

“开启掘金成长之旅!这是我参与「掘金日新计划 · 2 月更文挑战」的第 2 天,点击查看活动详情”
该文主要内容为一个完整神经网络的代码实现
1 神经网络的主要过程有:
1.1 前馈过程或者叫正向传播
1.2 误差反传或者叫反向传播
1.3 设置迭代次数训练模型
1.4 设置评价指标,生成评价指标
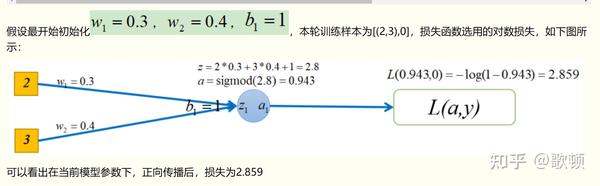
2 正向传播图示(仅供参考)与代码:
注:正向传播较容易理解,无非是每层都进行:权重*输入+偏移项,再使用激活函数计算后作为下一层的输入

def __init__(self, layer_list=[], lr=0.1, epochs=100):
self.lr = lr #学习率
self.layer_list = layer_list # 每层神经元(节点)个数
self.epochs = epochs #迭代次数
# 超参初始化
def weight_bias_init(self):
self.W = {} #权重字典,key是层号,value是对应权重矩阵
self.b = {} #偏置字典,key是层号,value是对应偏置矩阵
self.layer_num = len(self.layer_list)-1 #网络层数(权重矩阵的个数,输入层无权重)
for idx in range(self.layer_num): #为每层layer初始化W与b矩阵,每层 W 的shape为(前一层神经元个数,后一层神经元个数)
self.W[idx] = np.random.randn(self.layer_list[idx], \
self.layer_list[idx+1]) * 0.01 #正态分布
self.b[idx] = np.random.randn(self.layer_list[idx+1])
def forward(self, X, y):
self.X = X #将输入X保存为类的属性,可供其他函数使用
self.y = np.array(y).reshape(-1, 1) #更改y的shape,防止运算出错
#记录各层的z与a,反向传播时会用到
self.z = {} #字典,记录每层激活前的输出(z = W*X + b)
self.a = {} #字典,记录每层激活后的输出(a = sigmoid(z))
input = self.X
for idx in range(self.layer_num): #循环向前累乘
self.z[idx] = np.dot(input, self.W[idx]) + self.b[idx] #z = W*X + b
self.a[idx] = self.sigmoid(self.z[idx]) #a = sigmoid(z)
input = self.a[idx] #更新输入
self.output = self.a[self.layer_num-1] #记录最后一层输出
self.loss = -np.mean(self.y * np.log(self.output) + \
(1-self.y) * np.log(1-self.output)) #对数损失
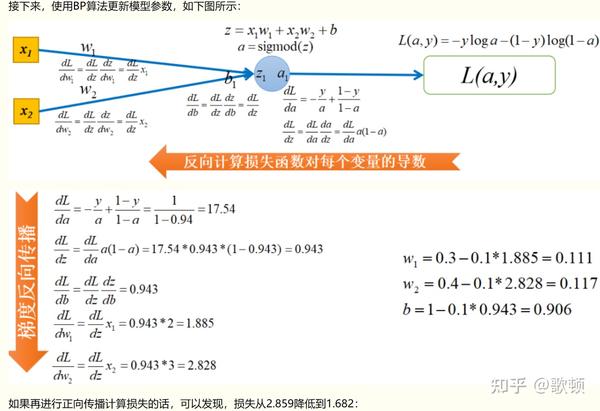
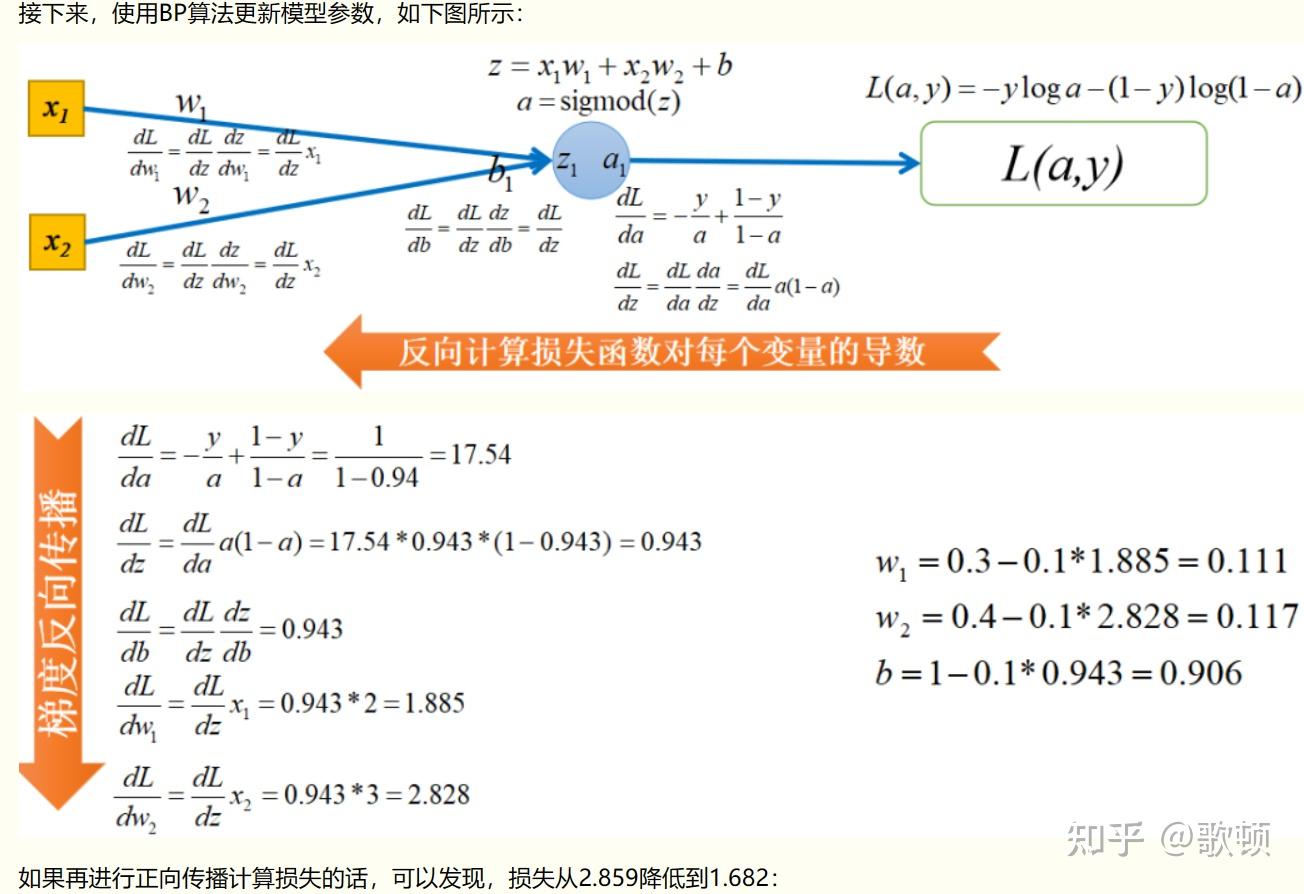
3 反向传播图示以及代码
关于反向传播该图仅作为参考之一,如果有困惑可以详细看参考资料,反向传播为该内容的核心和难点。
# sigmoid的一阶导数
def Dsigmoid(self, x):
return self.sigmoid(x) * (1 - self.sigmoid(x))
# 反向传播
def backward(self):
#跟权重保存方式一样,使用字典存储,key为对应的层号
self.dz = {} #对每层z的求导
self.dW = {} #对每层W的求导
self.db = {} #对每层b的求导
idx = self.layer_num - 1 #从后往前求导
while(idx>=0):
#********** 求dz *********#
if(idx==self.layer_num-1): #最后一层的求导比较特殊,套最后一层求导的公式dz3
self.dz[idx] = (self.output-self.y) * self.Dsigmoid(self.z[idx]) #元素乘
else: #前层都可根据最后一层的dz迭代得到,套迭代公式dzi
self.dz[idx] = np.dot(self.dz[idx+1], self.W[idx+1].T) \
* self.Dsigmoid(self.z[idx])
#********** 求dW *********#
if(idx == 0): #idx为0时,即到达第一层时,前层输入a[idx-1]是X
self.dW[idx] = np.dot(self.X.T, self.dz[idx]) / len(self.X) #梯度需除上总样本数
else: #idx不为0时迭代计算即可
self.dW[idx] = np.dot(self.a[idx-1].T, self.dz[idx]) / len(self.X)
#********** 求db *********#
self.db[idx] = np.sum(self.dz[idx], axis=0) / len(self.X) #db=dz, 但是需要所有维度取平均
idx -= 1 #跳前一层
# 求完所有层的梯度后,更新即可
for idx in range(self.layer_num):
self.W[idx] -= self.lr * self.dW[idx]
self.b[idx] -= self.lr * self.db[idx]
4 完整代码1展示:
上述代码以及接下来的完整代码1可以参考此处:
[代码1](深度学习3 -- MLP实现_Lian_Ge_Blog的博客-CSDN博客)
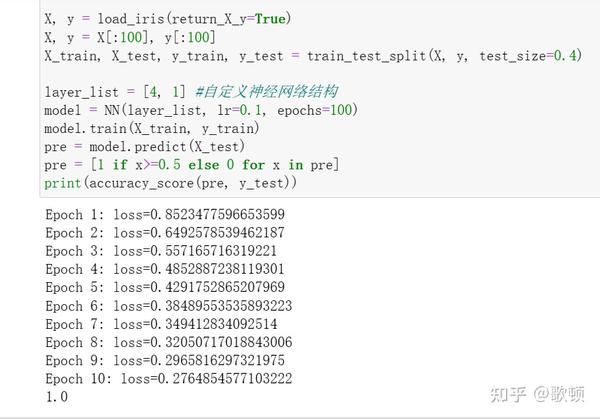
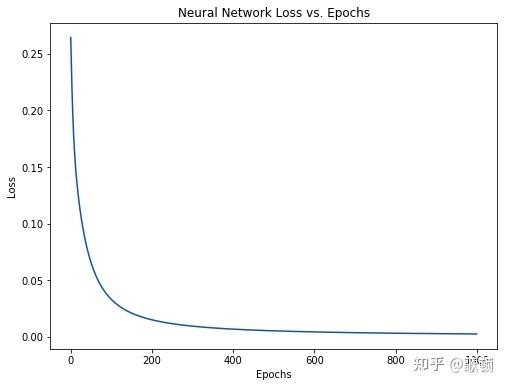
运行结果展示:
5 完整代码2展示:
同代码1链接
# Make some predictions
emily = np.array([-7, -3]) # 128 pounds, 63 inches
frank = np.array([20, 2]) # 155 pounds, 68 inches
print("Emily: %.3f" % network.feedforward(emily)) # 0.951 - F
print("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M
注:代码1主要是用矩阵的方式实现,虽然易于理解但是从公式到代码实现,代码2更丝滑一些,代码2理解后再去理解代码1,后续大多深度学习场景都会是矩阵形式。
6 参考资料:
1 该文承接前两篇文章,都为对下面文章的总结,但是该文章代码部分第一为python2实现,第二 个人无法理解参透,所以该文代码部分为另外文章所给(可以用微信连接打开,浏览器可能会吞掉图片): 参考文章1
2 关于代码1和2可以分别参考一下两篇文章,带入原作者思路,不理解的地方继续看参考资料 代码1 代码2
3 关于反向传播的理解,在两个代码文章中都有些抽象,可以配合一下文章理解 公式详解
