

这是我参与「第五届青训营 」伴学笔记创作活动的第6天
概念
- 事物
是一组由SQL语句组成的一个程序执行单元,需要满足ACID特性
- ACID
- A
- C
- I
- D
- A
- 高并发
数据库要有能够处理高并发的能力
- 高可靠
发展历史
前DBMS时代
- 人工管理:在计算机发明之前,数据通过人工方式记录以及管理,效率很低
- 文件系统:1950s,现代计算机雏形基本出现,1956年IBM发布了第一个磁盘驱动器,从此数据存储进入磁盘时代,在这个阶段,数据管理直接通过文件系统来实现
DBMS数据模型
- 网状模型
网状数据模型是以记录类型为结点的网络结构,即一个结点可以有一个或多个下级结点,也可以有一个或多个上级结点,两个结点之间甚至可以有多种联系,例如"教师"与"课程"两个记录类型,可以有"任课"和“辅导"两种联系,称之为复合链。 两个记录类型之间的值可以是多对多的联系,例如一门课程被多个学生修读,一个学生选修多门课程。是m对n的关系
- 层次模型
层次数据库就是树结构。每棵树都有且仅有一个根节点,其余的节点都是非根节点。每个节点表示一个记录类型对应与实体的概念,记录类型的各个字段对应实体的各个属性。各个记录类型及其字段都必须记录。是一对n的关系
- 关系模型
使用表格表示实体和实体之间关系的数据模型称之为关系数据模型。 关系数据模型中,无论是是实体、还是实体之间的联系都是被映射成统一的关系——张二维表,在关系模型中,操作的对象和结果都是一张二维表,它由行和列组成; 关系型数据库可用于表示实体之间的多对多的关系,只是此时要借助第三个关系一表,来实现多对多的关系;
- 总结
SQL语言
与结构化查询语言相对的是过程化语言,如c/c++,java;要详细的告诉计算机应该怎么做,结构化语言只需要告诉数据库需要做什么,而不是如何去做
核心技术
SQL语句执行流程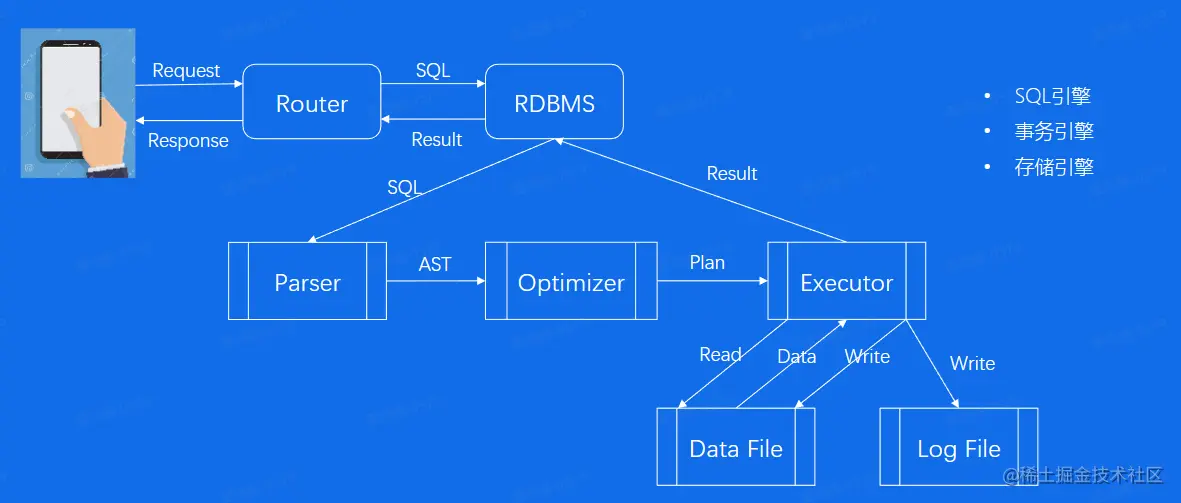
- SQL引擎:Paser(查询解析),Optimizer(查询优化),Executor(查询执行)
- 查询解析:SQL语言接近自然语言, 入门容易。但是各种关键字、操作符组合起来, 可以表达丰富的语意。因此想要处理SQL命令, 首先将文本解析成结构化数据, 也就是抽象语法树(AST)。
- 查询优化:SQL是一门表意的语言, 只是说『要做什么』, 而不说「怎么做」。所以需要一些复杂的逻辑选择『如何拿数据」, 也就是选择一个好的查询计划。优化器的作用根据AST优化产生最优执行计划(Plan Tree) 。
- 查询执行:根据查询计划,完成数据读取、处理、写入等操作。
- 事务引擎:处理事务一致性、并发、读写隔离等
- 存储引擎:内存中的数据缓存区、数据文件(Data File)、日志文件(Log File)
SQL引擎-解决SQL执行问题
-
Paser:解析器-明确用户的目的
- 词法分析:将一条SQL语句对应的字符串分割为一个个token, 这些token可以简单分类。
- 语法分析:把词法分析的结果转为语法树。根据to cken序列匹配不同的语法规则, 比如这里匹配的是update语法规则, 类似的还有insert、delete、select、create、drop等等语法规则。根据语法规则匹配SQL语句中的关键字, 最终输出一个结构化的数据结构。
- 语义分析:对语法树中的信息进行合法性校验。
-
optimizer:优化器-在众多达成用户目的的操作中选择最优
如图,做A、B、C三表连接就有三种方式
基于规则的优化器
基于代价的优化器,如果某个请求把资源用完了,其他请求就没有资源使用,因此需要计算代价,优化执行
-
executor:执行器
火山模型:Plan Tree为基础 调用关系是由根到叶 数据流是从叶到根
向量化执行更适合于大批量数据处理,对于很多单行数据处理并没有优势。而且往往搭配列式存储使用
把所有逻辑代码写入一个函数里,但是用户代码千变万化,把所有代码集成到一个函数中不太现实,前面提到的火山模型把代码拆成算子就是为了解决不同用户代码不同的问题,因此为了封装操作到函数中需要一个技术:LLVM动态编译技术,代码生成之后数据库运行时仍然是一个for循环, 只不过这个循环内部的代码从简单的一个虚函数调用plan.next() 展开成了一系列具体的运算逻辑, 这样数据就不用再各个operator之间进行传递, 而且有些数据还可以直接被存放在寄存器中, 进一步提升系统性能。整个操作有点像inline函数,动态编译执行技术根据优化器产生的计划,动态的生成执行代码。
存储引擎-解决数据和日志的存储问题
- innoDB
数据库中很多概念是互通的,但是实现各有差异
- 内存部分:内存和磁盘的io差了一个数量级,因此内存态需要缓存
- buffer pool:作为数据缓存
- log buffer:写日志的缓存
- 磁盘部分
- 系统表(System Tablespace):存储元信息
- 普通表(General Tablespace):存储一些用户信息
- 存储事务日志:Undo Tablespace,Redo Tablespace
- buffer pool
innoDB的Buffer pool中每个page是16k的大小,每个chunk是128M,由8192个page组成,可以避免内存碎片化,同时把buffer pool分成多个instance,可以降低访问冲突
- 内存部分:内存和磁盘的io差了一个数量级,因此内存态需要缓存
