

这是我参与「第五届青训营 」伴学笔记创作活动的第 30 天 本节课程主要围绕着消息队列概述展开,首先对消息队列进行了基本的概述,随后重点介绍了消息队列的三个应用场景:MQ 消息通道、EventBridge 事件总线、Data Platform 流数据平台,以及它们在各个领域所扮演的角色,通过学习本节课程能够对消息队列有一个具体的了解。
消息队列概述
消息队列应用场景
- MQ信息通道
- EventBridge事件总线
- Data Platform流数据处理平台
MQ消息通道
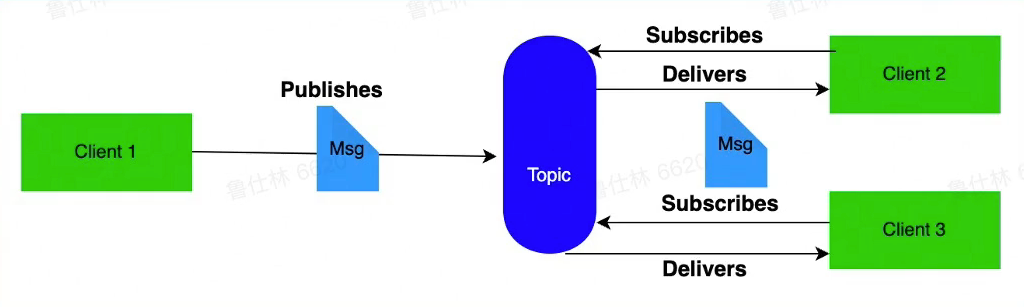
- 优势:
- 异步解耦
- 削峰填谷(下游如果寄了,暂时可以把消息缓存在MQ中)
- 发布订阅
- 高可用
EventBridge数据总线
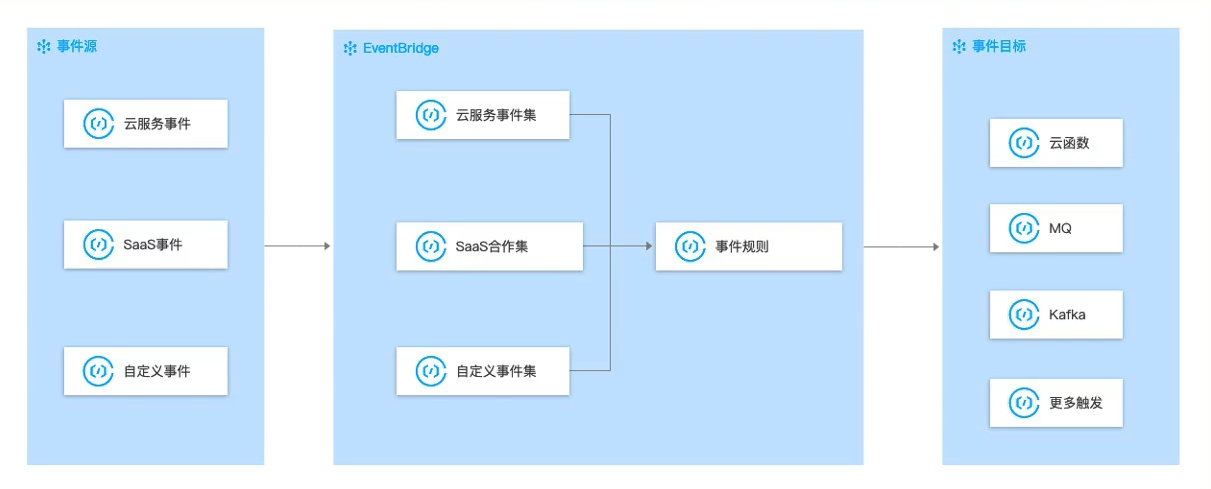
- 事件源: 将云服务、自定义应用、SaaS 应用等应用程序产生的事件消息发布到事件集。
- 事件集:存储接收到的事件消息,并根据事件规则将事件消息路由到事件目标。
- 事件目标:消费事件消息。
Data Platform流数据平台
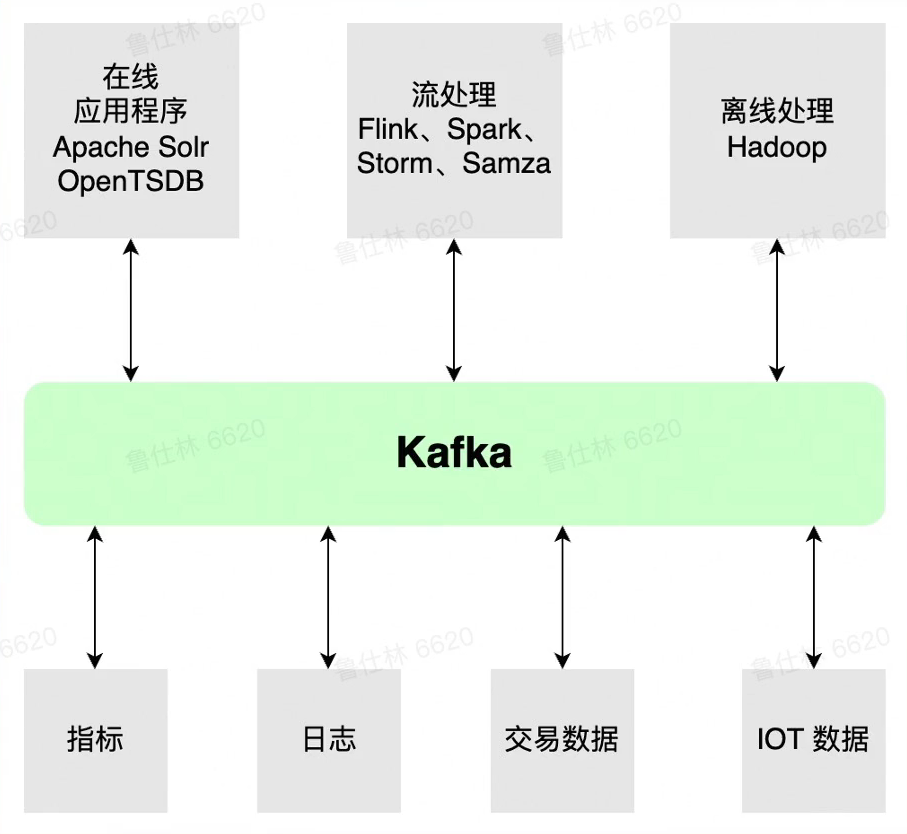
- 提供批/流数据处理能力
- 各类组件提供各类Connect
- 提供Streaming/Function能力
- 根据数据schema灵活的进行数据预处理
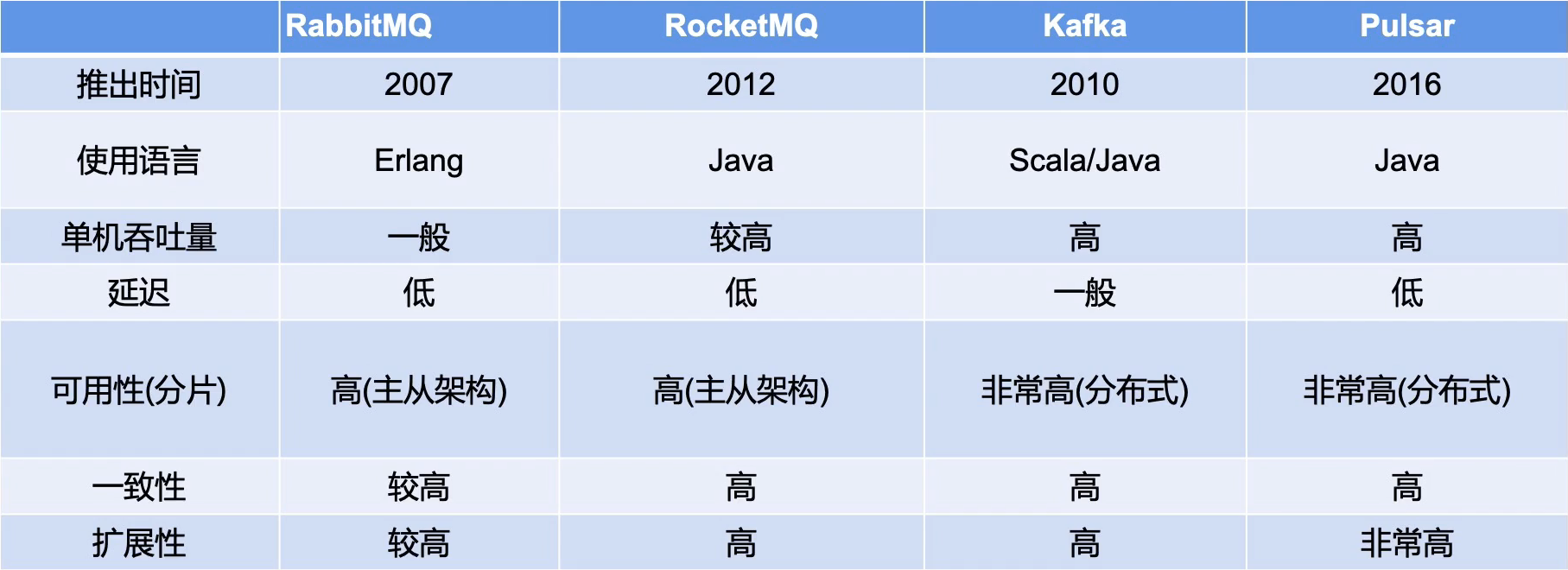
主流消息队列的相关介绍
Kakfa详解
Kafka架构介绍
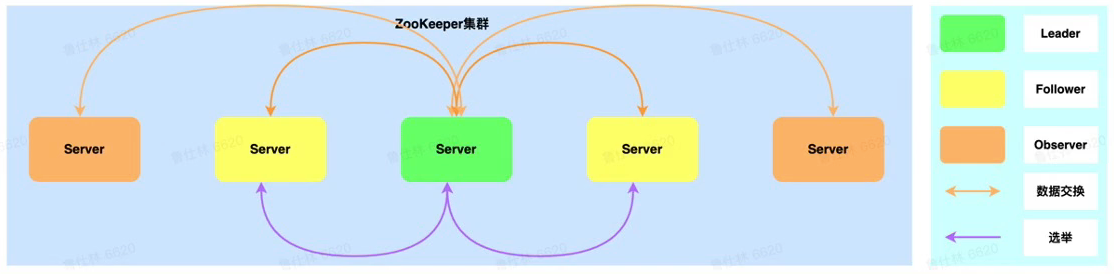
Zookeeper
-
选举机制: Paxos机制
-
提供一致性:
- 写入(强一致性)
- 读取(会话一致性)
-
提供可用性:
- 一半以上节点存活即可读写
-
提供功能:
- watch机制
- 持久/临时节点能力
-
Kafka存储数据:
- Broker Meta信息(临时节点)
- Controller信息(临时节点)
- Topic信息(持久节点)
- Config信息(持久节点)
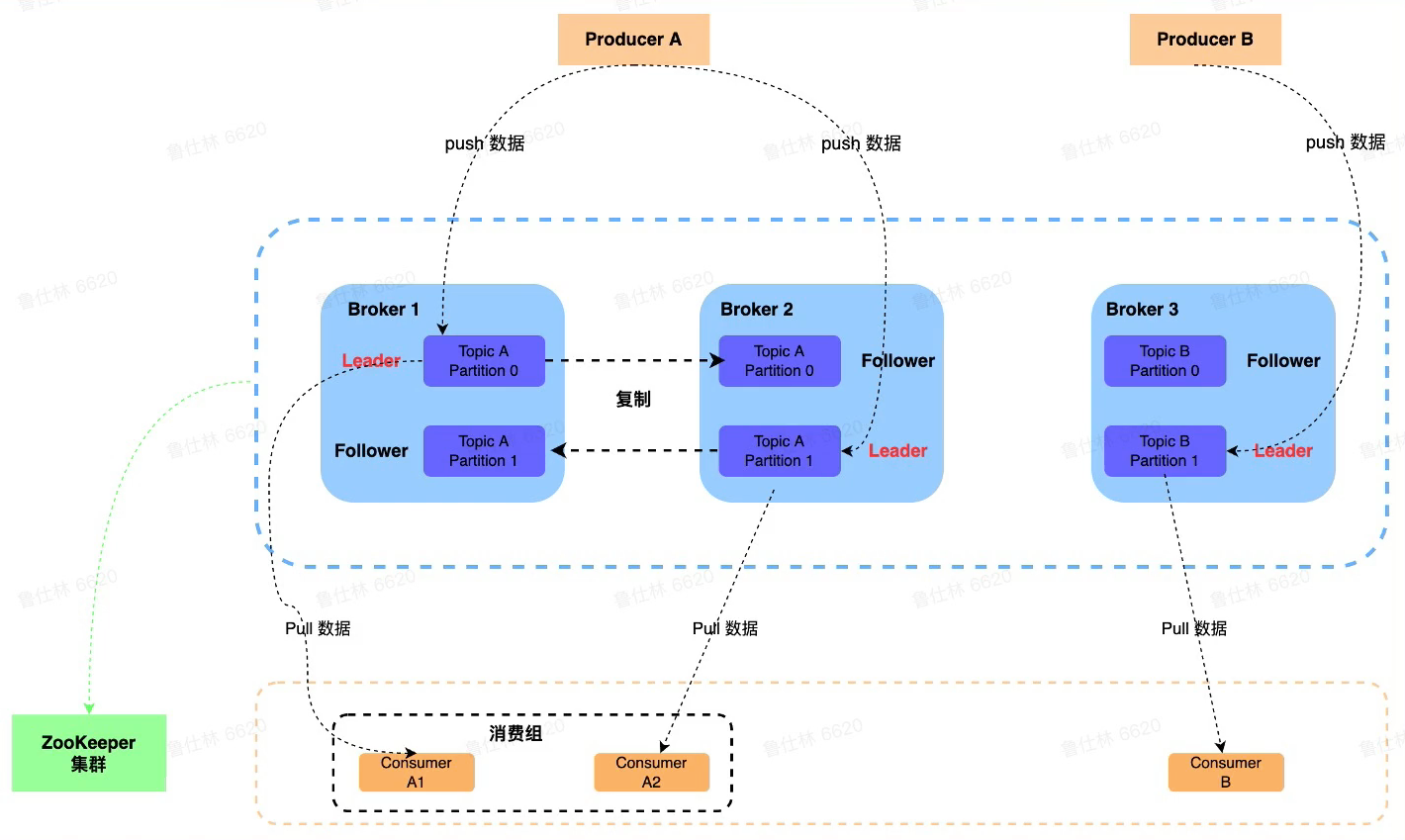
Broker
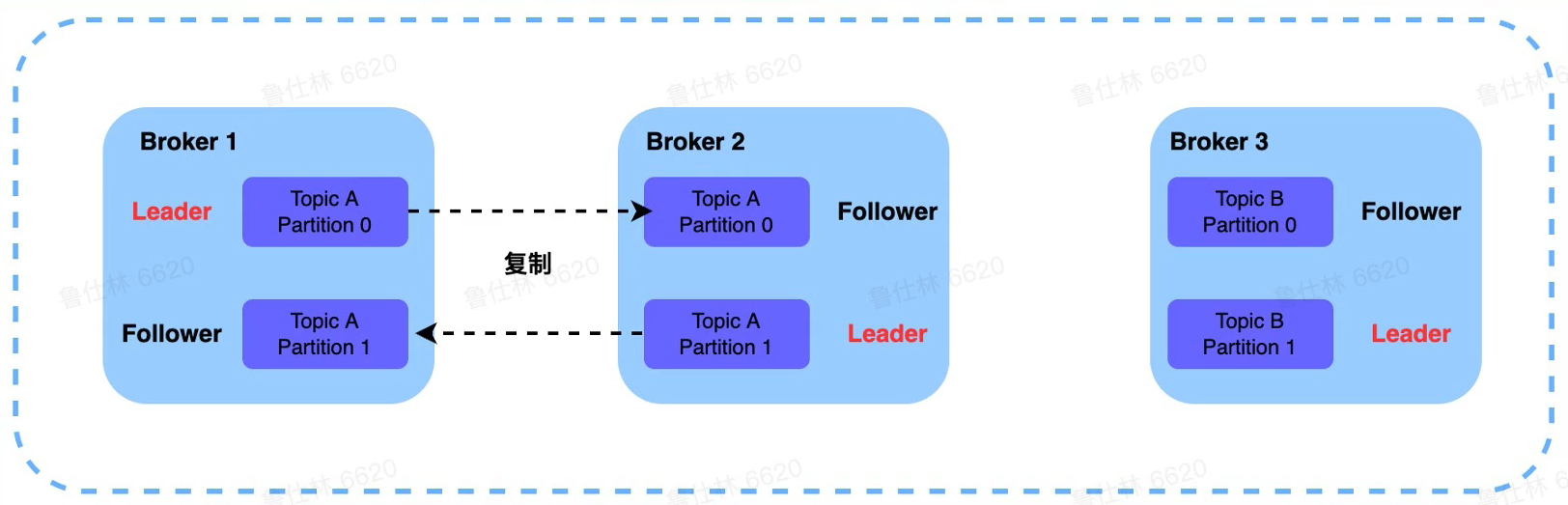
- Broker角色
- 若干个Broker节点组成Kafka集群
- Broker作为消息的接收模块,使用React网络模型进行消息数据的接收
- Broker作为消息的持久化模块,进行消息的副本复制以及持久化
- Broker作为高可用模块,通过副本间的Failover进行高可用保证
Controller
选举
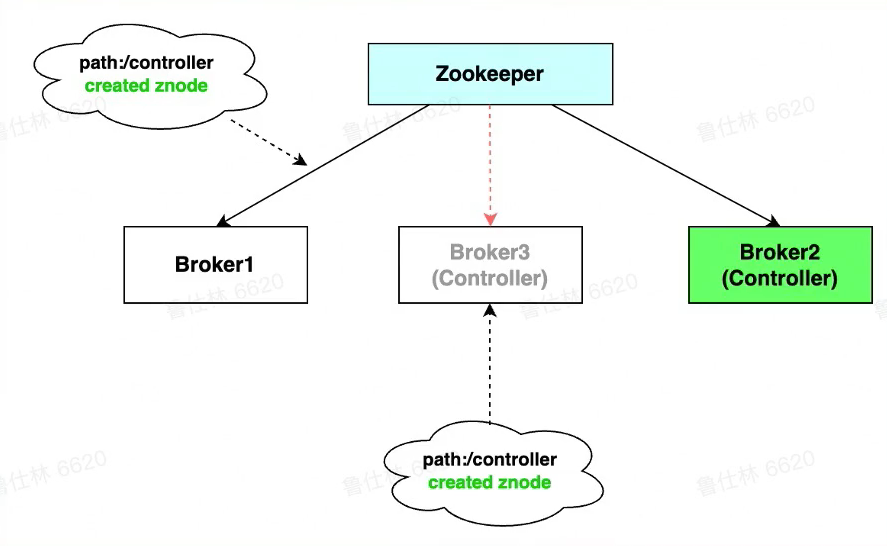
- Controller(特殊的broker):
- Broker启动会尝试去zk中注册controller节点
- 注册上的controller节点的broker即为controller
- 其余broker会watch controller,如果出现异常则重新选举
作用
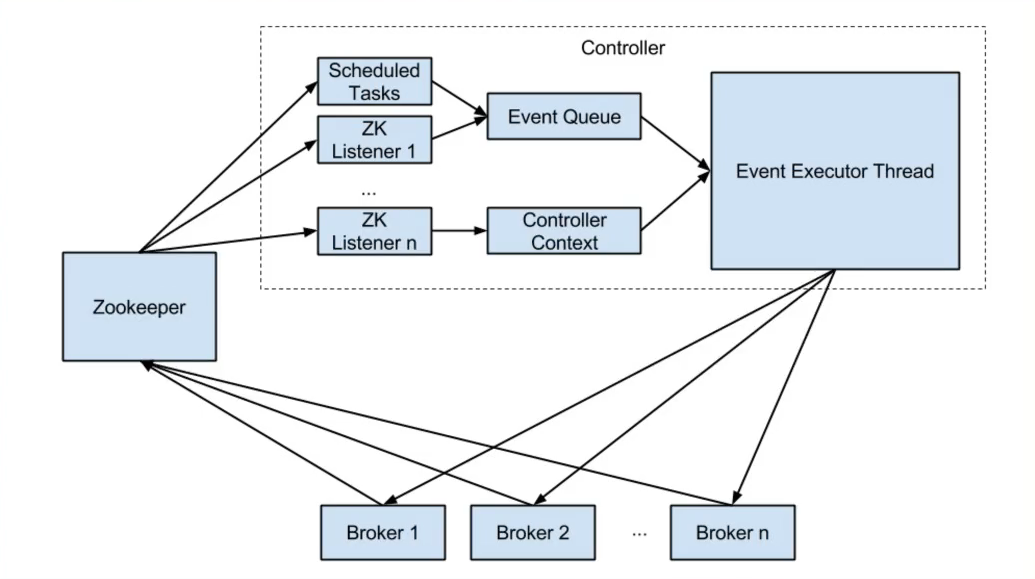
- Controller作用
- Broker重启/宕机时,负责副本的Failover切换
- Topic创建/删除时,负责Topic meta信息广播
- 集群扩缩容时,进行状态控制
- Partition/Replica状态机维护
Coordinator
- 本质也是一个特殊的broker,主要是对于消费端的控制
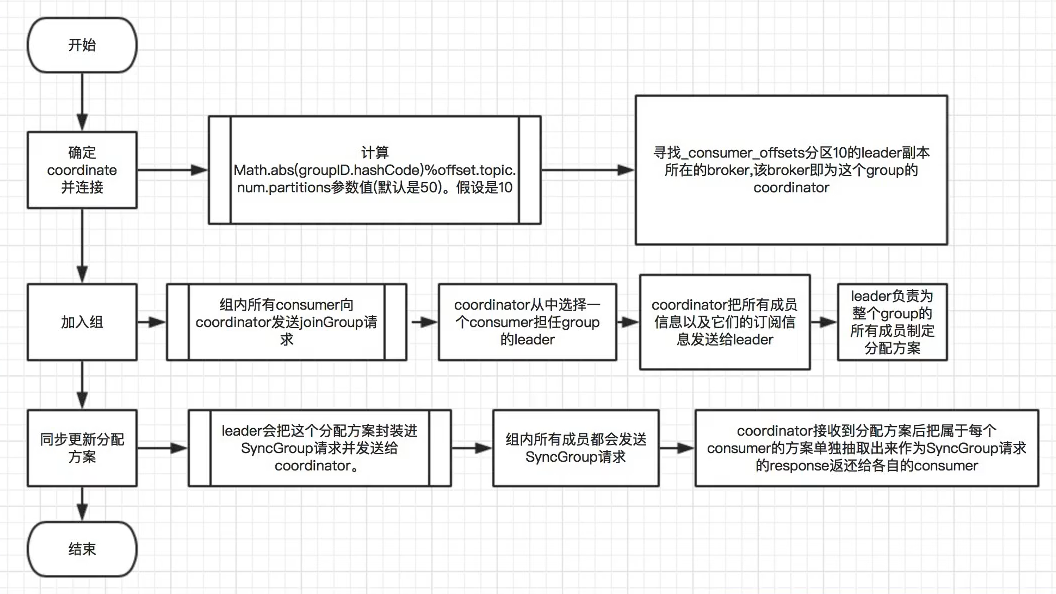
- Coordinator介绍:
- 负责 topic-partition <-> consumer的负载均衡
- 根据不同的场景提供不同的分配策略
- Dynamic Membership Protocol
- Static Membership Protocol
- Incremental Cooperative Rebalance
Kafka高可用
可用性定义
- Kafka高可用
- 副本同步机制
- 提供lsr副本复制机制,提供热备功能
- 写入端提供ack=0,-1, 1机制,控制副本同步强弱
- 副本切换机制
- 提供clean/unclean副本选举机制
- 副本同步机制
副本ISR机制
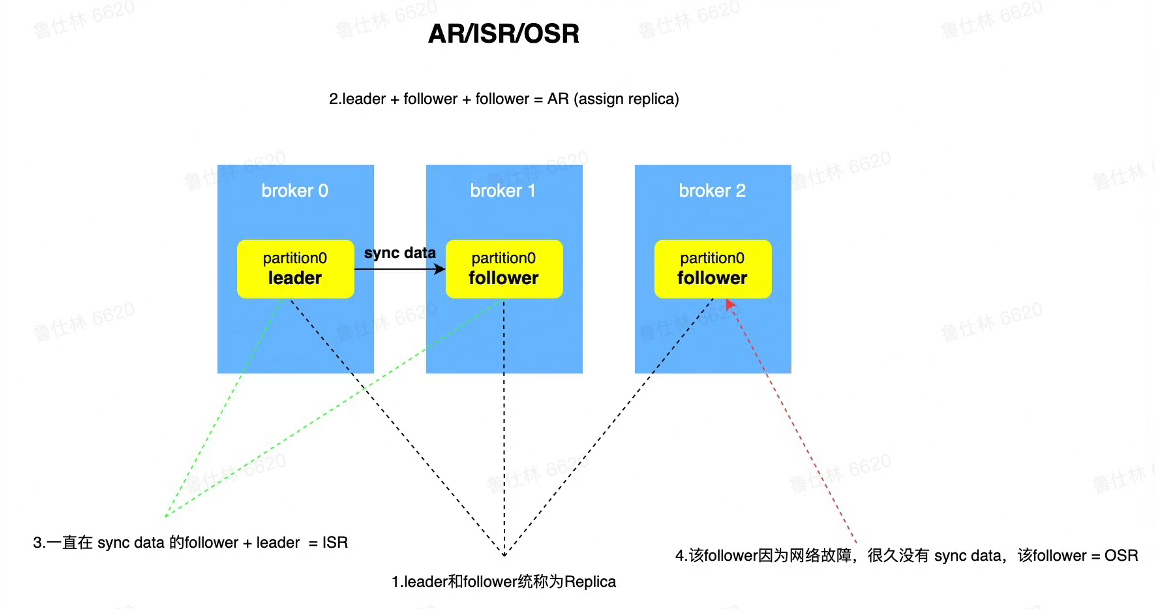
- AR
- Assign Replica ,已经分配的所有副本
- OSR
- Out Sync Replica
- 很久没有同步数据的副本
- ISR
- 一直都在同步数据的副本
- 可以作为热备进行切换的副本
- min.insync.replicas最少isr数量配置
写入Ack机制
- Ack= 1
- Leader副本写入成功, Producer即认为写成功
- Ack=0
- OneWay模式
- Producer发送后即为成功
- Ack = -1
- ISR中所有副本都成功,Producer才认为写成功
Kafka副本
同步
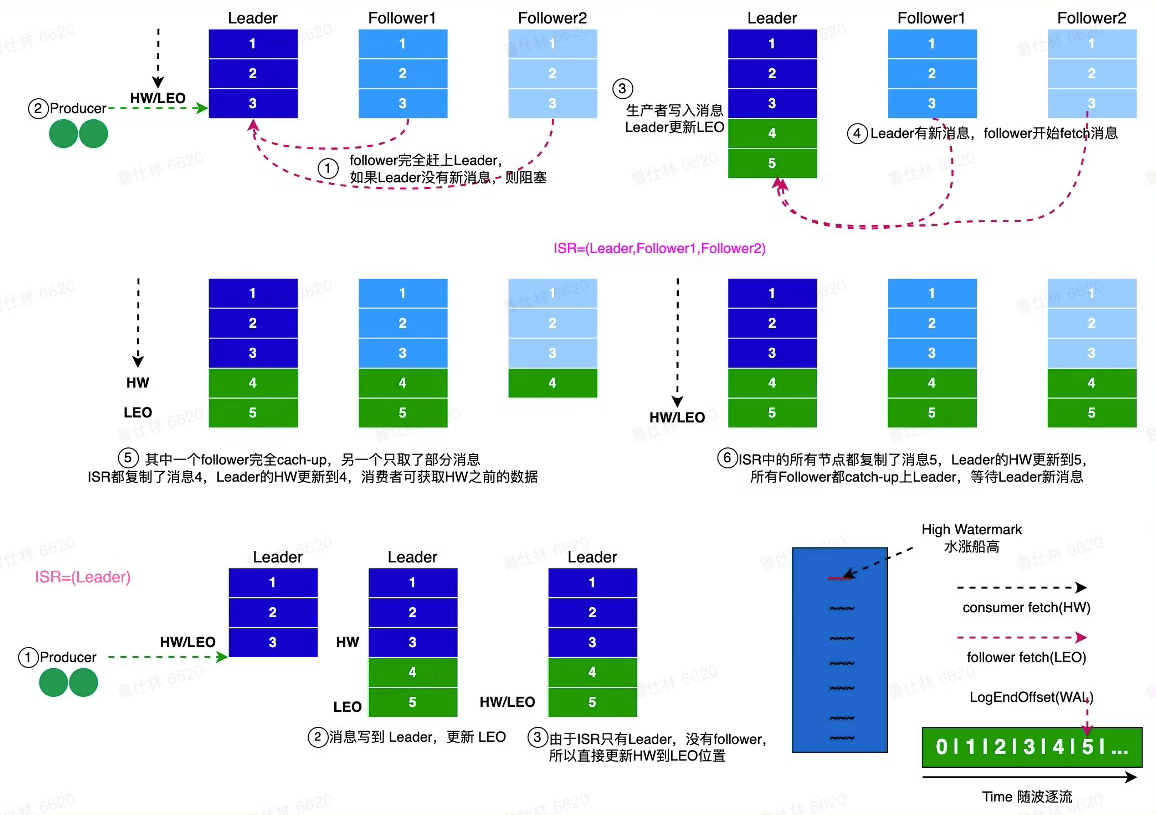
- LEO
- Log End Offset,日志最末尾的数据
- HW
- ISR中最小的LEO作为HW
- HW的消息为Consumer可见的消息
选举

- Clean选举
- 优先选取Isr中的副本作为leader
- 如果Isr中无可用副本,则partition不可用
- Unclean选举
- 优先选取lsr中的副本作为leader
- 如果Isr中无可用副本,则选择其他存活副本
Kafka集群扩缩容
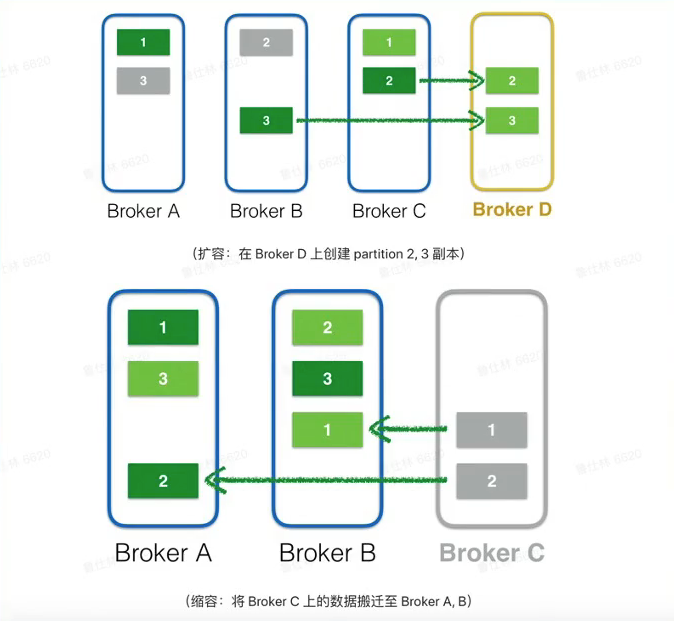
- Kafka集群扩缩容之后的目标
- Topic维度
- partition在各个broker之间分布是均匀的
- 同一个partition的replica 不会分布在一台 broker
- Broker维度
- Broker之间replica的数量是均匀的
- Topic维度
扩缩容步骤
- 扩容Broker节点
- Leader副本写入成功, Producer即认为写成功
- 计算均衡的Replica分布拓扑
- 保证Topic的partition在broker间分布均匀
- 保证Broker之间Replica分布均匀
- Controller负责新的副本分布元数据广播
- Controller将新的leader/follower信息广播给broker
- Broker负责新副本的数据同步
- Broker上有需要同步数据的副本则进行数据同步
扩缩容问题
- 扩缩容时间长
- 涉及到数据迁移,在生产环境中- -次扩缩容可能要迁移TB甚至PB的数据
- 扩缩容期间集群不稳定
- 保证数据的完整性,往往会从最老的数据进行同步,这样会导致集群时刻处于从磁盘读取数据的状态,disk/net/cpu 负载都会比较高
- 扩缩容期间无法执行其他操作
- 在一次扩缩容操作结束之前,无法进行其他运维操作(扩缩容)
未来演进
去除Zookeeper依赖
- 依赖ZK的问题
- 元数据存取困难
- 元数据的存取过于困难,每次重新选举的controller需要把整个集群的元数据重新restore,非常的耗时且影响集群的可用性。
- 元数据更新网络开销大
- 整个元数据的更新操作也是以全量推的方式进行,网络的开销也会非常大。
- 强耦合违背软件设计原则
- Zookeeper对于运维来说,维护Zookeeper也需要一定的开销 ,并且kafka强耦合与zk也并不好,还得时刻担心zk的宕机问题,违背软件设计的高内聚,低耦合的原则。
- 网络分区复杂度高
- Zookeeper本身并不能兼顾到broker与broker之间通信的状态,这就会导致网络分区的复杂度成几何倍数增长。
- 并发访问zk问题多
- Zookeeper本身并不能兼顾到broker与broker之间通信的状态,这就会导致网络分区的复杂度成几何倍数增长。
- 元数据存取困难
Kafka依赖KRaft
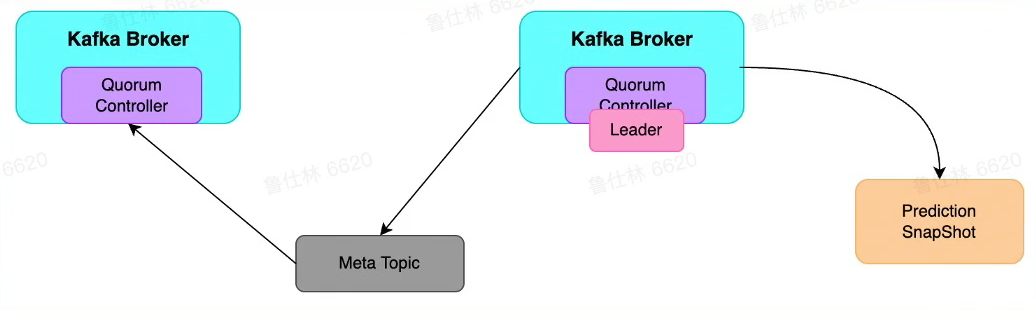
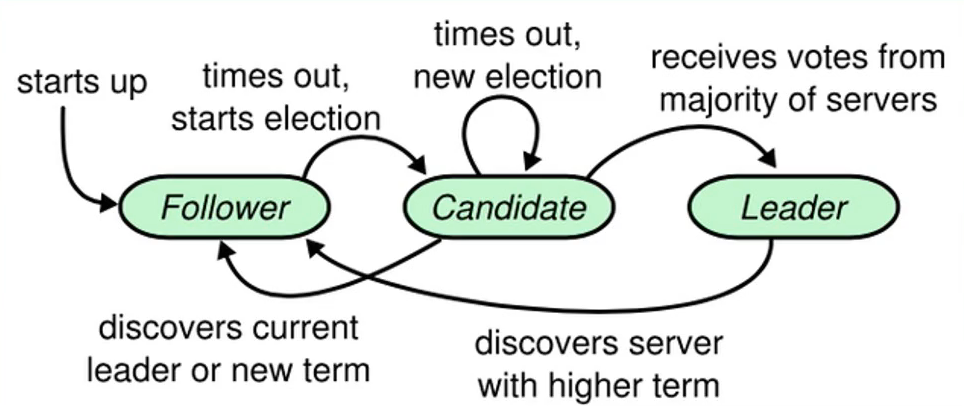
- Process.Roles = Broker
- 服务器在KRaft模式下充当Broker
- Process.Roles = Controller
- 服务器在KRaft模式下充当Controller
- Process.Roles = Broker ,Controller
- 服务器在KRaft模式下充当Broker和Controlle
- Process.Roles = null
- 那么集群就假定是运行在ZooKeeper模式下。
调优&运维经验
- 单机吞吐
- 参数配置
- 扩缩容优化
- 指标可视化
Kafka单机吞吐(字节内部在用的)
- Kafka Version
- 2.3.1
- 机器配置
- 40C 500GB 12 * 1TB 25GB
- 写入配置
- Ack=-1, replica=3, in_sync_replica = 2/3(重要的配置成3,例如金融业务昂!)
- 单条消息5 KB
- 吞吐
- 单机150MB/s
Kafka集群参数配置
- zookeeper. session.timeout.ms = 30000
- log.segment.bytes - 536870912
- log.retention.hours = 36
- log.retention.bytes = 27487 7906944
- num.network.threads = 32
- num.io.threads = 200
- auto.create.topics. enable = false
- auto.leader.rebalance enable = false
- unclean.leader election. enable = false
- advertised.listeners = SASL PL AINTEXT://:,PL AINTEXT://:
- security inter .broker.protocol = SASL Pl AINTEXT
扩缩容优化
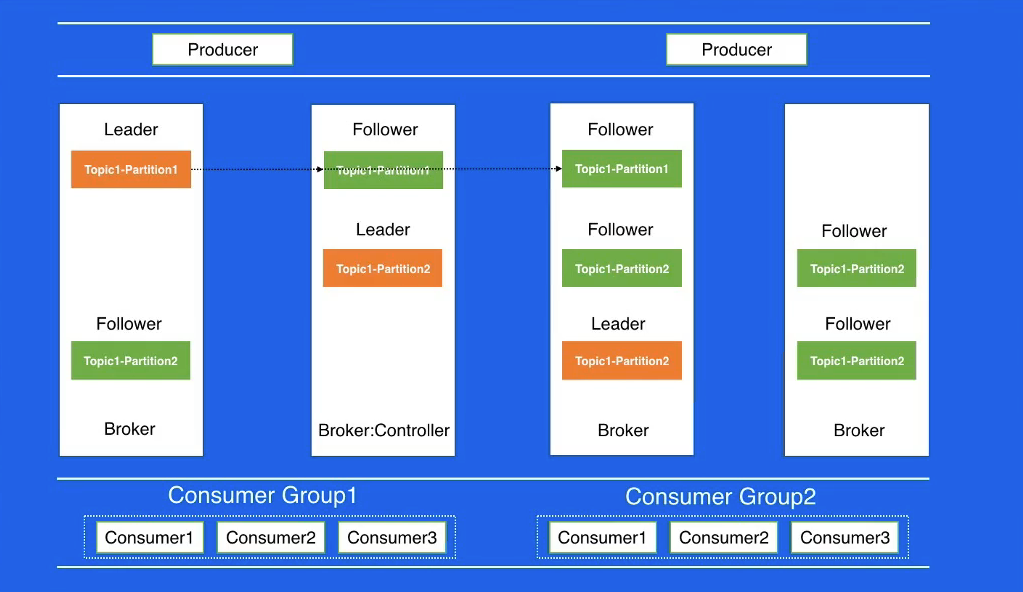
- 目标
- Topic-Partition均匀分布在Broker间
- Broker间的Replica是均匀的
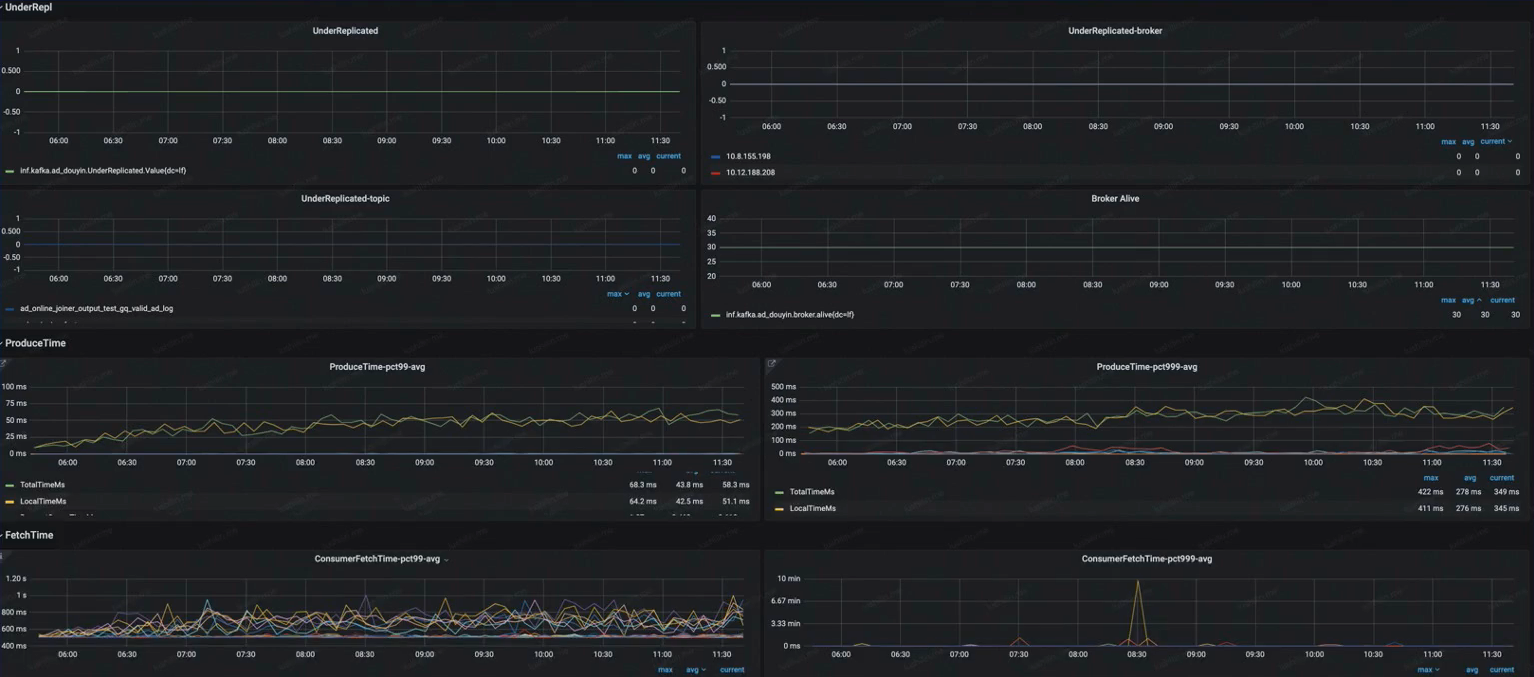
指标可视化
Pulsar详解
横空出世,具有Kafka不具有的功能!!!
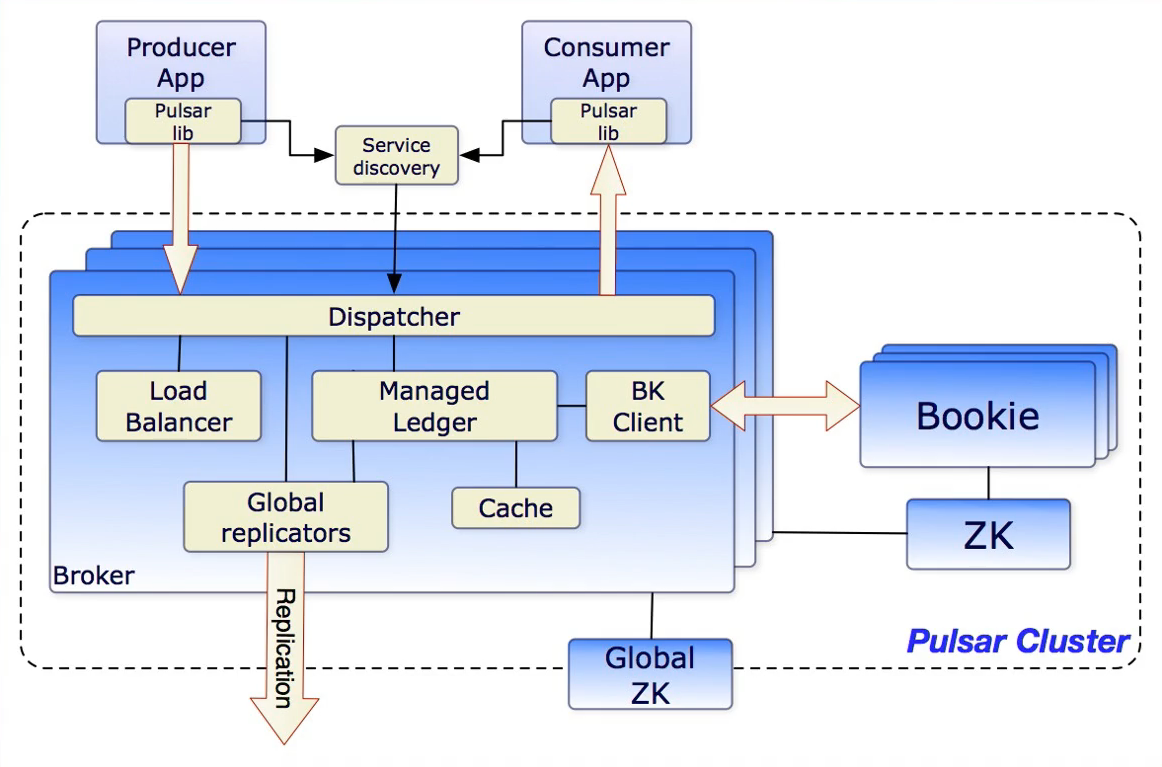
架构介绍
Pulsar Proxy
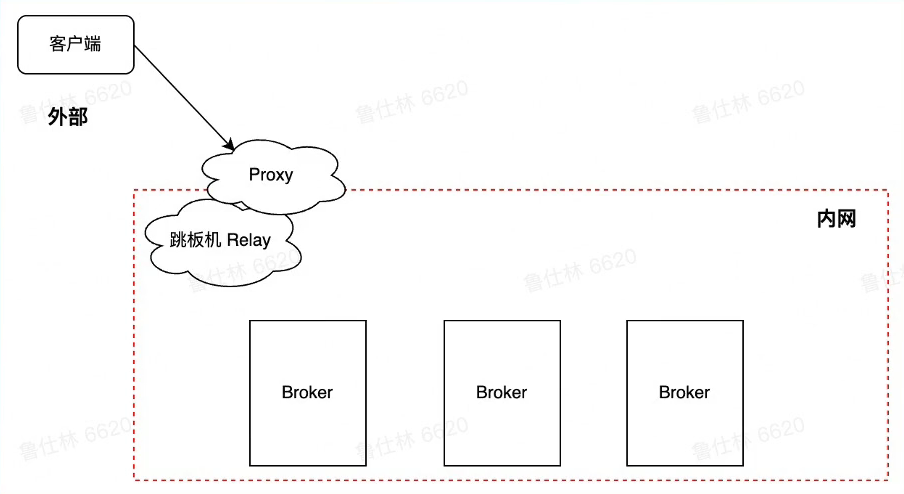
- Pulsar客户端连接集群的两种方式
- Pulsar Client -> Broker
- Pulsar Client -> Proxy
- Pulsar Proxy的作用及应用场景
- 部分场景无法知道Broker地址,如云环境或者Kubernetes环境
- Proxy提供类似GateWay代理能力,解耦客户端和Broker ,保障Broker安全
Pulsar Broker
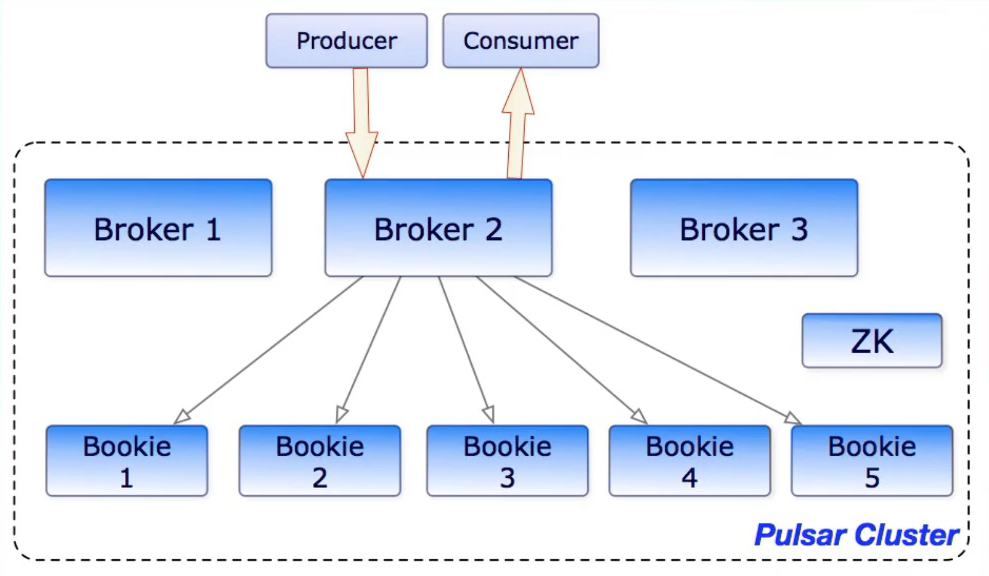
- Pulsar Broker无状态组件,负责运行两个模块
- Http服务器
- 暴露了restful 接口,提供生产者和消费者topic查找api
- 调度分发器
- 异步的tcp服务器,通过自定义二进制协议进行数据传输
- Http服务器
- Pulsar Broker作为数据层代理
- Bookie通讯
- 作为Ledger代理负责和Bookie进行通讯
- 流量代理
- 消息写入Ledger存储到Bookie
- 消息缓存在堆外,负责快速响应
- Bookie通讯
Pulsar Storage
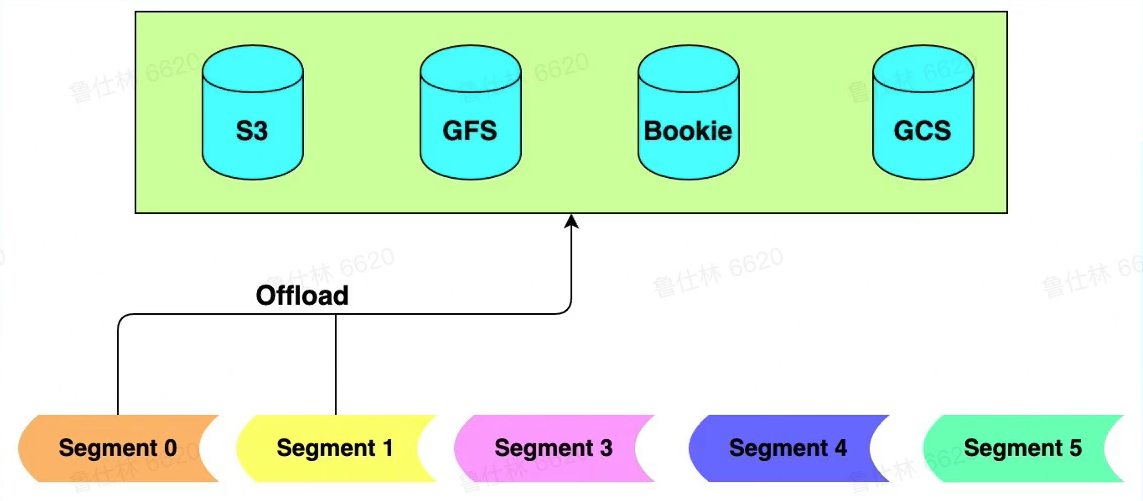
- Pulsar数据存储Segment在不同存储中的抽象
- 分布式Journal系统(Bookeeper)中为Journal/Ledger
- 分布式文件系统(GFS/HDFS)中为文件
- 普通磁盘中为文件
- 分布式BIob存储中为Blob
- 分布式对象存储中为对象
- 定义好抽象之后,即可实现多介质存储
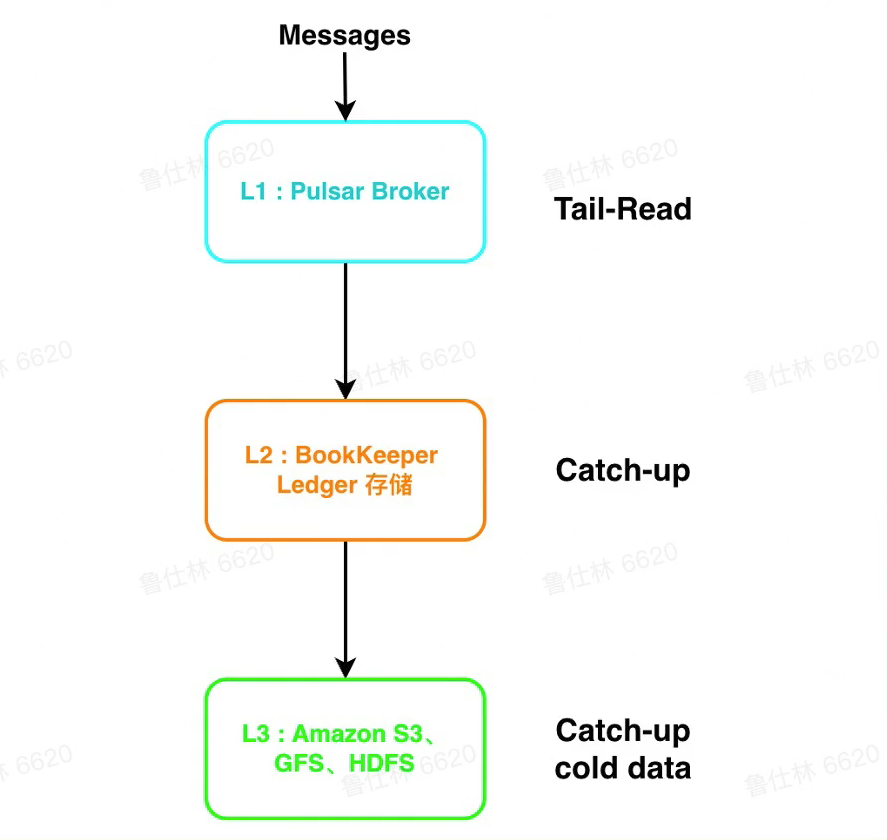
- L1(缓存):
- Broker使用堆外内存短暂存储消息
- 适用于Tail-Read读场景
- L2(Bookkeeper):
- Bookkeeper使用Qurom写,能有效降低长尾,latency 低
- 适用于Catch-Up较短时间内的较热数据
- L3(S3等冷存):
- 存储成本低,扩展性好
- 适用于Catch-Up长时间内的冷数据
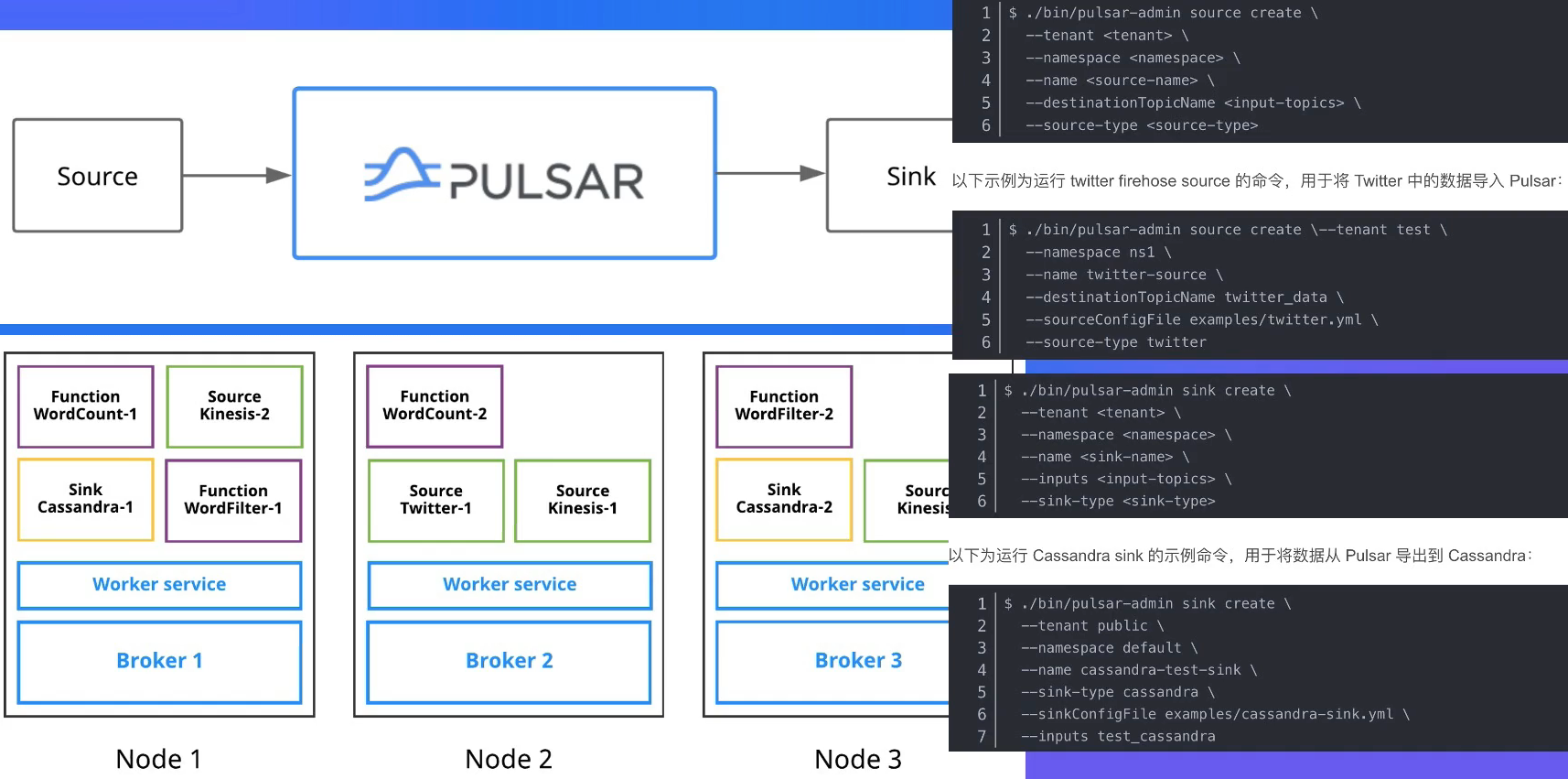
Pulsar IO 连接器

- Pulsar l0分为输入( Input )和输出( Output )两个模块,输入代表数据从哪里来,通过Source实现数据输入。输出代表数据要往哪里去,通过Sink实现数据输出。
- Pulsar提出了IO (也称为Pulsar Connector), 用于解决Pulsar与周边系统的集成问题,帮助用户高效完成工作。
- 目前Pulsar l0支持非常多的连接集成操作:例如HDFS、Spark、 Flink、 Flume、 ES、HBase等。
Pulsar Functions
轻量级计算框架
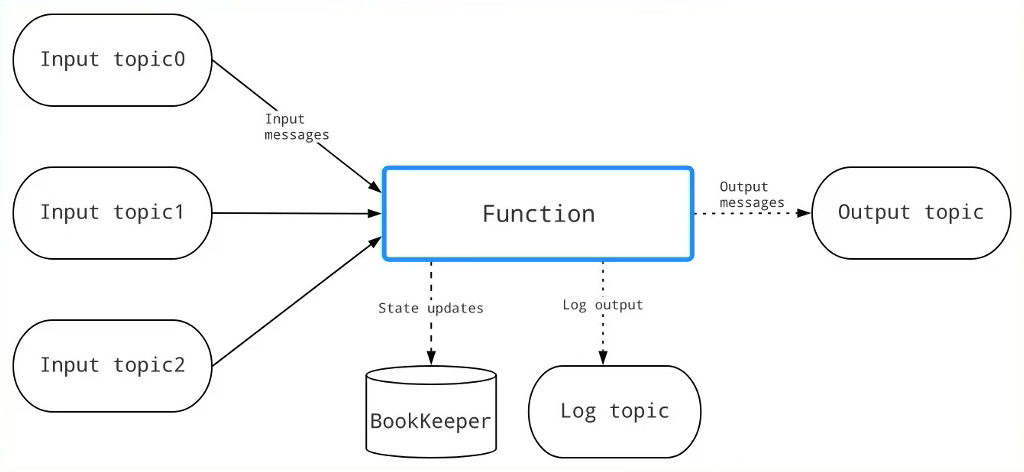
- Pulsar Functions是一个轻量级计算框架,提供一个部署简单运维简单、API 简单的FAAS平台。
- Pulsar Functions提供基于事件的服务,支持有状态与无状态的多语言计算,是对复杂的大数据处理框架的有力补充。
- 使用Pulsar Functions ,用户可以轻松地部署和管理function通过function从Pulsar topic读取数据或者生产新数据到Pulsar topic。
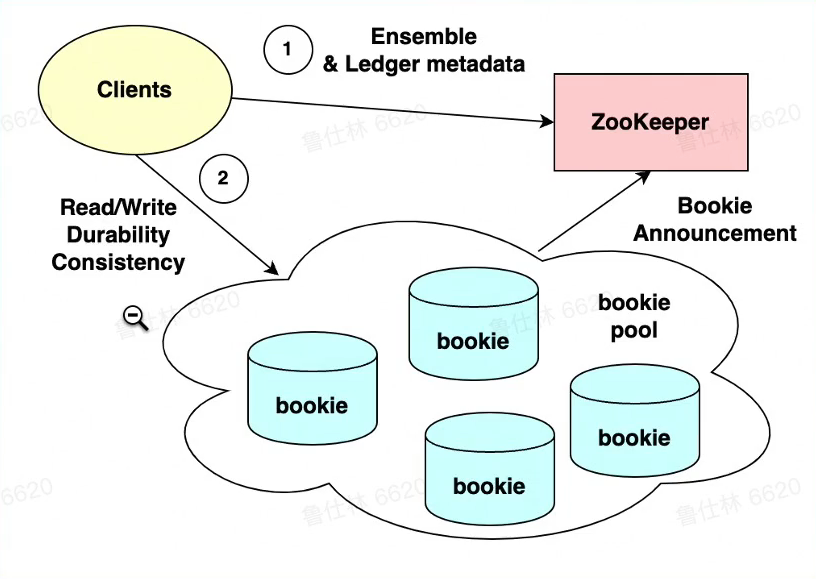
Bookkeeper介绍
整体架构
- 一致性强
- 延迟比较低,有效降低长尾延迟
基本概念
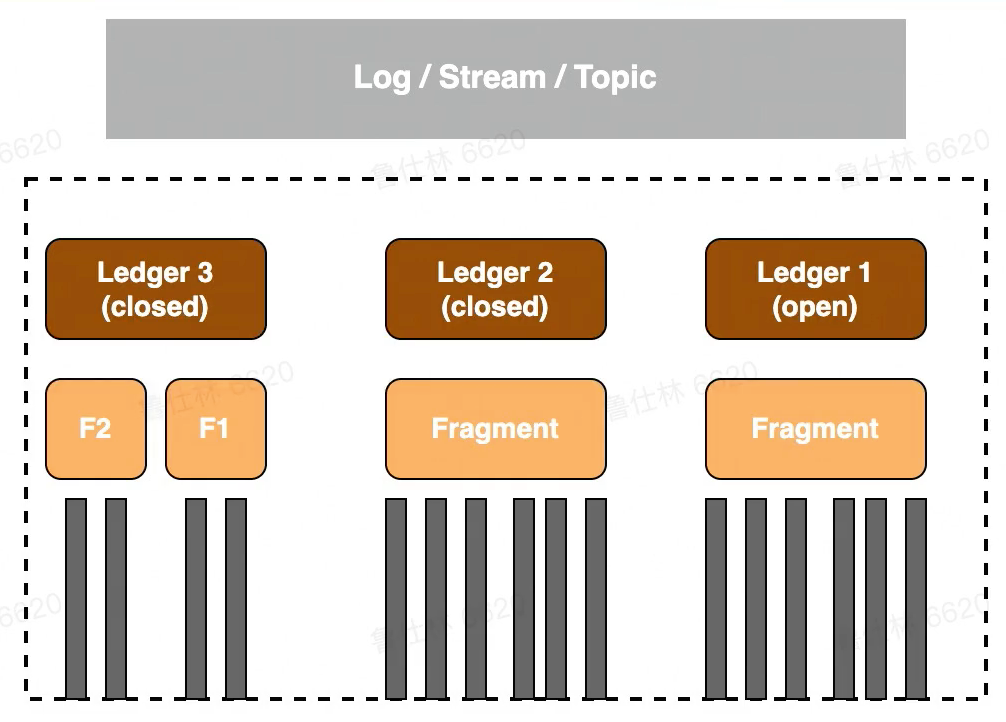
- Ledger: BK的一个基本存储单元, BK Client的读写操作都是以Ledger为粒度的
- Fragment: BK的最小分布单元(实际上也是物理上的最小存储单元),也是Ledger的组成单位,默认情况下一个Ledger会对应的一个Fragment (一个Ledger也可能由多个Fragment组成)
- Entry: 每条日志都是一个 Entry,它代表一个record,每条record都会有一个对应的Entry id
Ledger
新建Ledger
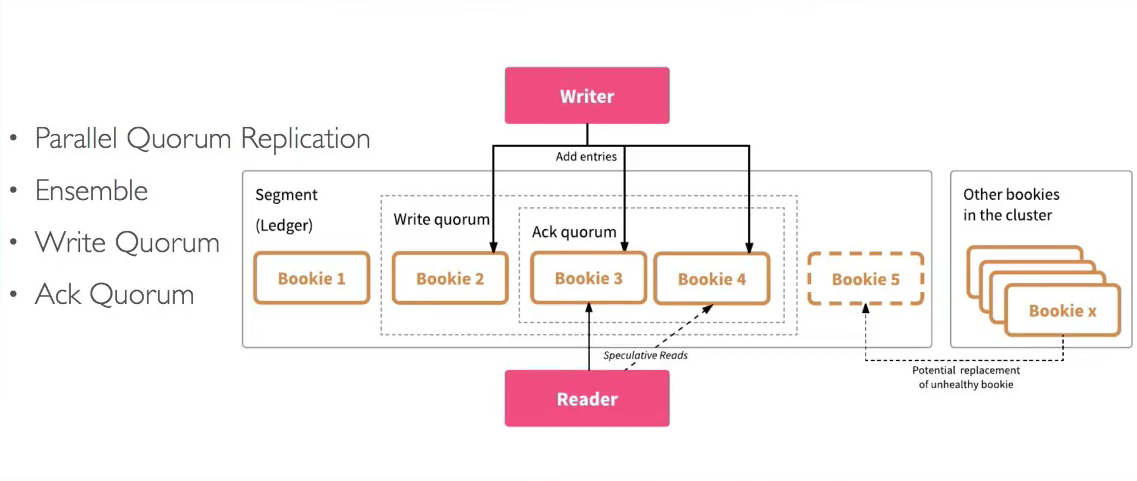
- Ensemble size(E): 一个Ledger所涉及的Bookie集合
- Write Quorum Size(Qw): 副本数
- Ack Quorum Size(Qa): 写请求成功需要满足的副本数
Quorum写的概念昂!!!
Ledger分布
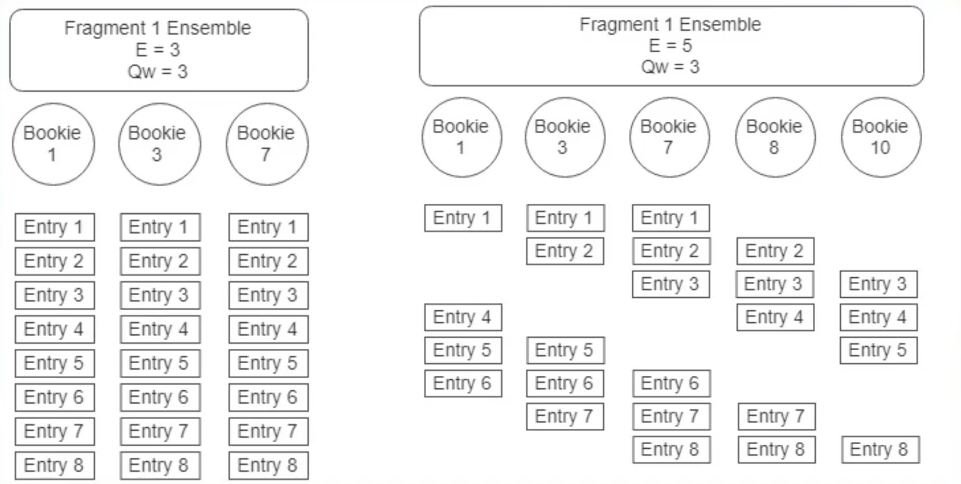
- 从Bookie Pool挑选Bookies构成Ensemble
- Write Quorum Size决定发送给哪些Bookies
- Ack Quorum Size决定收到几个Ack成功昂!
一致性
写一致性
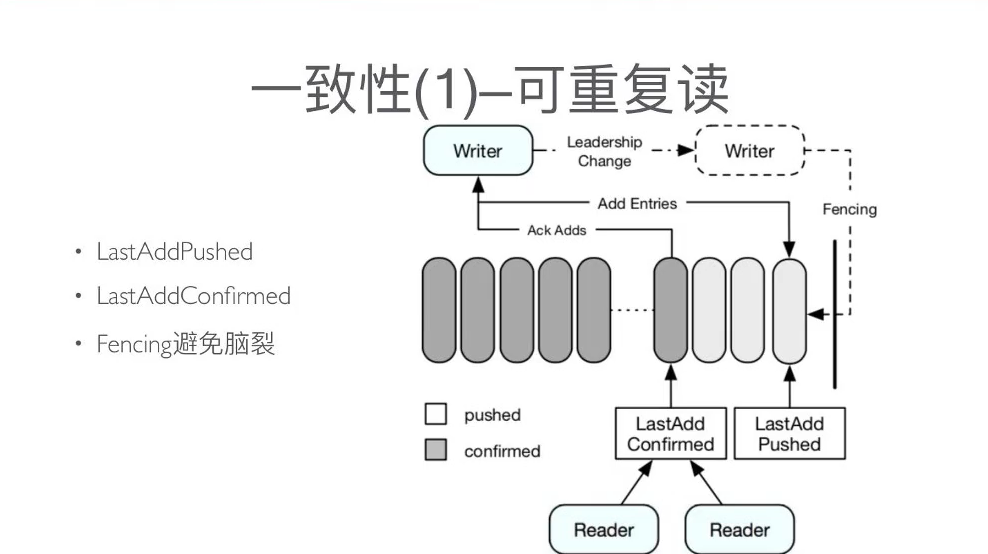
- LastAddPushed(LAP)
- LastAddConfirmed(LAC)
- Fencing避免脑裂
LAC控制了消息的可见性 -> 一致性被保证了昂!
读一致性
所有的Reader都可以安全读取Entry ID小于或者等于LAC的记录从而保证reader不会读取未确认的数据,从而保证了reader之间的一致性
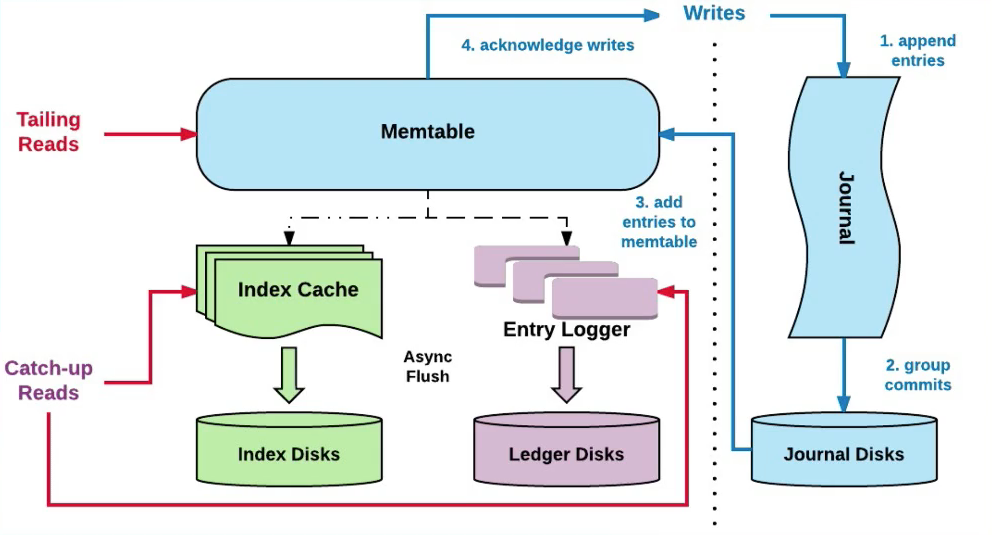
读写分离
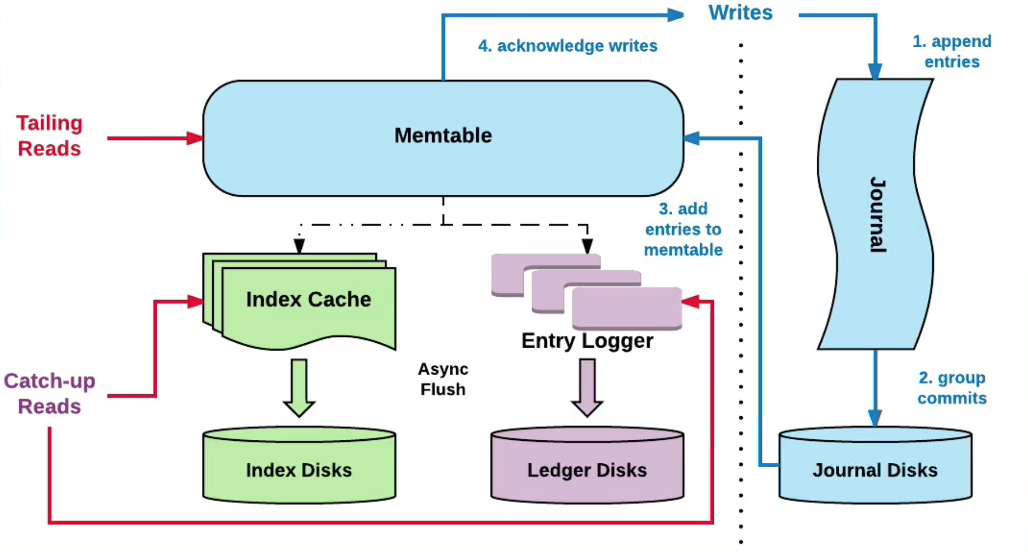
- 写入优化:
- 写入时,不但会写入到Journal中还会写入到缓存(memtable)中,定期会做刷盘(刷盘前会做排序,通过聚合+排序优化读取性能)
- 读取优化:
- 先读Memtable,没命中再通过索引读磁盘
- Ledger Device中会维护一个索引结构,存储在RocksDB中,它会将(Ledgerld,Entryld)映射到(EntryLogld,文件中的偏移量)
Bookeeper with Pulsar
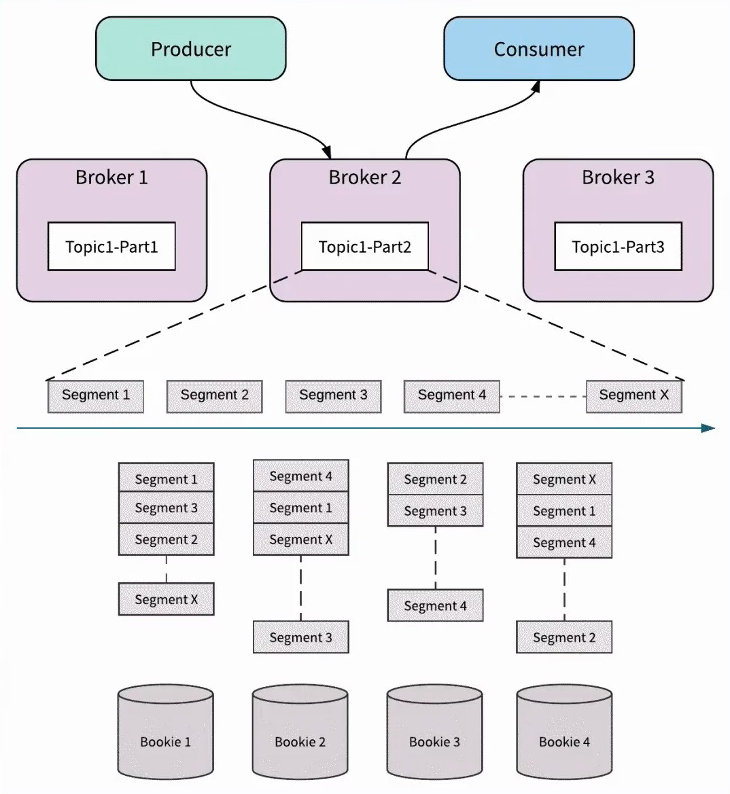
- Topic-Partition :
- Topic由多个partition组成
- Partition由多个segment组成
- Segment对应Ledger
- 可以发现:
- Partition <-> Broker之间只是映射关系
- Broker在扩缩容的过程中只需要更改映射即可
功能介绍
- 生产模式
- 消费模式
- 多租户能力
- Plugin
- GEO Replication
- ...
生产模式

消费模式
- 共有四种不同的消费模式,如下图:
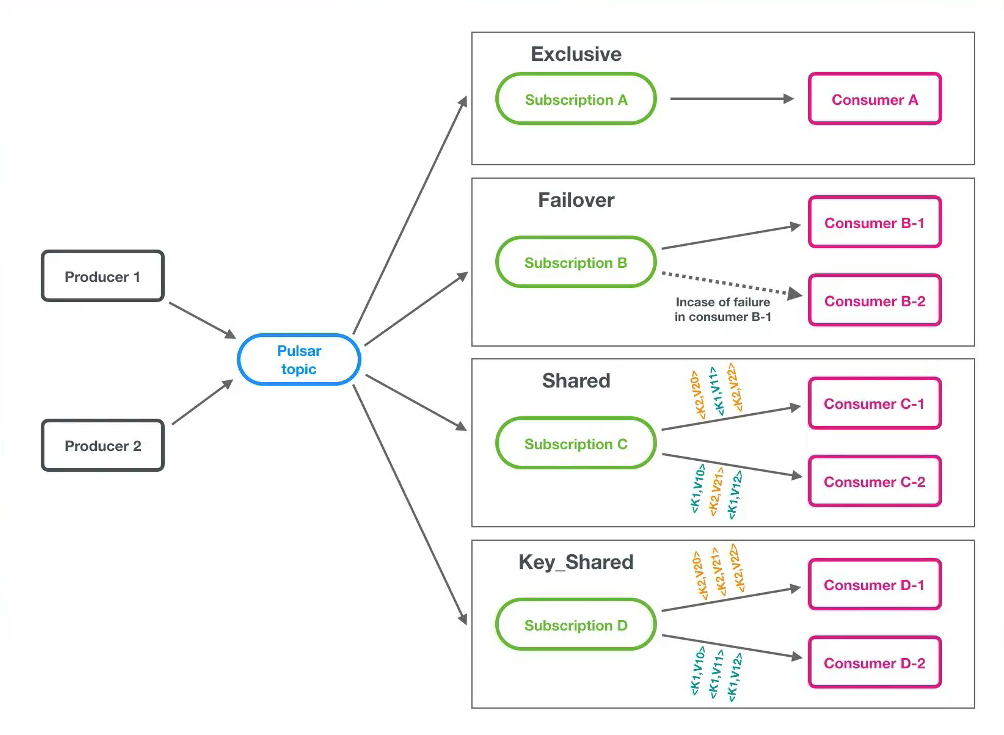
Exclusive消费模式
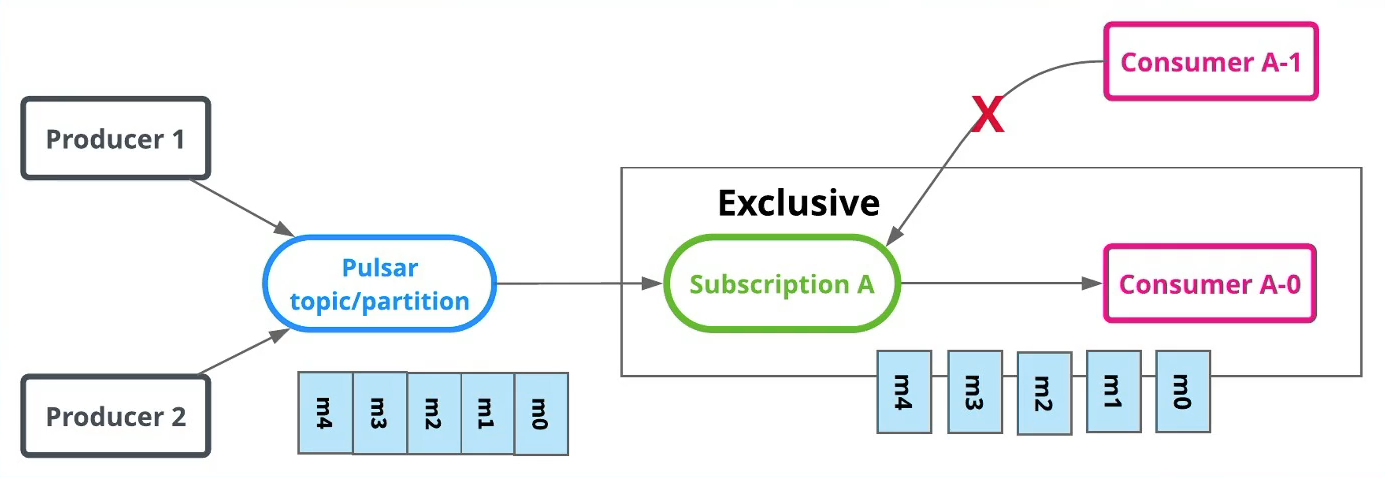
- 独占订阅( Stream流模型)
- 独占订阅中,在任何时间,一个消费者组(订阅)中有且只有一个消费者来消费Topic中的消息。
Failover消费模式
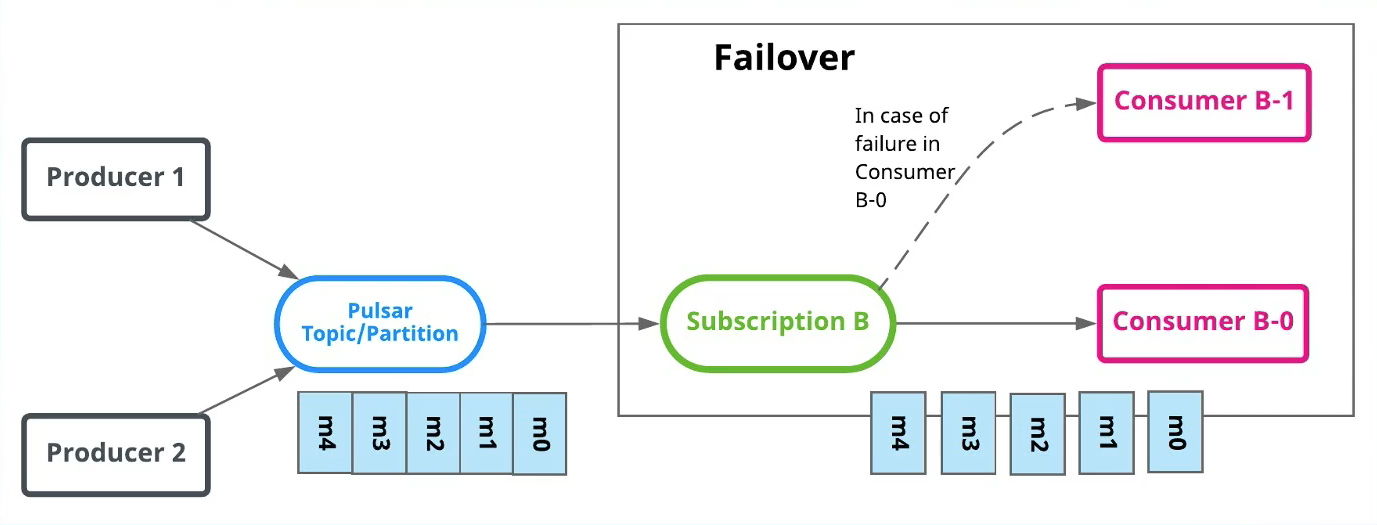
- 故障切换( Stream流模型)
- 使用故障切换订阅,多个消费者( Consumer )可以附加到同一订阅。但是,一个订阅中的所有消费者,只会有一个消费者被选为该订阅的主消费者。其他消费者将被指定为故障转移消费者。
Shared消费模式

这个其实就是Kafka中发布订阅的模式昂!!!
- 共享订阅( Queue队列模型)
- 使用共享订阅,在同一个订阅背后,用户按照应用的需求挂载任意多的消费者。订阅中的所有消息以循环分发形式发送给订阅背后的多个消费者,并且一个消息仅传递给一个消费者。
Key_Shared消费模式
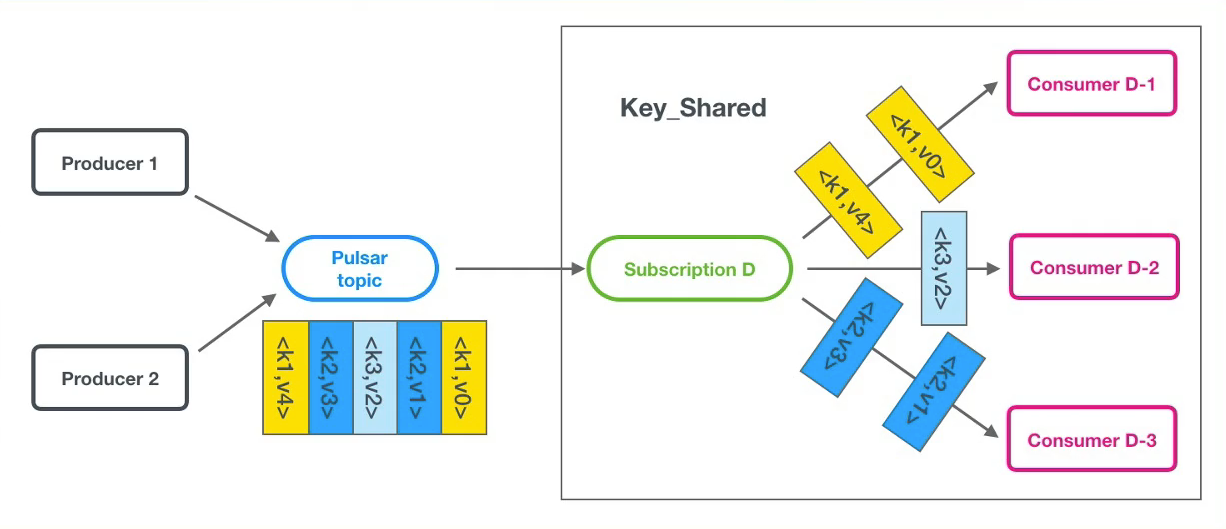
- 按Key共享订阅( Queue队列模型)
- 使用共享订阅,在同一个订阅背后,用户按照应用的需求挂载任意多的消费者。订阅中的所有消息以key-hash发送给订阅背后的多个消费者,并且一个消息仅传递给一个消费者。
Pulsar多租户
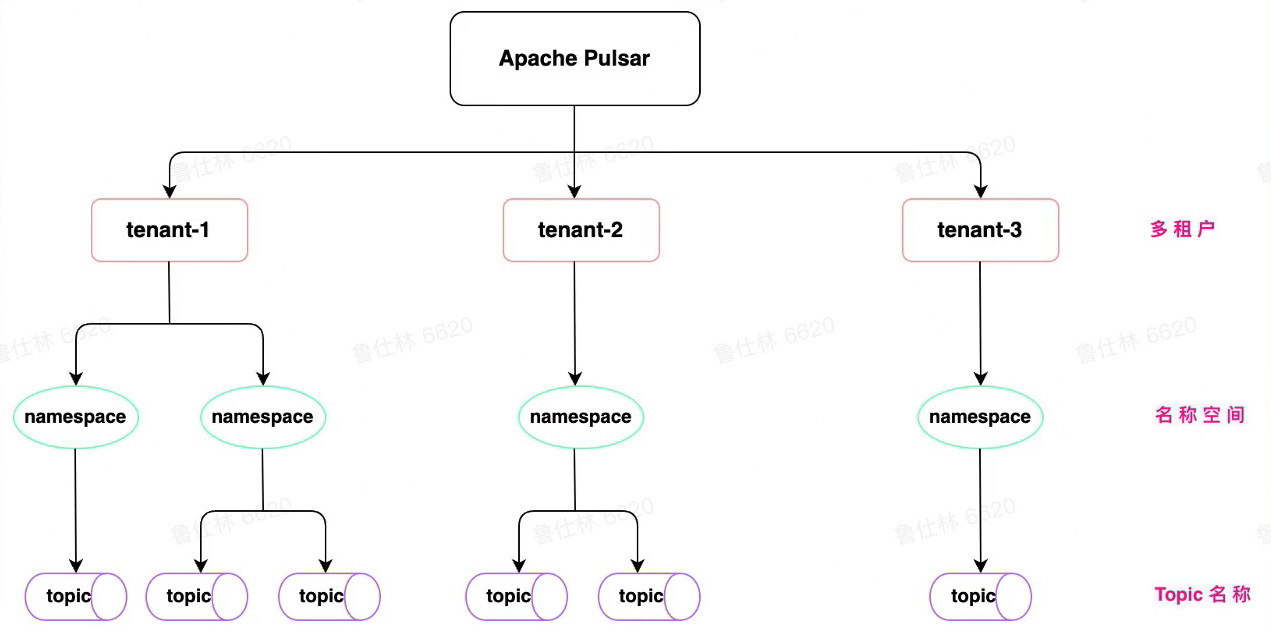
多业务线可以使用多租户,方便Pulsar进行资源管理昂!!!
Pulsar Plugin
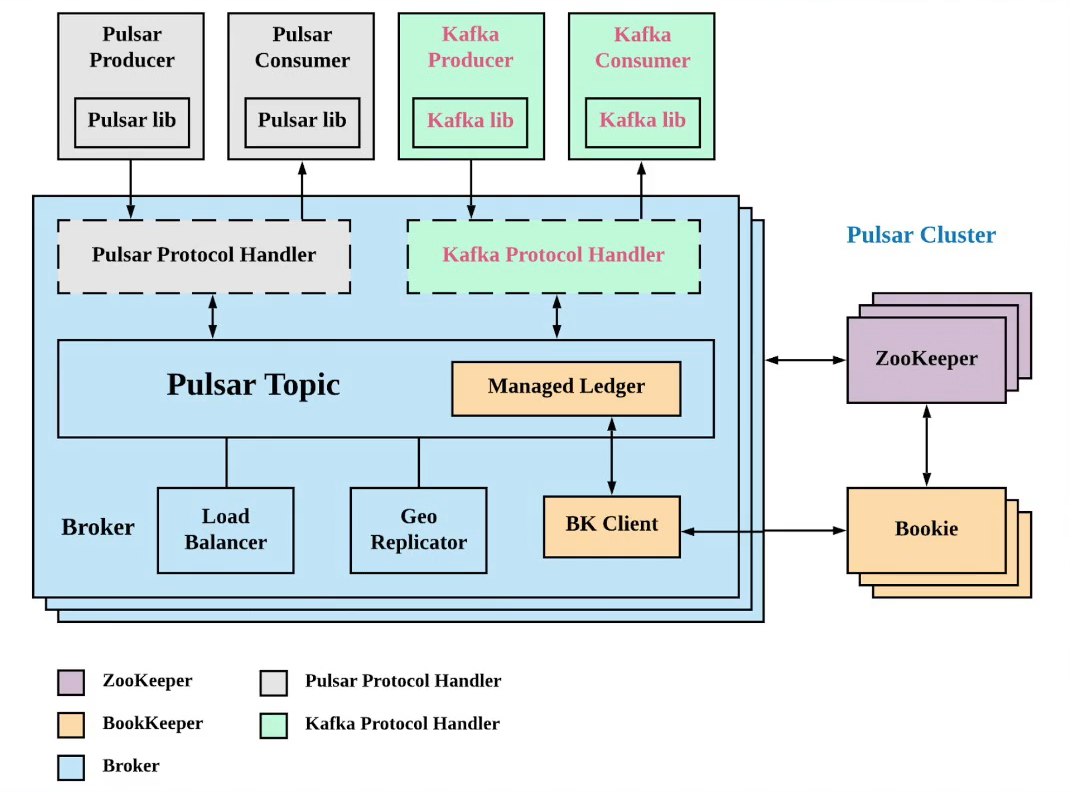
- 当前支持Plugin类型
- KOP (Kafka on Pulsar)
- ROP (RocketMQ on Pulsar)
- AOP (AMQP on Pulsar)
- Mop (MQTT on Pulsar)
- 实现Plugin需要支持的功能
- 路由查询
- Message Protocol
- Offset & Msgld
GEO Replication
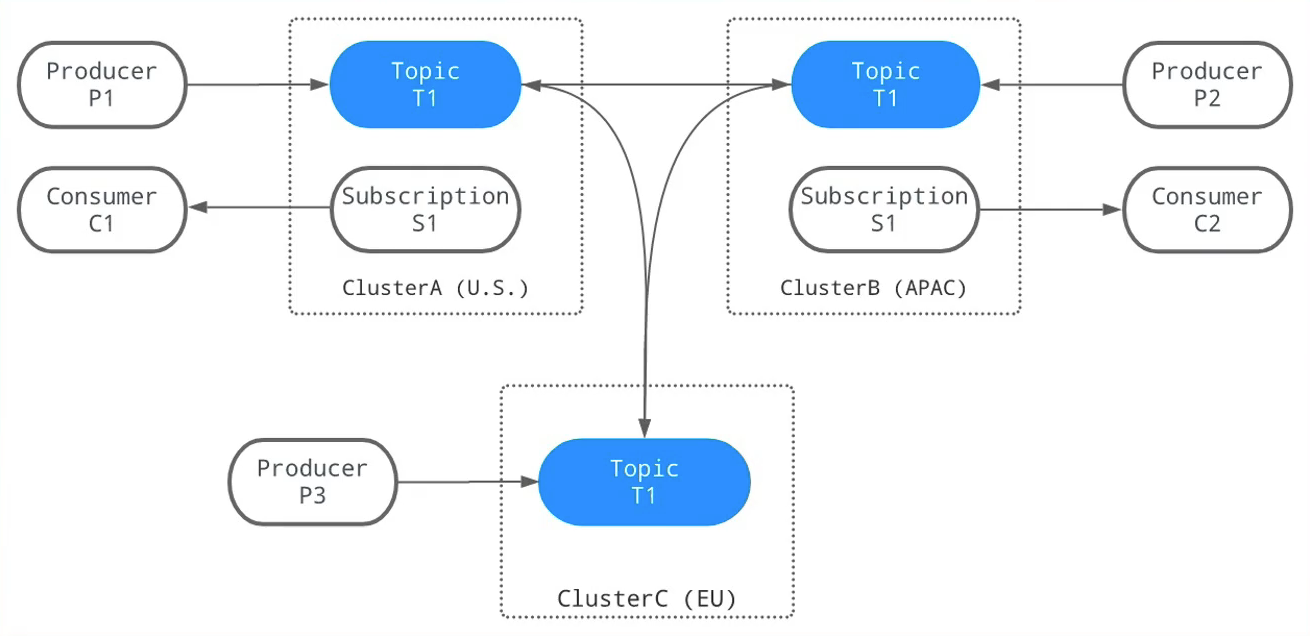
- 跨数据中心复制
- 消费其他地域数据
Pulsa HA & Scale-up
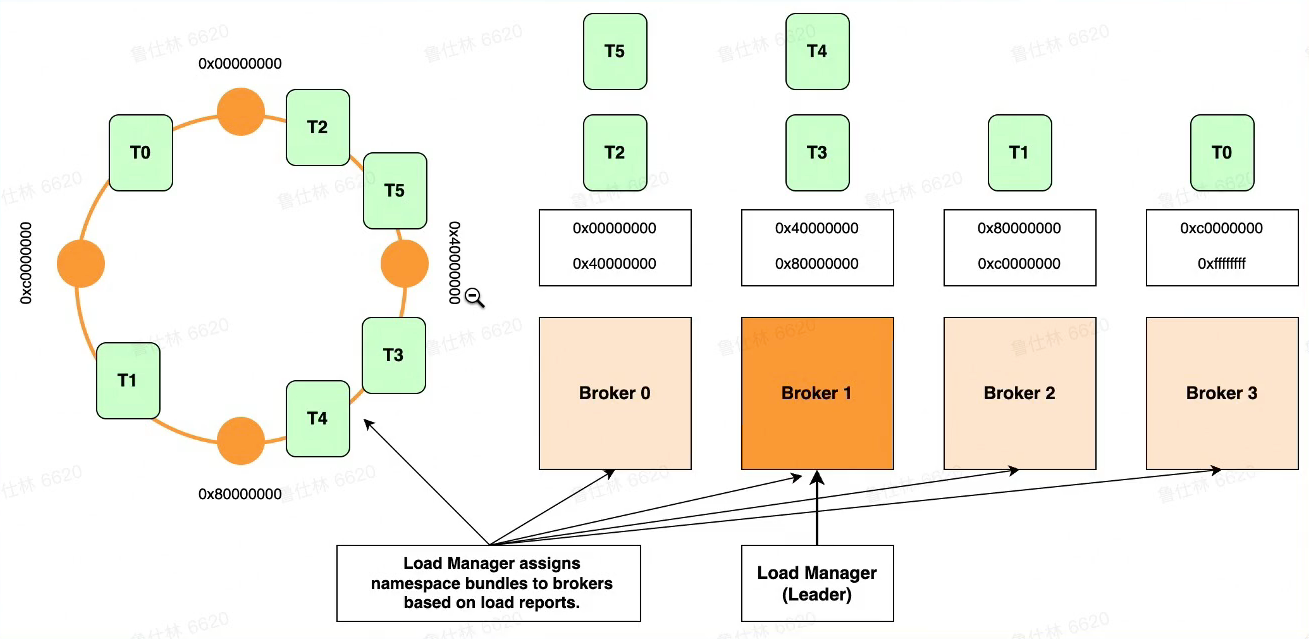
- Topic <-> Bundle 完成映射
- Bundle 分配给 Broker
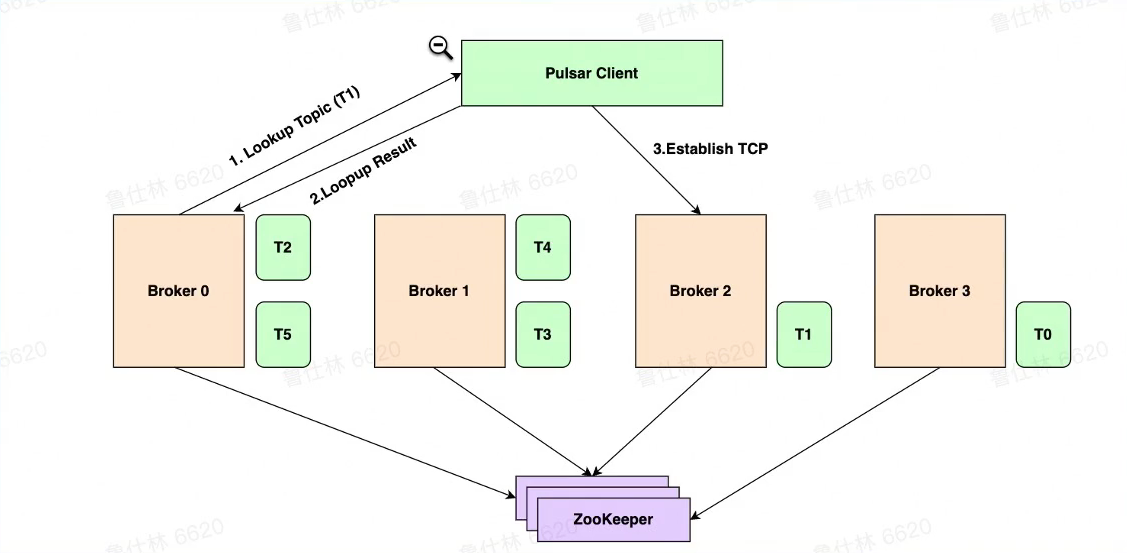
- Lookup Topic
- Lookup Result
- Establish TCP Connection
Pulsar vs Kafka
- 存储架构
- 存储计算分离之后带来的优劣势
- 多层架构,状态分离之后的优势
- 运维操作
- 应对突发流量变化,集群扩缩容是否便捷
- 运维任务是否影响可用性
- 集群部署是否灵活
- 功能特性
- 多语言&多协议
- 多租户管理
- 生产消费模式
- 生态集成
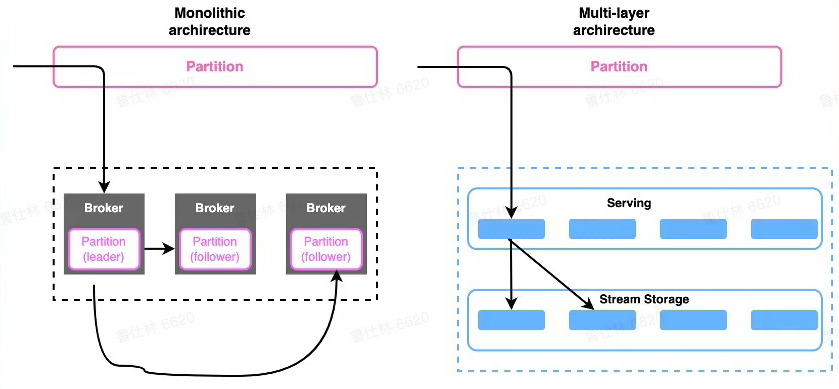
存算分离
-
分层架构优势
- 流量代理层和数据存储层解耦
- 流量代理层无状态,可快速扩缩容(k8s等弹性平台)
- 流量代理层可以对接海量的客户端连接
- 存储层负责数据存储,可以使用多级存储
-
计算层
- 对于写入的数据,可以做预处理,简单ETL
- 可以做数据缓存,应对高扇出度场景
- 无状态,扩缩容之后,能快速完成负载均衡Balance
-
存储层
- 按照数据冷热进行存储介质区分,降低成本
- 历史数据可海量保存,数据无价
- 可直接通过存储层接口读取数据,批式计算
周边和生态
概览
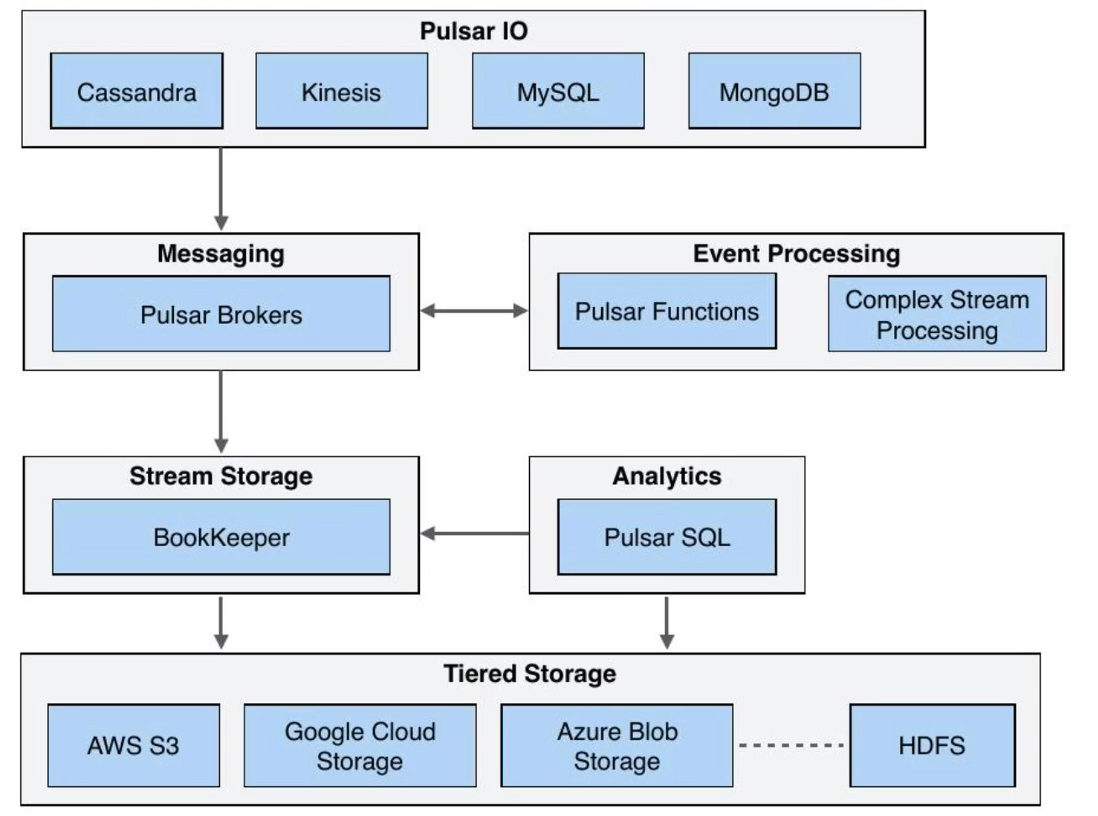
Pulsar IO
Kafka Schema
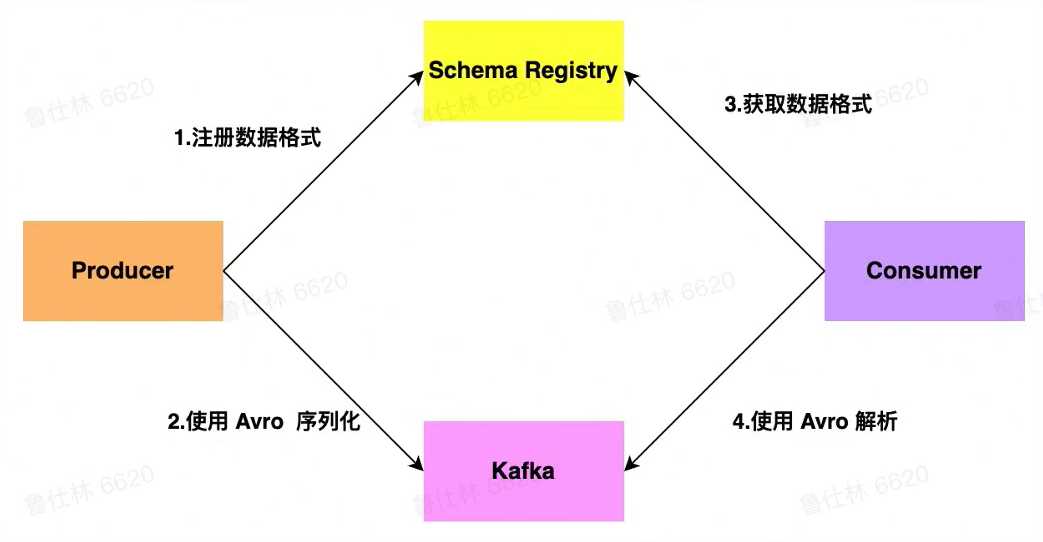
- 向Kafka发送数据时,需要先向Schema Registry注册schema,然后序列化发送到Kafka里
- Schema Registry server为每个注册的schema提供一个全局唯一ID,分配的ID保证单调递增,但不一定是连续的
- 当我们需要从Kafka消费数据时,消费者在反序列化前,会先判断schema是否在本地内存中,如果不在本地内存中,则需要从Schema Registry中获取schema,否则,无需获取
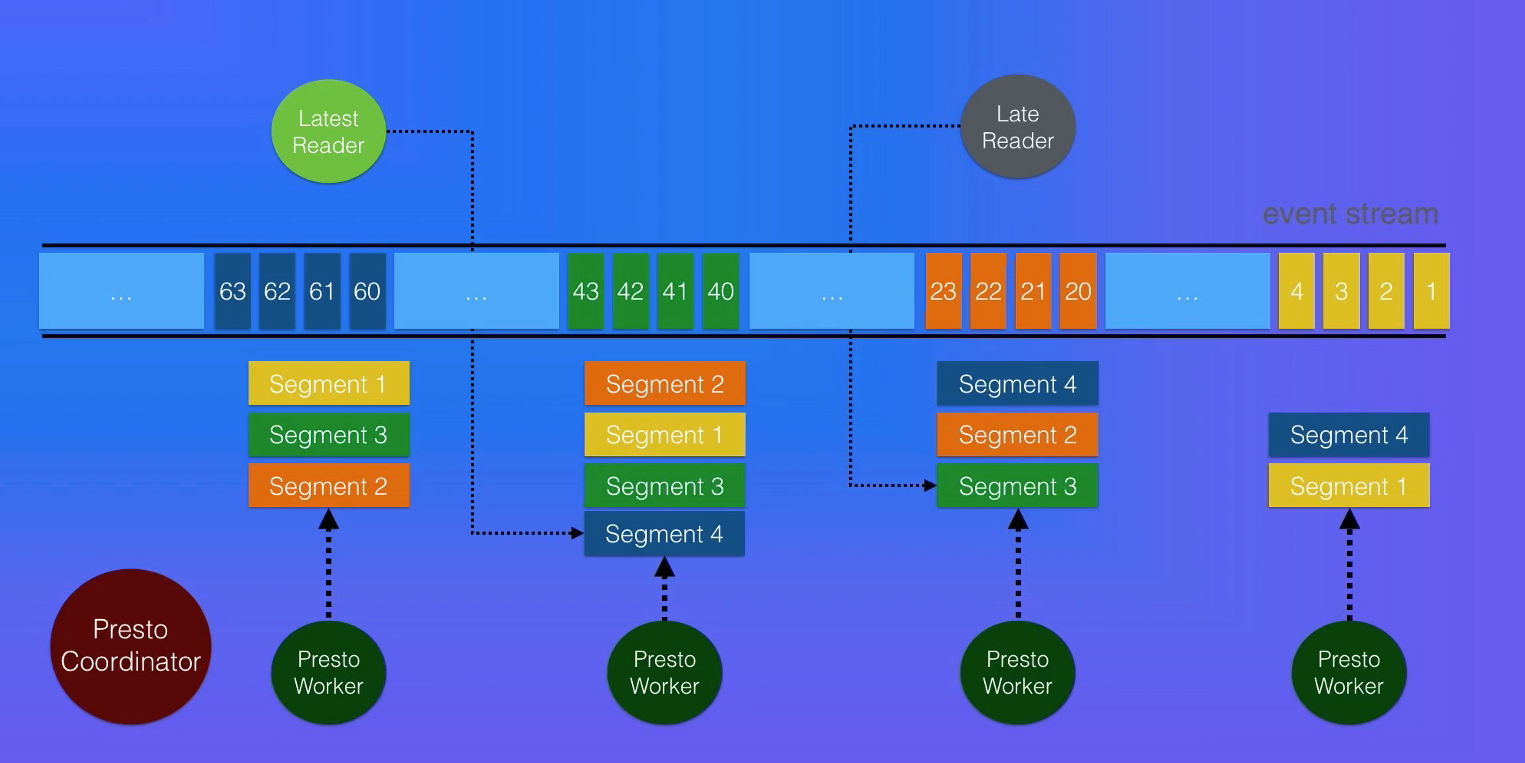
Pulsar SQL
Suammry
- 消息队列概述
- 应用场景(从消息到消息、事件、流融合的处理平台)
- 主流消息队列
- Kafka
- 集群架构、高可用、集群扩缩容、运维调优
- Pulsar
- 集群架构、存储层分析、特性介绍、HA &集群扩缩容
- 周边和生态
- SQL、IO、 Schema
References
- Pulsar-Cloud Native Messaging & Streaming
