

这是我参与「第五届青训营 」伴学笔记创作活动的第 33 天
本节课讲述的内容:
分布式系统现在面临着几个挑战:数据规模越来越大、服务的可用性要求越来越高、快速迭代的业务要求系统足够易用。主要从三个维度介绍了分布式系统需要什么特性,该如何去考量它,在此基础上结合相关案例对 KV 概念进行讲解。
围绕着一致性和共识算法展开,先展示了如何使用副本复制算法升级 KV ,然后讲述了如何用共识算法实现一致性,即两者之间的关系,通过学习本节课程能够帮助同学对以上二者有一个较为全面的认知。
分布式系统
Challenge
- 数据规模越来越大
- 服务的可用性越来越高
- 快速迭代的业务要求系统足够易用
理想
- 高性能:可拓展,低时延,高吞吐
- 正确:一致性,易于理解
- 可靠:容错,高可用
从HDFS开始
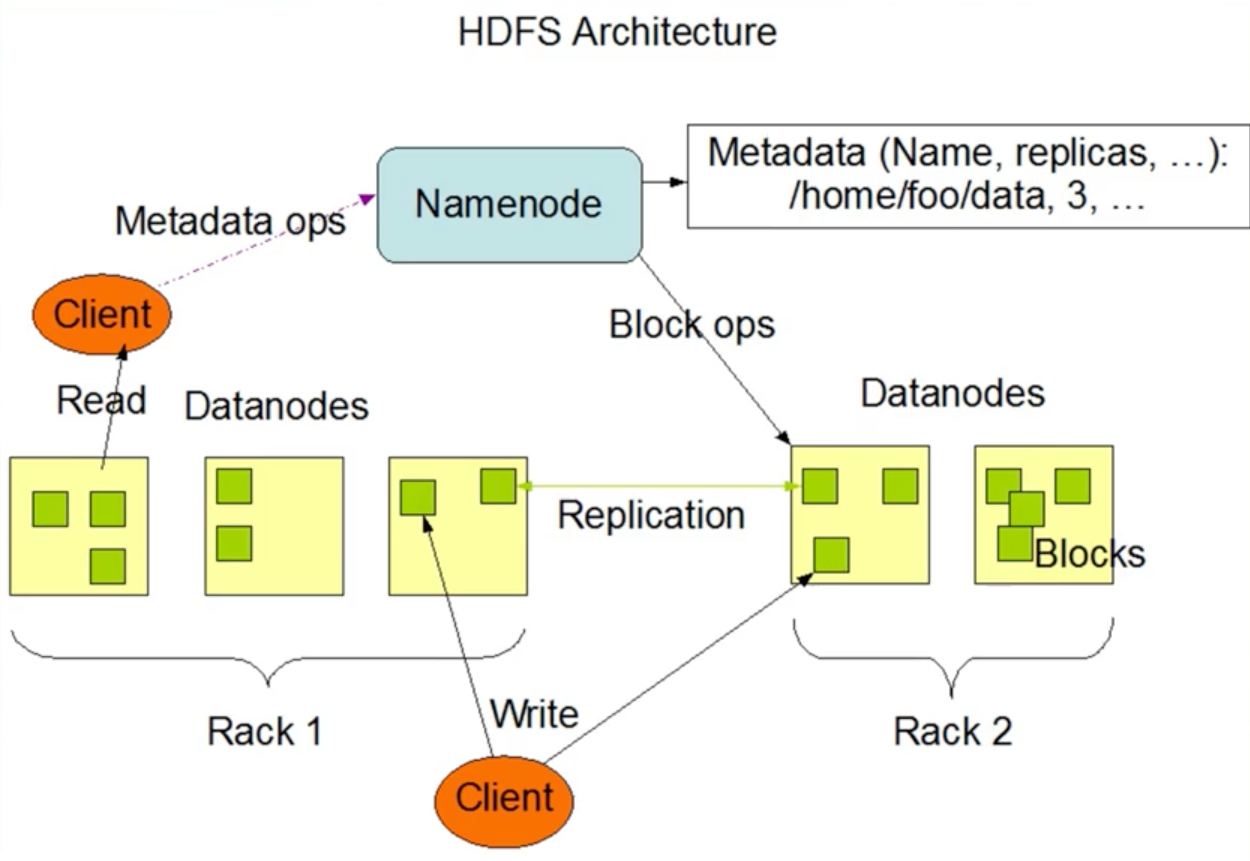
写进去,读得出来,一致性!!!
案例-KV
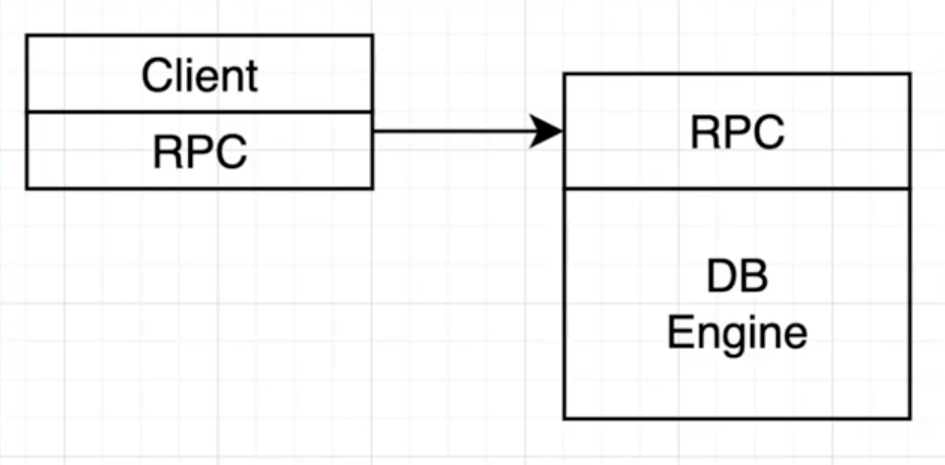
- 从最简单机KV开始
- 接口:
- Get(key) -> value
- BatchPut([k1, k2, ... [v1, v2, ..
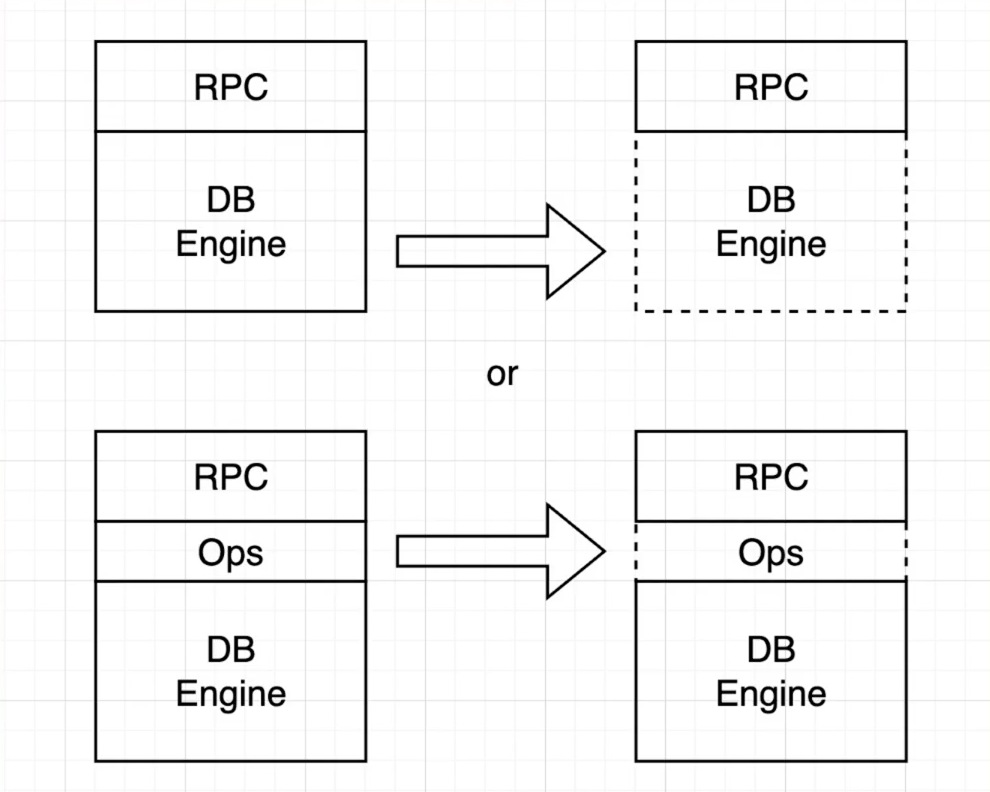
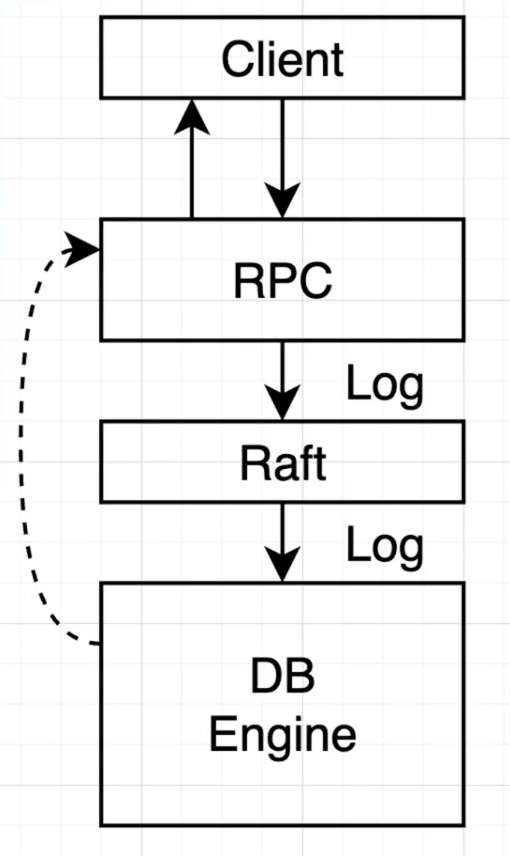
- 第一次实现
- RPC
- DB Engine
上面这个例子就非常简单,显而易见的正确昂!!!
一致性和共识算法
从复制开始
- 既然一台机器会挂:
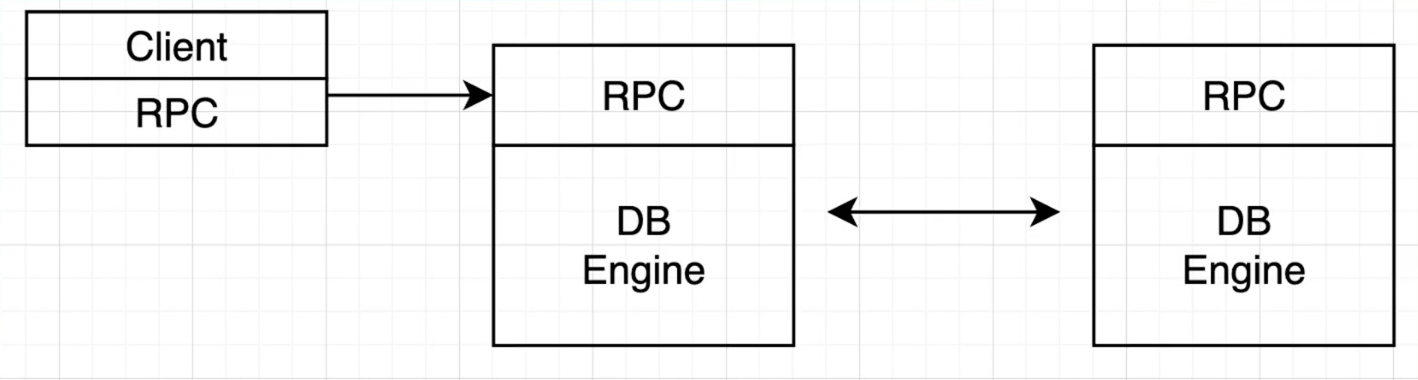
- 如果两个副本都能接受请求?
可以,但是打咩,太复杂了昂!!!
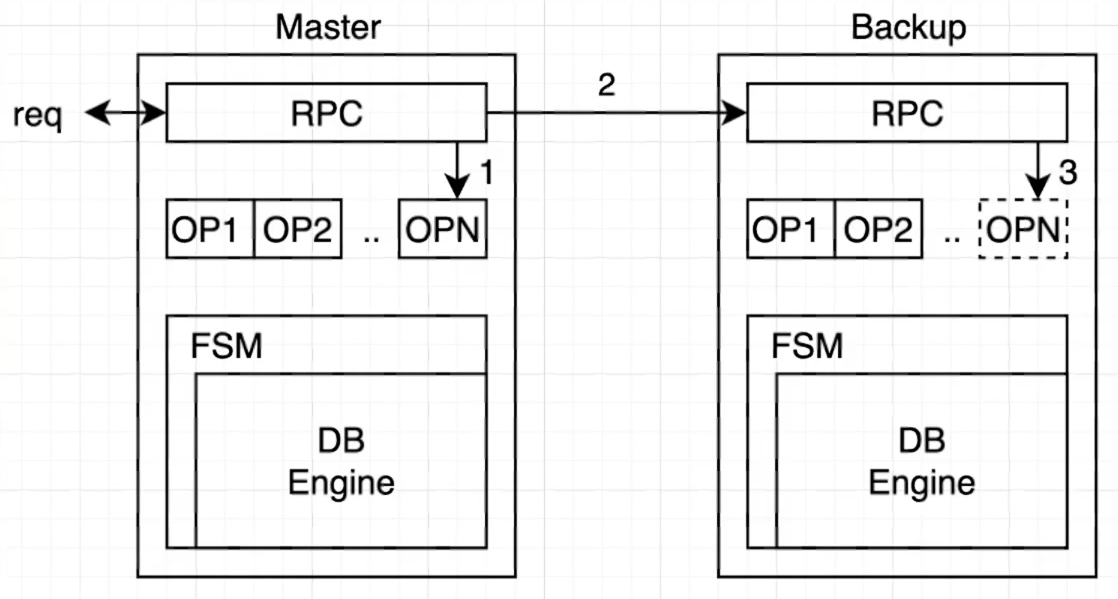
如何复制
- 定期拷贝全量数据到副本(State Transfer)-> 开销很大
- 主副本拷贝操作到从副本(Replication State Machine)
如何复制操作
- 主副本把所有的操作打包成Log
- 所有的Log写入都是持久化的,保存在磁盘上
- 应用包装成状态机,只接收Log作为Input
- 主副本确认Log已经成功写入到副本机器上,当状态机apply后,返回客户端
- 读操作
- 方案一: 直接读状态机,要求写操作进入状态机后再返回client
- 方案二: 写操作复制完成后直接返回,读操作Block等待所有pending log进入状态机
- 如果不遵循上述两种方案呢?
- 可能存在刚刚写入的值读不到的情况(在Log中)
什么是一致性
- 对于我们的KV
- 像操作一台机器一样
- 要读到最近写入的值
- 像操作一台机器一样
- 一致性是一种模型(或语议)
- 来约定一个分布式系统如何向外界(应用)提供服务
- KV中常见的一致性模型
- 最终一致性:读取可能暂时读不到但是总会读到
- 线性一致性:最严格,线性执行
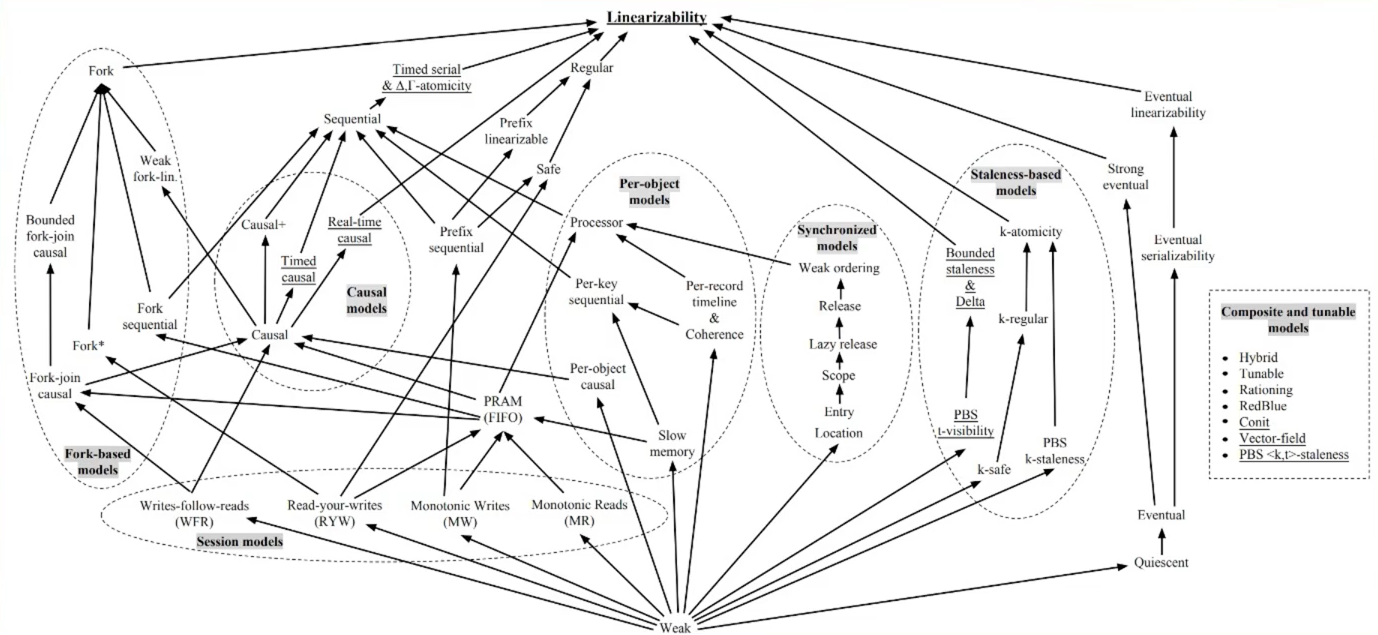
- 一致性的分类
- 经常与应用本身有关
- Linearizability 是最理想的
当失效发生
- 当主副本失效
- 手动切换
- 容错?
- 不,我们的服务还是停了
- 高可用?
- 也许,取决于我们从发现到切换的过程的有多快
- 正确?
- 操作只从一台机器上发起
- 所有操作返回前都已经复制到另一台机器了
小结
- 当主副本失效时,为了使得算法简单
- 我们人肉切换,只要足够快
- 我们还是可以保证较高的可用性。
- 但是如何保证主副本是真的失效了呢?
- 在切换的过程中,主副本又开始接收client 端的请求
- 两个主副本显然是不正确的,log会被覆盖写掉
- 我们希望算法能在这种场景下仍然保持正确
- 要是增加到三个节点呢?
- 每次都等其他节点操落盘性能较差
- 能不能允许少数节点挂了的情况下,仍然可以工作
- falut-tolerance
共识算法
-
什么是共识算法
- "The consensus problem requires agreement among a number of processes (or agents) for a single data value. Some of the processes (agents) may fail or be unreliable in other ways, so consensus protocols must be fault tolerant or resilient"
- 简而言之一个值一旦确定,所有人都认同。
-
有文章证明是一个不可能的任务( FLP impossibility )
- "In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliableit delivers all messages correctly and exactly once." -- JACM 85 [1]
-
错误总是发生:
- Non-Byzantine fault
-
错误类型很多
- 网络断开,分区,缓慢,重传,乱序
- CPU、I0 都机会停住
-
容错 ( falute-tolerance )
非拜占庭错误都很复杂,拜占庭就更难了orz
- 共识协议不等于一致性
- 应用层面不同的一致性,都可以用共识协议来实现
- 比如可以故意返回旧的值
- 简单的复制协议也可以提供线性一致性
- 应用层面不同的一致性,都可以用共识协议来实现
- 一般讨论共识协议时提到的一致性,都指线性一致性
- 因为弱一致性往往可以使用相对简单的复制算法实现
一致性协议:Raft
Paxos
- The Part-Time Parliamen by Lamport 1989
- 也就是人们提到的Paxos
- 基本上就是一致性协议的的同义词
- 该算法的正确性是经过证明的
- 那么问题解决了吗?
- Paxos是出了名的难以理解,Lamport本人在01年又写了-篇Paxos Made Simple
- "The Paxos Algorighm, when presented in plain English, is very simple.
- 算法整体是以比较抽象的形式描述,工程实现时需要做一些修改
- Google在实现Chubby的时候是这样描述的
- here are significant gaps between the description of the Paxos algorithm and the needs of a real-world system...... The final system will be based on an unproven protocol .
- Paxos是出了名的难以理解,Lamport本人在01年又写了-篇Paxos Made Simple
Raft
- 2014年发表
- 易于理解作为算法的设计目标
- 使用了RSM、Log、RPC的概念
- 直接使用RPC对算法进行了描述
- Strong Leader-based
- 使用了随机的方法减少约束
- 正确性
- 形式化验证
- 拥有大量成熟系统
运用Raft的分布式产品:TiKV, etc, Cockroach DB等等
复制状态机
RSM: Replicated state machine
- RSM ( replicated state machine )
- Raft中所有的consensus都是直接使用Log作为载体
- Commited Index
- 一旦Raft更新Commited Index,意味着这个Index前的所有Log都可以提交给状态机了
- Commited Index是不持久化的,状态机也是volatile 的,重启后从第一条Log开始
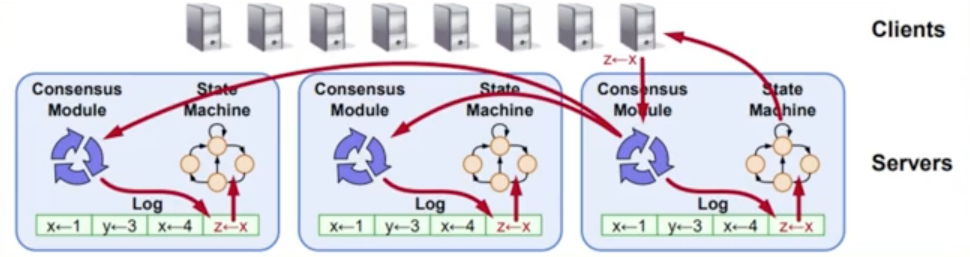
Raft角色
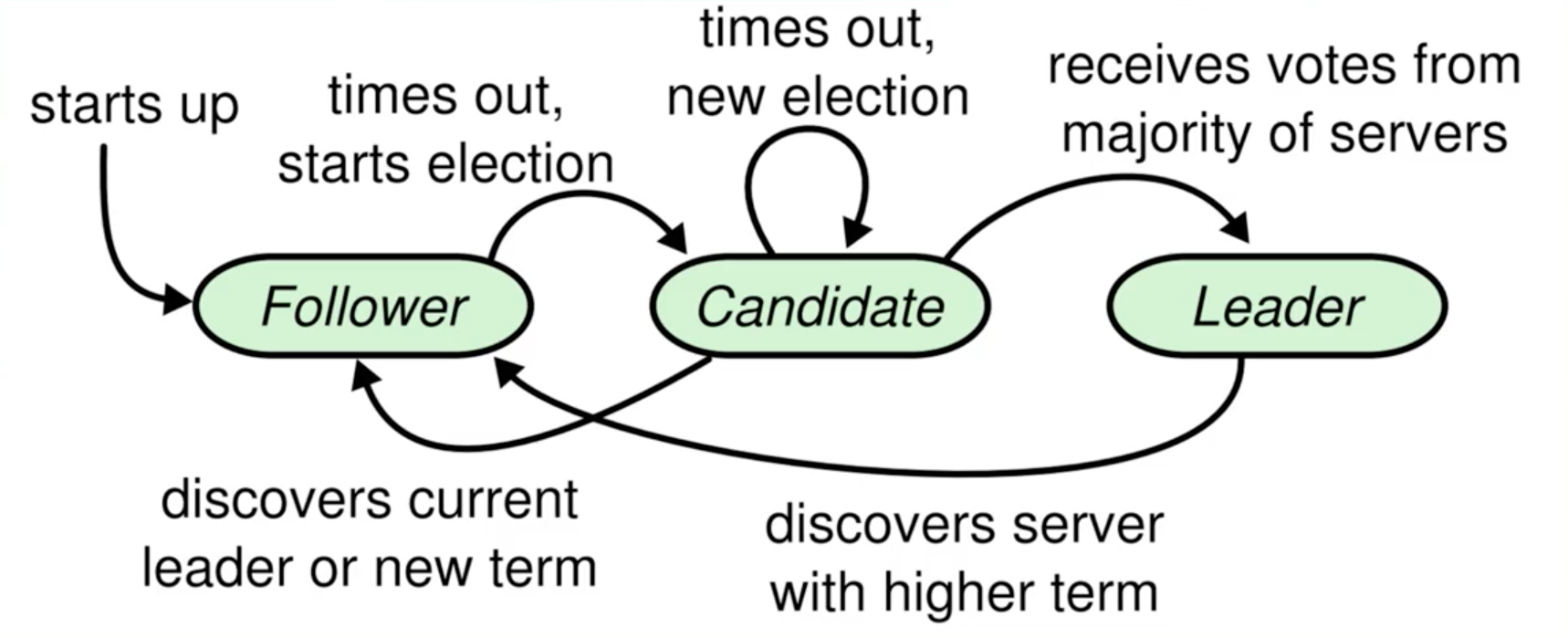
Raft日志复制
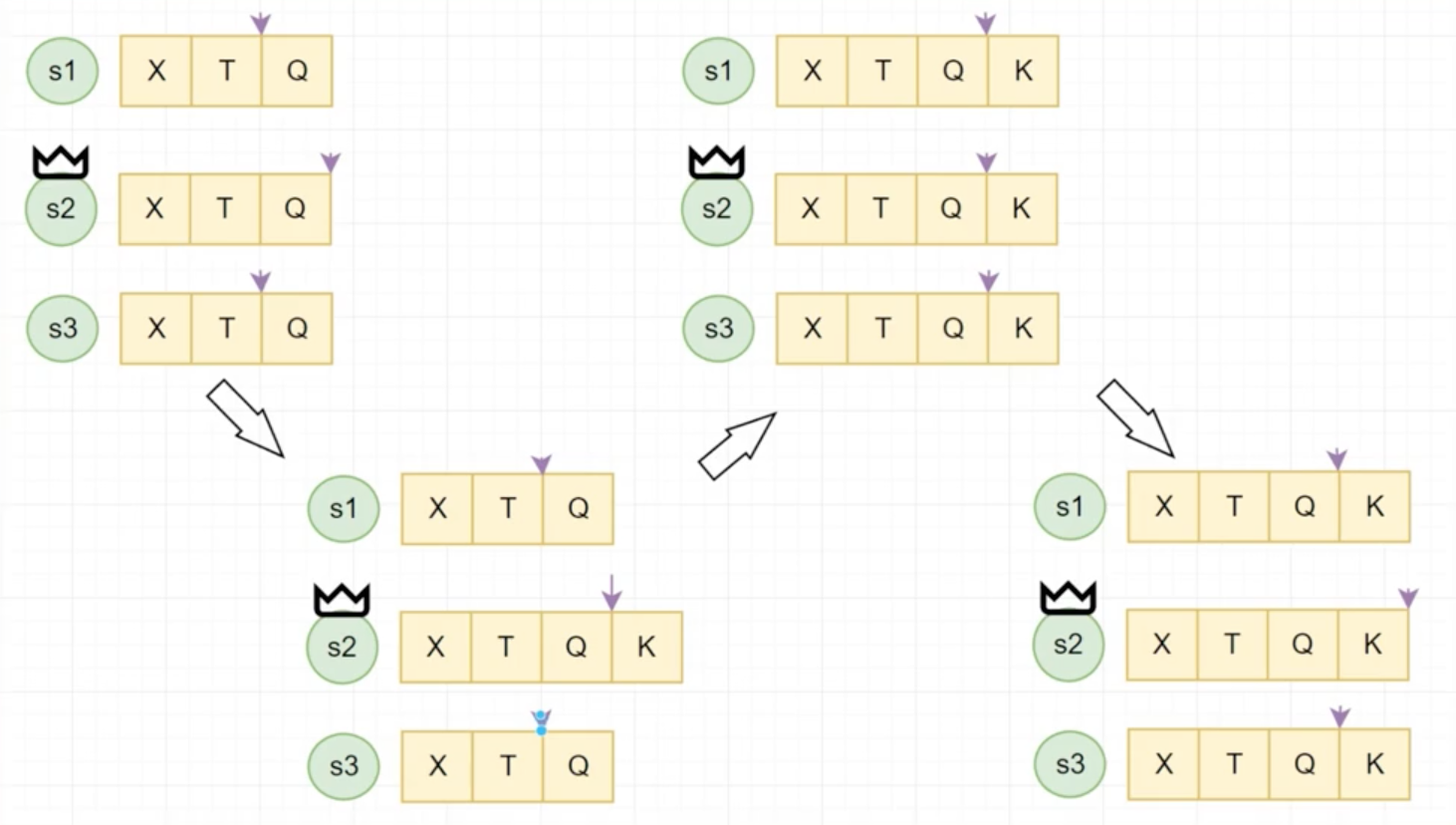
Commit Index在各个节点上是不一致的,最终会看到,但是看到的时间不一定。
复制操作在Raft中十分重要,叫Append Entry
Raft从结点失效
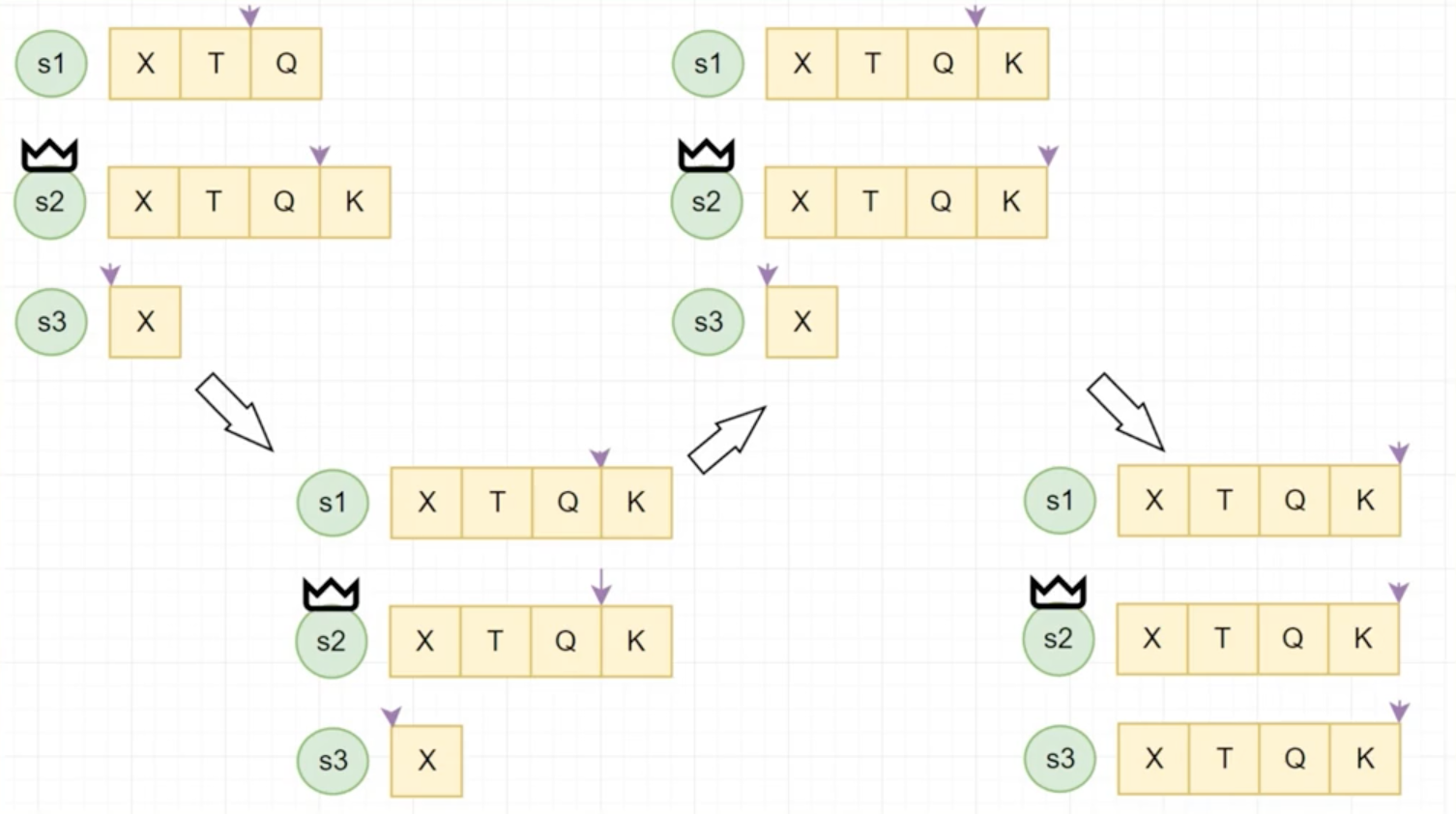
Raft不对比Log的内容,对比的是Index嘛!!!
Raft Term
- 每个Leader服务于一个term
- 每个term至多只有一个leader
- 每个节点存储当前的term
- 每个节点term从一开始,只增不减
- 所有rpc的request reponse都携带term
- 只commit本term内的log
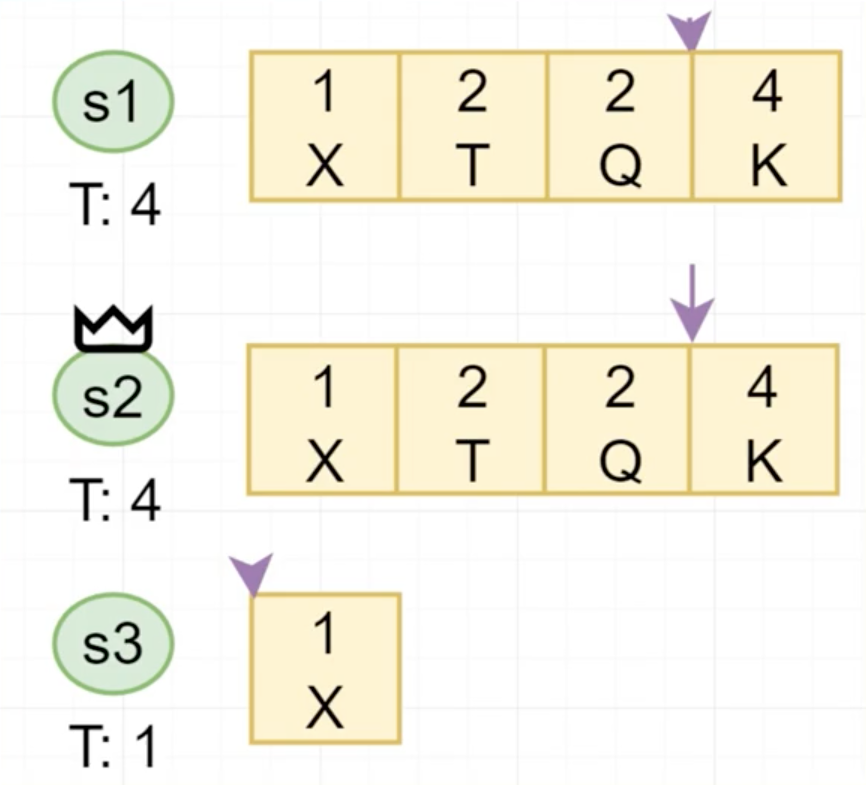
Raft主节点失效
- Leader定期的发送AppendEntries RPCs给其余所有节点
- 如果Follower有一-段时间没有收到Leader的AppendEntries,则转换身份成为Candidate
- Candidate自增自己的term,同时使用RequestVote RPCs向剩余节点请求投票
- raft在检查是否可以投票时,会检查log是否outdated,至少不比本身旧才会投给对应的Candidate
- 如果多数派节点投给它,则成为该term的leader
Raft Leader failure
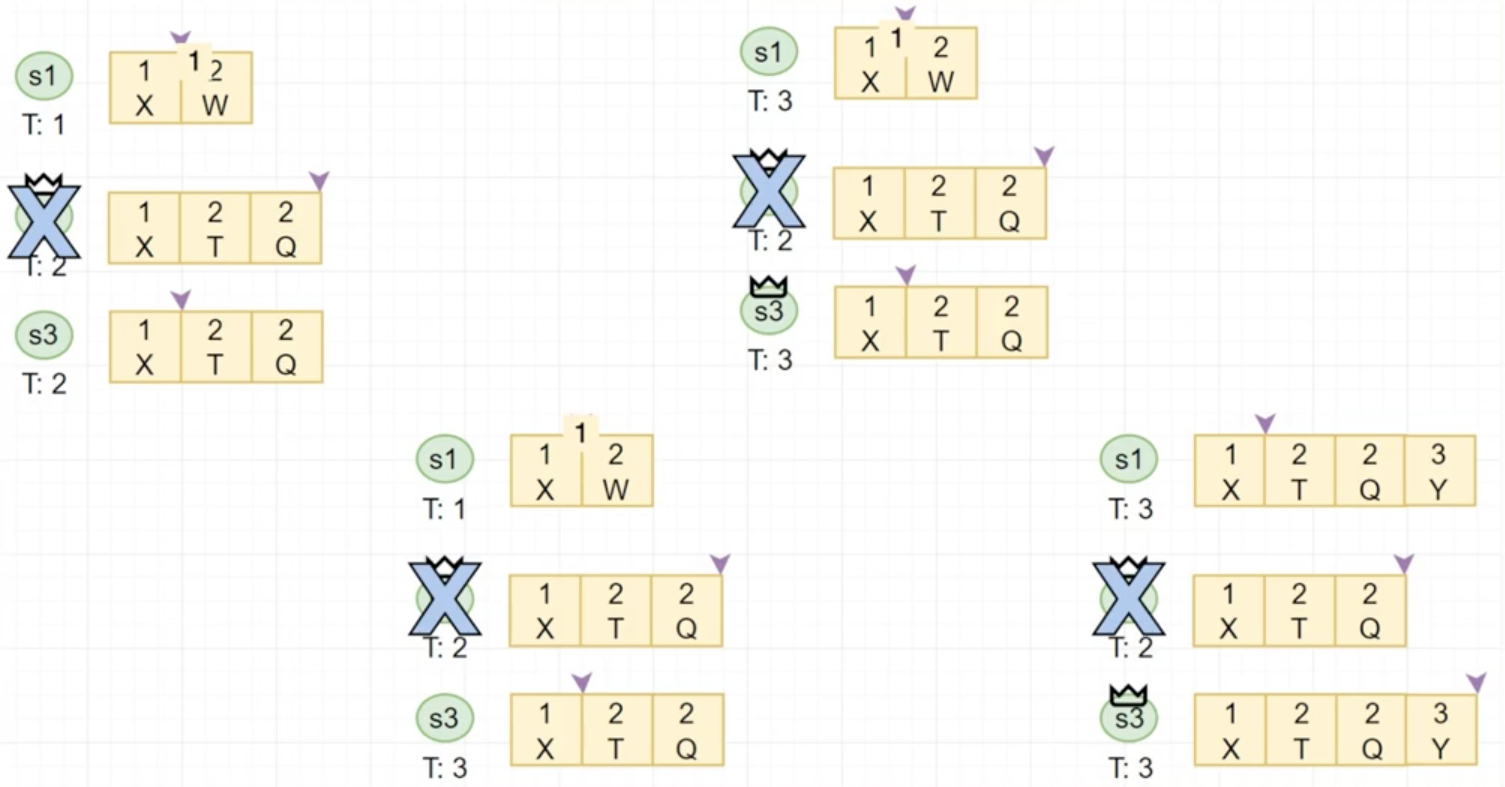
Raft安全性
同Term
- 对于Term内的安全性
- 目标:
- 对于所有已经的commited的<term, index>位置上至多只有一条log
- 目标:
- 由于Raft的多数派选举,我们可以保证在一个term 中只有一个leader
- 我们可以证明一条更严格的声明:在任何<term,index>位置上,至多只有一条log
跨Term
- 对于跨Term的安全性
- 目标:
- 如果一个log被标记commited,那这个log - -定会在未来所有的leader中出现Leader completeness
- 目标:
- 可以证明这个property
- Raft选举时会检查Log的是否outdated,只有最新的才能当选Leader
- 选举需要多数派投票,而commited log也已经在多数派中(必有overlap )
- 新Leader一定持有commited log,且Leader永远不会overwrite log
Raft安全性验证
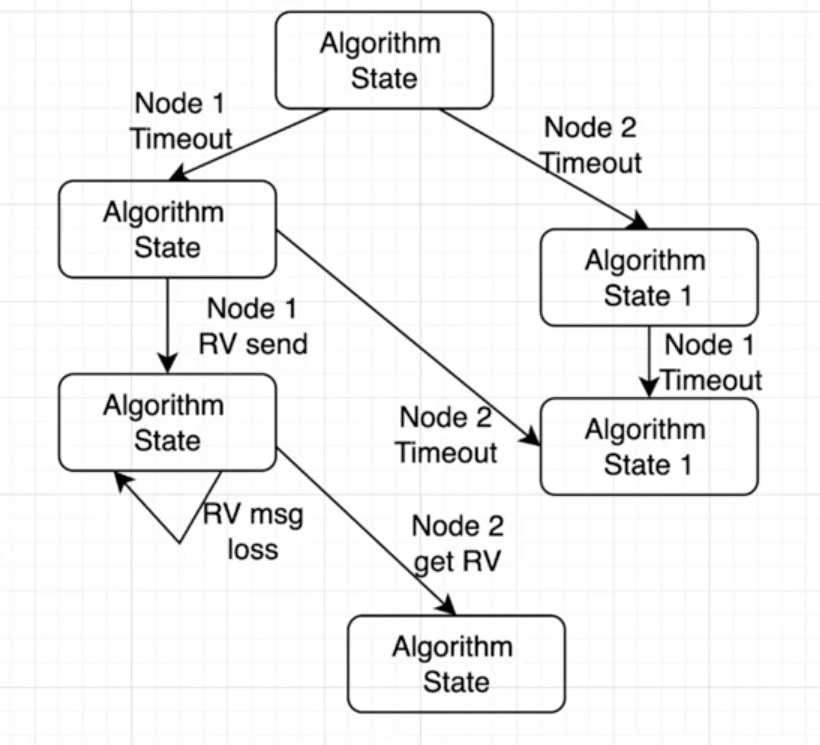
.
-
真的安全吗
-
Raft使用TLA+进行了验证
- 形式验证( Formal Method )
以数学的形式对算法进行表达,
由计算机程序对算法所有的状态进行遍历
-
NJU的JYY就是神仙!!!形式化验证!!!对于所有情况进行遍历,验证了是正确的昂!!!状态机就是最牛批的!!!
实现细节以及未来
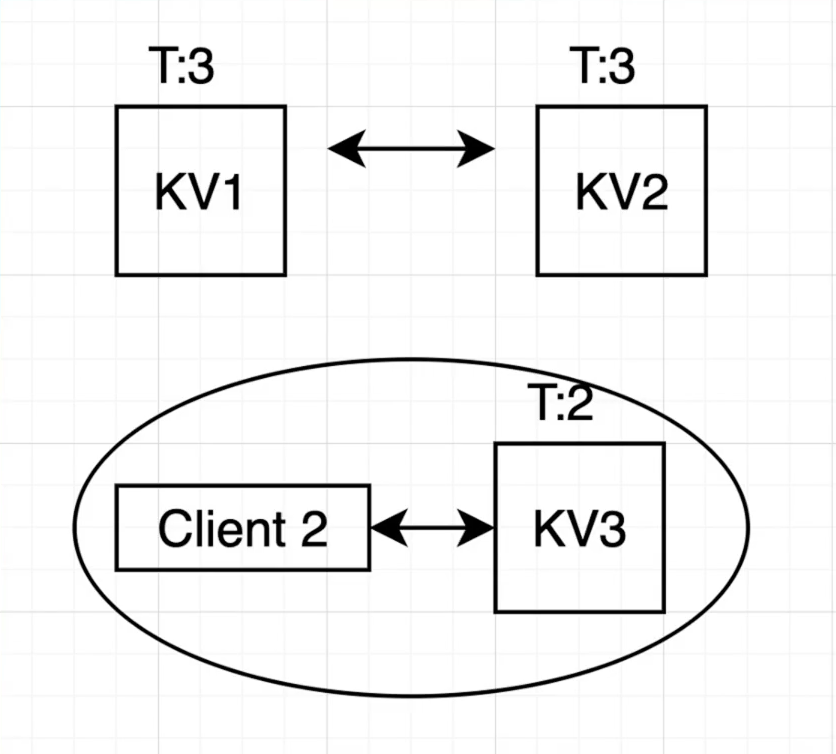
案例-KV
利用Raft算法,重新打造我们的KV
- 回顾一下一致性读写的定义
- 方案一:
- 写log被commit了,返回客户端成功,
- 读操作也写入一条 log,状态机apply时返回client
- 增加Log量
- 方案二:
- 写log被commit了,返回客户端成功
- 读操作先等待所有commited log apply,再读取状态机
- 优化写时延
- 方案三:
- 写Log被状态机apply,返回给client
- 读操作直接读状态机
- 优化读时延
- 方案一:
- Raft不保证一直有一个Leader
- 只保证一个Term至多有一个Leader
- 可能存在多个Term的Leader
- Split-brain
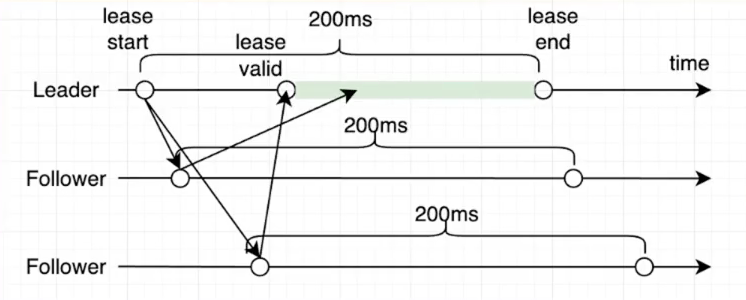
- 确定合法的Leadership
- 方案一:
- 通过一轮Heartbeat确认Leadership (获取多数派的响应)
- 方案二:
- 通过上一次Heartbeat时间来保证接下来的有段时间内follower不会timeout
- 同时follower在这段时间内不进行投票
- 如果多数follower满足条件,那么在这段时间内则保证不会有新的Leader产生
- 方案一:
- 结合实际情况选择方案二 or 方案三,同时搭配这里的方案一 or 方案二,解决脑裂的问题昂:取决于Raft的实现程度以及读写的情况
Raft组
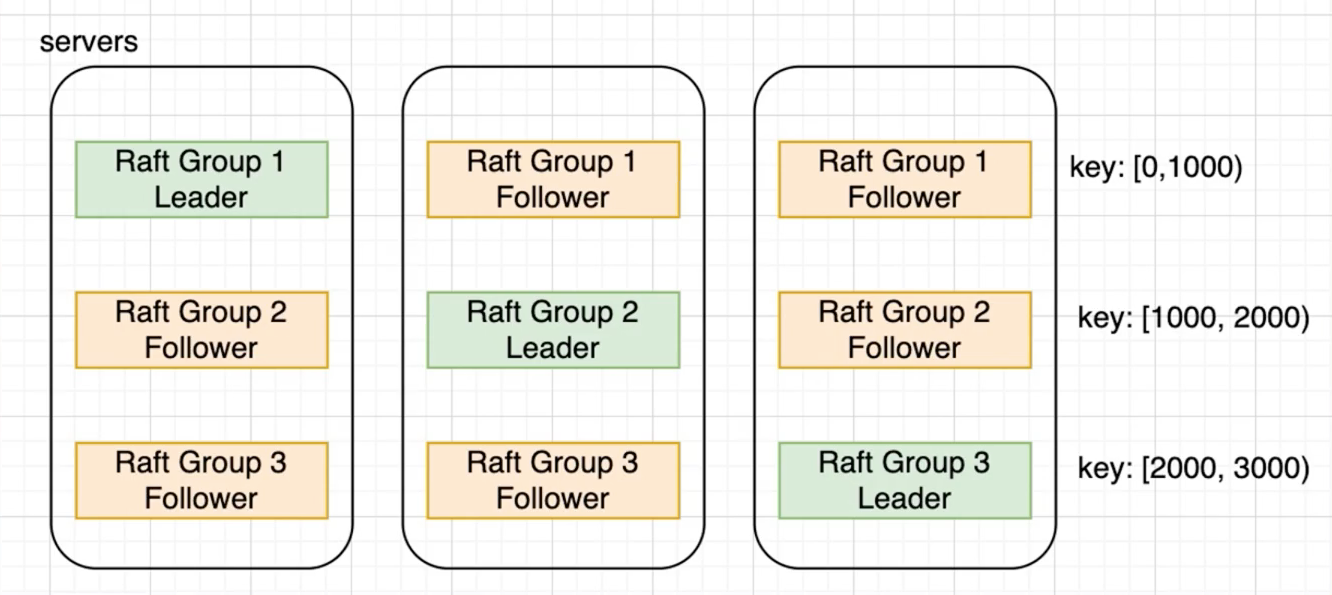
- 多个副本只有单个副本可以提供服务
- 服务无法水平拓展
- 增加更多Raft组
- 如果操作跨Raft组
跨Raft组很重要昂!!!按照Key进行切分成不同的Raft组,提高并行度,工业上实现的昂!!!
回到共识算法
Snapshot & Configuration Change
- Raft : 关于Log
- 论文中就给出的方案,当过多的Log占用后,启动snapshot,替换掉Log
- 如果对于持久化的状态机,如何快速的产生Snapshot
- 多组Raft的应用中,Log如何合流
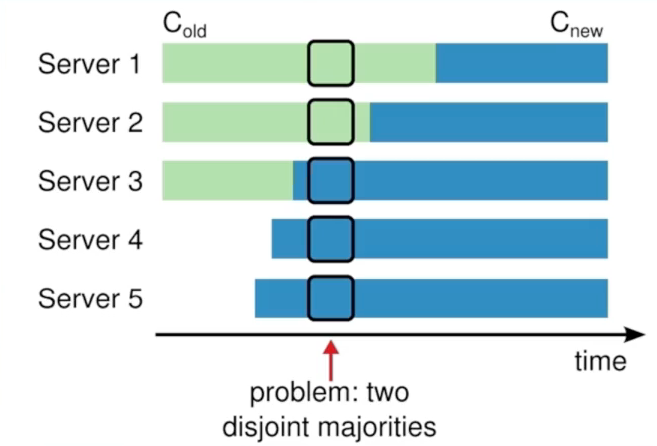
- 关于configuration change
- 论文中给出的joint-consensus以及单一节点变更两种方案
Byzantine Failure
- Raft是正确的,但是在工程世界呢?
- 真实世界中不是所有的错误都是完美fail-stop 的
- cloudflare的case,etcd在partial network下, outage 了6个小时[1]
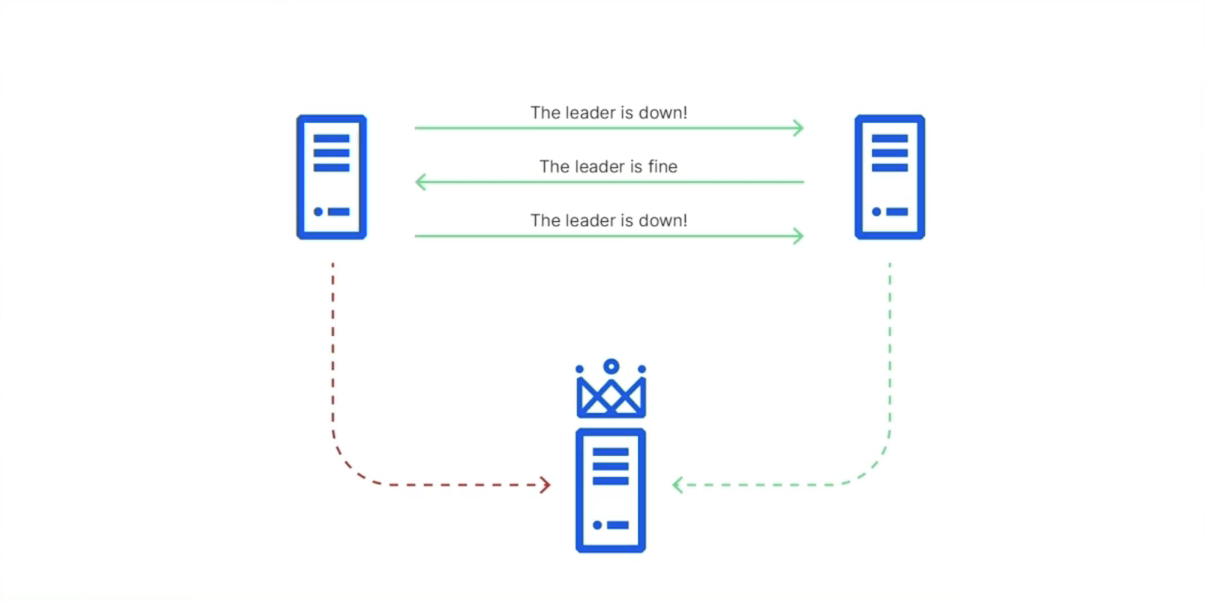
裂开,左右的通信是正常的,左下的通信是寄了的。右下选好了,左下一直detect不到Leader的心跳,一直在update term,一直打扰已经选好的主,麻了。 -> Promote方法去做昂!!!
共识算法的未来
高性能
- 数据中心网络100G,时延约为几个us
- RDMA网卡以及programmable switch的应用
- 我们想要的是: us级别的共识,以及us级别的容错
- HovercRaft
- P4 programable switch : IP multicast
- Mu
- Use one-sided RDMA.
- pull based heartbeat instead of push-based.
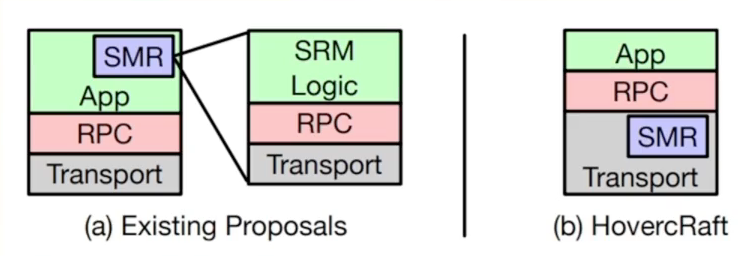
相当于把SMR和类似的Raft协议下推,实现到Switch上,上层APP不感知,从而提高整体效率,超高性能昂!!!
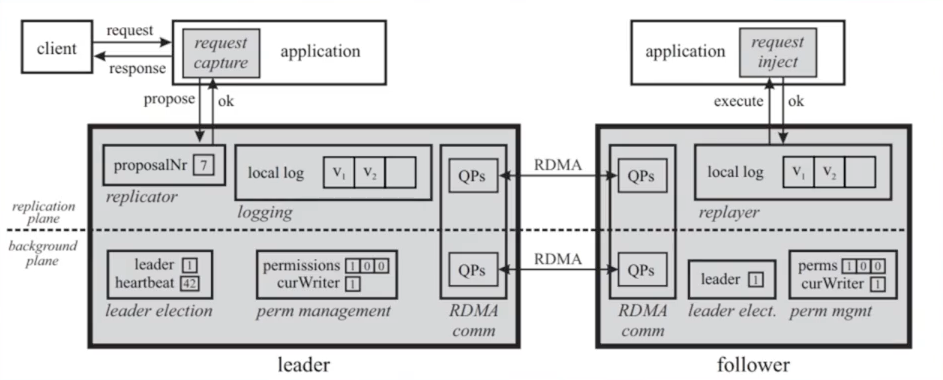
多节点提交(Leaderless)
- 节点跨地域,导致节点间的RTT(Round Trip Time)很大
- EPaxos[1]
- 使用了冲突图的方式来允许并行Commit
- 不冲突的情况下1RTT提交时间
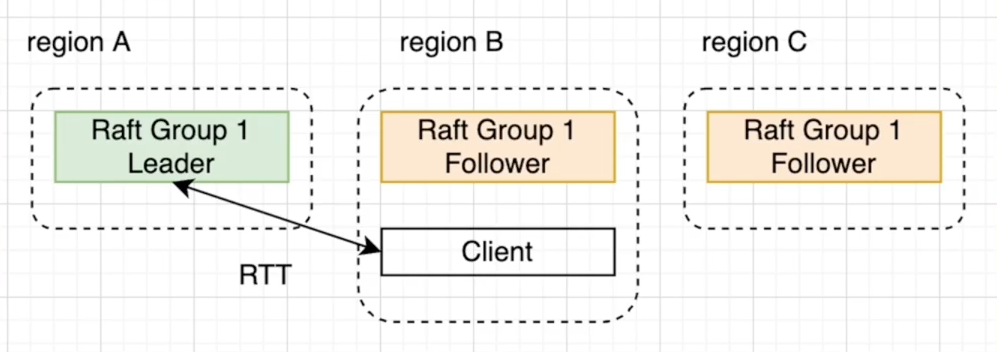
Raft Paxos相互移植
- Raft Paxos相互移植
- Raft有很多成熟的实现
- 研究主要关注在Paxos上
- 如何关联两种算法
- On the Parallels between Paxos and Raft, and how to Port Optimizations[1]
- Paxos VS Raft: Have we reached consensus on distributed consensus?[2]
共识算法作为一个系统
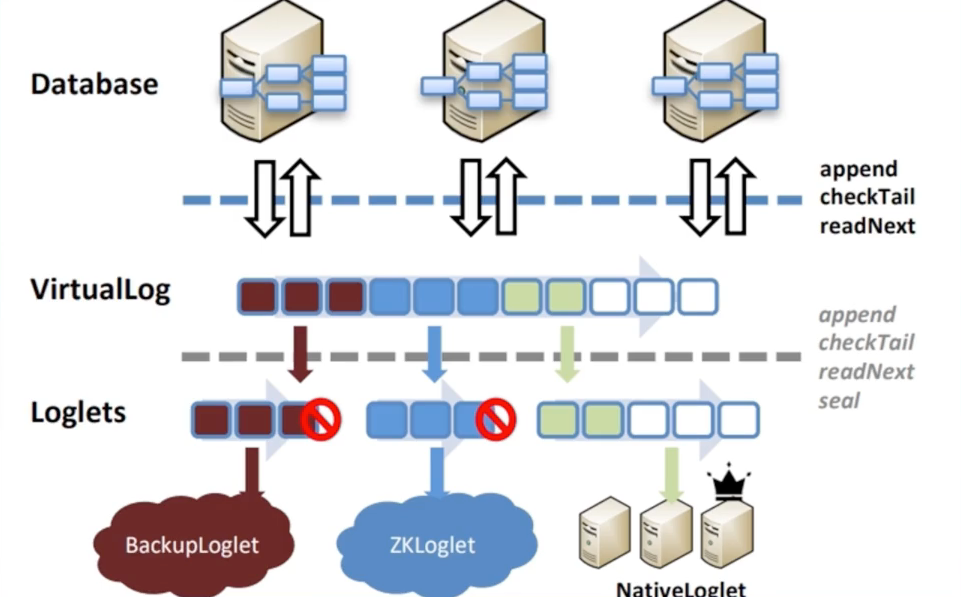
- 共识算法作为一个系统
- 多数分布式系统都选择共识算法作为底座
- 不同一致性协议有不同的特性
- Virtual consensus in delos[1]
- 对外暴露一致性的LOG作为接口
- 内部对于LOG可以选择不同的实现
References
- [1] Michael J. Fischer, Nancy A. Lynch, Mike Paterson: Impossibility of Distributed Consensus with One Faulty Process. PODS 1983
- On the Parallels between Paxos and Raft, and how to Port Optimizations[1]
- Paxos VS Raft: Have we reached consensus on distributed consensus?[2]
