

这是我参与「第五届青训营 」伴学笔记创作活动的第 2 天
消息队列
定义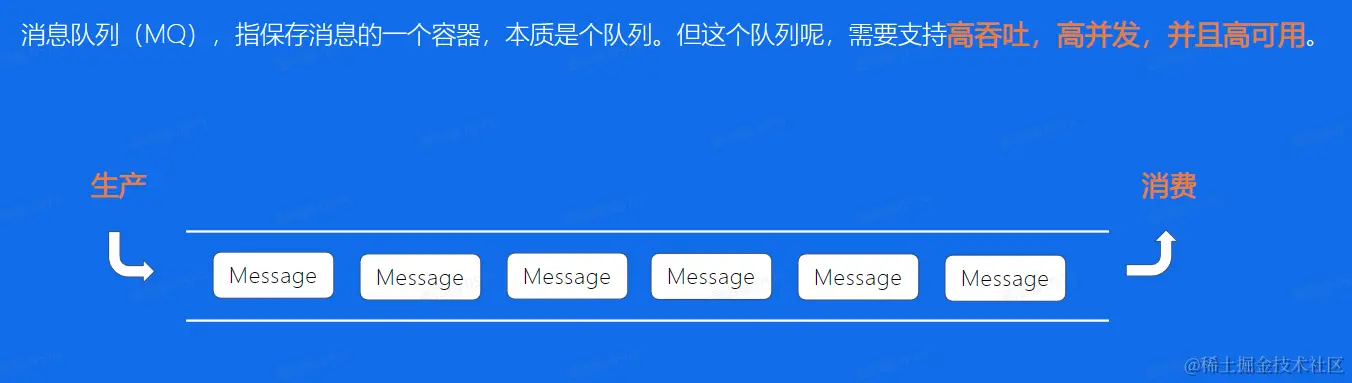
发展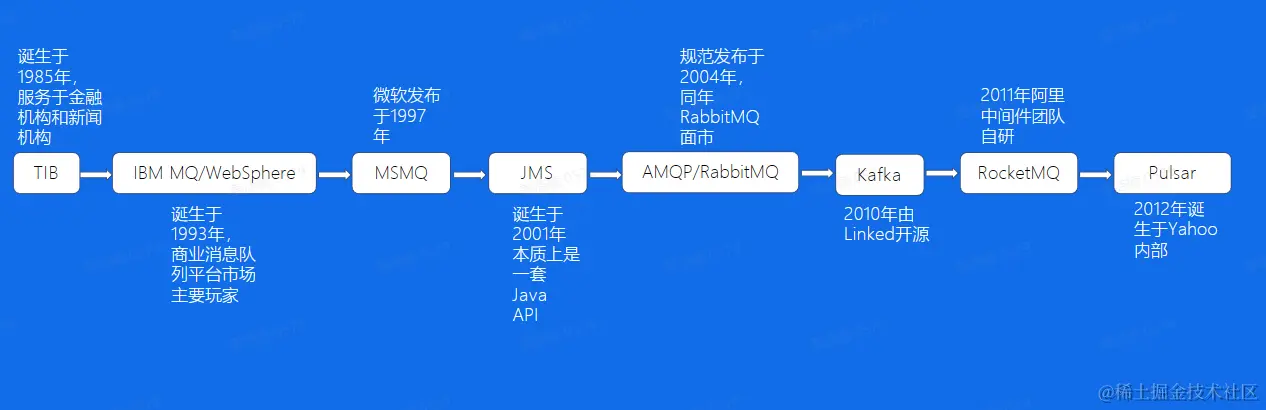
常见消息队列
Kafka
- 场景:一般使用在离线的消息处理中,如日志信息,metrics信息(程序状态信息)
Kafka使用
- 创建集群
- 创建Topic,设置分区数
- 引入Kafka的SDK,编写上游生产者逻辑,把消息发送到Kafka中
- 下游消费者拉去消息,编写消费者逻辑
基本概念
- Topic:逻辑队列,Kafka的基本处理单元,不同的业务逻辑建立不同的Topic
- Cluster:物理集群
- Producer:生产者,生产业务消息发送到Topic中
- Partition:分区,不同的分区消息可以并发处理,提高吞吐能力
- consumer:消费者,消费Topic的消息
offset概念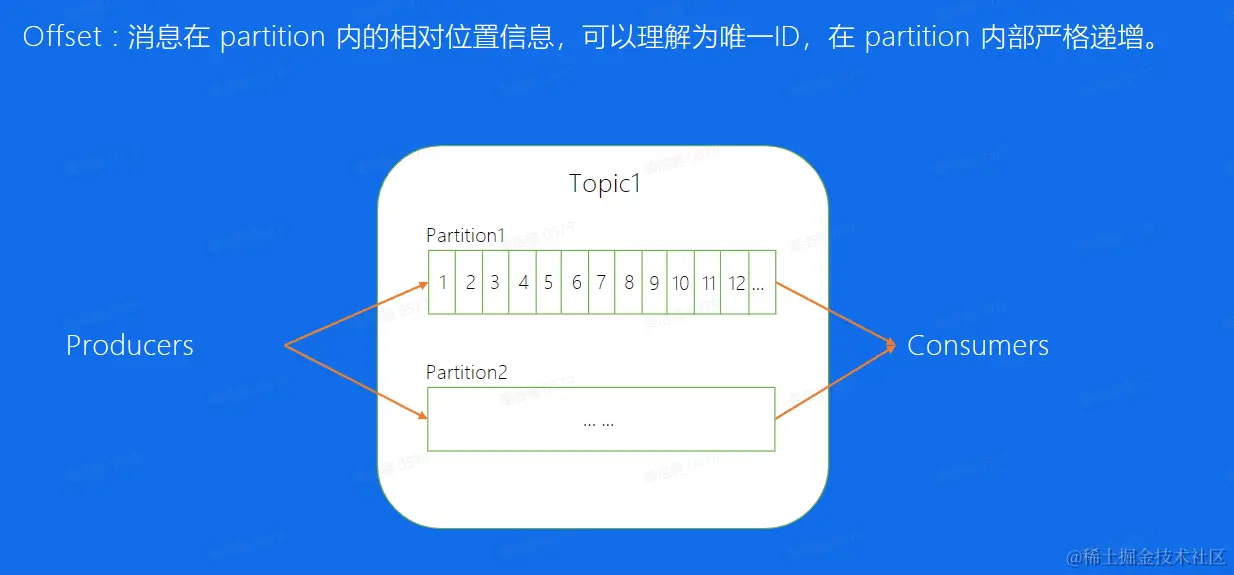
- 消息在partition内的相对位置
replica概念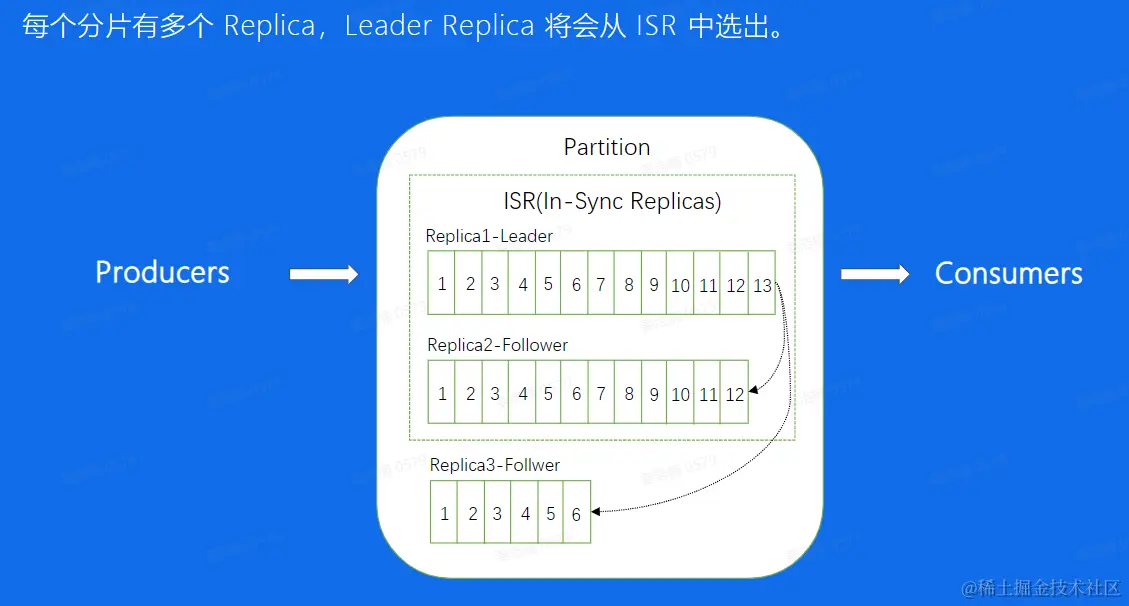
- Follower拉取Leader的消息,不断追求和Leader同步,同步过程中差距过大的Follower会被踢出
- 作用:Leader一旦宕机,可以从ISR中选择新Leader
数据复制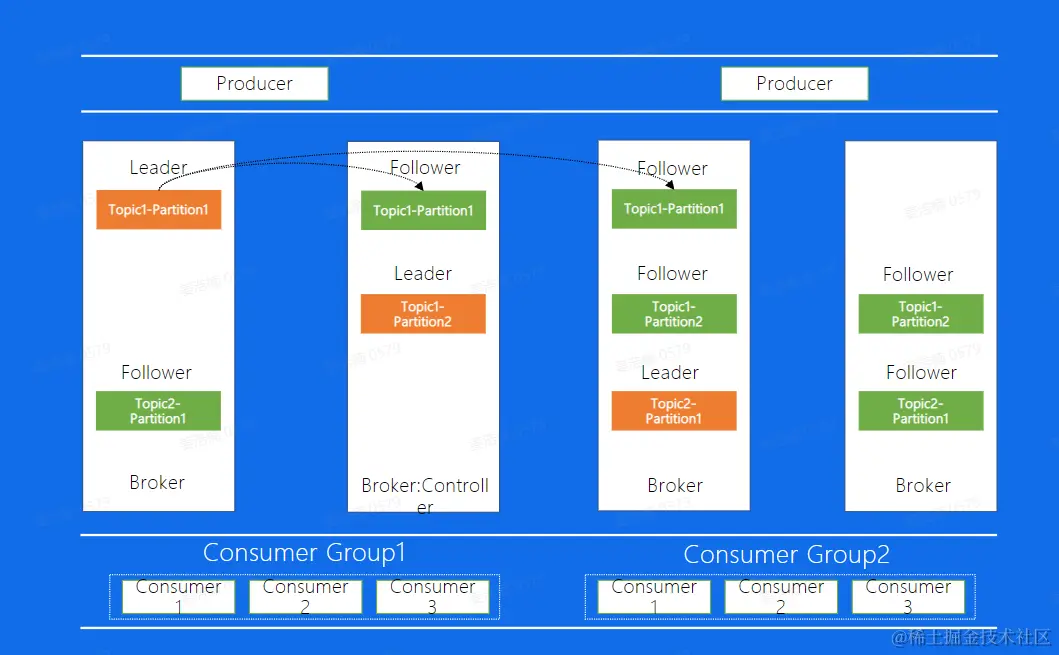
- broker:集群节点
- 图中每个partition都有三个副本
- controler作用:计算图中各个topic下各个partition的分区位置
架构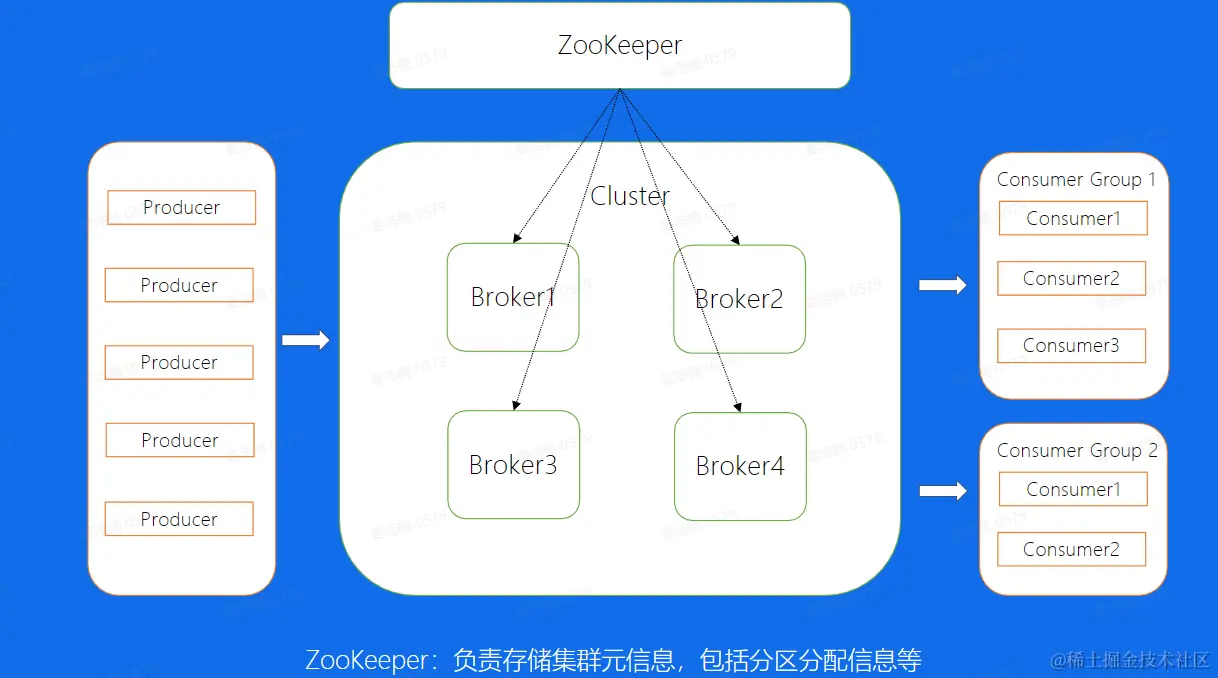
从消息视角研究Kafka的高吞吐
- 思考:下图的消息发送方式有什么问题
- 吞吐率依赖于等待时间
- 改进:把消息打包提高吞吐量
- 单个消息很大的时候,对于一个broker来说带宽可能不够用
- 改进:压缩
broker存储
副本以日志形式写到磁盘上
- 由于消息的过期机制,日志不可能无限存储
- 把副本切分成LogSegment
磁盘结构
- 机械硬盘中移动磁头寻道时间很长,Kafka为了减少时间成本,采用顺序写
顺序写
读消息
- 如何索引
- 首先二分法找到小于目标offset的最大文件,因为logsegment的命名是以存储在其首部的消息的offset为文件名的,所以文件名是不连续的,本例选择6.log
- 文件的组织是系数索引的,并且文件的最小存储单元是消息包(batch)
- 首先二分法找到小于目标offset的最大文件,因为logsegment的命名是以存储在其首部的消息的offset为文件名的,所以文件名是不连续的,本例选择6.log
- 如何利用时间戳索引
- 在offset映射前加上时间戳映射
- 发送给consumer的过程中Kafka的优化
- 传统数据拷贝的io
- 传统数据流中间产生了很多数据的拷贝
- Kafka中broker的零拷贝
- 降低了三次数据拷贝
- 传统数据拷贝的io
consumer消息接收端
- 需要解决的问题:对于每个partition需要由哪个consumer来消费的问题
- 手动分配
- 容灾能力差,如果consumer3挂掉了,partition7,8就停止消费了,如果要新增partition4,则需要停掉集群
- 自动分配-High Level
- 选择一个broker作为coordinate,帮助consumer group分配partition,每当有新的consumer加入或者宕机,partition和consumer就会重新分配达到平衡,也叫rebalance
- 选择一个broker作为coordinate,帮助consumer group分配partition,每当有新的consumer加入或者宕机,partition和consumer就会重新分配达到平衡,也叫rebalance
- 手动分配
- rebalance的发生
- leader的作用,制定分配方案
- 建立分配之后,每隔一段时间consumer要发送心跳,监控状态
总结Kafka提高稳定性和吞吐的功能
- producer:批量发送,数据压缩
- broker:顺序写,消息索引,零拷贝
- consumer:rebalance
