

这是我参与「第五届青训营 」伴学笔记创作活动的第 16 天
前言
这是我将参加青训营期间的收获进行整理和总结,同时便于日后复习和查阅。如果能给各位小伙伴提供些帮助,也是我的荣幸,希望大家可以多多赐教,一起学习和交流。
文章概述
RDBMS(关系型数据库)是目前使用最为广泛的数据库之一,同时也是整个信息化时代的基石。本篇文章通过生活中常见的场景向大家介绍RDBMS的作用、发展历程及其核心技术,最后再展示RDBMS的企业级实践,主要为以下内容:
- 经典案例
- 发展历史
- 关键技术
- 企业实践
经典案例
通过一场红包雨说起,来介绍 RDBMS的概念:
事务(Transaction):是由一组SQL语句组成的一个程序执行单元(Unit),他需要满足 ACID特性。
BEGIN;
UPDATE account_table SET balance = balance - '小目标' WHERE name = '抖音';
UPDATE account_table SET balance = balance + '小目标' WHERE name = '杨洋';
COMMIT;
ACID:
- 原子性(Atomicity):事务是一个不可再分割的工作单元,事务中的操作要么都发生过,要么都不发生。
- 一致性(Consistency):数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
- 隔离性(Isolation):多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其他事务运行效果。
- 持久性(Ourability):在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
发展历史
DBMS 数据模型
在现代计算机发明出来以前,通过人工的方式进行数据记录和管理:结绳记事、账本、打孔机等。1950年,现代计算机的雏形基本出现。1956年 IBM 发布了第一个的磁盘驱动器 -- Model 305 RAMAC,从此数据存储进入磁盘时代。在这个阶段,数据管理直接通过文件系统来实现。
1960年,传统的文件系统已经不能满足人们的需要,数据库管理系统(DBMS)应运而生。
DBMS:按照某种数据模型来组织、存储和管理数据的仓库。所以通常按照数据库模型的特点将传统数据库系统分成网状数据库、层次数据库和关系数据库三类。
- 网状模型: 基于网状数据模型建立的数据之间的联系,能反映现实世界中信息的关联,是许多空间对象的自然表达形式。
- 层次模型: 使用树形结构来描述实体及其之间关系的数据模型。
- 关系模型: 使用表格表示实体与实体之间关系的数据模型,可用于表示实体之间的多对多的关系。
| 网状模型 | 层次模型 | 关系模型 | |
|---|---|---|---|
| 优势 | 能直接描述现实世界;存取效率较高。 | 结构简单;查询效率高;可以提供较好的完整性支持。 | 实体及实体间的联系都通过二维表结构表示;可以方便的表示M:N关系;数据访问路径对用户透明。 |
| 劣势 | 结构复杂;用户不易使用;访问程序设计复杂。 | 无法表示M:N的关系;插入、删除限制多;遍历子结点必须经过父结点;访问程序设计复杂。 | 关联查询效率不够高;关系必须规范化。 |
SQL 语言
1974年 IBM 的Ray Boyce和Don Chamberlin 将 Codd 关系数据库的12条准则的数学定义以简单的关键字语法表现出来,里程碑式地提出了 SQL(Structured Query Language)语言。
- 语法风格接近自然语言;
- 高度非过程化;
- 面向集合的操作方式;
- 语言简洁,易学易用;
历史回顾
关键技术
一条SQL的一生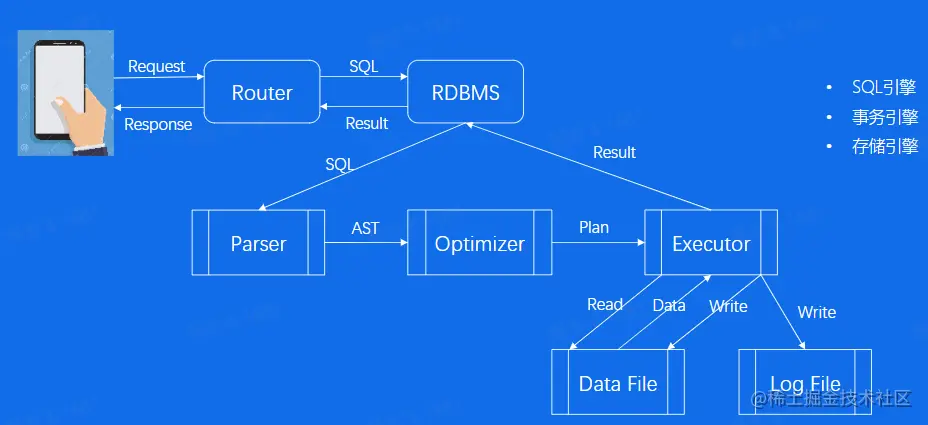
- 查询解析:SQL 语言接近自然语言,入门容易。
- 查询优化:SQL 是一门表意的语言,优化器的作用根据AST优化产生最优执行计划(Plan Tree)。
- 查询执行:根据查询计划,完成数据读取、处理、写入等操作。
- 事务引擎:处理事务一致性、并发、读写隔离等
- 存储引擎:内存中的数据缓存区、数据文件、日志文件。
SQL引擎
解析器(Parser): 一般分为词法分析(Lexical analysis)、语法分析(Syntax analysis)、语义分析(Semantic analyzer)等步骤。
UPDATE account_table SET balance = balance - '小目标' WHERE name = '抖音';
-
词法分析: 将一条SQL语句对应的字符串分割为一个个token,这些token可以简单分类。
关键字:UPDATE/SET/WHERE 表列名:account_table/balance/name 常量:'小目标' / '抖音' 运算符:'='/'-' 结束符:';'
-
语法分析: 把词法分析的结果转为语法树。根据 tocken 序列匹配不同的语法规则。
struct UpdateStmt { Table: account_table; Fields: balance; Vaules: balance - '小目标'; Where: name = '抖音'; OrderBy: null; Limit: null; }
-
语义分析: 对语法树中的信息进行合法性效验。
检查 account_table 是否存在; 检查 balance/name 是否存在; 检查 '小目标'/'抖音' 是否存在;
Optimizer
基于规则的优化(RBO Rule Base Optimizer)
-
条件化简
-
表连接优化
- 总是小表先进行连接
-
Scan 优化
- 唯一索引
- 普通索引
- 全表扫描
数据库索引:是数据库管理系统中辅助数据结构,以协助快速查询、更新数据库表中数据。目前数据库中最常用的索引是通过B+树实现的。
基于代价的优化(CBO Cost Base Optimizer)
一个查询有多种执行方案,CBO会选择其中代价最低的方案去真正的执行。
Executor
火山模型:
- 优点:每个算子独立抽象实现,相互之间没有耦合,逻辑结构简单。
- 缺点:每计算以条数据有多次函数调用开销,导致CPU效率不高。
-
向量化: 每个 Operator 每次操作计算的不再是一行数据,而是一批数据(Batch N行数据),计算完成后向上层算子返回一个 Batch。
- 优点:函数调用次数降低为 1/N;CPU cache命中率更高;可以利用 CPU 提供的 SIMD 机制。
-
编译执行: LLVM动态编译执行技术,根据优化器产生的计划,动态的生成执行代码。
存储引擎
Buffer Pool: 存储引擎位于内存中的重要结构,用户缓存数据,减少磁盘 IO 的开销。
Page: 数据存储的最基本单位,一般为16KB。
B+u Tree: InnoDB中最常用的索引结构。
MySQL 中每个chunk 的大小一般为 128M,每个block对应的一个page,一个chunk下面有 8192 个block。这样可以避免内存碎片化。分成多个instance,可以有效避免并发冲突。
页面内:页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
从根到叶:中间节点存储。
事务引擎
Atomicity(原子性) 与 Undo Log
可以通过Undo Log进行回退到修改之前的状态。
Undo Log是逻辑日志,记录的是数据的增量变化。利用Undo Log可以进行事务回滚,从而保证事物的原子性。同时也实现了多版本并发控制(MVCC),解决读写冲突和一致性读的问题。
Isolation(隔离性)和锁
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力。隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
Isolation 与 MVCC
MVCC 的意义:
- 读写互不阻塞;
- 降低死锁概率;
- 实现一致性读;
Undo Log 在MVCC的作用:
- 每个事务有一个单增的事务ID;
- 数据页的行记录中包含了DB_ROW_ID,DB_TRX_ID,DB_ROLL_RTP;
- DB_ROLL_PTR将数据行的所有快照记录都通过链表的结构串联了起来。
Durability 与 Redo Log
持久化: 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
redo log是物理日志,记录的是页面的变化,它的作用是保证事务持久化。如果数据写入磁盘前发生故障,重启MySQL后会根据redo log重做。
企业实践
大流量 - Sharding
问题背景
- 单节点写容易成为瓶颈
- 单机数据容量上限
解决方案
- 业务数据进行水平拆分
- 代理层进行分片路由
实施效果
- 数据库写入性能线性扩展
- 数据库容量线性扩展
流量突增
扩容 - 问题背景
- 活动流量上涨
- 集群性能不满足要求
解决方案
- 扩容DB物理节点数量
- 利用影子表进行压测
实施效果
- 数据库集群提供更高的吞吐
- 保证集群可以承担预期流量\
代理连接池 - 问题背景
- 突增流量导致大量建联
- 大量建联导致负载变大,延时上升
解决方案
- 业务侧预热连接池
- 代理侧预热连接池
- 代理侧支持连接队列
实施效果
- 避免 DB 被突增流量打死
- 避免代理和 DB 被大量建联打死
稳定性 & 可靠性
3AZ高可用
- BinLog:binlog是mysql用来记录数据库表结构变更以及表数据修改的二进制日志,他只会记录表的变更操作,但不会记录select和show这种查询操作。
- 数据恢复:误删数据之后可以通过 mysqlbinlog 工具恢复数据。
- 主从复制:主库将binlog传给从库,从库接收到之后读取内容写入从库,实现主库和从库数据一致性。
- 审计:可以通过二进制日志中的信息进行审计,判断是否对数据库进行注入攻击。
三级机房部署
- 机房级别容灾
- 机房级别流量调度
proxy
- 读写分离,分库分表
- 限流,流量调度
监控报警
- 实时监控集群运行状态
- 提前上报集群风险
HA
- High Availability
- 实时监控DB运行状态
- 宕机快速切换
HA管理 - 问题背景
- db 所在机器异常宕机
- db 节点异常宕机
解决方案
- ha 服务监管、切换宕机节点
- 代理支持配置热加载
- 代理自动屏蔽宕机读节点
实施效果
- 读节点宕机秒级恢复
- 写节点宕机 30s 内恢复服务
总结
引用
- 字节内部课《后端入门 - 存储与数据库》
- 由Michael Stonebraker撰写红宝书
