

这是我参与「第五届青训营」伴学笔记创作活动的第 11 天
前言
在听完课后,结合网上查找到的知识,对分布式理论有了初步的认识,学员手册上的课后问题也有了自己的最优解。现将问题及解答分享如下,供大家参考。
为什么TCP采用三次握手?而不是两次和四次?
TCP 的可靠连接是靠 seq( sequence numbers 序列号)来达成的。
所以说,建立可靠连接,需要对客户端和服务器的起始序列号达成共识。TCP建立链接的过程如下: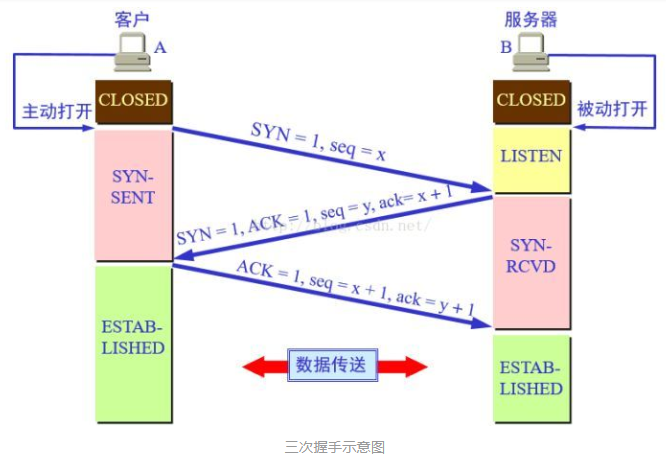
为什么不能两次握手?| 两次握手演绎
第一步:
客户端发送一个起始序列号seq = x的 报文段给服务器。
第二步:
服务器端返回向客户端发送确认号 ack = x+1,表示对客户端的起始序列号x 表示确认,
并告诉客户端,他的起始序列号是 seq = y.
所以,为什么不能两次握手?
因为这种情况下,只有服务器对客户端的起始序列号做了确认,但客户端却没有对服务器的起始序列号做确认,不能保证传输的可靠性。
为什么不是四次握手?| 四次握手演绎
第一步:
客户端A 发送同步信号SYN + A的初始序列号 seq = x
第二步:
服务器端B 确认收到A的同步信号,并记录A的初试序列号到本地,
并向A发送确认信息 ack =x+1。
第三步:
B发送同步信号SYN + B的初始序列号 seq 给客户端A。
第四步:
A确认收到B的同步信号,并记录 B'的初试序列号到本地,并向B发送确认信息 ack = y + 1.
很显然,第二,三步可以合并,只需要三次握手,可以提高连接的速度与效率。
总结:
TCP链接之所以可靠,是因为其链接是面向字节的。
在通信的过程中,协议会给每个字节一个序分配一个序号。三步握手的过程,主要是为了互相确认双方的起始序列号。
如果只进行两次握手, 客户端发送链接请求及起始序列号seq = x, 收到 服务器端的起始序列号seq = y及对客户端序列号seq= x 的确认。此时,双方就 客户端的起始序列号达成了共识。
此时,并没有对服务器的起始序列号达成共识,所以就需要进行第三次握手。对B的起始序列号达成共识,不能保证通信的可靠。
如果进行四次握手,在四次握手的过程中,可以把第二、三步合并,这样可以提高连接的速度与效率。
什么场景适合乐观锁?什么场景适合悲观锁?
悲观锁和乐观锁的区别
场景
什么时候使用乐观锁?
资源提交冲突,其他使用方需要重新读取资源,会增加读的次数,但是可以面对高并发场景,前提是如果出现提交失败,用户是可以接受的。因此一般乐观锁只用在高并发、多读少写的场景。
其中:GIT,SVN,CVS等代码版本控制管理器,就是一个乐观锁使用很好的场景,例如:A、B程序员,同时从SVN服务器上下载了code.html文件,当A完成提交后,此时B再提交,那么会报版本冲突,此时需要B进行版本处理合并后,再提交到服务器。这其实就是乐观锁的实现全过程。如果此时使用的是悲观锁,那么意味者所有程序员都必须一个一个等待操作提交完,才能访问文件,这是难以接受的。
什么时候使用悲观锁?
一旦通过悲观锁锁定一个资源,那么其他需要操作该资源的使用方,只能等待直到锁被释放,好处在于可以减少并发,但是当并发量非常大的时候,由于锁消耗资源,并且可能锁定时间过长,容易导致系统性能下降,资源消耗严重。因此一般我们可以在并发量不是很大,并且出现并发情况导致的异常用户和系统都很难以接受的情况下,会选择悲观锁进行。
示例
乐观锁
版本号控制
1, start transaction
2, first_version = get_cur_version() // 获取当前数据版本
3, update_data(version+=1) // 更新操作版本号+1
4, cur_version = get_cur_version() // 提交更新时,获取版本号
5, if first_version == cur_version // 比较提交时的版本号与第一次获取的版本号,如果一致,那么认为资源是最新的,可以更新
then commit
else rollback or raise exception // 否则回滚或者抛出异常
时间戳控制
1, start transaction
2, first_timestamp = get_cur_timestamp()
3, update_data(timestamp=get_sys_cur_timestamp)
4, if first_timestamp = get_cur_timestamp()
then commit
else rollback or raise Exception
悲观锁
悲观锁的实现一般都是通过锁机制来实现的,锁可以简单理解为资源的访问的入口。如果要对一个具有锁属性的资源执行访问时,在更新操作时,需要持锁权才能进行操作,但是往往这种操作可以保证数据的一致性和完整性。例如数据库表的行锁。
RAFT协议中该如何解决Stale读的问题?
解决方案:
引入一个新的概念, region leader。region leader 是一个逻辑上的概念, 任意时刻对于某一个 region 来说, 一定只拥有一个 region leader, 每个 region leader 在任期之内尝试每隔 t 时间间隔, 在 raft group 内部更新一下 region leader 的 lease. 所有的读写请求都必须通过 region leader 完成,
但是值得注意的是, region leader 和 raft leader 可能不是一个节点,当 region leader 和 raft leader 不重合的时候,region leader 会将请求转发给当前的 raft leader,当网络出现分区时,会出现以下几种情况:
- region leader 落在多数派,老 raft leader 在多数派这边
- region leader 落在多数派,老 raft leader 在少数派这边
- region leader 落在少数派,老 raft leader 在多数派这边
- region leader 落在少数派,老 raft leader 在少数派这边
对于第一种情况,region leader 的 lease 不会过期,因为 region leader 的心跳仍然能更新到多数派的节点上,老的 raft leader 仍然能同步到大多数节点上,少数派这边也不会选举出新的 leader, 这种情况下不会出现 stale read。
第二种情况,就是开篇提到会出现 stale read 的典型情况,老的 raft leader 被分到了少数派这边,多数派这边选举出了新的 raft leader ,如果此时的 region leader 在多数派这边。
因为所有的读写请求都会找到 region leader 进行,即使在原来没有出现网络分区的情况下,客户端的请求也都是要走 node 1 ,经由 node 1 转发给 node 5,客户端不会直接访问 node 5,所以此时即使网络出现分区,新 leader 也正好在多数派这边,读写直接就打到 node 1 上,皆大欢喜,没有 stale read。
第三种情况,region leader 落在少数派这边,老 raft leader 在多数派这边,这种情况客户端的请求找到 region leader,他发现的无法联系到 leader(因为在少数派这边没有办法选举出新的 leader),请求会失败,直到本次 region leader 的 lease 过期,同时新的 region leader 会在多数派那边产生(因为新的 region leader 需要尝试走一遍 raft 流程)。因为老的 region leader 没办法成功的写入,所以也不会出现 stale read。但是付出的代价是在 region leader lease 期间的系统的可用性。
第四种情况和第三种情况类似,多数派这边会产生新的 raft leader 和 region leader。
总体来说,这种方法牺牲了一定的可用性(在脑裂时部分客户端的可用性)换取了一致性的保证。
