六六丶
链接:juejin.cn/post/684490…
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
9.Keepalive
先来看一个项目中的需求
作为苦逼的前端开发者,我们无时无刻都要面对产品经理提的各种需求, 比如下图这个场景
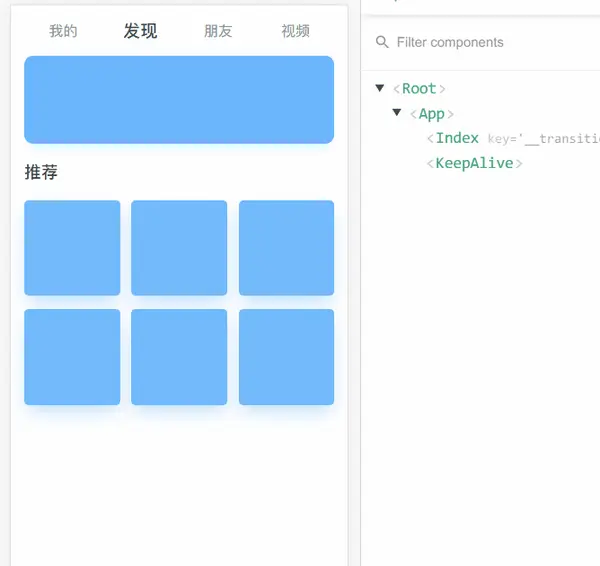
场景:
从首页的点击导航进入列表页,
列表页点击列表进入 该 数据详情页
从详情页返回,希望列表页缓存,不重新渲染数据,这样会提高用户体验。
分析一下
这样需求,如果是小程序的话,默认列表页就会缓存,因为小程序的运行环境是微信客户端,当我们打开一个页面会新建一个webview,
所有列表页和详情页是两个webview,当我们进入详情页,列表页webview,只是会在详情页webview下面,不会销毁。
以下是小程序运行环境:我们可以看到每个页面都有一个webview
但是但是,我们的项目是用vue开发的webapp,多个组件共用一个窗口,当我们切换路由时,切出路由组件会销毁,所有列表页进入详情页列表页会销毁,重新回到列表页,列表页组件会重新加载。
解决方案
- 睡服提需求的人,改个简单的需求
emm... ,看了看镜子中的自己,估计这辈子没办法从脸上得到任何的便利了,老老实实换个方案吧。
keep-alive
keep-alive是Vue提供的一个抽象组件,主要用于保留组件状态或避免重新渲染。
<keep-alive> 包裹动态组件时,会缓存不活动的组件实例,而不是销毁他们。
和<transition> 相似, <keep-alive> 是一个抽象组件,它自身不会渲染一个DOM元素,也不会出现在父组件链中。
但是 keep-alive 会把其包裹的所有组件都缓存起来。
em...怎么办呢,我们只是需要让列表页缓存啊.
分析一下
我们可以把需求拆分为2步
(1) 把需要缓存和不需要缓存的组件区分开,在组件的路由配置的元信息,meta中定义哪些需要缓存哪些不需要缓存
具体代码如下
1,定义两个出口 router-view
<keep-alive>
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive">
</router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive">
</router-view>
2,在router配置中定义哪些需要缓存哪些不需要缓存
new Router({
routes: [
{
path: '/',
name: 'index',
component: () => import('./views/keep-alive/index.vue')
},
{
path: '/list',
name: 'list',
component: () => import('./views/keep-alive/list.vue'),
meta: {
keepAlive: true //需要被缓存
}
},
{
path: '/detail',
name: 'detail',
component: () => import('./views/keep-alive/detail.vue')
}
]
})
(2),开始按需缓存组件
我们从官方文档提供的 api 入手,
keep-alive组件如果设置了 include ,就只有和 include 匹配的组件会被缓存,
所以思路就是,动态修改 include 数组来实现按需缓存。
<template>
<keep-alive :include="include">
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive">
</router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive">
</router-view>
</template>
<script>
export default {
name: "app",
data: () => ({
include: []
}),
watch: {
$route(to, from) {
//如果 要 to(进入) 的页面是需要 keepAlive 缓存的,把 name push 进 include数组
if (to.meta.keepAlive) {
!this.include.includes(to.name) && this.include.push(to.name);
}
}
}
};
</script>
此时我们发现,从详情页返回列表页,列表页真的不再刷新了
em...新的问题又出现了,由于 列表页被缓存了,这个时候我从首页,再点击进入某个列表,也不刷新了,完了,点击首页导航应该进入不同的列表页的. 也就是说,从首页进入列表组件不应该被缓存的。
解决一下,我们在定义路由是,在元信息中再加一个字段,这里是deepth字段,代表进入路由的层级,比如首页路由deepth是0.5,列表页是1,详情页是2
new Router({
routes: [
{
path: '/',
name: 'index',
component: () => import('./views/keep-alive/index.vue'),
meta: {
deepth: 0.5 // 定义路由的层级
}
},
{
path: '/list',
name: 'list',
component: () => import('./views/keep-alive/list.vue'),
meta: {
deepth: 1
keepAlive: true //需要被缓存
}
},
{
path: '/detail',
name: 'detail',
component: () => import('./views/keep-alive/detail.vue'),
meta: {
deepth: 2
}
}
]
})
然后在 app.vue中增加监听器,监听 我们进入路由的 方向
具体代码如下
<template>
<keep-alive :include="include">
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive">
</router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive">
</router-view>
</template>
<script>
export default {
name: "app",
data: () => ({
include: []
}),
watch: {
$route(to, from) {
//如果 要 to(进入) 的页面是需要 keepAlive 缓存的,把 name push 进 include数组
if (to.meta.keepAlive) {
!this.include.includes(to.name) && this.include.push(to.name);
}
//如果 要 form(离开) 的页面是 keepAlive缓存的,
//再根据 deepth 来判断是前进还是后退
//如果是后退
if (from.meta.keepAlive && to.meta.deepth < from.meta.deepth) {
var index = this.include.indexOf(from.name);
index !== -1 && this.include.splice(index, 1);
}
}
}
};
</script>
10.Http的缓存
前端缓存
前端缓存可分为两大类:http缓存和浏览器缓存。我们今天重点讲的是http缓存,所以关于浏览器缓存大家自行去查阅。下面这张图是前端缓存的一个大致知识点:
image
HTTP缓存
首先是解决困扰人们的老大难问题:
一、什么是HTTP缓存 ?
http缓存指的是: 当客户端向服务器请求资源时,会先抵达浏览器缓存,如果浏览器有“要请求资源”的副本,就可以直接从浏览器缓存中提取而不是从原始服务器中提取这个资源。
常见的http缓存只能缓存get请求响应的资源,对于其他类型的响应则无能为力,所以后续说的请求缓存都是指GET请求。
http缓存都是从第二次请求开始的。第一次请求资源时,服务器返回资源,并在respone header头中回传资源的缓存参数;第二次请求时,浏览器判断这些请求参数,命中强缓存就直接200,否则就把请求参数加到request header头中传给服务器,看是否命中协商缓存,命中则返回304,否则服务器会返回新的资源。
1、http缓存的分类:
根据是否需要重新向服务器发起请求来分类,可分为(强制缓存,协商缓存) 根据是否可以被单个或者多个用户使用来分类,可分为(私有缓存,共享缓存) 强制缓存如果生效,不需要再和服务器发生交互,而协商缓存不管是否生效,都需要与服务端发生交互。下面是强制缓存和协商缓存的一些对比:
image
1.1、强制缓存
强制缓存在缓存数据未失效的情况下(即Cache-Control的max-age没有过期或者Expires的缓存时间没有过期),那么就会直接使用浏览器的缓存数据,不会再向服务器发送任何请求。强制缓存生效时,http状态码为200。这种方式页面的加载速度是最快的,性能也是很好的,但是在这期间,如果服务器端的资源修改了,页面上是拿不到的,因为它不会再向服务器发请求了。这种情况就是我们在开发种经常遇到的,比如你修改了页面上的某个样式,在页面上刷新了但没有生效,因为走的是强缓存,所以Ctrl + F5一顿操作之后就好了。 跟强制缓存相关的header头属性有(Pragma/Cache-Control/Expires)
image
这个Pragma和Cache-Control共存时的优先级问题还有点异议,我在不同的文章里发现:有的说Pragma的优先级更高,有的说Cache-Control高。为了搞清楚这个问题,我决定动手操作一波,首先我用nodejs搭建后台服务器,目的是设置缓存参数,具体代码如下:
image
然后再浏览器上访问:http://localhost:8888
第一次访问时都是从后台返回的数据:
image
第二次访问时:
image
image
最终得出结论:
Pragma和Cache-control共存时,Pragma的优先级是比Cache-Control高的。
注意:
在chrome浏览器中返回的200状态会有两种情况:
1、from memory cache
(从内存中获取/一般缓存更新频率较高的js、图片、字体等资源)
2、from disk cache
(从磁盘中获取/一般缓存更新频率较低的js、css等资源)
这两种情况是chrome自身的一种缓存策略,这也是为什么chrome浏览器响应的快的原因。其他浏览返回的是已缓存状态,没有标识是从哪获取的缓存。
chrome浏览器:
image
Firefox浏览器:
image
1.2、协商缓存
当第一次请求时服务器返回的响应头中没有Cache-Control和Expires或者Cache-Control和Expires过期还或者它的属性设置为no-cache时(即不走强缓存),那么浏览器第二次请求时就会与服务器进行协商,与服务器端对比判断资源是否进行了修改更新。如果服务器端的资源没有修改,那么就会返回304状态码,告诉浏览器可以使用缓存中的数据,这样就减少了服务器的数据传输压力。如果数据有更新就会返回200状态码,服务器就会返回更新后的资源并且将缓存信息一起返回。跟协商缓存相关的header头属性有(ETag/If-Not-Match 、Last-Modified/If-Modified-Since)请求头和响应头需要成对出现
image
协商缓存的执行流程是这样的:当浏览器第一次向服务器发送请求时,会在响应头中返回协商缓存的头属性:ETag和Last-Modified,其中ETag返回的是一个hash值,Last-Modified返回的是GMT格式的最后修改时间。然后浏览器在第二次发送请求的时候,会在请求头中带上与ETag对应的If-Not-Match,其值就是响应头中返回的ETag的值,Last-Modified对应的If-Modified-Since。服务器在接收到这两个参数后会做比较,如果返回的是304状态码,则说明请求的资源没有修改,浏览器可以直接在缓存中取数据,否则,服务器会直接返回数据。
image
image
注意:
ETag/If-Not-Match是在HTTP/1.1出现的,主要是解决以下问题:
(1)、Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
(2)、如果某些文件被修改了,但是内容并没有任何变化,而Last-Modified却改变了,导致文件没法使用缓存
(3)、有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
1.3、私有缓存(浏览器级缓存)
私有缓存只能用于单独的用户:Cache-Control: Private
1.4、共享缓存(代理级缓存)
共享缓存可以被多个用户使用: Cache-Control: Public
二、为什么要使用HTTP缓存 ?
根据上面的学习可发现使用缓存的好处主要有以下几点:
- 减少了冗余的数据传输,节省了网费。
- 缓解了服务器的压力, 大大提高了网站的性能
- 加快了客户端加载网页的速度
三、如何使用HTTP缓存 ?
一般需要缓存的资源有html页面和其他静态资源:
1、html页面缓存的设置主要是在标签中嵌入标签,这种方式只对页面有效,对页面上的资源无效
1.1、html页面禁用缓存的设置如下:
// 仅有IE浏览器才识别的标签,不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求
// 其他主流浏览器识别的标签
// 仅有IE浏览器才识别的标签,该方式仅仅作为知会IE缓存时间的标记,你并不能在请求或响应报文中找到Expires字段
1.2、html设置缓存如下:
// 其他主流浏览器识别的标签
// 仅有IE浏览器才识别的标签
2、静态资源的缓存一般是在web服务器上配置的,常用的web服务器有:nginx、apache。具体的配置这里不做详细介绍,大家自行查阅。
3、不想使用缓存的几种方式:
3.1、Ctrl + F5强制刷新,都会直接向服务器提取数据。
3.2、按F5刷新或浏览器的刷新按钮,默认加上Cache-Control:max-age=0,即会走协商缓存。
3.2、在IE浏览器下不想使用缓存的做法:打开IE,点击工具栏上的工具->Internet选项->常规->浏览历史记录 设置. 选择“从不”,然后保存。最后点击“删除”把Internet临时文件都删掉 (IE缓存的文件就是Internet临时文件)。
3.3、还有就是上面1、2中禁用缓存的做法
3.4、对于其他浏览器也都有清除缓存的办法
四、HTTP缓存的几个注意点
1、强缓存情况下,只要缓存还没过期,就会直接从缓存中取数据,就算服务器端有数据变化,也不会从服务器端获取了,这样就无法获取到修改后的数据。决解的办法有:在修改后的资源加上随机数,确保不会从缓存中取。
例如:
www.kimshare.club/kim/common.…
www.kimshare.club/kim/common.…
2、尽量减少304的请求,因为我们知道,协商缓存每次都会与后台服务器进行交互,所以性能上不是很好。从性能上来看尽量多使用强缓存。
3、在Firefox浏览器下,使用Cache-Control: no-cache 是不生效的,其识别的是no-store。这样能达到其他浏览器使用Cache-Control: no-cache的效果。所以为了兼容Firefox浏览器,经常会写成Cache-Control: no-cache,no-store。
4、与缓存相关的几个header属性有:Vary、Date/Age。
Vary:
vary本身是“变化”的意思,而在http报文中更趋于是“vary from”(与。。。不同)的含义,它表示服务端会以什么基准字段来区分、筛选缓存版本。
在服务端有着这么一个地址,如果是IE用户则返回针对IE开发的内容,否则返回另一个主流浏览器版本的内容。
格式:Vary: User-Agent
知会代理服务器需要以 User-Agent 这个请求首部字段来区别缓存版本,防止传递给客户端的缓存不正确。
Date/Age:
响应报文中的 Date 和 Age 字段:区分其收到的资源是否命中了代理服务器的缓存。
Date 理所当然是原服务器发送该资源响应报文的时间(GMT格式),如果你发现 Date 的时间与“当前时间”差别较大,或者连续F5刷新发现 Date 的值都没变化,则说明你当前请求是命中了代理服务器的缓存。
Age 也是响应报文中的首部字段,它表示该文件在代理服务器中存在的时间(秒),如文件被修改或替换,Age会重新由0开始累计。
浏览器缓存
下面说说最常用到的浏览器缓存有:cookie、sessionStorage、localStorage这三者的主要特征如下:
image
课程总结
1、对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行协商缓存策略。
2、对于协商缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
下图是浏览器首次和再次发送http请求的执行流程图:
image
作者:前端进阶体验
链接:www.jianshu.com/p/227cee9c8…
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
