CPU水位负载均衡
这是我参与「第五届青训营」伴学笔记创作活动的第5天
本节课我主要关注的重点在于
- 实现随机权重负载均衡的实际方案
每个主机的性能可能会有所不同,这也就导致它们处理请求的能力会不同,而为了提高吞吐量,我们很多时候需要让“能者多劳”,也就是说需要将更多的请求让性能高的主机来处理
那么我们要如何解决这个问题?
就需要一种随机权重负载均衡的方法,其中权重由每台主机的处理能力来决定
随机权重负载均衡,如何给定每个服务实例响应的权重,按照什么标准来给定?
-
负载均衡是在客户端方进行,那我们要如何获取服务的权重?
- 只能够从注册中心中获取,所以说我们的
注册中心需要存储服务的权重
- 只能够从注册中心中获取,所以说我们的
-
服务的权重由其主机的处理能力来决定,注册中心要如何获取这些信息呢?
- 所以服务实例应当能
对外提供资源使用情况 - 或者提供主机的
物理资源信息(硬件信息,如CPU型号等)
- 所以服务实例应当能
实际方案
1、自适应静态权重
- 由服务实例对自己的资源使用情况进行统计(计算QPS、CPU利用率等信息)
- 然后服务实例通过资源使用情况,调用注册中心给定的API,修改自身的权重
缺点:缺乏紧急回滚能力。
因为是由实例本身来修改权重,所以如果某个实例给自己改了一个较大的权重,但却被大量的请求耗尽资源(类似于宕机,但还能运行),但仍有大量请求发来,实例却无暇去修改权重,这就会导致致命问题的发生
发展方向: 提高紧急回滚能力、增加运行时自适应能力
2、自适应动态权重Alpha
在上一种方案中,我们需要将实例的权重进行回滚,但却没有服务可以做到这件事
同时,我们还需要有一个服务,可以根据多个实例的资源使用情况,给它们设定响应的权重
这两件事都有一个共同的目标,我们都需要一个中间件服务去做这些事
- 这种方案设计了一个用于动态修改权重的中间件,它会采集所有服务实例的资源使用情况,然后再综合这些信息,动态修改各个实例的权重,同时也保证了对错误权重的修改能力
缺点:过度流量倾斜可能会造成异常情况,比如说流量都向X服务倾斜了,那X服务自然就会被判定为性能较强的,所以它的权重会较大,但实际上Y服务的性能会更强,这就会导致权重异常
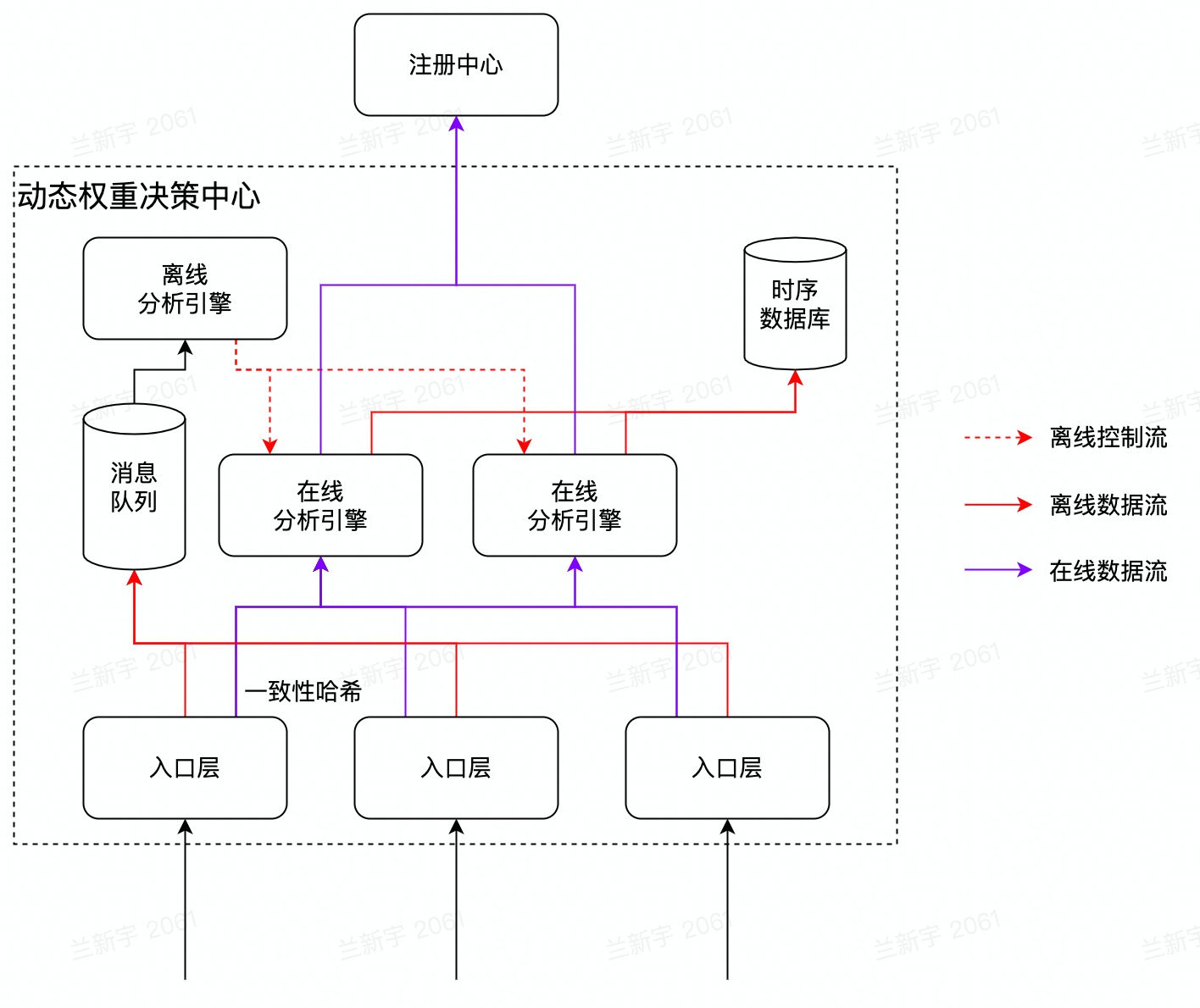
3、自适应动态权重Beta
在上一种方案中,在过度流量倾斜的场景下,会出现一种权重与主机性能不匹配的异常情况
其出现的主要原因就是我们决策中心的判断指标过于单一,所以需要更多的指标去帮助我们确认
于是在这种方案中,就采集了另外一种指标 ———— RPC指标(比如响应延迟)
- 采集了更多的指标 —— RPC指标(响应延迟),让决策更加精准,防止异常情况
- RPC指标是一种时序性数据,所以还提供了时序数据库来进行存储
缺点:
加多了一层时序数据库,会有数据库压力过大的风险决策中心需要负责更多的事情,风险也提高了
4、自适应动态权重Release(微服务化、离线在线区分)