一、概述
对于高斯混合模型的假设,首先来看以下两个例子。
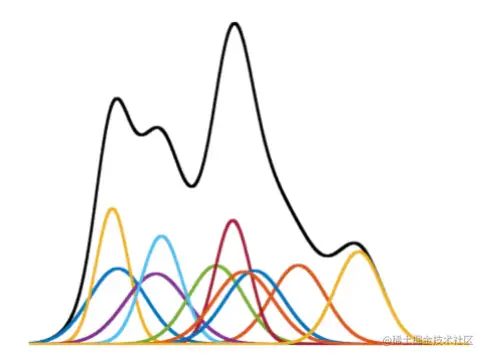
首先,让我们以一维数据为例。如下图所示,我们可以将多个独立的高斯模型通过加权叠加在一起,从而得到一个高斯混合模型。这种混合模型明显具有比单个高斯模型更高的拟合能力:
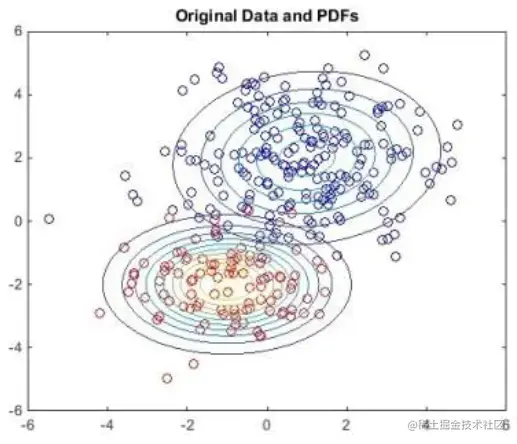
接下来,我们以二维数据为例。在下图中,我们可以看到存在两个数据聚集区域,这两个区域对应的概率分布会有两个峰值。高斯混合模型可以视为生成模型,其数据生成过程可以认为是首先选择一个高斯分布,然后从这个被选中的高斯分布中生成数据:
综合上述两个例子,我们可以从两种角度来描述高斯混合模型:
- 几何角度:加权平均
可以认为高斯混合模型是将多个高斯分布加权平均而成的模型:
p(x)=k=1∑KαkN(μk,Σk),k=1∑Kαk=1
- 混合模型(或者生成模型)角度
可以认为高斯混合模型是一种含有隐变量的生成模型:
x:观测变量
z:隐变量
z是隐变量,表示对应的样本x属于哪一个高斯分布,其概率分为如下表:
| z | C1 | C2 | ⋯ | Ck |
|---|
| p | p1 | p2 | ⋯ | pk |
可以认为这里的概率pk就是几何角度加权平均中的权重,两种角度的解释其实是一个意思。
我们可以画出高斯混合模型的概率图:
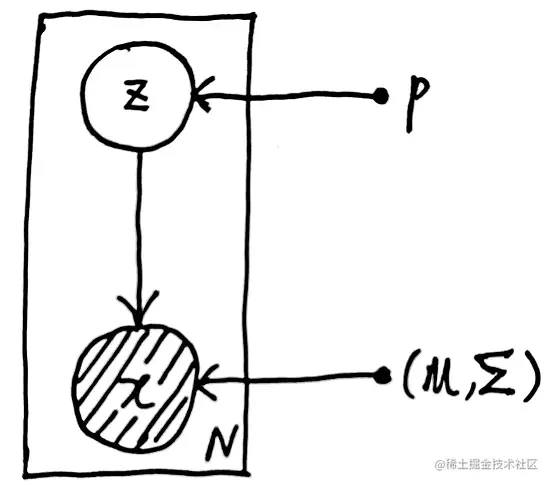
实心点p代表模型的一个参数,空心圈Z代表随机变量,右下角的N代表样本个数。
生成过程:随机变量Z的参数是p,p=(p1,p2,...,pk)(k为该高斯混合模型中高斯分布的个数),再在选择出的高斯分布中随机取样x样本点,将这个过程重复N次即为生成了N个样本点。
二、尝试用极大似然估计来求解
X :observed data →X=(x1,x2,⋯,xN)
(X,Z) :comlete data
θ :parameter
→θ={p1,p2,⋯,pk,μ1,μ2,⋯,μk,Σ1,Σ2,⋯,Σk},∑i=1Kpk=1
以上为我们的数据以及需要求解的参数。接下来我们表示一下概率 p(x) :
p(x)=z∑p(x,z)=k=1∑Kp(x,z=Ck)=k=1∑Kp(z=Ck)⋅p(x∣z=Ck)=k=1∑Kpk⋅N(x∣μk,Σk)
然后我们使用极大似然估计法求解这个参数估计问题。首先告知结论:极大似然估计法无法求解含有隐变量的参数估计问题,或者说不能得到解析解。接下来来看为什么不能用极大似然估计法来求解:
θ^MLE=θargmaxlogp(X)=θargmaxlogi=1∏Np(xi)=θargmaxi=1∑Nlogp(xi)=θargmaxi=1∑Nlogk=1∑Kpk⋅N(xi∣μk,Σk)
极大似然估计法无法获得解析解,主要原因是log函数中出现了求和符号。我们更倾向于log函数内部存在乘法的情况,因为这样可以将其拆分为两项相加,从而更易于求解。但是,如果在对特定参数求导之后,出现了log函数内求和的情况,那么这就意味着需要满足log函数中一长串累加项的和等于0的条件,这是一件困难的事情。当然,我们可以使用梯度下降法进行求解,但对于包含隐变量的模型,使用EM算法更为合适。
三、使用EM算法求解
由于使用EM算法需要用到联合概率p(x,z)和后验p(z∣x),所有我们首先写出这两个概率的表示:
p(x,z)=p(z)p(x∣z)=pz⋅N(x∣μz,Σz)p(z∣x)=p(x)p(x,z)=∑k=1Kpk⋅N(x∣μk,Σk)pz⋅N(x∣μz,Σz)
- E step
Q(θ,θt)=Z∑logp(X,Z∣θ)⋅p(Z∣X,θt)=z1z2⋯zN∑logi=1∏Np(xi,zi∣θ)⋅i=1∏Np(zi∣xi,θt)=z1z2⋯zN∑i=1∑Nlogp(xi,zi∣θ)⋅i=1∏Np(zi∣xi,θt)=z1z2⋯zN∑[logp(x1,z1∣θ)+logp(x2,z2∣θ)+⋯+logp(xi,zi∣θ)]⋅i=1∏Np(zi∣xi,θt)
对于上式展开的每一项,我们可以进行化简:
z1z2⋯zN∑logp(x1,z1∣θ)i=1∏Np(zi∣xi,θt)=z1z2⋯zN∑logp(x1,z1∣θ)⋅p(z1∣x1,θt)i=2∏Np(zi∣xi,θt)=z1∑logp(x1,z1∣θ)⋅p(z1∣x1,θt)z2z3⋯zN∑i=2∏Np(zi∣xi,θt)=z1∑logp(x1,z1∣θ)⋅p(z1∣x1,θt)z2z3⋯zN∑p(z2∣x2,θt)p(z3∣x3,θt)⋯p(zN∣xN,θt)=z1∑logp(x1,z1∣θ)⋅p(z1∣x1,θt)=1z2∑p(z2∣x2,θt)=1z3∑p(z3∣x3,θt)⋯=1zN∑p(zN∣xN,θt)=z1∑logp(x1,z1∣θ)⋅p(z1∣x1,θt)
同样的我们可以得到:
z1z2⋯zN∑logp(xi,zi∣θ)i=1∏Np(zi∣xi,θt)=zi∑logp(xi,zi∣θ)⋅p(zi∣xi,θt)
继续对Q(θ,θt)进行化简可以得到:
Q(θ,θt)=z1∑logp(x1,z1∣θ)⋅p(z1∣x1,θt)+⋯+zN∑logp(xN,zN∣θ)⋅p(zN∣xN,θt)=i=1∑Nzi∑logp(xi,zi∣θ)⋅p(zi∣xi,θt)=i=1∑Nzi∑log[pzi⋅N(xi∣μzi,Σzi)]⋅∑k=1Kpkt⋅N(xi∣μkt,Σkt)pzit⋅N(xi∣μzit,Σzit)(∑k=1Kpkt⋅N(xi∣μkt,Σkt)pzit⋅N(xi∣μzit,Σzit)与θ无关,暂时写作p(zi∣xi,θt))=i=1∑Nzi∑log[pzi⋅N(xi∣μzi,Σzi)]⋅p(zi∣xi,θt)=zi∑i=1∑Nlog[pzi⋅N(xi∣μzi,Σzi)]⋅p(zi∣xi,θt)=k=1∑Ki=1∑Nlog[pk⋅N(xi∣μk,Σk)]⋅p(zi=Ck∣xi,θt)=k=1∑Ki=1∑N[logpk+logN(xi∣μk,Σk)]⋅p(zi=Ck∣xi,θt)
- M step
EM算法的迭代公式为:
θt+1=θargmaxQ(θ,θt)
下面以求解pt+1=(p1t+1,p2t+1,⋯,pKt+1)T为例,来看如何进行迭代求解,以下是求解的迭代公式:
pkt+1=pkargmaxk=1∑Ki=1∑Nlogpk⋅p(zi=Ck∣xi,θt),s.t.k=1∑Kpk=1
于是可以转化为以下约束优化问题:
{pmin−∑k=1K∑i=1Nlogpk⋅p(zi=Ck∣xi,θt)s.t.∑k=1Kpk=1
然后使用拉格朗日乘子法进行求解:
L(p,λ)=−k=1∑Ki=1∑Nlogpk⋅p(zi=Ck∣xi,θt)+λ(k=1∑Kpk−1)∂pk∂L=−i=1∑Npk1⋅p(zi=Ck∣xi,θt)+λ=△0⇒−i=1∑Np(zi=Ck∣xi,θt)+pkt+1λ=0⇒k=1,2,⋯,K−=Ni=1∑N=1k=1∑Kp(zi=Ck∣xi,θt)+=1k=1∑Kpkt+1λ=0⇒−N+λ=0⇒λ=N代入−i=1∑Np(zi=Ck∣xi,θt)+pkt+1λ=0得−i=1∑Np(zi=Ck∣xi,θt)+pkt+1N=0⇒pkt+1=N∑i=1Np(zi=Ck∣xi,θt)
这里以求解pt+1为例展示了M step的求解过程,其他参数也按照极大化Q函数的思路就可以求解,求得一轮参数后要继续迭代求解直至收敛。
“开启掘金成长之旅!这是我参与「掘金日新计划 · 2 月更文挑战」的第 9 天,点击查看活动详情”


