

这是我参与「第五届青训营 」伴学笔记创作活动的第 36 天 本节课将介绍函数冷启动发生的背景、ByteFaaS 的冷启动优化过程和一些最佳案例,以及结合异步执行的一些需求推出的异步模式,分享在日常开发中如何优化自身服务的冷启动时间,提高服务的性能和稳定性,帮助大家对异步模式的架构和使用场景有一定的了解。
FaaS Cold Start Introduction
Cold Start Introduction
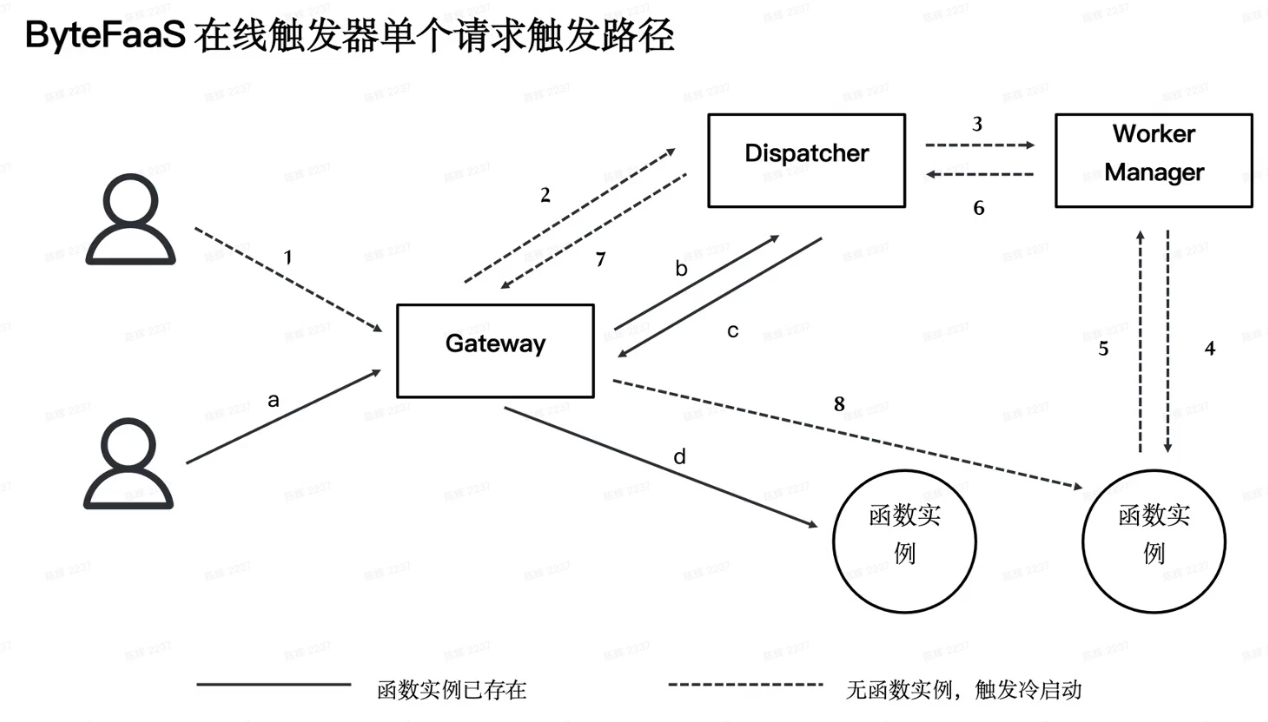
What happened during instance start
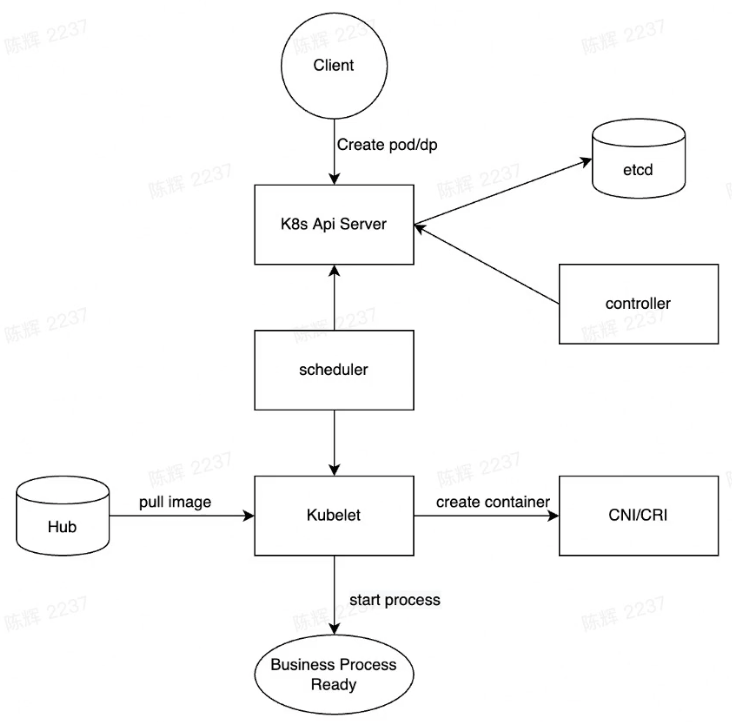
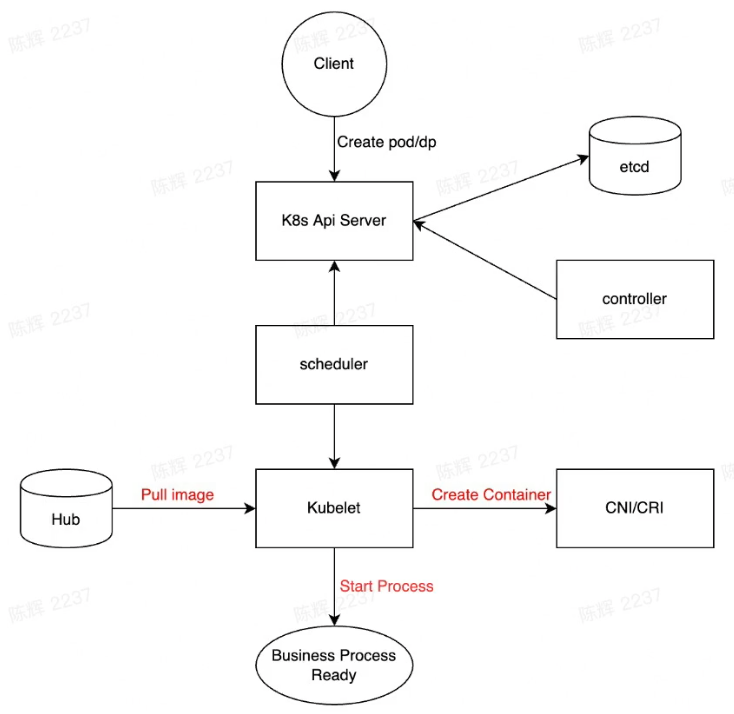
- Call k8s api server to scale dp/ create pod
- Kubernetes Schedule process and finally to Kubelet
- Create pod sandbox/network, pull image, mount volume.
- Start Container and Run business process
- health check and service registration
Time-Consuming Part
- Image Pull
- Image pulling time - Seconds to Minutes level
- Image heterogeneous
- faas High-density deployment, autoscale often
- kubelet image pulling concurrency limit, avoid multiple I/O write
- Container created Time
- Sandbox/volume mount - seconds level
- Process Starting slowly
- Some runtime like nodejs start times is seconds level
Cold Start Introduction

100ms is our goal
[Response Times: The 3 Important Limits](www.nngroup.com/articles/re… -3-important-limits/)
Cold Start Optimization in ByteFaaS
Image Code Split(pull image)
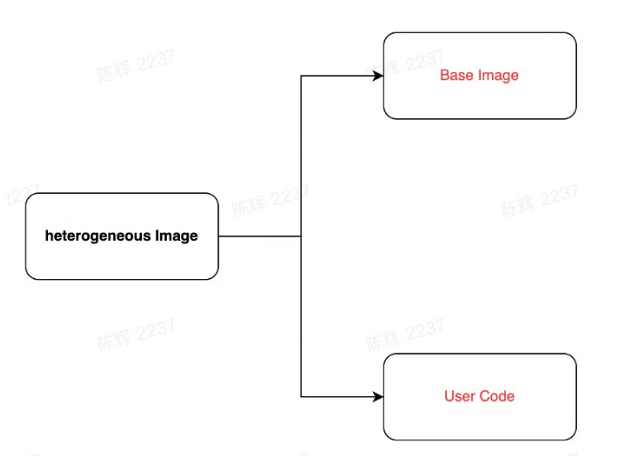
Optimize the Image Pull Time
- Base images
- Unify the baseimage for each runtime
- Lighten the size of baseimage
- Split baseimages and user code
- Store user code separately
- Pull code if needed
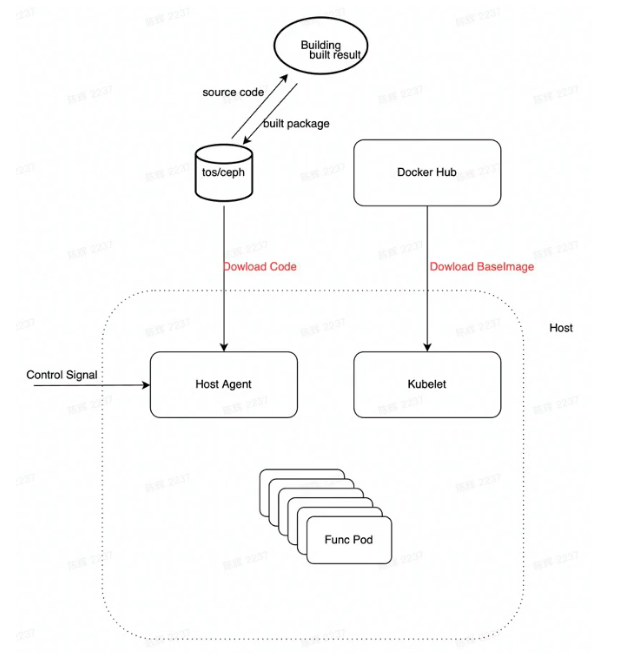
Solution
- FaaS Control plane
- Adjust Build logic, upload code/dependencies to TOS
- Deployment/pod spec add mount dir
- Host-Agent: Host daemon pod
- Pull code when pod schedule to this machine
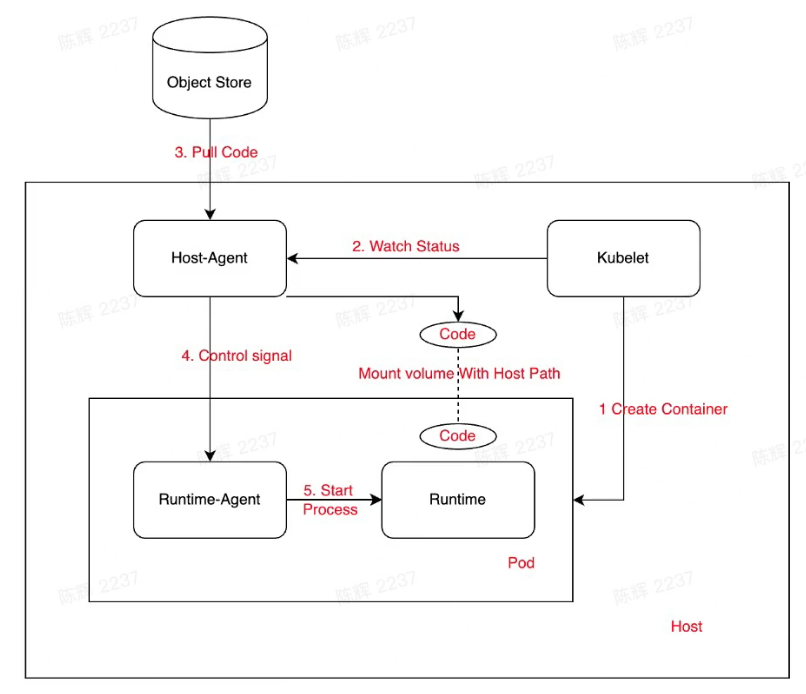
Container/runtime Start process
- Kubelet create container with mount volume
- Host-Agent watch status
- Host-Agent pull code from object store
- Host-Agent Health check with runtime-agent and send signal /v1/load
- Runtime- -agent start runtime process
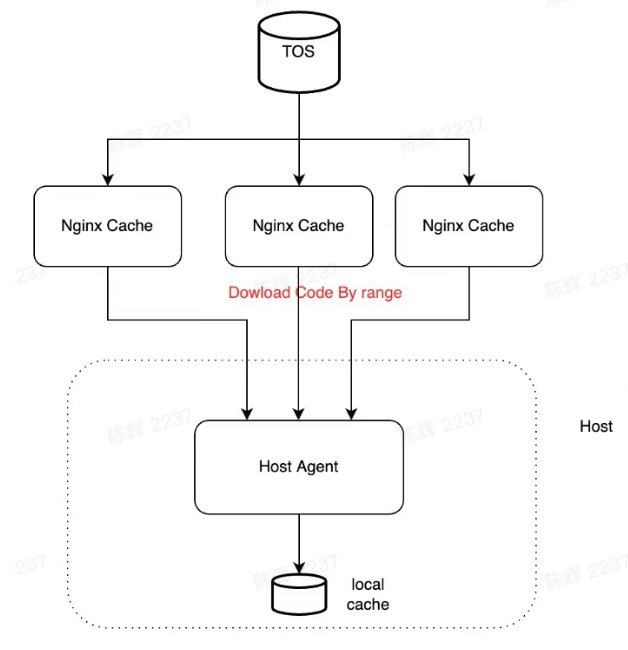
Optimize the code download speed
- Add nginx-cache, Pre-Warmup code cache during building
- Download by http range and concurrently
- Unzip/untar during downloading
- Manage thin local cache
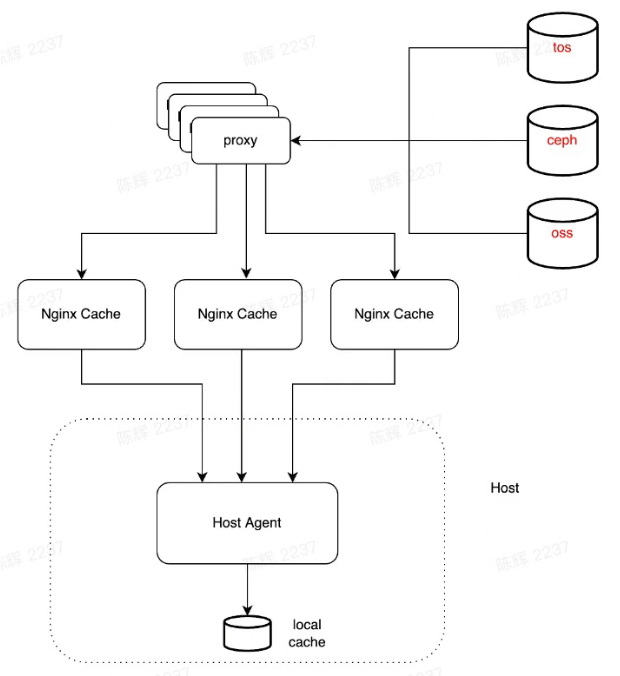
Stability/High availability
- Integrate with Luban, tos/ceph/oss
- Add fallback when download from nginx failed/limited
Results
- Eliminate the image pulling , but added the code pull time
- Seconds -> tens of milliseconds
Warming Pool(create container)
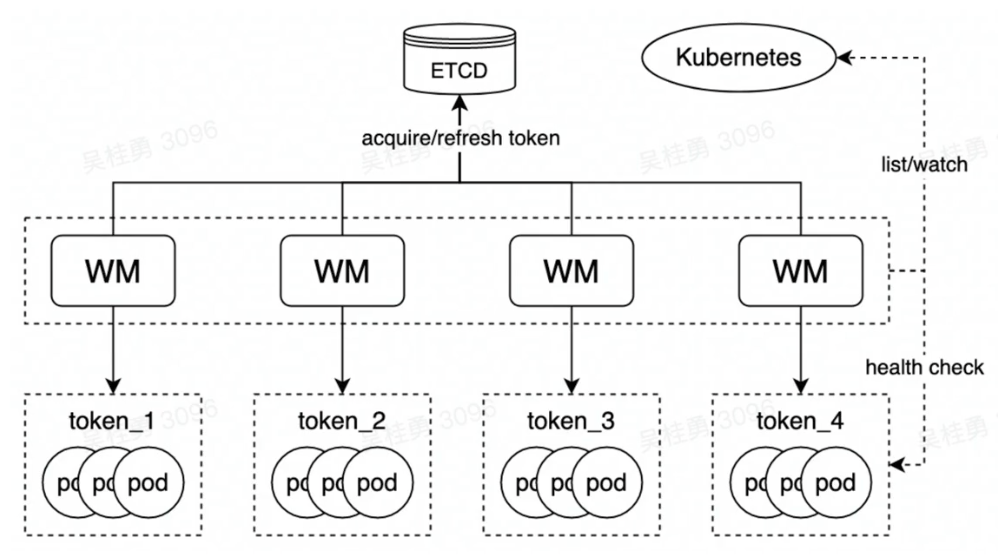
Optimize the Pod creating Time
- Create pod before use
- Manage pre-created pod with pool
- Create pool for each runtime
- Provide api for taken pod from pool
- Take pod when cold start happened
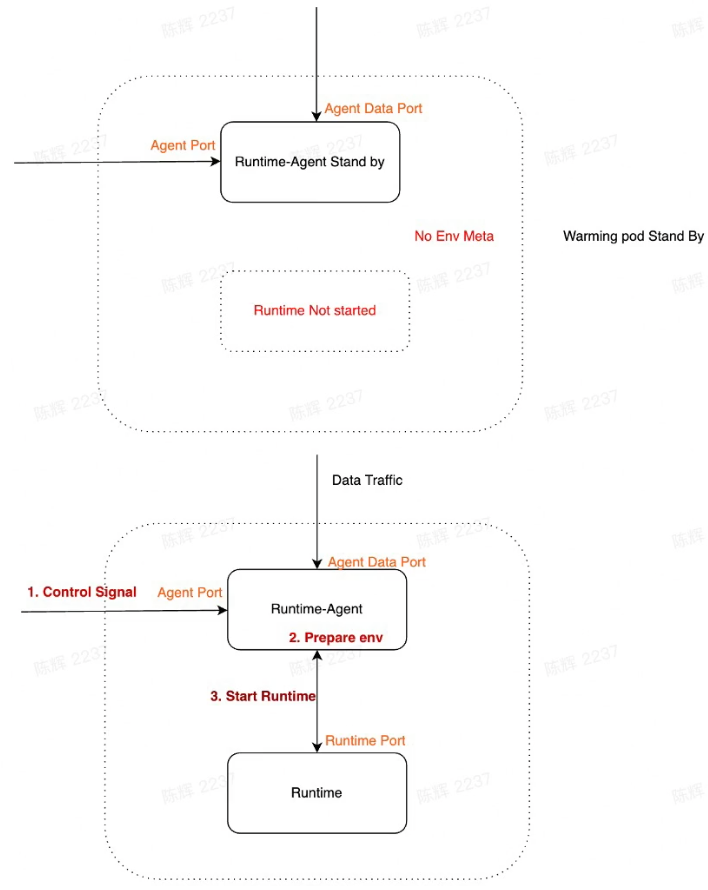
Warming Pod
- Has no service meta like psm, env
- Runtime-Agent start with stand by mode
- Runtime Not started( as we have no meta info)
When taken pod from pool
- Remove pod from pool, mark it as used
- Prepare meta info and send with Control Signal /v1/load to load the runtime
- Runtime-Agent set process env and then start runtime process
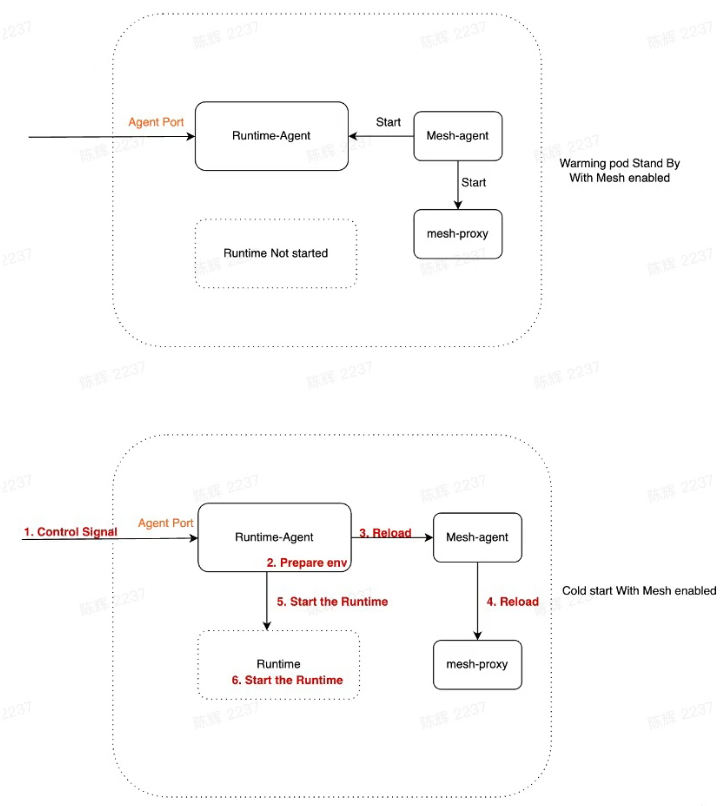
How Mesh Start
Warming pool standby pod
- Mesh don't have enough info to start
- Start mesh ad-hoc will increase the latency
- Need download mesh_ proxy binary
- Start process latency
Solution
- Mesh support standby mode
- Reload mesh during /v1/load
Runtime Standby(start process)
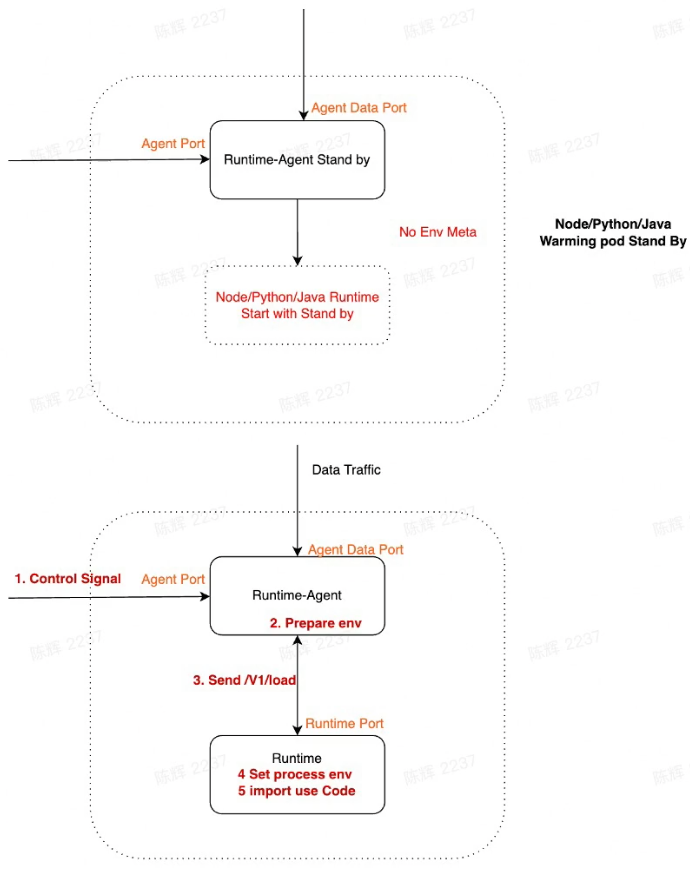
How to optimize the cold start time further
- What has been left ?
- The process staring time
- Node/Python/Java much slower, seconds level
- Golang pretty fast
- How to faster the dynamic language
- Pre-Start the runtime process
- Send meta info through /v1/load during cold start
- Import user 's code dynamically
Results
System latency Cost
- The latency for acquire a route
- Currently is 10ms
Code Related Latency
- Code Downloading Time, Positively correlated with code package size
- Code import time, Positively correlated with code package size
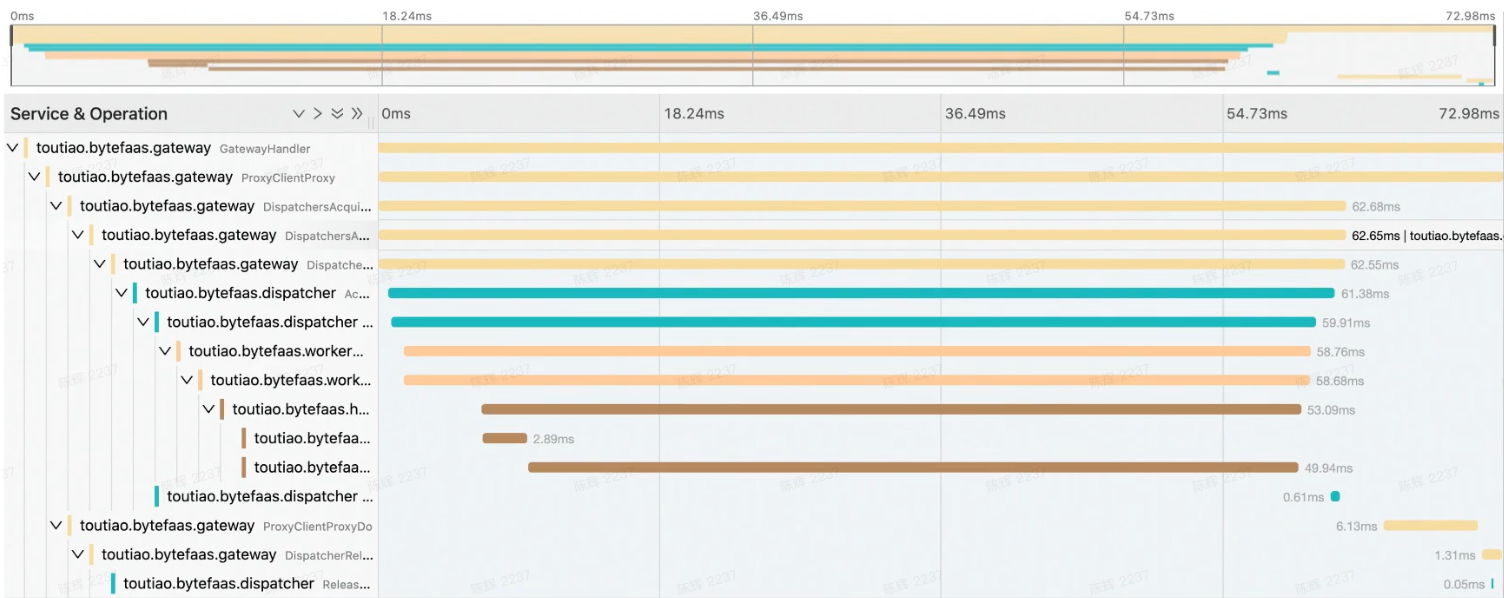
Best Practice
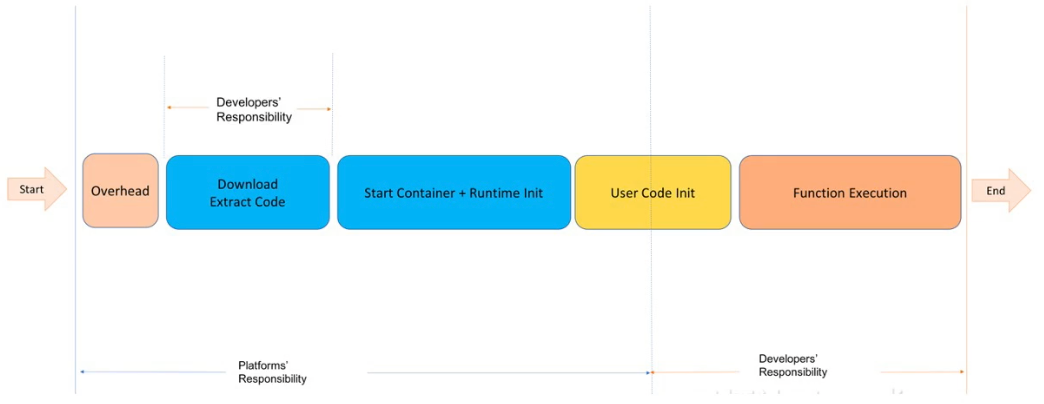
Developer's Responsibilty
- Minimize the code as small as possible
- If business is very sensitive to cold start, you can choose to reserve instances
- Self-define runtime, put some shared dependencies into base images, like Goofy, light, cold start time shorten from 5s to 1s
Platform's Responsibility
- Shorten the download code time
- Work with K8S team shorten the container creating time
- Shorten runtime process start time further
Summary
- image code split - image download time
- warming pool - container create time
- runtime standby - runtime start time(Node/Python/Java)
Async Mode Intro & Demo
Background
- We only support maximum 15 min execution time by default
- Long-running execution demands
- Can not just increase the time because the connection should be persist between client -> tlb -> gateway -> runtime-agent -> runtime
- Cronjob Pain points
- Image pulling cannot guaranteed, minutes level delays, and may failed
- Containers cannot be reused
- PPE not support etc.
Architecture
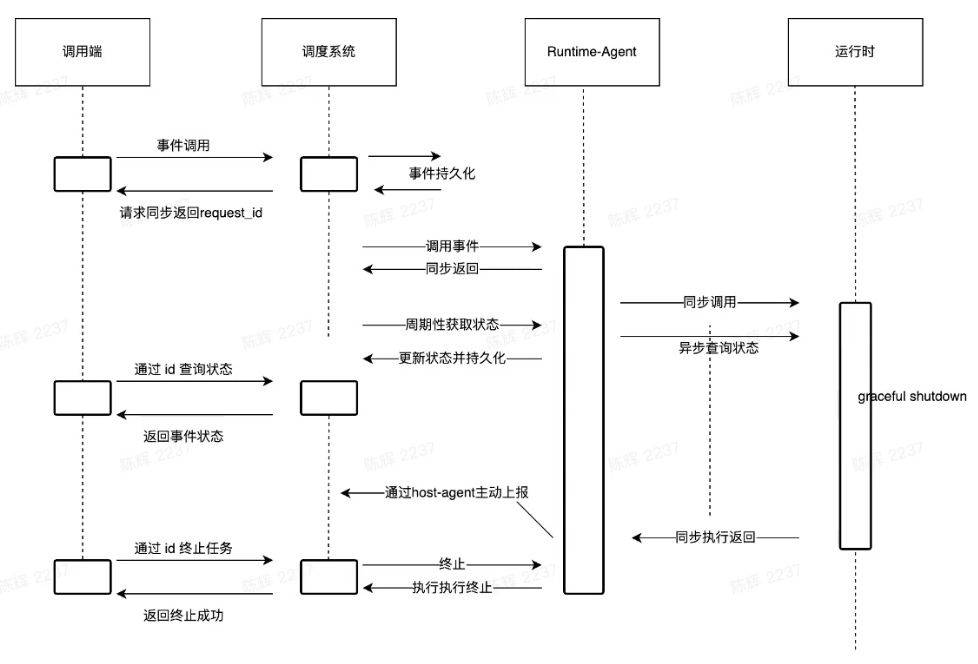
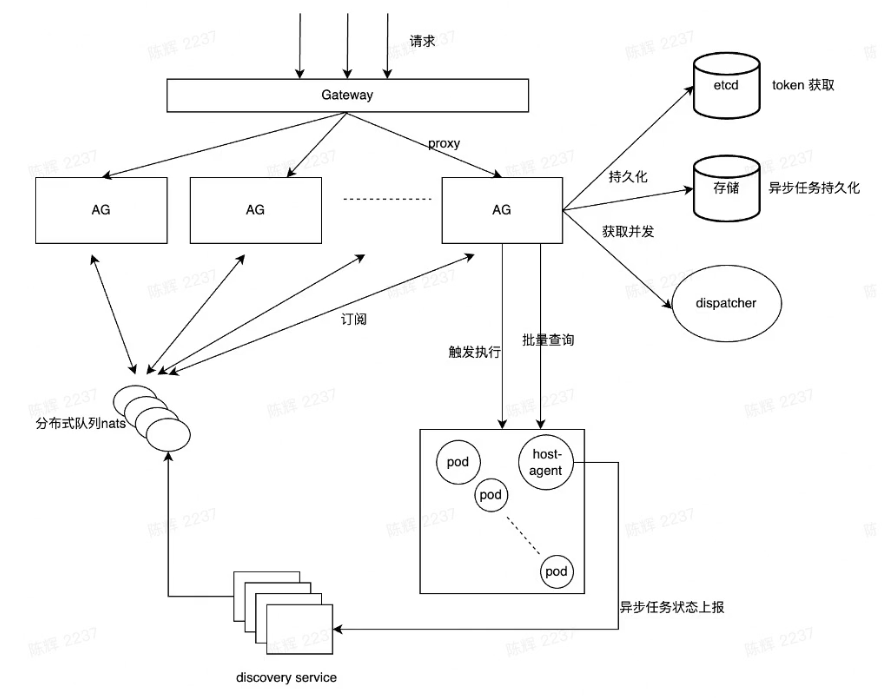
-
AG(Async Gateway)
-
Concurrency limit and management
-
Acquire route and proxy request to func instance
-
Request lifecycle management
-
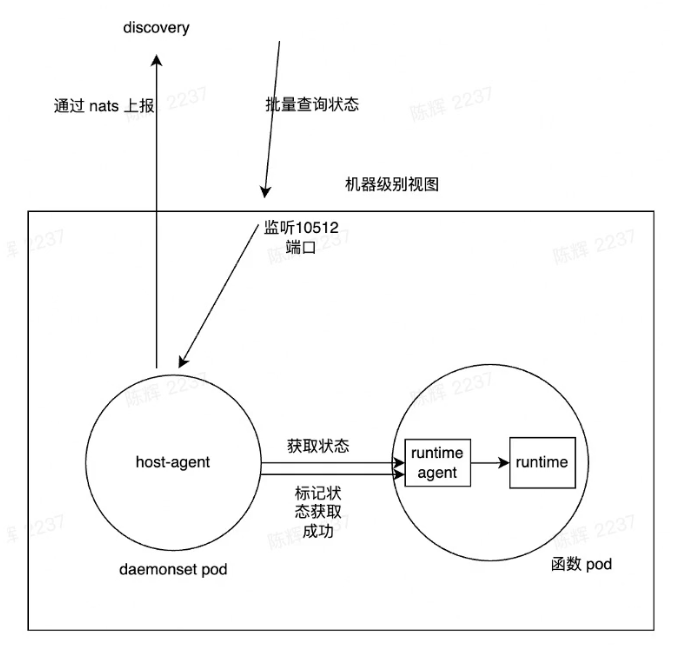
Look batch status from host-agent and subscribe nats to receive the status change
-
-
Nats
-
Cloud-Native, High performance
-
Lighter than kafka/rocketmq
-
-
Discovery
- Status Report Service
- Avoid all clients connect nats
- Runtime-Agent
- Request Proxy and Status Management in memory
- Graceful shutdown Management
- Log Collection, Stdout/Stderr
- Api for status lookup/kill
- Host-Agent
- Async Pod management
- Status report
- Batch collect log
- Api for batch lookup status/kill request
Demo & User Guide
Advantages
- All kinds of event trigger supported by ByteFaaS
- Easy integrate
- Almost no delay for execution (concurrency remains)
- Support Maximum execution 3 hours
- ELK support, fetch log by request id
Disadvantage
- Not support custom image for now
- Not support lib mount like SS_ _lib
Applicable Scenarios
- Long-running, average more than 10 seconds
- Currently only support exclusive-mode
- High cpu/mem demand execution
Future Planning
Cold Start
- Host-Agent p2p network introduce
- Lazy load code refer to image lazy load
Async Mode
- Observability
- Longer Running time
- Async + Share mode (Coming)
