这是我参与「第五届青训营 」笔记创作活动的第3天
通过青训营课程之分布式架构学习,其中的「Raft算法」让我十分感兴趣并且想要更深层次地了解该算法。
共识算法 Raft
什么是分布式共识?
对于单机架构来说,很显然我们无须考虑共识的问题--客户端与数据库之间不会出现拜占庭将军问题,即不会出现数据篡改的情况。但在分布式架构中,往往存在着多个节点,如何实现客户端与多个节点之间的信息一致便称为分布式共识。
什么是Raft算法?
Raft算法和Paxos算法类似,都是用来在多个节点之间达成共识,解决一定CAP问题中的一致性问题。
Raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。遵从此协议的分布式集群会对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。
Raft是怎么工作的?
Raft的节点状态
Raft将节点的状态分为以下三种:follower , candidate , leader 。follower顾名思义就是跟随者,负责听从leader的命令
candidate是当follower长时间没有收到来自leader的消息时,就会转变为candidate,进而竞选leader的地位
leader负责跟客户端进行通信,接受客户端的命令传达给follower
Leader Election (领导选举)
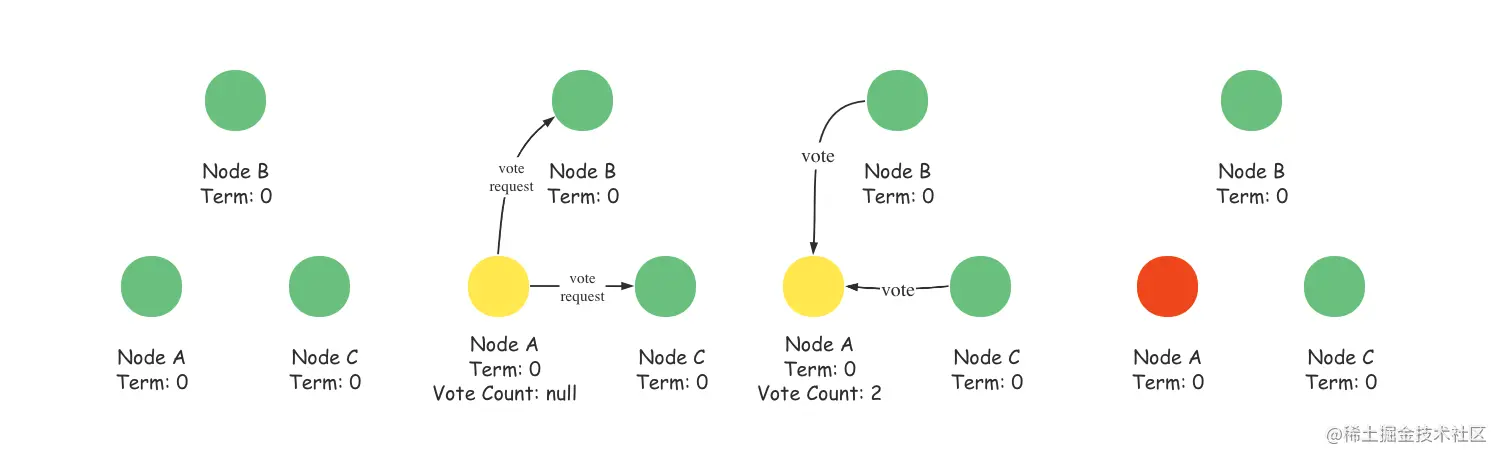
如上图所示,Raft中的领导选举开始时,所有的节点都为跟随者状态;当跟随者长时间没有收到来自领导者的消息时,那他们将可以成为候选人并且向其他节点发起投票请求,其他节点在收到候选人节点的投票请求后,通过投票响应请求;在一轮领导者选举中票数占多的候选人将成为新的领导者。
接下来系统的所有更改将率先经过领导者。
Log Replication (日志复制)
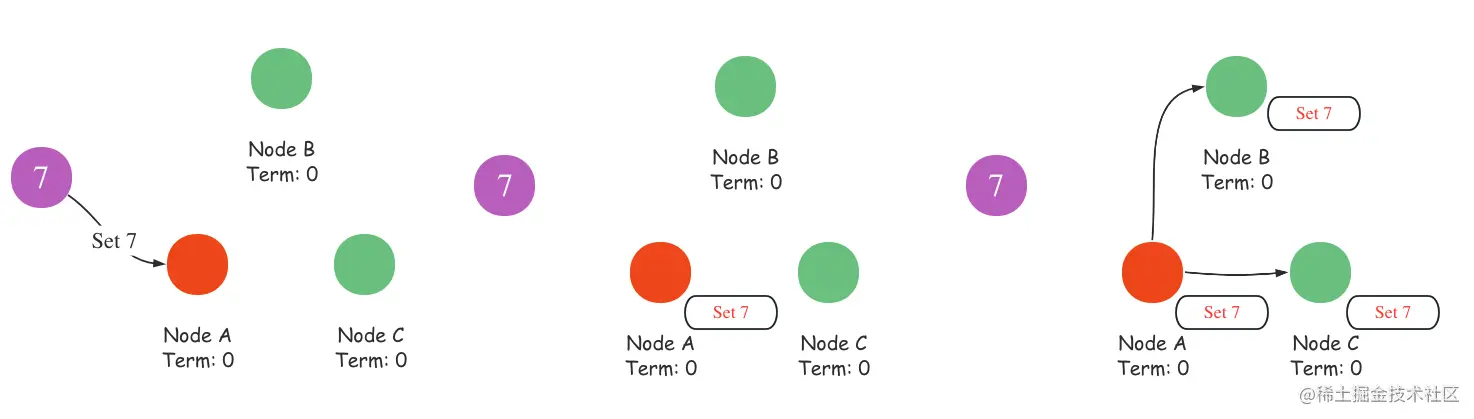
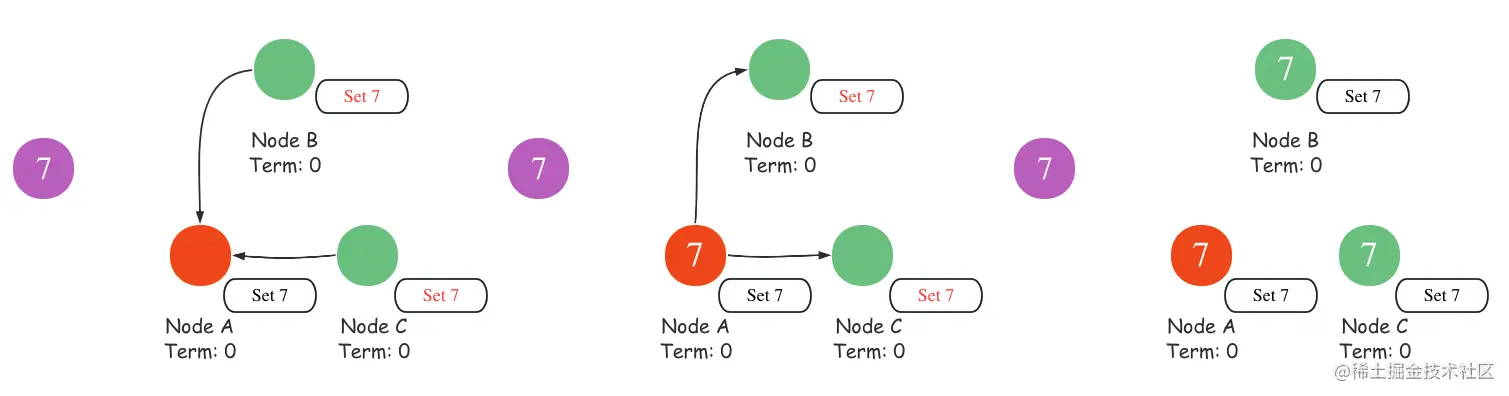
如图所示,当系统中存在领导者的时候,客户端与系统的交互会先通过leader,leader在接收到客户端传来的命令的时候先用log日志的形式记录,再将log复制给其他的跟随者节点,在收到跟随者节点写入条目完成确认时,领导节点提交该条目,再通知跟随者们条目已经提交,跟随者们提交条目。至此,集群已经就系统状态达成共识。
总结
Raft是工程上使用较为广泛的强一致性、去中心化、高可用的分布式协议。遵从此协议的分布式集群会对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分割的情况下。
由于时间的关系没有更详尽地讨论关于选举时间和心跳时间的问题以及网络分区的问题,Raft在实现系统共识方面十分地精妙,有时间再更新一篇关于领导选举细节和日志复制细节的笔记。
引用参考
1.分布式共识算法 —— Raft详解
2.The Raft Consensus Algorithm


