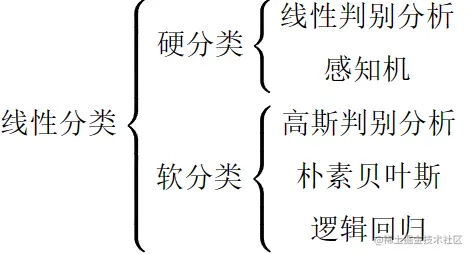
一、从线性回归到线性分类
- 线性回归的特性

线性回归 f(w,b)=wTx+b 具备线性、全局性和数据末加工的特性。
线性包括三个方面,其中:
- 属性线性指的是 f(w,b) 关于 x 是线性的;
- 全局线性指的是 wTx+b 只是一个线性组合,然后直接就输出得到 f(w,b) ;
- 系数线性指的是 f(w,b) 关于 wT 是线性的。
全局性指的是线性回归是在整个特征空间上学习,并没有将特征空间进行划分然后在每个划分上学习。
数据未加工指的是线性回归直接在给定数据上进行学习没有对数据进行其他的加工。
其他的学习算法跟线性回归比较起来打破了其某些特性,在上面的树状图中也举出了一些例子。
- 从线性回归到线性分类
线性回归经过一个激活函数然后根据一个阈值来获得分类的结果,如此就成为线性分类,也可以理解为将wTx+b降维到一维而获得分类结果。
激活函数y=f(wTx+b),y∈{{0,1}, 硬分类 [0,1], 软分类 函数f叫做激活函数(activationfunction)函数f−1叫做链接函数(linkfunction)f:wTx+b↦{0,1}/[0,1]f−1:{0,1}/[0,1]↦wTx+b
- 硬分类和软分类
二、感知机
两分类-硬分类-感知机算法
- 概述
假设有一可以被线性分类的样本集 {(xi,yi)}i=1N ,其中 xi∈Rp,yi{−1,+1} 。感知机算法(Perceptron Learning Algorithm)使用随机梯度下降法 (SGD) 来在特征空间 Rp 寻找一个超平面 wTx+b=0 来将数据 划分为正、负两类,其中 w∈Rp ,是超平面的法向量。
2. 学习策略
感知机的思想是错误驱动。其模型是 f(x)=sign(wTx+b),f(x) 输出该样本点的类别,定义集合M为误分类点的集合。
补充:wTx也可以表示wTx+b,因为我们可以看做W = [W b] X = [X 1]^T
- 可以确定对于误分类的数据 (xi,yi) 来说,满足以下关系:
=∣wTxi+b∣−yi(wTxi+b)>0
损失函数的一个自然选择是误分类点的个数,即 L(w)=∑i=1NI{−yi(wTxi+b)>0} ,但是这样的损失函数虽然直观,但是是非连续函数,所以不可导,不易优化。因此采用另一种损失函数,即误分类点到超平面的总距离。
在 Rp 空间中任一点 x0 到超平面的距离为:
∥w∥∣∣wTx0+b∣∣(可以参考初中知识,平面中点到直线的距离:d=A2+B2∣Ax+By+C∣)
因此所有误分类点到超平面 wTx+b=0 的总距离为:
xi∈M∑∥w∥∣∣wTx0+b∣∣=−∥w∥1xi∈M∑yi(wTxi+b)
不考虑 ∥w∥1 ,就得到感知机的损失函数:
L(w,b)=−xi∈M∑yi(wTxi+b)
- 学习算法
计算损失函数的梯度:
∂w∂L(w,b)=−xi∈M∑yixi∂b∂L(w,b)=−xi∈M∑yi
感知机的学习算法使用随机梯度下降法 (SGD),这里选取 η(0<η≤1) 作为学习率,其学习的步骤如下:
① 选取初值 w0,b0 ;
② 在训练集中选取数据 (xi,yi) ;
③ 如果 yi(wTxi+b)≤0 ,则更新参数:
w←w+ηyixib←b+ηyi
④ 转至②,直到训练集中没有误分类点。
截止这里我们都是假设数据是线性可分的,如果线性不可分,可以用口袋算法 (pocket algorithm),这里不做过多介绍。
三、线性判别分析
两分类-硬分类-线性判别分析 LDA
- 概述
线性判别分析可用于处理二分类问题,其过程是寻找一个最佳的投影方向,使得样本点在该方向上的投影符合类内小、类间大的思想,具体指的是类内的方差之和小,类间的均值之差大。
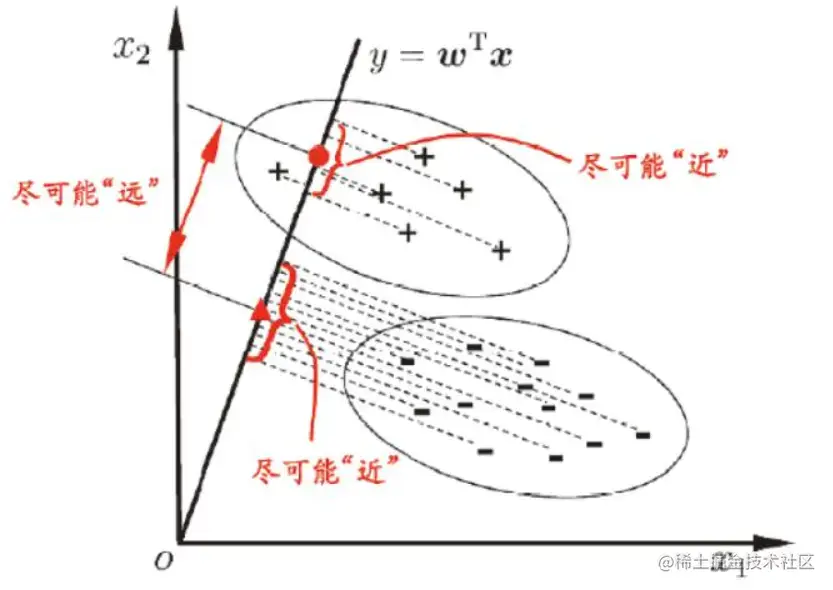
假设有以下数据:
X=(x1,x1,⋯,xN)T=⎝⎛x1Tx2T⋮xNT⎠⎞N×pY=⎝⎛y1y2⋮yN⎠⎞N×1{(xi,yi)}i=1N,xi∈Rp,yi∈{C1+1C2−1}xC1={xi∣yi=+1},xC2={xi∣yi=−1}∣xC1∣=N1,∣xC2∣=N2,N1+N2=N
- 线性判别分析的损失函数
投影轴的方向向量为 w ,将样本点往该轴上投影以后的值 zi 为 wTxi ,均值和方差按照如下方法计算:
均值 zˉ=N1∑i=1Nzi=N1∑i=1NwTxi
方差 Sz=N1∑i=1N(wTxi−z2)(wTxi−z2)T
接下来计算每一类的均值和方差:
C1:zˉ1=N11i=1∑N1wTxiS1=N11i=1∑N1(wTxi−zˉ1)(wTxi−zˉ1)TC2:zˉ2=N21i=1∑N2wTxiS2=N21i=1∑N2(wTxi−zˉ2)(wTxi−zˉ2)T
类间:(zˉ1−zˉ2)2
类内:S1+S2
定义损失函数:
J(w)=S1+S2(zˉ1−zˉ2)2分子=(zˉ1−zˉ2)2=(N11i=1∑N1wTxi−N21i=1∑N2wTxi)2=[wT(N11i=1∑N1xi−N21i=1∑N2xi)]2=[wT(xˉC1−xˉC2)]2=wT(xˉC1−xˉC2)(xˉC1−xˉC2)Tw−−−−−−−−−−−−−−−−−−−−S1=N11i=1∑N1(wTxi−zˉ1)(wTxi−zˉ1)T=N11i=1∑N1(wTxi−N11i=1∑N1wTxi)(wTxi−N11i=1∑N1wTxi)T=N11i=1∑N1wT(xi−xˉC1)(xi−xˉC2)Tw=wT[N11i=1∑N1(xi−xˉC1)(xi−xˉC2)T]w=wTSC1w分母=S1+S2=wTSC1w+wTSC2w=wT(SC1+SC2)w∴J(w)=wT(SC1+SC2)wwT(xˉC1−xˉC2)(xˉC1−xˉC2)Tw
极大化 J(w) 就可以使得类内的方差之和小,类间的均值之差大。
- 线性判别分析的求解
令 {Sb=(xˉC1−xˉC2)(xˉC1−xˉC2)TSw=SC1+SC2 则 J(w)=wTSwwwTSbw=wTSbw(wTSww)−1∂w∂J(w)=2Sbw(wTSww)−1+wTSbw(−1)(wTSww)−22Sbw=2[Sbw(wTSww)−1+wTSbw(−1)(wTSww)−2Sbw]=0(wTSbw,wTSww∈R)⇒Sbw(wTSww)−wTSbwSww=0⇒wTSbwSww=Sbw(wTSww)⇒Sww=wTSbwwTSwwSbw⇒w=wTSbwwTSwwSw−1Sbw
(要注意对于 w 我们只关注它的方向, 不关心它的大小。)
⇒w∝Sw−1Sbw⇒w∝Sw−1(xC12−xC22)1⩽S1xC12−xC22)Tw⇒w∝Sw−1(xC12−xC22)⇒w∝(SC1+SC2)−1(xC12−xC22)
进一步如果 Sw−1 是各向同性的对角矩阵的话, w∝xC12−xC22 。
四、逻辑回归
两分类-软分类-概率判别模型-Logistic 回归
- 概述
逻辑回归是一种二分类算法,通过 sigmoid 激活函数将线性组合 wTx 压缩到 0 和 1 之间来代表属于某一个分类的概率。
假设有如下数据:
{(xi,yi)}i=1N,xi∈Rp,yi∈{0,1}
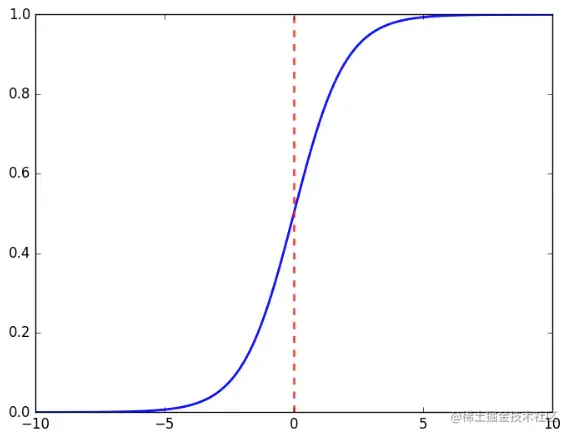
- sigmoid 激活函数
σ(z)=1+e−z1
其图像为:
- 逻辑回归的模型
逻辑回归预测 y=1 的概率,然后根据极大似然估计法来求解。
p1=P(y=1∣x)=σ(wTx)=1+e−wTx1=φ(x;w)p0=P(y=0∣x)=1−P(y=1∣x)=1+e−wTxe−wTx=1−φ(x;w)}p(y∣x)=p1yp01−y
- 逻辑回归的求解
w^=wargmaxloglikelihood P(Y∣X)=wargmaxlogi=1∏NP(yi∣xi)=wargmaxi=1∑NlogP(yi∣xi)=wargmaxi=1∑N(yilogp1+(1−yi)logp0)=wargmax−cross entropy i=1∑N(yilogφ(xi;w)+(1−yi)log(1−φ(xi;w))
因此这里的极大似然估计就等价于极小化交叉熵损失函数。
求导的过程较为简单,就不做展示了。
五、高斯判别分析
两分类-软分类-概率生成模型-高斯判别分析 GDA
- 概述
假设有如下数据:
{(xi,yi)}i=1N,xi∈Rp,yi∈{0,1}
- 高斯判别分析的模型
在高斯判别分析中样本数据的类别 y 在给定的情况下服从伯努利分布,另外不同类别中的样本数据分别服从多元高斯分布,因此有以下模型:
y∼ Bernoulli (ϕ)⇔ϕy,y=1(1−ϕ)1−y,y=0}P(y)=ϕy(1−ϕ)1−yx∣y=1∼N(μ1,Σ)x∣y=0∼N(μ2,Σ)}P(x∣y)=N(μ1,Σ)yN(μ2,Σ)1−y
这里假设两个高斯分布具有同样的方差。
3. 高斯判别模型的求解
- 损失函数
高斯判别模型的损失函数为其 log 似然,要估计的参数 θ 为 (μ1,μ2,Σ,ϕ) :
L(θ)=logi=1∏NP(xi,yi)=i=1∑NlogP(xi,yi)=i=1∑NlogP(xi∣yi)P(yi)=i=1∑N[logP(xi∣yi)+logP(yi)]=i=1∑N[logN(μ1,Σ)yiN(μ2,Σ)1−yi+logϕyiϕ1−yi]=i=1∑N[①logN(μ1,Σ)yi+②logN(μ2,Σ)1−yi+③logϕyiϕ1−yi]
然后使用极大似然估计法来求解:
θ^=θargmaxL(θ)
定义标签为1的样本个数为N1,标签为0的样本个数为N2,则有N1+N2=N。
ϕ只存在于③式中,因此求解ϕ只需要看③式即可:
③=i=1∑N[yilogϕ+(1−yi)log(1−ϕ)]∂ϕ∂③=i=1∑N[yiϕ1−(1−yi)1−ϕ1]=0⇒i=1∑N[yi(1−ϕ)−(1−yi)ϕ]=0⇒i=1∑N(yi−ϕ)=0⇒i=1∑Nyi−Nϕ=0ϕ^=N1i=1∑Nyi=NN1
- 求解μ1、μ2
ϕ只存在于①式中,因此求解μ1只需要看①式即可:
①=i=1∑Nyilog(2π)p/2∣Σ∣1/21exp{−21(xi−μ1)TΣ−1(xi−μ1)}μ1=μ1argmax①=μ1argmaxi=1∑Nyi[log(2π)p/2∣Σ∣1/21−21(xi−μ1)TΣ−1(xi−μ1)]=μ1argmaxi=1∑Nyi[−21(xi−μ1)TΣ−1(xi−μ1)]=μ1argmaxΔΔ=i=1∑Nyi[−21(xi−μ1)TΣ−1(xi−μ1)]=−21i=1∑Nyi(xiTΣ−1−μ1TΣ−1)(xi−μ1)=−21i=1∑Nyi(xiTΣ−1xi−2μ1TΣ−1xi+μ1TΣ−1μ1)∂μ1∂Δ=−21i=1∑Nyi(−2Σ−1xi+2Σ−1μ1)=0⇒i=1∑Nyi(Σ−1μ1−Σ−1xi)=0⇒i=1∑Nyi(μ1−xi)=0⇒i=1∑Nyiμ1=i=1∑Nyixiμ1^=∑i=1Nyi∑i=1Nyixi=N1∑i=1Nyixi同理μ2^=N2∑i=1Nyixi
以下是求解过程中用到的一些预备知识:
∂A∂tr(AB)=BT∂A∂∣A∣=∣A∣A−1tr(AB)=tr(BA)tr(ABC)=tr(CAB)=tr(BCA)
两类数据按照以下两个集合来表示:
C1={xi∣yi=1,i=1,2,⋯,N}C2={xi∣yi=0,i=1,2,⋯,N}∣C1∣=N1,∣C2∣=N2,N1+N2=N
然后进行求解:
Σ^=Σargmax(①+②)①+②=xi∈C1∑logN(μ1,Σ)+xi∈C2∑logN(μ2,Σ)
然后求解上式中的通项:
∑i=1NlogN(μ,Σ)=∑i=1Nlog(2π)p/2∣Σ∣1/21exp{−21(xi−μ)TΣ−1(xi−μ)}=∑i=1N[log(2π)p/21+log∣Σ∣−21−21(xi−μ)TΣ−1(xi−μ)]=∑i=1N[C−21log∣Σ∣−21(xi−μ)TΣ−1(xi−μ)]=C−21Nlog∣Σ∣−21∑i=1N(xi−μ)TΣ−1(xi−μ)=C−21Nlog∣Σ∣−21∑i=1Ntr[(xi−μ)TΣ−1(xi−μ)](实数的迹等于其本身)=C−21Nlog∣Σ∣−21∑i=1Ntr[(xi−μ)(xi−μ)TΣ−1]=C−21Nlog∣Σ∣−21tr[∑i=1N(xi−μ)(xi−μ)TΣ−1]=C−21tr(NSΣ−1)(S=N1∑i=1N(xi−μ)(xi−μ)T,为协方差矩阵)=−21Nlog∣Σ∣−21Ntr(SΣ−1)+C则①+②=−21N1log∣Σ∣−21N1tr(S1Σ−1)−21N2log∣Σ∣−21N2tr(S2Σ−1)+C=−21Nlog∣Σ∣−21N1tr(S1Σ−1)−21N2tr(S2Σ−1)+C=−21[Nlog∣Σ∣+N1tr(S1Σ−1)+N2tr(S2Σ−1)]+C
然后对Σ进行求导:
∂Σ∂①+②=−21[N∣Σ∣1∣Σ∣Σ−1+N1∂Σ∂tr(Σ−1S1)+N2∂Σ∂tr(Σ−1S2)]=−21[NΣ−1+N1S1T(−1)Σ−2+N2S2T(−1)Σ−2]=−21(NΣ−1−N1S1TΣ−2−N2S2TΣ−2)=0NΣ−N1S1−N2S2=0Σ^=NN1S1+N2S2
六、朴素贝叶斯
两分类-软分类-概率生成模型-朴素贝叶斯
- 概述
假设有如下数据:
{(xi,yi)}i=1N,xi∈Rp,yi∈{0,1}
- 朴素贝叶斯的模型
朴素贝叶斯分类器可以用来做多分类,其基本思想是条件独立性假设,即假设数据的每个特征之间是相互独立的,其形式化表达为
对于x∣y来说xi∣y与xj∣y是相互独立的(i=j),即P(x∣y)=i=1∏pP(xi∣y)
朴素贝叶斯分类器是最简单的概率图模型(有向图):
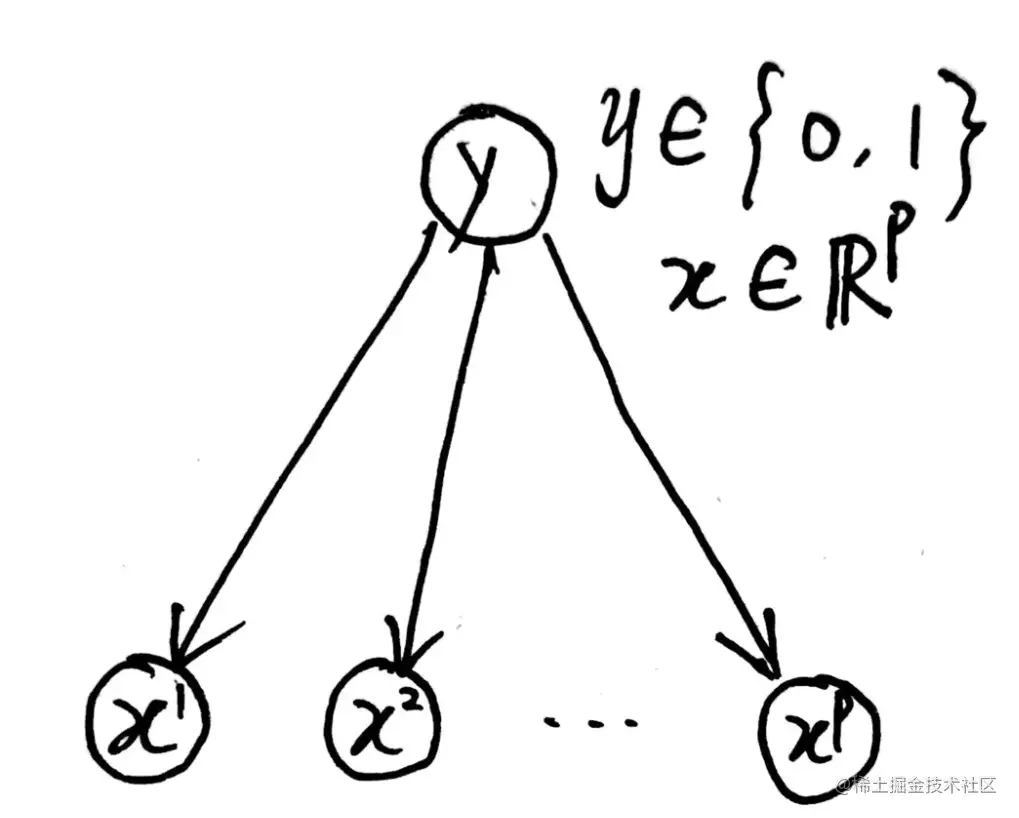
给定x,判断y的类别可以通过以下方法,即将x归为类别的概率中最大的一类:
y^=yargmaxP(y∣x)=yargmaxP(x)P(x,y)=yargmaxP(x)P(y)P(x∣y)=yargmaxP(y)P(x∣y)
P(y)是先验概率,如果有两类则服从伯努利分布(Bernoulli distribution),如果有多类则服从类别分布(Categorical distribution)。P(x∣y)则符合条件独立性假设P(x∣y)=∏i=1pP(xi∣y),其中对于xi,如果xi是离散的,则可以认为其服从类别分布(Categorical distribution),如果xi是连续的,则可以认为其服从高斯分布(Gaussian distribution)。
至于其求解过程则可以根据具体情况使用极大似然估计法即可。对于朴素贝叶斯方法重要的是理解其条件独立性假设,这个假设也是其被称为“朴素(Naive)”的原因。
七、小结
分类任务分为两类,对于需要直接输出类别的任务,感知机算法中我们在线性模型的基础上加入符号函数作为激活函数,那么就能得到这个类别,但是符号函数不光滑,于是我们采用错误驱动的方式,引入 xi∈Dwrong∑−yiwTxi 作为损失函数,然后最小化这个误差,采用批量随机梯度下降的方法来获取最佳的参数值。而在线性判别分析中,我们将线性模型看作是数据点在某一个方向的投影,采用类内小,类间大的思路来定义损失函数,其中类内小定义为两类数据的方差之和,类间大定义为两类数据中心点的间距,对损失函数求导得到参数的方向,这个方向就是 Sw−1(xc1−xc2),其中 Sw 为原数据集两类的方差之和。
另一种任务是输出分类的概率,对于概率模型,我们有两种方案,第一种是判别模型,也就是直接对类别的条件概率建模,将线性模型套入 Logistic 函数中,我们就得到了 Logistic 回归模型,这里的概率解释是两类的联合概率比值的对数是线性的,我们定义的损失函数是交叉熵(等价于 MLE),对这个函数求导得到 N1i=1∑N(yi−p1)xi,同样利用批量随机梯度(上升)的方法进行优化。第二种是生成模型,生成模型引入了类别的先验,在高斯判别分析中,我们对数据集的数据分布作出了假设,其中类先验是二项分布,而每一类的似然是高斯分布,对这个联合分布的对数似然进行最大化就得到了参数, N1i=1∑Nyixi,N0i=1∑N(1−yi)xi,NN1S1+N2S2,NN1。在朴素贝叶斯中,我们进一步对属性的各个维度之间的依赖关系作出假设,条件独立性假设大大减少了数据量的需求。


