一、概述
- 介绍
概率模型有时既包含观测变量(observed variable),又包含隐变量(latent variable)。当概率模型只包含观测变量时,那么给定观测数据,就可以直接使用极大似然估计法或者贝叶斯估计法进行模型参数的求解。然而如果模型包含隐变量,就不能直接使用这些简单的方法了。EM算法就是用来解决这种含有隐变量的概率模型参数的极大似然参数估计法。这里只讨论极大似然估计,极大后验估计与其类似。
- 算法
EM算法的输入如下:
X :观测数据
Z : 末观测数据 (隐变量)
p(x,z∣θ) : 联合分布
p(z∣x,θ) :后验分布
θ :parameter
在算法运行开始时需要选择模型的初始化参数 θ(0) 。EM算法是一种迭代更新的算法,其计算公式为:
θt+1=θargmaxEz∣x,θt[logp(x,z∣θ)]=θargmax∫zlogp(x,z∣θ)⋅p(z∣x,θt)dz
这个公式包含了迭代的两步:
-
①E step: 计算 p(x,z∣θ) 在概率分布 p(z∣x,θt) 下的期望;
-
②M step: 计算使这个期望最大化的参数得到下一个EM步骤的输入。
总结来说,EM算法包含以下步骤:
- ①选择初始化参数θ(0);
- ②E step;
- ③M step;
- ④重复②③步直至收敛。
二、EM算法的收敛性
现在要证明迭代求得的 θt 序列会使得对应的 p(x∣θt) 是单调递增的 (如果 p(x∣θt) 是单调递 增的,那么训练数据的似然就是单调递增的),也就是说要证明 p(x∣θt)≤p(x∣θt+1) 。首先我们有:
logp(x∣θ)=logp(x,z∣θ)−logp(z∣x,θ)
接下来等式两边同时求关于 p(z∣x,θt) 的期望:
左边 =∫zp(z∣x,θt)⋅logp(x∣θ)dz=logp(x∣θ)∫zp(z∣x,θt)dz=logp(x∣θ) 右边 =记作 Q(θ,θt)∫zp(z∣x,θt)⋅logp(x,z∣θ)dz−记作 H(θ,θt)∫zp(z∣x,θt)⋅logp(z∣x,θ)dz
因此有:
logp(x∣θ)=∫zp(z∣x,θt)⋅p(x,z∣θ)dz−∫zp(z∣x,θt)⋅logp(z∣x,θ)dz
这里定义了 Q(θ,θt) ,称为 Q 函数 ( Q function),这个函数也就是上面的概述中迭代公式里 用到的函数,因此满足 Q(θt+1,θt)≥Q(θt,θt) 。
接下来将上面的等式两边 θ 分别取 θt+1 和 θt 并相减:
logp(x∣θt+1)−logp(x∣θt)=[Q(θt+1,θt)−Q(θt,θt)]−[H(θt+1,θt)−H(θt,θt)]
我们需要证明 logp(x∣θt+1)−logp(x∣θt)≥0 ,同时已知Q(θt+1,θt)−Q(θt,θt)≥0,现在来观察H(θt+1,θt)−H(θt,θt) :
H(θt+1,θt)−H(θt,θt)=∫zp(z∣x,θt)⋅logp(z∣x,θt+1)dz−∫zp(z∣x,θt)⋅logp(z∣x,θt)dz=∫zp(z∣x,θt)⋅logp(z∣x,θt)p(z∣x,θt+1)dz≤log∫zp(z∣x,θt)p(z∣x,θt)p(z∣x,θt+1)dz=log∫zp(z∣x,θt+1)dz=log1=0
这里的不等号应用了Jensen不等式:
logj∑λjyj≥j∑λjlogyj,其中λj≥0,j∑λj=1
也可以使用KL散度来证明 ∫zp(z∣x,θt)⋅logp(z∣x,θt)p(z∣x,θt+1)dz≤0 ,两个概率分布 P(x) 和 Q(x) 的KL散度是恒 ≥0 的,定义为:
DKL(P∥Q)=Ex∼P[logQ(x)P(x)]
因此有:
∫zp(z∣x,θt)⋅logp(z∣x,θt)p(z∣x,θt+1)dz=−KL(p(z∣x,θt)∣∣p(z∣x,θt+1))≤0
因此得证 logp(x∣θt+1)−logp(x∣θt)≥0 。这说明使用EM算法迭代更新参数可以使得 logp(x∣θ) 逐步增大。
另外还有其他定理保证了EM的算法收敛性。首先对于 θi(i=1,2,⋯) 序列和其对应的对数似然序列 L(θt)=logp(x∣θt)(t=1,2,⋯) 有如下定理:
-
①如果 p(x∣θ) 有上界,则 L(θt)=logp(x∣θt) 收敛到某一值 L∗ ;
-
②在函数 Q(θ,θ′) 与 L(θ) 满足一定条件下,由EM算法得到的参数估计序列 θt 的收敛值 θ∗ 是 L(θ) 的稳定点。
三、EM算法的导出
- ELBO+KL散度的方法
对于前面用过的式子,首先引入一个新的概率分布q(z):
logp(x∣θ)=logp(x,z∣θ)−logp(z∣x,θ)=logq(z)p(x,z∣θ)−logq(z)p(z∣x,θ)q(z)=0
以上引入一个关于z的概率分布q(z),然后式子两边同时求对q(z)的期望:
左边=∫zq(z)⋅logp(x∣θ)dz=logp(x∣θ)∫zq(z)dz=logp(x∣θ)右边=ELBO(evidencelowerbound)∫zq(z)logq(z)p(x,z∣θ)dzKL(q(z)∣∣p(z∣x,θ))−∫zq(z)logq(z)p(z∣x,θ)dz
因此我们得出 logp(x∣θ)=ELBO+KL(q∥p) ,由于KL散度恒 ≥0 ,因此logp(x∣θ)≥ELBO ,则 ELBO 就是似然函数 logp(x∣θ) 的下界。使得logp(x∣θ)=ELBO 时,就必须有 KL(q∥p)=0 ,也就是 q(z)=p(z∣x,θ) 时。在
每次迭代中我们取 q(z)=p(z∣x,θt) ,就可以保证 logp(x∣θt) 与 ELBO 相等,也就是:
logp(x∣θ)=ELBO∫zp(z∣x,θt)logp(z∣x,θt)p(x,z∣θ)dzKL(p(z∣x,θt)∣∣p(z∣x,θ))−∫zp(z∣x,θt)logp(z∣x,θt)p(z∣x,θ)dz
当 θ=θt 时, logp(x∣θt) 取ELBO,即:
logp(x∣θt)=ELBO∫zp(z∣x,θt)logp(z∣x,θt)p(x,z∣θt)dz=0−∫zp(z∣x,θt)logp(z∣x,θt)p(z∣x,θt)dz=ELBO
也就是说 logp(x∣θ) 与 ELBO 都是关于 θ 的函数,且满足 logp(x∣θ)≥ELBO ,也就 是说 logp(x∣θ) 的图像总是在 ELBO 的图像的上面。
对于 q(z) ,我们取q(z)=p(z∣x,θt) ,这也就保证了只有在 θ=θt 时 logp(x∣θ) 与 ELBO 才会相等,因 此使 ELBO 取极大值的 θt+1 一定能使得 logp(x∣θt+1)≥logp(x∣θt) 。该过程如下图 所示:
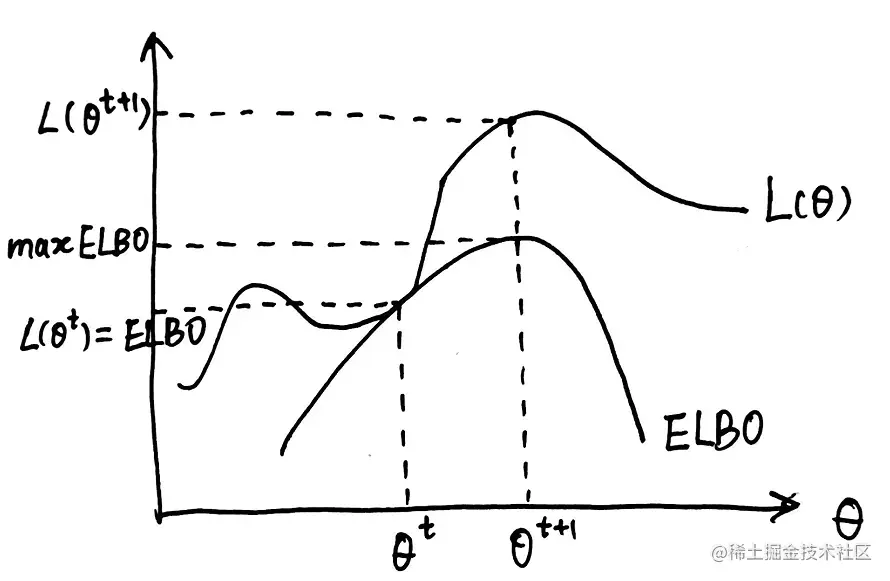
然后我们观察一下ELBO取极大值的过程:
θt+1=θargmaxELBO=θargmax∫zp(z∣x,θt)logp(z∣x,θt)p(x,z∣θ)dz=θargmax∫zp(z∣x,θt)logp(x,z∣θ)dz−与θ无关θargmax∫zp(z∣x,θt)p(z∣x,θt)dz=θargmax∫zp(z∣x,θt)logp(x,z∣θ)dz=θargmaxEz∣x,θt[logp(x,z∣θ)]
由此我们就导出了EM算法的迭代公式。
- ELBO+Jensen不等式的方法
首先要具体介绍一下Jensen不等式:对于一个凹函数 f(x)(国内外对凹凸函数的定义恰好相反,这里的凹函数指的是国外定义的凹函数),我们查看其图像如下:
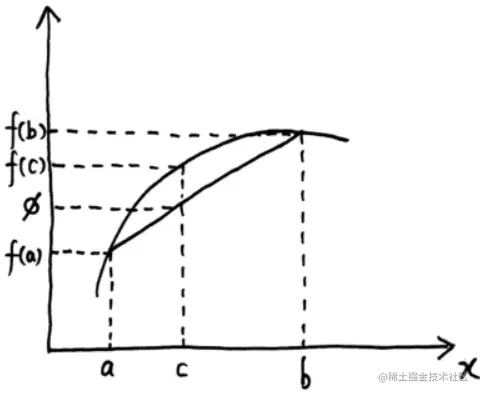
t∈[0,1]c=ta+(1−t)bϕ=tf(a)+(1−t)f(b)
凹函数恒有 f(c)≥ϕ\mathrm ,也就是 f(ta+(1−t)b)≥tf(a)+(1−t)f(b) ,当 t=21 时有 f(2a+2b)≥2f(a)+2f(b) ,可以理解为对于凹函数来说 先求期望再求函数值 恒 ≥ 先求函数值再求期望,即 f(E)≥E[f] 。
上面的说明只是对Jensen不等式的一个形象的描述,而非严谨的证明。接下来应用Jensen不等式来导出EM算法:
logp(x∣θ)=log∫zp(x,z∣θ)dz=log∫zq(z)p(x,z∣θ)⋅q(z)dz=logEq(z)[q(z)p(x,z∣θ)]≥ELBOEq(z)[logq(z)p(x,z∣θ)]
这里应用了Jensen不等式得到了上面出现过的 ELBO ,这里的 f(x) 函数也就是 log 函数, 显然这是一个凹函数。当 logq(z)P(x,z∣θ) 这个函数是一个常数时会取得等号,利用这一点我们 也同样可以得到 q(z)=p(z∣x,θ) 时能够使得 logp(x∣θ)=ELBO 的结论:
q(z)p(x,z∣θ)=C⇒q(z)=Cp(x,z∣θ)⇒∫zq(z)dz=∫zC1p(x,z∣θ)dz⇒1=C1∫zp(x,z∣θ)dz⇒C=p(x∣θ)将C代入q(z)=Cp(x,z∣θ)得q(z)=p(x∣θ)p(x,z∣θ)=p(z∣x,θ)
这种方法到这里就和上面的方法一样了,总结来说就是:
logp(x∣θ)≥ELBOEq(z)[logq(z)p(x,z∣θ)]
上面的不等式在q(z)=p(z∣x∣θ)时取等号,因此在迭代更新过程中取q(z)=p(z∣x,θt)接下来的推导过程就和第1种方法一样了。
四、广义EM算法
上面介绍的EM算法属于狭义的EM算法,它是广义EM的一个特例。在上面介绍的EM算法的E步中我们假定q(z)=p(z∣x,θt),但是如果这个后验p(z∣x,θt)无法求解,那么必须使⽤采样(MCMC)或者变分推断等⽅法来近似推断这个后验。前面我们得出了以下关系:
logp(x∣θ)=∫zq(z)logq(z)p(x,z∣θ)dz−∫zq(z)logq(z)p(z∣x,θ)dz=ELBO+KL(q∥p)
当我们对于固定的 θ ,我们希望 KL(q∥p) 越小越好,这样就能使得 ELBO 更大:
固定θ,q^=qargminKL(q∥p)=qargmaxELBO
ELBO 是关于 q 和 θ 的函数,写作 L(q,θ) 。以下是广义EM算法的基本思路:
E step: qt+1=argmaxL(q,θt)
M step: θt+1=qargmaxL(qt+1,θ)
再次观察一下 ELBO :
ELBO=L(q,θ)=Eq[logp(x,z)−logq]=Eq[logp(x,z)]H[q]−Eq[logq]
因此,我们看到,⼴义 EM 相当于在原来的式⼦中加⼊熵H[q]这⼀项。
五、EM的变种
EM 算法类似于坐标上升法,固定部分坐标,优化其他坐标,再⼀遍⼀遍的迭代。如果在 EM 框架中,⽆法求解z后验概率,那么需要采⽤⼀些变种的 EM 来估算这个后验:
①基于平均场的变分推断,VBEM/VEM
②基于蒙特卡洛的EM,MCEM
“开启掘金成长之旅!这是我参与「掘金日新计划 · 2 月更文挑战」的第 8 天,点击查看活动详情”


