

这是我参与「第五届青训营 」伴学笔记创作活动的第 14 天
前言
这是我将参加青训营期间的收获进行整理和总结,同时便于日后复习和查阅。如果能给各位小伙伴提供些帮助,也是我的荣幸,希望大家可以多多赐教,一起学习和交流。
消息(Message)是指在应用之间传送的数据,消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。消息队列(Message Queue) 是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
本篇文章主要内容:
- 前世今生
- 消息队列 - Kafka
- 消息队列 - BMQ
- 消息队列 - RocketMQ
消息队列的前世今生
消息队列是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
发展历程
- TIB: 世界上第一个现代消息队列软件,诞生于1985年,服务于金融机构和新闻机构。
- IBM MQ/WebSphere: 诞生于1993年,商业消息队列平台市场主要玩家。
- MSMQ: 微软发布于1997年。
- JMS: 诞生于2001年,本质上是一套Java API
- AMQP: 规范发布于2004年,同年
RAbbitMQ面市 - Kafka: 2010年由 Linked 开源
- RocketMQ: 2011年阿里中间件团队自研
- Pulsar: 2012年诞生于 Yahoo 内部
业界的消息队列对比
- Kafka: 分布式的、分区的、多副本的日志提交服务,
在高吞吐场景下发挥较为出色。 - RocketMQ: 低延迟、强一致、高性能、高可靠、万亿级容量和灵活的可扩展性,在一些
实时场景中运用较广。 - Rulsar: 是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体、采用存算分离的架构设计。
- BMQ: 和Pulsar架构类似,存算分离,初期定位是承接高吞吐的离线业务场景,逐步替换掉对应的Kafka集群。
消息队列 - Kafka
定义: Kafka是一个分布式的、高吞吐量、高可扩展性消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等,是大数据生态中不可或缺的产品之一。
使用场景: 业务日志、用户行为数据、Metrics数据
如何使用 Kafka:
- 首先需要创建一个Kafka集群;
- 需要在这个集群中创建一个Topic,并且设置号分片数量;
- 引用对应语言的 SDK,配置好集群和Topic等参数,初始化一个生产者,调用 Send 方法,将你的 Hello World 发送出去。
- 引入对应语言的SDK,配置好集群和Topic等参数,初始化一个消费者,调用Poll方法,你将收到刚刚发送出去的 Hello World。
基本概念
- Topic:逻辑队列,不同 Topic 可以建立不同的 Topic
- Cluster:物理集群,每个集群中可以建立多个不同的 Topic
- Producer:生产者,负责将业务消息发送到 Topic 中
- Consumer:消费者,负责消费 Topic 中的消息
- Consumer Group:消费者组,不同组 Consumer 消费进度互不干涉
- Offset:消息在 partition 内的相对位置信息。可以理解为唯一ID,在 partition 内部严格递增。
- Redlca:分片的副本,分布在不同的机器上,可用来容灾。 ISR:意思是同步中的副本。
Kafka 架构
Zookeeper:负责存储集群元信息,包括分区分配信息等。
一条消息的自述 | 处理流程
一般发送消息方为生产者Producer,接收消费消息方为消费者Consumer,消息队列服务端为Broker。消息从 Producer 发往 Broker ,Broker 将消息存储至本地,然后 Consumer 从 Broker 拉取消息,或者 Broker 推送消息至 Consumer,最后消费。
Producer端逻辑
批量发送: 批量发送可以减少 IO 次数,从而加强发送能力。
数据压缩: 通过压缩、减少消息大小,目前支持Snappy、Gzip、LZ4、ZSTD压缩算法。
Broker端逻辑
磁盘结构: 移动磁头找到对应磁道,磁盘转动,找到对应扇区,最后写入。寻道成本比较高,因此顺序写可以减少训道所带来的时间成本。
顺序写: 采用顺序写的方式进行写入,以提高写入效率。
消息索引: 按照时间窗口和消息大小Consumer 通过发送FetchRequest 请求消息数据,Broker 会将指定 offset 处的消息小窗口发送给 Consumer
零拷贝: Consumer 从 Broker 中读取数据,通过 sendfile 的方式,将磁盘读到 os 内核缓冲区后,直接转到 socket buffer 进行网络发送。Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入。
Consumer端逻辑
Rebalance:
问题总结
- 运维成本高。
- 对于负载不均衡的场景,解决方案复杂。
- 没有自己的缓存,完全依赖 Page Cache。
- Controller 和 Coordinator 和 Broker 在同一进程中,大量 IO 会造成其性能下降。
消息队列 - BMQ
BMQ兼容Kafka协议,存算分离,云原生消息队列。初期定位是承接高吞吐的离线业务场景。
BMQ 架构模型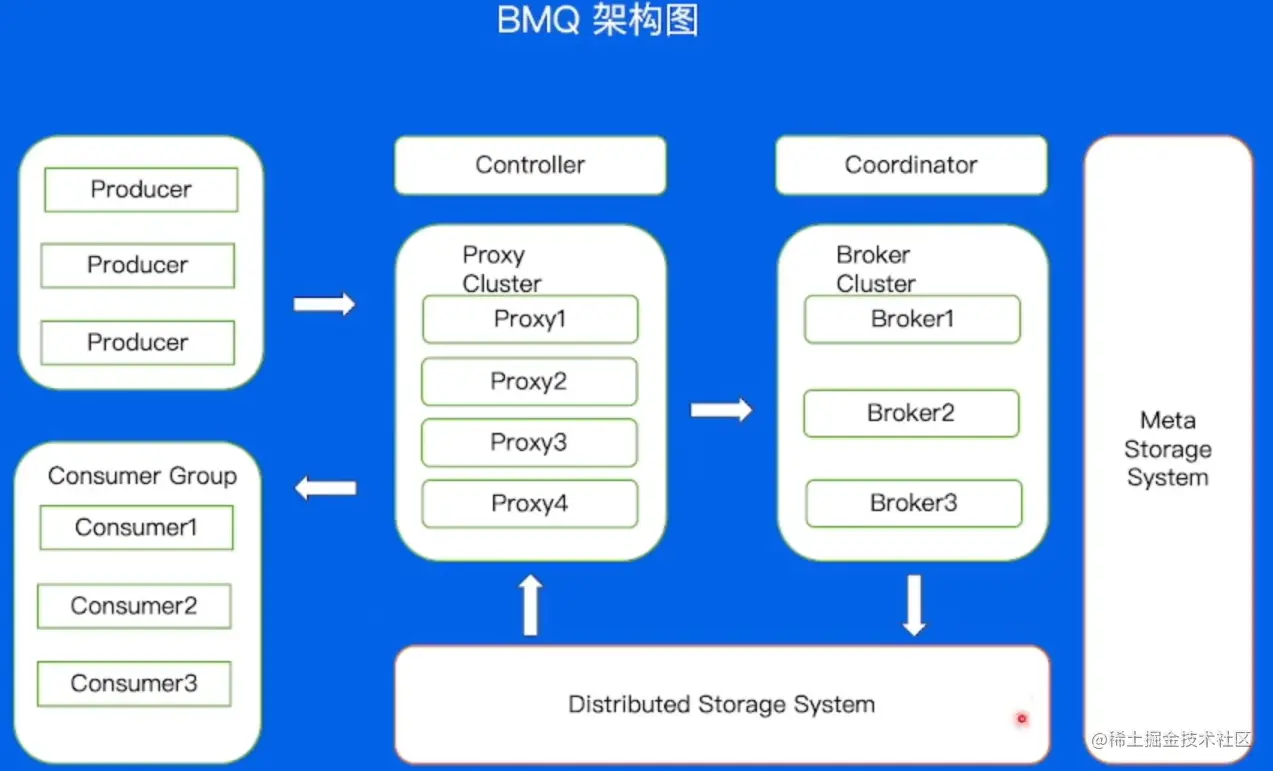
运维操作对比:
| 具体操作 | Kafka | BMQ |
|---|---|---|
| 重启 | 需要数据复制,分钟级重启 | 重启后可以对外服务,秒级完成 |
| 替换 | 需要数据复制,分钟级替换,甚至天级别 | 替换后可以对外服务,秒级完成 |
| 扩容 | 需要数据复制,分钟级扩容,甚至天级别 | 扩容后可以对外服务,秒级完成 |
| 缩容 | 需要数据复制,分钟级缩容,甚至天级别 | 缩容后可以对外服务,秒级完成 |
文件结构对比:
BMQ 读写流程
Partition 状态机
保证对于任意分片在同一时刻只能在一个 Broker 上存活
写文件 Failover:
BMQ 高级特性
泳道消息
开发流程:开发—> BOE —> PPE —> Prod
BOE: Bytedance Offline Environment,是一套完全独立的线下机房环境。
PPE: Producet Preview Environment,及产品预览环境。
Databus
DatabusClient databusClient = new DatabusClient(channelName);
String key ="test_key";
String value = "test_value";
Boolean ok = true;
try {
databusClient.send(key, value, 0);
} catch (IOException e) {
System.out.printIn("send fail");
ok = false;
}
databusClient.stop();
- 简化消息队列客户端复杂度。
- 解耦业务与 Topic。
- 缓解集群压力,提高吞吐。
直接使用原生 SDK 的问题:
- 客户端配置复杂。
- 不支持动态配置,更改配置需要停掉服务。
- 对于 latency 不是很敏感的业务,batch 效果不佳。
Parquet
Apqche Parquet 是 Hadoop 生态圈中一种新型列式存储格式,它可以兼容 Hadoop 生态圈中大多数计算框架(Hadoop、Spark等),被多种查询引擎支持(Hive、Impala、Drill等)。
| 行式存储 | 1 | A | 12 | 2 | B | 3 | C |
|---|---|---|---|---|---|---|---|
| 列式存储 | 1 | 2 | 3 | A | B | C | 12 |
直接在 BMQ 中将数据结构化,通过 Parquet Engine,可以使用不同的方式构建 Parquet 格式文件。
消息队列 - RocketMQ
使用场景 例如,针对电商业务线,其业务涉及广泛,如注册、订单、库存、物流等;同时,也会涉及许多业务峰值时刻,如秒杀活动、周年庆、定期特惠等。
基本概念
| 名称 | Kafka | RocketMQ |
|---|---|---|
| 逻辑队列 | Topic | Topic |
| 消息体 | Message | Message |
| 标签 | 无 | Tag |
| 分区 | Partition | Consumer Queue |
| 生产者 | Producer | Producer |
| 生产者集群 | 无 | Producer Group |
| 消费者 | Consumer | Consumer |
| 消息者集群 | Consumer Group | Consumer Group |
| 集群控制器 | Controller | Nameserver |
架构: 数据流也是通过 Producer 发送给 Broker 集群,再由 Consumer 进行消费。
Broker 节点有 Master 和 Slave 的概念,NameServer 为集群提供轻量级服务发现和路由。
高级特性
事务消息
延迟消息
消费重试和死信队列
引用
- 字节内部课《后端入门 - 中间件》
