

规则引擎学习
这是我参与「第五届青训营 」伴学笔记创作活动的第6天
认识规则引擎
举个例子,比如在活动期间购买商品获得积分 < 100得20,<200得80
但后续发现规则不太好,过了几天,运营同学说,这个效果不太好,我们再改下规则,变成100-200 元的赠送20,200-500元赠送90,500-800赠送100..如此类推一直到1W。
然后后面产品又脑洞大开了,觉得这个条件不够精细化,还要根据商品的标签属性,用户标签来判断。如果是新用户就乘二,如果商品是xx活动的特卖商品,积分就加多20.
输入:计算规则、商品价格、用户标签、商品属性….
输出:积分
规则简单容易配置、可扩展
规则引擎的定义
规则引擎是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
规则引擎前
 规则引擎后
规则引擎后
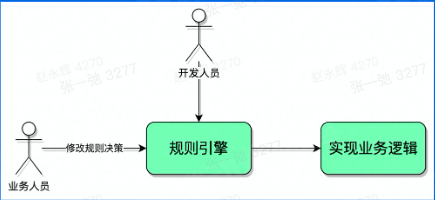 解决开发人员重复编码的问题
解决开发人员重复编码的问题
业务决策与服务本身解轉,提高服务的可维护性缩短开发路径,提高效率
组成部分
- 数据输入
支持接受使用预定义的语义编写的规则作为策略集。比如 "price >500”
接受业务的数据作为执行过程中的参数,比如价格、标签等
- 规则理解
能够按照预先定义的词法、 语法、优先級、运算符等正确理解业务规则所表达的语义。
- 规则执行
应用场景
风控对抗、 活动策略运营、数据分析和清洗
编译原理
规则引擎的编译原理
过程 理解(词法分析和语法分析)-> 执行(抽象语法树)-> 输入输出(参数注入和类型检查)
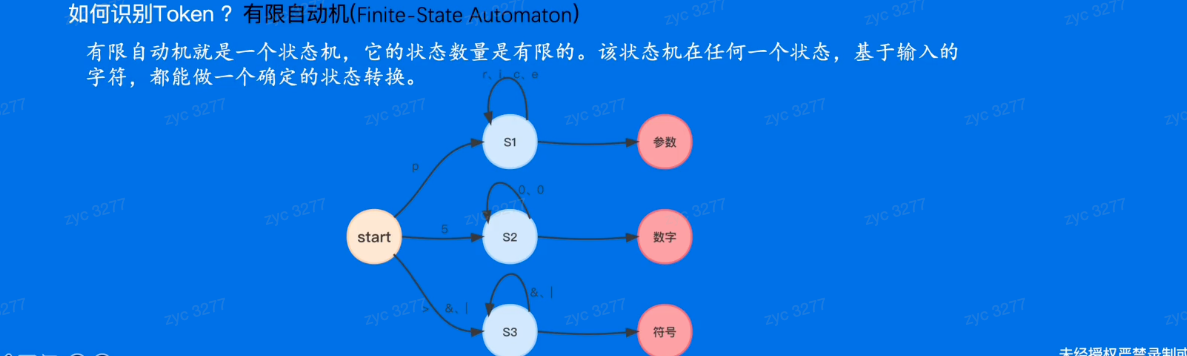
词法分析 Lexical Analysis
- 词法分析:把源代码宇符串转换为词法单元
(Token)的这个过程
例如 :

有限自动机的概念
语法分析
语法分析:在词法分析的基础上识别出表达式的
语法结构
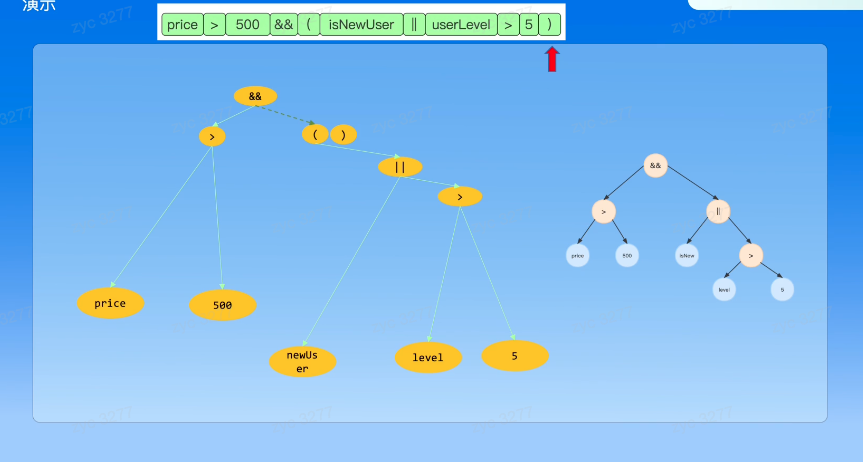
表达式抽象语法结构的树状表示,对于一个表达式,抽象语法树一定时唯一确定的
抽象语法树
抽象语法树是上下文无关语法,即一条表达式的结果与上下文无关 且语言句子无需考虑上下文,就可以判断准确性。可以使用巴克斯范式(BNF)来表示
巴克斯范式可以表示优先级,通过递归下降算法,来自顶向下构造语法树
不断的对Token进行语法展开,展开过程中可能会遇到递归的情况
下面是演示
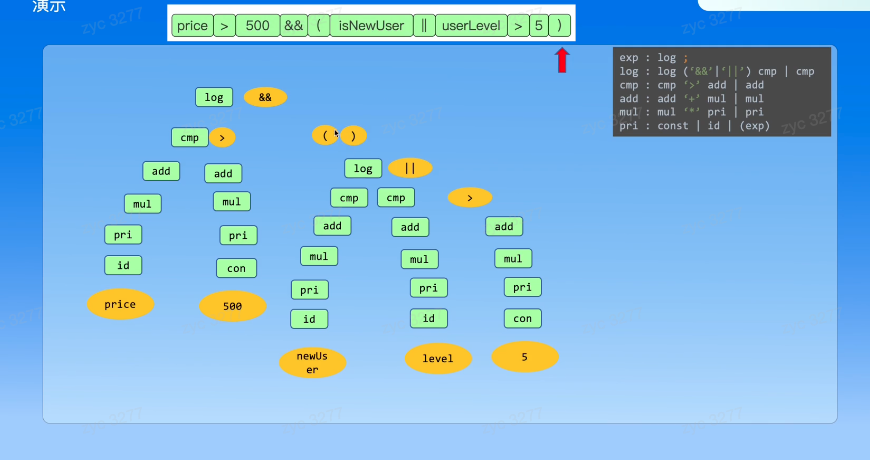
最后得到一个递归语法树
类型检查
类型检查:验证执行的结果是否为合适的数据类型。在抽象语法树中,通常会验证某节点的子节
点的数据类型是否合法
参数注入:在规则执行过程中,使用输入的参数值来计算语法树中的标识符节点值的过程
Postman测试
下面是可掉用的接口
通过postman给Body里面增加exp字段来掉用post请求,结果10+20+30>10+20返回为true
小结
规则引擎可以通过预先设定语法规则,减少业务代码的耦合度。当有新的需求时可以通过修改规则引擎来快速解决业务。
