一、初识Python爬虫
1.1 什么是爬虫?
- 爬虫的概念:通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
1.2 爬虫有什么风险?
- 爬虫干扰了被访问网站的正常运营
- 爬虫抓取了受到法律保护的特定类型的数据或信息
1.3 如何规避爬虫风险?
- 时常优化自己的程序,避免干扰被访问网站的正常运行。
- 在使用,传播爬取到的数据时,审查抓取到的内容,如果发现涉及到用户隐私及商业机密等敏感内容需要及时停止爬取或传播。
1.4 爬虫在使用场景中的分类
| 类别 | 作用 |
|---|
| 通用爬虫 | 抓取系统重要组成部分,抓取的是一整张页面数据。 |
| 聚焦爬虫 | 建立在通用爬虫的基础之上,抓取的是页面中特定的局部内容。 |
| 增量式爬虫 | 检测网站中数据更新的情况,只会抓取网站中最新更新出来的数据。 |
1.5 什么是反爬机制与反反爬策略?
- 反爬机制的概念:门户网站,可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
- 反反爬策略的概念:爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据。
1.5.1 最早的反爬协议
- robots.txt协议:是一种君子协议,规定了网站中那些数据是可以被爬虫程序爬取,那些数据不可以被爬取。
1.6 超文本传输协议
1.6.1 Http协议
- Http协议概念:就是服务器和客户端进行数据交互的一种形式。
| 常用请求头信息 | 简介 |
|---|
| User-Agent | 请求载体的身份标识。首部包含了一个特征字符串,用来让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商以及版本号。 |
| Connection | 请求完毕后,是断开连接还是保持连接。决定当前的事务完成后,是否会关闭网络连接。如果该值是“keep-alive”,网络连接就是持久的,不会关闭,使得对同一个服务器的请求可以继续在该连接上完成。 |
| 常用响应头信息 | 简介 |
|---|
| Content-Type | 服务器响应回客户端的数据类型,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件。 |
1.6.2 Https协议
| 加密方式 | 简介 |
|---|
| 对称密钥加密 | 对称密钥加密又叫专用密钥加密或共享密钥加密,即发送和接收数据的双方必使用相同的密钥对明文进行加密和解密运算。 |
| 非对称密钥加密 | 公开密钥加密(Public-key Cryptography)也称为非对称密钥加密(Asymmetric Cryptography),是一种密码学算法类型。该加密算法使用两个不同的密钥:加密密钥和解密密钥。 |
| 证书密钥加密 | 由服务器和客户端均认可的证书机构,对公钥做数字签名。然后分配已签名的公开密钥,并将密钥放在证书中进行绑定。服务器将数字证书发送给客户端,客户端可通过数字签名来验明公钥真伪。一旦确定信息无误后,客户端就会通过公钥对报文进行加密发送,服务器收到后再通过私钥解密。 |
二、Requests模块
2.1 什么是Requests模块?
- Requests模块的概念:Python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
- Requests模块的作用:模拟浏览器发请求。
2.2 Requests模块的编码流程
graph TD
Step1:指定URL --> Step2:发起请求
Step2:发起请求 --> Step3:获取响应数据
Step3:获取响应数据 --> Step4:持久化存储
2.3 Requests模块安装
方法一:通过PyCharm图形化界面安装
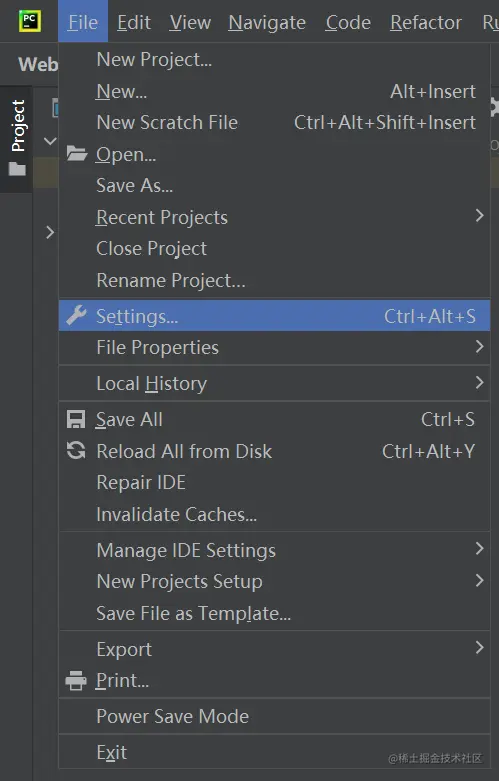
- Step1:PyCharm快捷工具栏File中单击Settings(Ctrl+Alt+S):
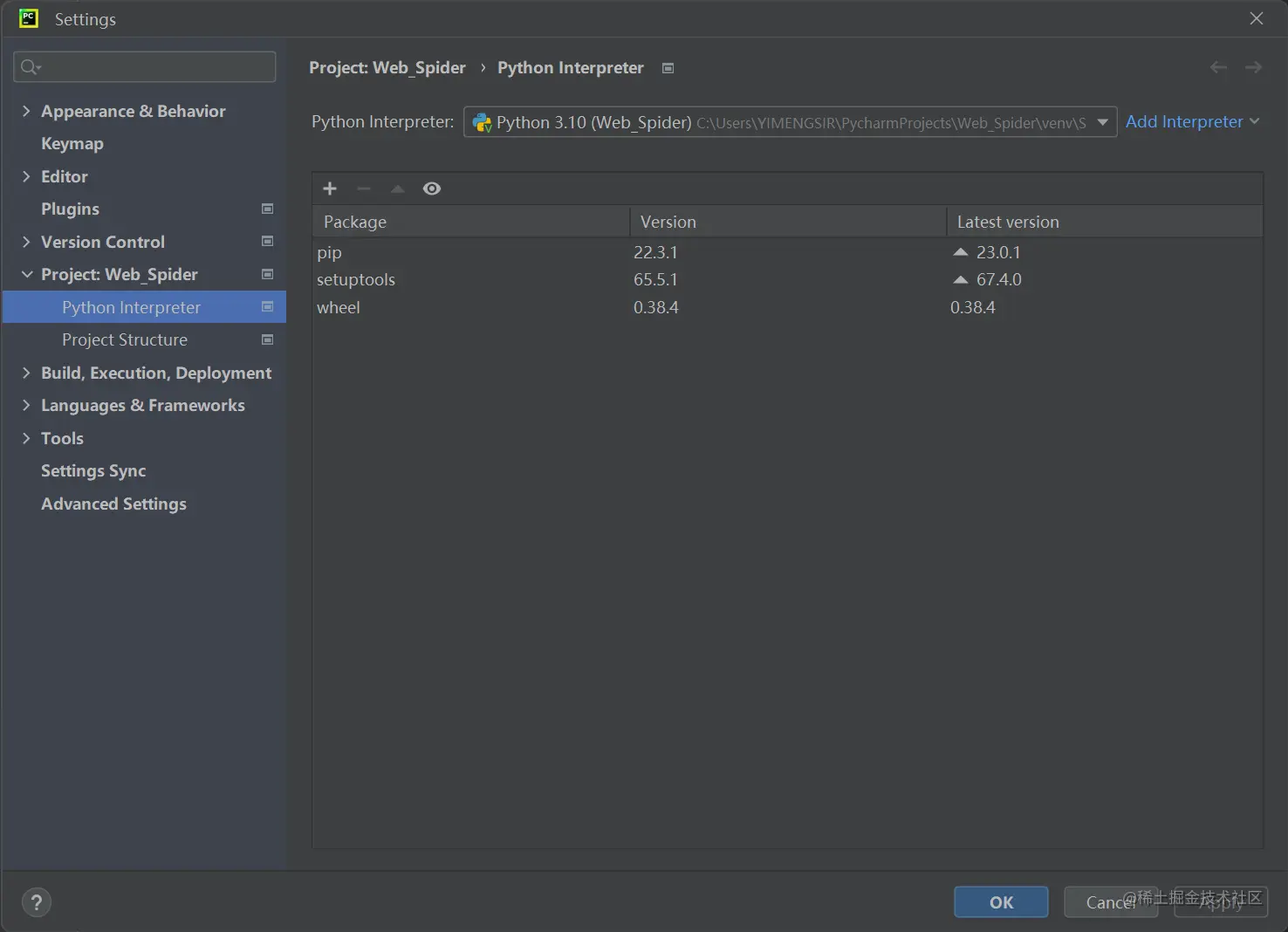
- Step2:在所需Requests模块的Project中选择Python Interpreter界面里的+号:
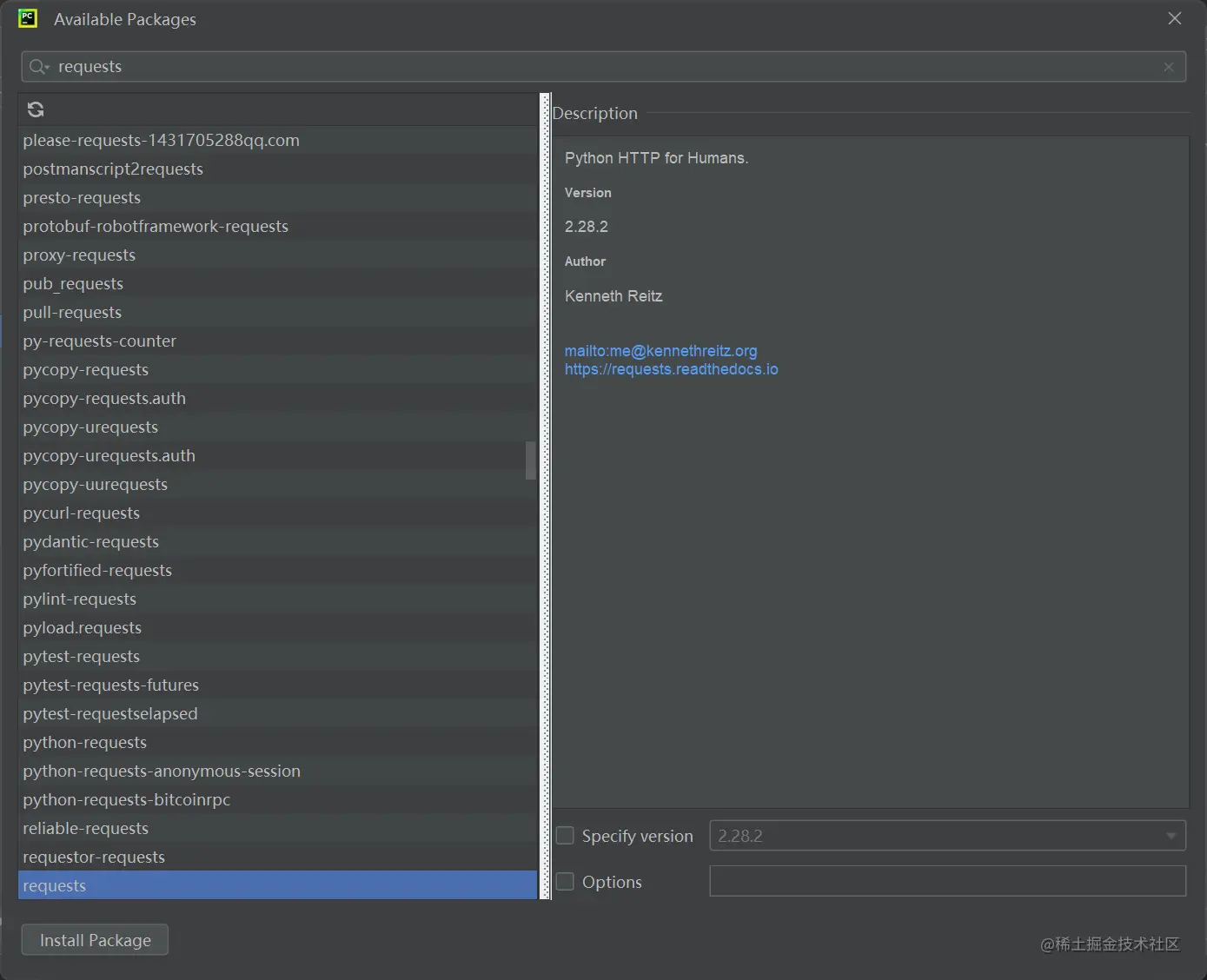
- Step3:搜索Requests模块并单击Install Package进行安装:
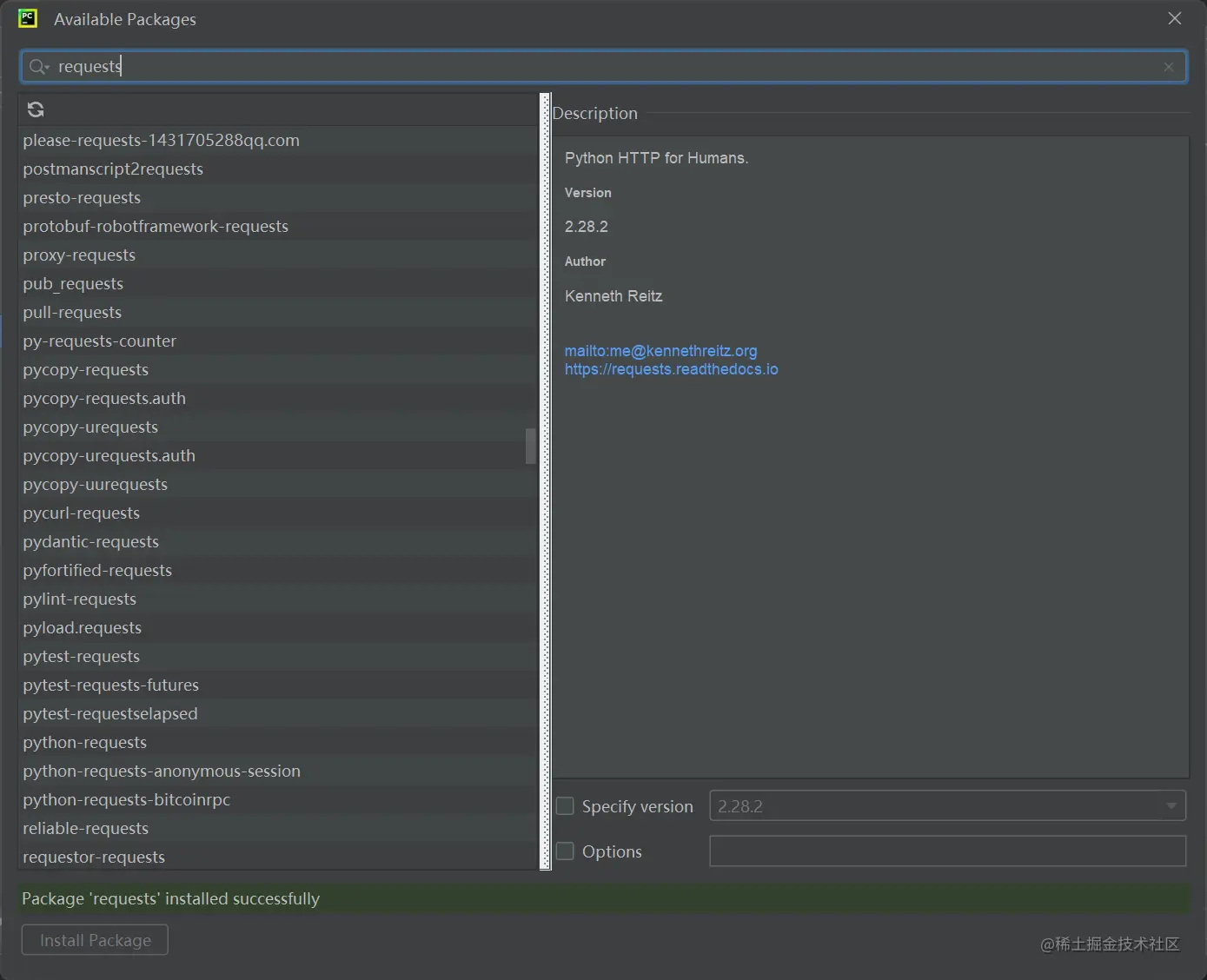
- Step4:显示Package 'requests' installed successfully则安装成功
方法二:通过命令行进行安装
pip install requests
2.4 UA检测与UA伪装
| 名称 | 介绍 |
|---|
| UA | User-Agent(请求载体的身份标识) |
| UA检测 | 80%以上的门户网站均采用了UA检测反爬机制。门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示该请求为不正常请求(爬虫),则服务器端很有可能拒绝该次请求。 |
| UA伪装 | 让爬虫对应的请求载体身份标识伪装成某一款浏览器。 |
2.5 项目实战
★需求:爬取搜狗首页的页面数据
import io
import requests
if __name__ == "__main__":
url = 'https://www.sogou.com/'
response = requests.get(url=url)
page_text = response.text
print(page_text)
with io.open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取数据结束!')
★需求:爬取搜狗指定词条对应的搜索结果页面(简易网页采集器)
import requests
if __name__ == "__main__":
url = 'https://www.sogou.com/web'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
kw = input('Enter a word:')
param = {
'query':'kw'
}
response = requests.get(url=url,params=param)
page_text = response.text
fileName = kw + '.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'保存成功!')
★需求:破解Baidu翻译
- 需要获得页面中的局部数据,页面局部刷新。
- 分析数据包,发现为post请求(携带了参数)。
- 响应是一组json数据。
import requests
import json
if __name__ == "__main__":
post_url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
word = input('Enter a word:')
data = {
'kw':word
}
response = requests.post(url=post_url,data=data,headers=headers)
dic_obj = response.json()
print(dic_obj)
fileName = word + '.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print('Over!')
★需求:爬取豆瓣电影分类排行榜中科幻电影排行详情数据
import requests
import json
if __name__ == "__main__":
url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type':'17',
'interval_id':'100:90',
'action':'',
'start':'0',
'limit':'20',
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
response = requests.get(url=url,params=param,headers=headers)
list_data = response.json()
fp = open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print('Over!')
★需求:爬取肯德基餐厅查询中指定地点的餐厅数
import requests
if __name__ == "__main__":
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
word = input('Enter a city:')
data = {
'op':'keyword',
'cname':'',
'pid':'',
'keyword':word,
'pageIndex':'1',
'pageSize':'10',
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
response = requests.post(url=post_url,data=data,headers=headers)
list_text = response.text
fileName = word + '.txt'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(list_text)
print(fileName,'保存成功!')
★Tips:
- Payload中所有参数均要在data字典中包含,否则就会出现-1000的结果。
三、数据解析
3.1 什么是数据解析?
- 数据解析的概念:对网页源码进行分析,获取指定内容的过程。
- 数据解析的应用:常用于(75%以上的需求)聚焦爬虫。
3.2 数据解析的编码流程
graph TD
Step1:指定URL --> Step2:发起请求
Step2:发起请求 --> Step3:获取响应数据
Step3:获取响应数据 --> Step4:数据解析
Step4:数据解析 --> Step5:持久化存储
3.3 数据解析原理
★需要解析的局部文本内容都会在标签之间或者标签对应的属性中进行存储,通过数据解析方法对指定标签进行定位,然后对标签或者标签对应的属性中存储的数据进行提取(解析)。
3.4 数据解析方法
3.4.1 正则匹配
- 正则匹配的概念:是一个特殊的字符序列,它能帮助用户便捷地检查一个字符串是否与某种模式匹配。
- 环境安装:Python的正则模块是re,是Python的内置模块,不需要安装,导入即可。
★正则匹配基本语法
| 单字符匹配 | 匹配对象 |
|---|
| . | 匹配任意字符(不包括\n) |
| [] | [aoe][a-w]集合中任意一个字符 |
| \d | 数字[0-9] |
| \D | 非数字[0-9] |
| \w | 数字、字母、下划线、中文 |
| \W | 非数字、字母、下划线、中文 |
| \s | 所有空白字符包括空格、制表符、换页符等。等价于:[\f\n\r\t\v] |
| \S | 非空白字符 |
| [\u4e00-\u9fa5] | 中文 |
| 匹配数量限制 | 数量含义 |
|---|
| * | 任意多次:>=0 |
| + | 至少1次:>=1 |
| ? | 可有可无,即0次或者1次 |
| {m} | 前一个字符固定m次 |
| {m,} | 前一个字符至少m次 |
| {m,n} | 前一个字符m~n次 |
| {m,n}? | 前一个字符m~n次,并取尽可能少的情况 |
| 匹配边界限制 | 边界含义 |
|---|
| $ | 以XXX结尾 |
| ^ | 以XXX开头 |
| \A | 只在字符串开头进行匹配 |
| \Z | 只在字符串结尾进行匹配 |
| \b | 匹配位于开头或者结尾的空字符串 |
| \B | 匹配不位于开头或者结尾的空字符串 |
| 匹配模式 | 模式含义 |
|---|
| .* | 贪婪模式 |
| .*? | 非贪婪(惰性)模式 |
| 匹配单/多行 | 匹配含义 |
|---|
| re.M | 多行匹配 |
| re.S | 单行匹配 |
| 匹配替换 | 匹配含义 |
|---|
| re.match(pattern,string,flags=0) | 尝试从字符串的开始位置匹配一个模式,如果匹配成功,就返回一个匹配成功的对象,否则返回None。 |
| re.search(pattern,string,flags=0) | 扫描整个字符串并返回第一次成功匹配的对象,如果匹配失败,就返回None |
| re.findall(pattern,string,flags=0) | 获取字符串中所有匹配的字符串,并以列表的形式返回 |
| re.sub(pattern, repl,string,count=0,flags=0) | 用于替换字符串中的匹配项,如果没有匹配的项则返回没有匹配的字符串 |
| re.compile(pattern[ ,flags]) | 用于编译正则表达式,生成一个正则表达式(Pattern)对象,供match()和search()函数使用 |
3.4.2 BeautifulSoup4(BS4)
- BS4的概念:全称为BeautifulSoup4,可以在HTML或XML文件中提取数据的网页信息提取库。
- 环境安装:先安装lxml库再安装bs4库。
pip install lxml
pip install bs4
- BS4数据解析的原理:①实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中。②通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取。
★BS4实例化
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
page_text = response.text
soup = BeautifulSoup(page_text,'lxml')
from bs4 import BeautifulSoup
html_test = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, features='lxml')
print(soup.prettify())
★Tips:
- 因为BeautifulSoup是一个类,所以要实例化类,参数html_test是要转化为soup对象的数据,features则是要转化为soup对象时编码的方法:soup = BeautifulSoup(html_doc, features='lxml')
- features='lxml':解析器,就是把lxml数据转化为soup数据的编码方法。
★BS4基本语法
①soup.tagName:
- 返回的是文档中第一次出现的tagName对应的标签。
②soup.find():
- find('tagName'):等同于soup.div
- 属性定位:soup.find('div',class_/id/attr='song')
③soup.find_all('tagName'):
④soup.select():
- select('某种选择器(id、class、tag...)'),返回的是一个列表。
- id使用格式:#id
- 标签使用格式:tag
- 类使用格式:class
⑤层级选择器:
soup.select('.tang > ul > li > a')[0]
soup.select('.tang > ul a')[0]
⑥获取标签之间的文本数据:
soup.a.text/get_text()
soup.a.string
3.4.3 Xpath
3.4.4 三种数据解析方法对比
1:re模块:语法简单,但是不好编写而且阅读性差
2:xpath模块:使用方法简单,但是要记住xpath语法,并且在使用的时候还要把数据转化为element对象才可以使用xpath语法进行索引导航
3:bs4:可以说是re模块和xpath模块的混合版,可以使用特定的字符串来索引,并且不需要把数据进行转化,但是要对数据进行编译为soup对象,才可以使用soup对象中的方法
总结:这三种解析数据的方法都各有利弊,我们在解析网页数据的时候,只要寻找最合适的解析数据的方法就可以了,这三个解析方法没有没有高低之分,只要找到最合适的解析方法就合适了。
与re和xpath模块的区别:
re模块:使用起来过于麻烦且阅读性不好
xpath模块:需要使用一些特定的语法
bs4模块:只需要记住一些方法如:find()、find_all(),后面会发现bs4可以认为是re和xpath的混合使用
总结
在爬取不同的网站的时候,寻找最适合的解析数据方法
可以与别的解析方法进行比较
3.5 项目实战
3.5.1 正则匹配项目实战
3.5.1 BS4匹配项目实战
3.5.1 Xpath匹配项目实战


