一. 什么是建模?模型又是什么?
建模,是人们为了理解事物而对事物做出的一种抽象,是对事务进行书面无歧义的描述。
模型就是对实际问题或者是客观规律进行的形式化的表达。
二. 关于语言模型
长久以来,人们一直希望计算机可以理解我们人类的语言,从而进行一系列其他的应用,比如机器翻译,语音识别,分词,输入法,搜
索引擎的自动补全等。以前人们是进行基于规则的语言模型的研究方向,遇到了很大的问题,后来便出现了基于统计的语言模型,这些
在《数学之美》中吴军老师有进行详细的介绍。那么,当下人们使用最多,应用最广的便是n元语言模型。其实这个模型本质上就是在
判断一个句子是句子的概率.
三. N-gram model
1. 定义
假设一个句子是由{w1,w2,w3,...wn},来表示的,其中wi表示的句子中的单词,那么,一个语言模型就可以用如下来表示:
P={w1,w2,w3,...wn}
那么我们将如何来计算呢?
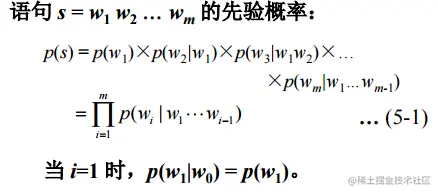 从公式可以看出,我们要计算这样一个表达式的,是非常困难的,于是,这个时候马尔可夫链便发挥了重大作用。
从公式可以看出,我们要计算这样一个表达式的,是非常困难的,于是,这个时候马尔可夫链便发挥了重大作用。
2.什么是马尔可夫链?
马尔科夫链描述的是一个随机状态,他指出某个状态只与其前(后)一个或者两个状态有关系,再往前的状态对当前状态的影响可以忽略不
算,这个整体还是比较符合人民的认知的。按照这个理论的话,上面的计算便可以简化,因为:
P{wm∣w1,w2,...wn}=P{wm∣wm−1,wm−2}
以上就是一个简单的三阶马尔可夫链,也就是三元语言模型,属于二阶马尔科夫假设。

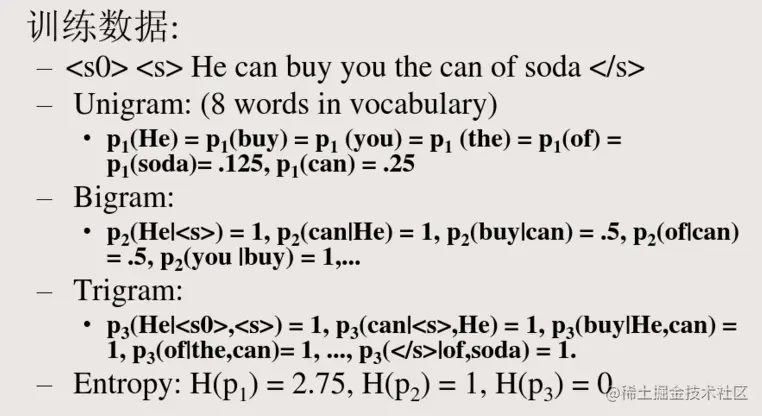
3.n-gram 模型应用举例
P(PinYin) = ta shi yan jiu sheng wu de
那么对应的可能的汉语是:
P(CString)= 他是研究生物的
=踏实研究生物的
=他实验救生物的
=.......
那么究竟应该要翻译为哪一个句子才是对的,假设我们次用2元语言模型,其实就是在求每一个句子出现的概率。
P(CString1)=P(他∣<BOS>)∗P(是∣他)∗P(研究∣是)∗P(生物∣研究)∗P(的∣生物)∗P(<EOS>∣的);
P(CString2)=P(踏实∣<BOS>)∗P(研究∣踏实)∗P(生物∣研究)∗P(的∣生物)∗P(<EOS>∣的);
- 中文分词
其实从上面就可以看出来,想要计算上面的表达式,首先就需要去进行中文分词。
那么假设已经分好词了,如何计算上面的表达式呢?
这里需要提及两个概念。
- 训练语料库 :training data. 用来训练模型的语料库。其实说简单点儿,就是比如人民日报啊,各种文献中的的句子的数据库罢了。
- 最大似然估计法:maximum like evaluation,MLE. 就是利用统计词频的办法来代替概率的计算。
4.参数估计
例如,给定训练语料:
“John read Moby Dick”,
“Mary read a different book”,
“She read a book by Cher”
根据 2 元文法求句子(She read a book.)的概率?
P(She∣<BOS>)=∑wc(<BOS>,w)c(<BOS>,She)=31
P(read∣She)=∑wc(She,w)c(read,She)=11=1
P(a∣read>)=∑wc(read,w)c(read,a)=32
P(book∣a>)=∑wc(a,w)c(book,a)=21
P(<EOS>∣book>)=∑wc(book,w)c(book,<EOS>)=21
P(She read a book) = 31∗1∗32∗32∗41=271
这样便解决了我们的问题。
但是考虑这样一个场景,假设我们想要分词的句子是:He read a book.
这样,由于He这个单词在语料库中从未出现过,导致句子概率为0,显然是不合理的。
这个问题的出现,主要是由于语料库数据稀少的原因,我们采用数据平滑的办法来解决。
本文同步在个人博客,开启掘金成长之旅!这是我参与 「掘金日新计划 · 2 月更文挑战」的第 18 天,点击查看活动详情


