0 内容提要
本文覆盖概率与计算第二版Chap1-4,9的内容。
这5章内容比较基础,涉及:
- 理论
- 概率的基本概念
- 交、并、贝叶斯、全概率计算公式
- 期望、方差、中位数等数字特征
- Jensen不等式、Markov不等式、Chebyshev不等式
- 切诺夫界和Hoeffding界
- 高斯分布、中心极限定理
- 模型
- Naive Bayesian Classifier
- 分支过程
- 赠券收集问题
- 秘书问题
- 算法
- EM算法
- 均匀分布产生正态分布
- 多项式判等
- 矩阵判等
- 最小割算法
- 中位数算法
1 理论
这一节的思路是首先建立概率的定义。其实我们探讨随机现象,概率几乎是唯一的原生数值量(连接了物理世界和逻辑世界),其他的期望、方差都是基于概率分布算出来的衍生量。建立概率分布量后,就可以直接按照定义产生一系列概率公式(1.2)。之后我们进一步探索一个概率分布的度量方法,基本方法是一些数字特征(1.3),高级方法是一些尾部不等式(1.4)和更为高级的不等式(1.5)
1.1 基本定义
随机试验:可重复、结果可限定、结果具有随机性
概率的定义,不学习测度理论的话认识深度不会超过本科。两个基本的定义:概率空间和概率,简单摘要不再赘述。
- 概率空间:基本事件集、可行事件集(基本事件子集的集合,对交并补运算封闭)、概率 从可行事件集到实数的映射函数
- 概率:非负、归一(全集概率为1)、和可加 (互斥事件并的概率为各事件概率之和)
频率悖论:假设根据统计数据,30~45岁的人出现癌症的频率是15%,40~70岁的人出现癌症的频率是40%,一个43岁的人,出现癌症的概率如何推断?如果进一步确定了性别、出生地、遗传病史,如何确定统计的样本?越精确,样本越少,越不能说明问题。越不精确,样本虽多,但是统计特性和个体相差越大。
1.2 概率计算公式
和本科学的没啥区别,直接整理一下放在这里了
- 交事件概率
- 一般事件:P(AB)=P(A∣B)P(B)
- 独立事件:P(AB)=P(A)P(B)
- 独立的定义:P(A∣B)=P(A)
- n个事件独立:任意事件子集的概率等于概率乘积(很强、超过两两独立)
- 并事件概率(容斥原理)
- 2个事件:P(A+B)=P(A)+P(B)−P(AB)
- n个事件:P(∑i=1nAi)=∑iP(Ai)−∑i<jP(AiAj)+∑i<j<kP(AiAjAk)−...+(−1)k+1∑i1<i2<...<ikP(Ai1...Aik)+...+(−1)n+1P(Ai1...Ain)
这里其实有两个小不等式,如果截断只保留前k项,k是奇数,截断的最后一项是正数,则右侧是个上界。k是偶数则右侧是个下界。
- 基础不等式:P(∩iAi)≤∑iP(Ai)
- 全概率公式:P(B)=∑i=1nP(B∣Ai)P(Ai),其中Ai是一组事件,形成一个覆盖(不重不漏地划分整个概率空间)。
- 贝叶斯公式:P(A∣B)=P(B)P(AB)=P(B)P(B∣A)P(A)
正确的看待后验:一个很高的P(B∣Aj) 并不意味着有Aj就有很大的把握确定B。有两个原因:一是因为另一个事件Ak可能也有很大的概率导致B,二是因为Aj可能实在太小了,导致可信度差。如下图:Aj是橘色,B是绿色,Ak是红色

1.3 概率分布的数字特征
期望
- 定义:E[X]=∑xxP(x)
- 性质:线性性(没有限制条件)
- 定理:X,Y独立,E[XY]=E[X]E[Y],E[X∣Y]=E[X]
- 不等式:∣E[h(x)g(x)]∣≤E[h2(x)g2(x)]
- 引理:对非负离散随机变量X, E[X]=∑i=1∞Pr[X≥i]
简单证一下:∑i=1∞Pr[X≥i]=∑i=1∞∑j=i∞Pr[X=j]=∑j=1∞∑i=1jPr[X=j]=∑j=1∞jPr[X=j]=E[X]
这里第二个等号的重排原理见下图,因为都是正数,这样重排合理。第三个等号是因为对i求和就是完全一样的j个数加起来。

条件期望
- 定义:E(X∣Y)=∑xxP(x∣Y)。这个东西本质是一个关于Y的函数,而Y是一个随机变量,所以条件期望也是随机变量。
- 性质:E[E[X∣Y]]=E[X],E[Z∣X]=E[E[Z∣Y,X]∣X]
方差
- 定义:Var[X]=E[(X−E[X])2]
- 性质:Var[X]=E[X2]−(E[X])2
矩
- 原点矩:E[Xr]
- 中心矩:E[(X−E[X])r]
协方差
- 定义:Cov[X,Y]=E[(X−E[X])(Y−E[X])]
- 性质;Var[X+Y]=Var[X]+Var[Y]+2Cov[X,Y]
- 推论:X,Y独立,Cov[X,Y]=0
协方差和相关系数
令mij=E[XiYj],cij=E[(X−EX)i(Y−EY)j]
相关系数:ρ=c20c02c11
为何∣ρ∣≤1?
构造法:Q(λ)=E[(λ(X−EX)(Y−EY))2]=λ2c20+2λc11+c02
非负数的期望肯定非负,所以Q(λ)≥0
由Δ≤0→∣ρ∣≤1
中位数
- 定义:一般中位数是从统计那里学来的,对于随机变量,其中位数是满足Pr[X<m]=Pr[X>m]的m
- 性质:中位数是使得E[∣X−m∣]的值最小的m。
关系
- 期望与方差的关系:
E[X]是使E[(X−c)2]最小的c,展开求导即可证明。并且最小值恰好是方差。
- 中位数、期望和方差的关系:如果X有σ=Var(X)<∞,那么∣μ−m∣≤σ
证明:∣μ−m∣=∣E[X]−m∣=∣E[X−m]∣≤E[∣X−m∣]≤E[∣X−μ∣]≤E[(X−μ)2]=σ
第3个不等号是Jensen不等式,第4个是中位数的性质,第5个是Jensen不等式
两个随机变量的关系
- 不相关:Cov[X,Y]=0
- 独立:E[XY]=E[X]E[Y]
- 正交:E[XY]=0
1.4 高级度量方法
高级度量方法主要有3个不等式:Jensen、Markov、Chebyshev
Jensen不等式
这个其实严格来说不算是概率的不等式,只是函数凸性的利用。
下凸函数f,有E[f(X)]≥f(E[X])
严格的证明是在μ处taylor展开,不严格的证法是画图,但不严格的其实只能证明有限项的求和正确定。
Markov不等式
非常经典,对于非负变量X,Pr[X≥a]≤aE[X]。
证明,构造指示器变量I,在X>a时取1,否则取0,则有I≤aX,然后对I求期望即可。
Chebyshev不等式
对任意X, Pr[∣X−E[X]∣≥a]≤a2Var[X]
证明 Pr[∣X−E[X]∣≥a]=Pr[(X−E[X])2≥a2],对后者的平方作为随机变量使用Markov不等式即可。
- 技巧:一般这个a会取一个和方差或期望相关的数值,这样不等式右侧会更优雅。
1.5 更高级的界
矩函数
- 定义:对随机变量X,定义矩函数MX(t)=E[etX]
- 性质1:E[Xn]=MX(n)(0)
- 性质2:矩函数唯一定义分布
- 性质3:两个独立随机变量 MX+Y(t)=MX(t)MY(t)
切诺夫界
Pr[X≥a]=Pr[etX≥eta]≤mint≥0etaE[etX]
最后一步用的是Markov界。注意这个里面虽然取min可以让bound更紧,但是t有时候也为了形式简洁不那么紧。
通常包含的两个技巧:
- 高频的使用ex≥x+1这个不等式。
- 右侧化简到只剩一个e,taylor展开。
霍夫丁界
对一系列相互独立的随机变量X1,..,Xn,若E[Xi]=μ, Pr[a≤Xi≤b]=1,则有Pr[∣n1∑iXi−μ∣≥ϵ]≤2e−2nϵ2/(b−a)2
用不太严格的话来说,度量了一系列独立的同界同均值变量的均值误差界
lemma 对于E[X]=0的有界[a, b]随机变量,对一切λ>0, 有E[eλX]≤eλ2(b−a)2/8.
证明思路利用指数函数的下凸性质
1 构造eλx<b−ab−xeλa+b−ax−aeλb
2 所以 E[eλx]≤b−abeλa−b−aaeλb
3 重写上面这个式子右侧,令ϕ(t)=−θt+ln(1−θ+θet),其中θ=b−a−a>0,那么右侧就变成了eϕ(λ(b−a))
4 对ϕ函数taylor展开可以发现他小于8t21,带入可证。
利用lemma,可以证明霍夫丁界
1 构造Zi=Xi−E[Xi],Z=n1∑iZi
2 Pr[Z≥ϵ]=Pr[eλZ≥eλϵ]≤e−λϵ∏E[eλZi/n]≤e−λϵ+λ2(b−a)2/8n
3 取λ=(b−a)24nϵ,可证一半,对于小于的部分也差不多。
更一般的。如果这n个随机变量的界彼此不一样,那么
Pr[∣n1∑Xi−μ∣≥ϵ]≤2e−2ϵ2/∑(bi−ai)2
1.6 正态分布
标准正态
N(0,1)=2π1e−21x2
- 性质1:线性变换也是正态,如果Z∼N(0,1),而X=σZ+μ,那么X∼N(μ,σ2),N(μ,σ2)=2πσ21e−21(σx−μ)2
- 性质2:独立正态的和也是正态,且N(μ1,σ12)+N(μ2,σ22)=N(μ1+μ2,σ12+σ22)
- 母函数:MX(t)=eμt+2t2σ2
高维正态
Y=(Y1,...,Yn)=(2π)n∣Σ∣1e−21(Y−μ)TΣ−1(Y−μ)
其中,μ是均值向量,Σ是协方差矩阵。上述密度存在的前提是Σ满秩,不然逆不存在。
中心极限定理
- n个独立同分布的随机变量,均值和方差分别为μ,σ2,那么limn→∞Pr(a≤σ/nXˉ−μ≤b)依分布收敛于Φ(b)−Φ(a)
- n个独立变量,期望方差分别是μi,σi2,如果随机变量绝对值有界且limn→∞∑inσi2=∞,则Pr[a≤∑σi2∑(Xi−μi)≤b]依分布收敛于Φ(b)−Φ(a)
- 配合Chebyshev不等式可以导出弱大数定律:
Xi是iid且均值方差分别为μ,σ,
μn=1/n∑i=1nXi,P(∣μn−μ∣≥δ)≤nδ2σ2
2 模型
这一节介绍基本理论较为通用的应用,他们一般不针对具体问题,或者所研究的问题具有通用性。
Naive Bayesian Classifier
这个其实很简单,把名字里的三个单词倒过来看就行了。
- 首先是Classifier,说明解决的是分类预测问题,即对于给定一个样本(具有k个属性)(o1,o2,...,ok),返回最有可能的分类。
- 第二个词是Bayesian,说明这个预测问题是基于贝叶斯的方法来的,那就是要求后验概率,即Pr[C=cj∣o1,o2,...,ok]的概率。
利用贝叶斯公式,这个概率可以转化成P(o1,o2,...,on)P(o1,o2,...,ok∣cj)P(cj)。其中分母比较难求,不过一般就是用来归一化的系数所以不需要求,更重要的是分子如何求。
- 这时就用到最后一个单词Naive了,naive的意思是假设样本所有的属性是彼此独立的,那么似然度就可以写成P(o1,o2,...,ok∣cj)=∏i=1kP(oi∣cj).
现在,如果有了训练数据,只要求出似然度中的k×c个概率P(oi∣cj)和c个先验概率P(cj)即可。这些概率很容易算,直接根据样本数据中满足条件的数据数量的频率推算即可。比如P(cj)就是训练数据中类别为cj的占比。而P(oi∣cj)就是样本中第i个属性取值为oi且类别为cj的样本占类别为cj样本的比例。
分支过程
这个对应原书2.3节,这一块他举的例子是程序的调用过程,其实用文字说不太直观,这里画一个图来表示这个过程。
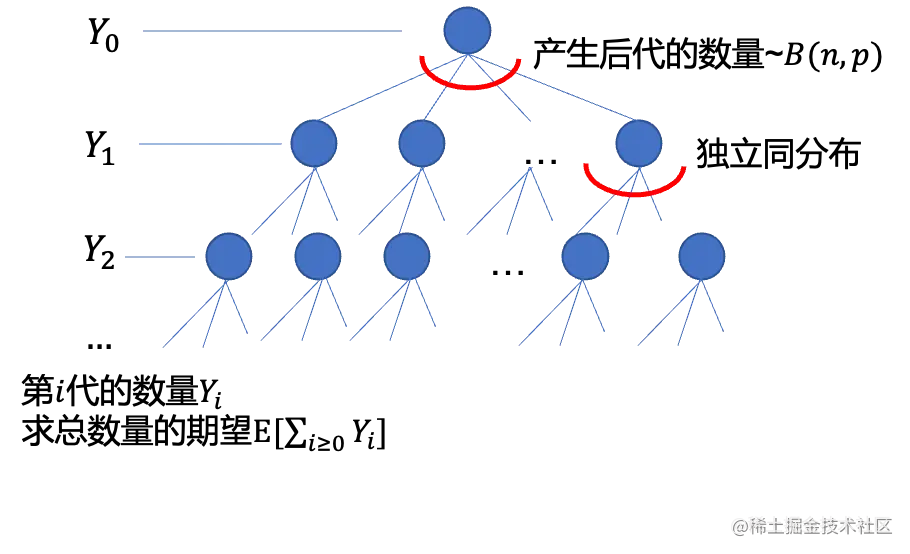 这里用到的思想是逐代递推,假设我们已经知道Yi−1=yi−1,尝试求Yi的期望:E[Yi∣Yi−1]=npyi−1。
这里用到的思想是逐代递推,假设我们已经知道Yi−1=yi−1,尝试求Yi的期望:E[Yi∣Yi−1]=npyi−1。
这个其实很直观,因为上一层有yi−1个结点,每一个分叉的期望数量是np且相互独立,那这一层总的期望数量就是npyi−1
因此E[Yi]=E[Yi∣Yi−1]=npE[Yi−1],一直递推到Y0,而Y0=1为定值,所以E[Yi]=(np)i。其实对0也成立。
所以总数E[∑i≥0Yi]=1−np1−(np)i
赠券收集问题
- 问题描述:现在有n种券,需要通过开盒子收集。每个盒子等可能地包含一张券。问平均需要开多少盒子才能集全所有券(即每一种至少一张)?
这里用到的思想和分支很像,可以称之为状态递推。
我们关心的是赠券收集的情况,而这个过程又是分步骤的,所以可以把最终目标拆分成一系列状态步骤。本问题中,定义状态Sk为恰好收集了k种券(即有n-k种券的数量为0)。状态转移图如下
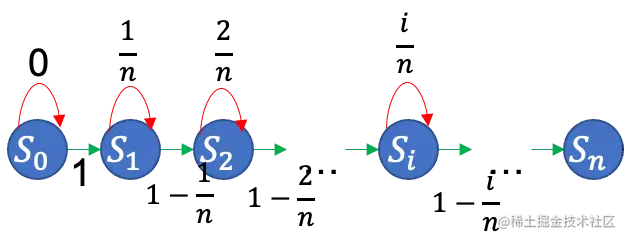
红色箭头表示在当前状态开了一个盒子,结果奖券种类没有增加,停留在当前状态。绿色表示种类增加了,进入下一状态。这个概率取决于当前手上有的种类数。有的种类越多,那开盒能得到新种类券的概率就越低。现在需要求从S0转移到Sn平均需要多少次转移。
定义Xk表示在Sk状态开盒的数量,那么保持在Sk的概率是nk,进入到下一状态的概率是1−nk。所以很容易列出
E[Xk]=∑i=0∞iPr[Xk=i]=∑i=0∞i(nk)i−1(1−nk)=n−kn。这里最后一步用到了级数求和公式。
而最终要求的其实是X0到Xn−1(因为最后一个状态不需要开盒子)。
所以E[∑k=0n−1Xk]=∑k=0n−1n−kn=n∑k=0n−1n−k1=n∑i=1ni1=Θ(nlogn)。
这个结论很有意思,作为一种营销策略其实很失败。因为如果我们希望通过增加券的种类来激励消费者购买更多产品,增加奖券的方法能带来的销量增长只比线性好了一点点。所以肯定不会等可能的投放奖券。
首中问题的随机变量服从几何分布,如果命中概率为p,那么期望和方差分别为p1和p21−p。直接按照定义求解需要求复杂的级数求和。比较tricky的方法是利用分布的无记忆性递推。E[X]=p+(1−p)(1+E[X])
秘书问题(习题2.32)
例题:招聘问题。有一串n个数字均匀分布,你每次看一个,看完决定要还是不要,不要之后就再也不能反悔,如何要到最大数字?
策略:先看前k个,从第k+1个开始,遇到比k大的就停止,关键是这个k如何选择。
Pr[这种策略选出最大的概率]=Pr[前k个里没有出现最大and最大值之前的数字里的最大值要出现在前k个里]=j=k∑N−1Pr[最大值位置x=j+1│前j个最大值在前k个里]=j=k∑N−1Pr[前j个最大值在前k个里│x=j+1]Pr[x=j+1]=N1j=k∑N−1k/j=k/N(1/k+⋯1/(N−1))≈k/Nln(N/k)
为了让概率最大,关于k求导,得到k=N/e。
集合的均衡
给定义个n×m的矩阵A,每个位置的值为0或1,求一个m维向量b,b的每一个元素只能取1或-1,使得minmaxici,其中c=Ab
一个很简单的方法是:b的每一个位置,等概率随机选择1或-1。这个方式看似完全忽略了A的内容,但他竟然是最优的,即,minmaxici=O(4mlnn),超越这个上限的概率n的增大而趋于0。
Pr[∣∣Ab∣∣∞≥4mlnn]≤2e−4nlnn/2k≤n22
这里其实分类讨论,对矩阵的某一行,如果1的数量(设为k)小于4mlnn,那显然成立。如果超过k,那么这k个对应的向量的位置是+1和-1的二项分布,利用切诺夫界可以求出上界。
3 算法
EM算法
EM的主要应用于样本来源于多个未知分布,但是不知道每个样本属于哪个分布的情况。此时需要估计的参数既有分布本身的,也有属于哪个分布的概率。然后我们就利用迭代的思想。一开始随便取,然后计算似然函数,然后对属于何分布的参数求偏导计算,之后更新之(E-step)。更新了该参数,再利用MLE计算其他分布里参数的估计(M-step)。
特点是每次迭代似然度都在提升,至少收敛到局部最优。
用均匀分布产生正态分布
这是一个很实用的问题。核心是对CDF的理解:0-1上的概率转移到了其他CDF上那么分为点是多少
1 最简单的近似
利用中心极限定理,一系列0-1上的均匀分布的求和然后标准化即可。一个良好的近似取12个就足够了即X=(∑i12Ui)−6。
它具有均值0,方差1,但区间是在[−6,6]。
2 极坐标转化
考虑两个独立的标准正态的联合分布:F(x′,y′)=∫−∞y′∫−∞x′2π1e−(x2+y2)/2dxdy
通过极坐标变换,可以分解成F(r′,θ′)=2πθ′(1−e−(r′)2/2)
可以看到,r和θ是分属两项的,说明极坐标变换完之后还是独立的。而前面整体恰好是一个[0,2π]均匀分布的CDF,而后面那一项如果硬看作(0,1)上的均匀分布的话,另它=1−V。这样经过一系列代换,同时注意到1−V和V都是0-1上的均匀分布可以直接替换,可以得到两个独立的标准正态X=−2lnVcos(2πU),Y=−2lnVsin(2πU)
3 拒绝采样避免三角函数计算
为了避免三角函数,还可以进一步改进,把U和V线性映射到(-1,1)区间,然后S=U2+V2。如果S>1,说明在单位圆外部重新采样。在内部可以利用U/S来表示cos, V/S来表示sin。然后S也是0-1上的均匀分布,所以lnS可以替换lnV
X=US−2lnS,Y=VS−2lnS,S是U和V的平方和。
算法部分研究的问题更具体,因此我更侧重于这些算法背后利用的思想,而具体技术细节和理论推导不在赘述。
-
随机探针思想
多项式判等和矩阵判等两个问题透露出一种共同的思想。对于多项式,探针是函数的自变量,而对于矩阵,探针是一个0-1向量。因为探针是随机抽取的,所以需要分析其失效的情况以及采样到失效情况的概率。
-
局部处理思想
中位数算法中,相较于对整体排序,该算法选取局部Θ(n)规模的元素进行排序。从而控制排序的元素规模来保证时间复杂度。局部处理的代价是可能miss包含中位数的范围。体现了trade-off的特点。
-
事后分析思想
最小割算法中,缩边本质是赌收缩的两个点在割的一侧,至于赌的对不对,其实是靠事后分析,即在已知最小割规模的情况下分析持续选对边的概率。
分析技巧
- 延迟决策原理:多个随机变量时,把一部分看作随机,其他看作固定。
- 单边错误重复
习题 Notes
Chap1
1.9
- 题目:抛一枚均匀硬币n次,对于k>0,计算连续出现log2(n)+k次正面向上的概率上界。
- Answer:
设事件Ei表示从第i次开始出现连续log2(n)+k次正面向上,则P(Ei)=(21)log2(n)+k=n2k1
所以P(E1+E2+...+En−(log2(n)+k+1))≤∑P(Ei)=n2kn−log2(n)+k+1≤2k1
1.15
- 题目:抛10个六面体骰子,点数之和能被6整除的概率
- Answer:pij表示i个骰子点数和mod 6余j的概率。那么p100=61p90+61p91+61p92+61p93+61p94+61p95=61(∑jp9j)=61.
1.18
- 题目:一个离散函数定义域是0~n-1的整数,值域是0~m-1的整数,有1/5的值被篡改了,但是函数有一个性质F((x+y)%n)=(F(x)+F(y))%m,问你如何设计一个算法,对任意的z,至少以21的概率给出正确结果。
- Answer:这个乍一看不好理解,如果我直接输出F(z),似乎错误的概率只有51,为啥这样不行呢?这里其实使用了对手模型,即,我们假设给你输入z的人就是篡改你函数表的人,那如果你设计这种算法,他可以直接输入他篡改的那些项,你的错误概率就是100%了。
为了应对这种攻击性的输入,算法必须具有内生的随机性来避免这个问题。这个可以联想随机快速排序,他通过内生的随机性,使得不论如何构造测试用例,期望复杂度始终是O(nlogn)的。
因此,这里考虑利用这个函数的性质,把输入转移到其他的函数值上。随机sample一个x,然后令y=(z-x) % n。这样把(F(x)+F(y))%m作为结果输出。这样,不论你输入的z是不是被篡改的,我总是会转化成另外两个输入的结果。而这个结果错误的概率为Pr[x被篡改+y被篡改]≤Pr[x]+Pr[y]=52。
正确概率超过1/.
1.23
- 题目:利用最小割随机化算法分析,至多有n(n−1)/2个不同的最小割。
- Answer:书中证明了一个最小割被返回的概率是n(n−1)2,那么k个的概率求和小于1,就可以了。
Chap 2
2.7/2.24 无记忆性
-
2.7: X和Y是独立的几何随机变量,概率分别为p和q。求X=Y的概率。
-
answer 这里利用了无记忆性 Pr[X=Y]=Pr[X1=Y1=1]Pr[X′=Y′]+Pr[X1=Y1=0]Pr[X′=Y′]=pqPr[X=Y]+(1−p)(1−q)Pr[X=Y],得到关于Pr的方程,求解即可。后面几个差不多。
-
2.24 掷骰子连续两个6的期望次数
-
answer 设X是第一次出现6的次数,Y是连续两个6的次数。那么在X出现之后,有1/6的概率Y=X+1,而其余5/6的概率Y=X+Y',Y'表示6的状态被清零了,需要重新投掷,那么在此出现两个6的概率按照无记忆性其实分布和Y是一样的。
因此E[Y]=61E[X+1]+65E[X+Y],显然E[X]=6,则E[Y]=42
2.20/2.21 指示器变量思想
2.2
- question 从26个小写字母随机采样100000次,出现proof的期望次数是多少。
- answer 各路答案的思路,是(1000000 - len(proof)) * (1 / 26)^len(proof),这个数值约等于0.085,我实际用python算了一下大概也确实是。这个答案基本是正确的。不过我没想清楚是怎么回事。感觉是一个近似解
Remakrs
- 概率、期望的求解:利用无记忆性列出方程
- 多步骤问题使用状态转移图
- 指示器变量思维


