1.wave文件的四个部分
1.0 四个部分
| RIFF Header | ID = ‘RIFF’ | RIFF_TYPE=‘WAVE’ |
|---|
| Format Chunk | ID = 'fmt ’ | |
| Fact Chunk 可选 | ID = ‘fact’ | |
| Data Chunk | ID =‘data’ | |
1.1 RIFF_WAVE_Chunk
| 名称 | 长度 | 内容 |
|---|
| ID | 4 Bytes | ‘RIFF’ |
| Size | 4 Bytes | 整个文件大小-8 |
| Type | 4 Bytes | ‘WAVE’ |
1.2 Format Chunk
| 名称 | 长度 | 内容 | |
|---|
| ID | 4 Bytes | 'fmt ’ | |
| Size | 4 Bytes | 整个文件大小-818/16 (有无附加信息) | 本结构大小(除ID,Size) |
| FormatTag | 2 Bytes | 通常0x0001 | 编码方式 |
| Channels | 2 Bytes | 1–单声道;2–双声道立体声 | 声道数目 |
| SamplesPerSec | 4 Bytes | | 采样频率 |
| AvgBytesPerSec | 4 Bytes | | 每秒所需字节数 |
| BlockAlign | 2 Bytes | 数据块对齐单位 | |
| BitsPerSample | 2 Bytes | | 每个采样需要的位bit数 |
| BlockAlign | 2 Bytes | (可选,通过Size来判断有无) | 附加信息 |
1.3 Fact_Chunk
| ID | 4 Bytes | ‘fact’ |
|---|
| Size | 4 Bytes | 数值为4 |
| data | 4 Bytes | |
1.4 Data_Chunk
| ID | 4 Bytes | ‘data’ |
|---|
| Size | 4 Bytes | 数据区大小 |
| data | 4 Bytes | 数据区,真正存储数据的地方 |
二.
2.1 读取wave文件的前45个字节,并按顺序打印出来。并作分析
cong@msi:/work/ffmpeg/test/alsa/testalsa/1wave$ ls ../../../resource/test.wav -l
-rw-rw-r-- 1 cong cong 39623500 Aug 17 16:35 ../../../resource/test.wav
这个文件的总长度是39623500=0x25C9B4C
RIFF_HEADER:
0=0x52 1=0x49 2=0x46 3=0x46 --> 'RIFF'
4=0x44 5=0x9b 6=0x5c 7=0x02 --> size=0x025c9b44=文件的总长度-8(即这个size代表去除RIFF与本身之外的文件长度)
8=0x57 9=0x41 10=0x56 11=0x45 --> 'WAVE'
Format Chunk:
12=0x66 13=0x6d 14=0x74 15=0x20 --> 'fmt'
16=0x10 17=0x00 18=0x00 19=0x00 --> len=16=Format部分的长度是16个byte(不包括自身)
20=0x01 21=0x00 --> FormatTag=0x0001(1代表WAV_FMT_PCM)
22=0x02 23=0x00 --> channels=0x0002
24=0x44 25=0xac 26=0x00 27=0x00 --> SamplePerSec=0x0000ac44=44100
28=0x10 29=0xb1 30=0x02 31=0x00 --> AvgBytePerSec=0x0002b110=176400
32=0x04 33=0x00 --> BlockAlign=0x0004=4
34=0x10 35=0x00 --> BitsPerSample=0x0010=16
Fact Chunk: none
Data Chunk:
36=0x64 37=0x61 38=0x74 39=0x61 -->'data'
40=0x20 41=0x9b 42=0x5c 43=0x02 --> size=0x025c9b20=剩余的数据长度=文件总长度-RIFF-Format-Data
44=0x00
45=0x00
46=0x00
47=0x00
48=0x00
49=0x00
50=0x00
51=0x00
52=0x00
53=0x00
54=0x00
55=0x00
56=0x00
57=0x00
58=0x00
59=0x00
2.2 关于wav与 DTS-in-WAV
下面是打印的一个DTS-in-WAV的前60个字节
RIFF_Header:
0=0x52 1=0x49 2=0x46 3=0x46
4=0x24 5=0xe0 6=0xd5 7=0x02
8=0x57 9=0x41 10=0x56 11=0x45
Format_Chunk:
12=0x66 13=0x6d 14=0x74 15=0x20
16=0x10 17=0x00 18=0x00 19=0x00
20=0x01 21=0x00
22=0x02 23=0x00
24=0x44 25=0xac 26=0x00 27=0x00
28=0x10 29=0xb1 30=0x02 31=0x00
32=0x04 33=0x00
34=0x10 35=0x00
Fact Chunk: none
Data Chunk:
36=0x64 37=0x61 38=0x74 39=0x61
40=0x00 41=0xe0 42=0xd5 43=0x02
44=0xff 45=0x1f 46=0x00 47=0xe8 48=0xf1 49=0x07
50=0xdf
51=0xfc
52=0x98
53=0xfc
54=0x01
55=0xec
56=0xe9
57=0xf4
58=0x09
59=0x00
DTS-coding有两种格式: raw bitsteam coding 与14bit words,而这两种格式进行coding时既可用big-endian也可用little-endian
所以为了区分就在每帧开头加上如下标志:
Every frame in DTS starts with 32-bit syncword which can be used to distinguish current bitstream encoding:
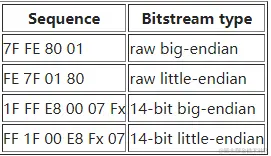
所以要区分wav与DTS-in-WAV,文件头(前44个字节)是一样的没法区分,只能判断数据部分是否是以上面的4组开始。
三.
3.1 代码
#include "utils.h"
#include <stdlib.h>
typedef struct {
u_int magic; /* 'RIFF' */
u_int length; /* filelen */
u_int type; /* 'WAVE' */
} WaveHeader;
typedef struct {
u_short format; /* see WAV_FMT_* */
u_short channels;
u_int sample_fq; /* frequence of sample */
u_int byte_p_sec;
u_short byte_p_spl; /* samplesize; 1 or 2 bytes */
u_short bit_p_spl; /* 8, 12 or 16 bit */
} WaveFmtBody;
typedef struct {
WaveFmtBody format;
u_short ext_size;
u_short bit_p_spl;
u_int channel_mask;
u_short guid_format; /* WAV_FMT_* */
u_char guid_tag[14]; /* WAV_GUID_TAG */
} WaveFmtExtensibleBody;
typedef struct {
u_int type; /* 'data' */
u_int length; /* samplecount */
} WaveChunkHeader;
#define COMPOSE_ID(a,b,c,d) ((a) | ((b)<<8) | ((c)<<16) | ((d)<<24))
#define WAV_RIFF COMPOSE_ID('R','I','F','F')
#define WAV_WAVE COMPOSE_ID('W','A','V','E')
#define WAV_FMT COMPOSE_ID('f','m','t',' ')
#define WAV_DATA COMPOSE_ID('d','a','t','a')
int check_wavfile(int fd)
{
int ret;
int i, len;
WaveHeader* header;
WaveFmtBody* fmt;
WaveChunkHeader* chunk_header;
unsigned char* pbuf = (unsigned char*)malloc(128);
if(NULL == pbuf)
{
dbmsg("pbuf malloc error");
return -1;
}
//1. 读取wave的Header部分并解析
len = sizeof(WaveHeader);
if( (ret=read(fd, pbuf, len)) != len)
{
dbmsg("read error");
return -1;
}
header = (WaveHeader*)pbuf;
if( (header->magic!=WAV_RIFF) || (header->type!=WAV_WAVE))
{
dbmsg("not a wav file");
return -1;
}
//2.读取wave的FormatChunk部分并解析
//2.FormatChunk又可分为header和body两部分
len = sizeof(WaveChunkHeader)+sizeof(WaveFmtBody);
if( (ret=read(fd, pbuf, len)) != len)
{
dbmsg("read error");
return -1;
}
chunk_header = (WaveChunkHeader*)pbuf;
if( chunk_header->type!=WAV_FMT)
{
dbmsg("fmt body error");
return -1;
}
fmt = (WaveFmtBody*)(pbuf+sizeof(WaveChunkHeader));
if(fmt->format != 0x0001) //WAV_FMT_PCM
{
dbmsg("format is not pcm");
return -1;
}
dbmsg("format=0x%x, channels=0x%x,sample_fq=%d,byte_p_sec=%d,byte_p_sample=%d,bit_p_sample=%d",
fmt->format, fmt->channels,fmt->sample_fq, fmt->byte_p_sec,
fmt->byte_p_spl, fmt->bit_p_spl);
//3.读取wave的DataChunk部分并解析
//3.DataChunk只包括header部分
len = sizeof(WaveChunkHeader);
if( (ret=read(fd, pbuf, len)) != len)
{
dbmsg("read error");
return -1;
}
chunk_header = (WaveChunkHeader*)pbuf;
if(chunk_header->type != WAV_DATA)
{
dbmsg("not data chunk");
return -1;
}
dbmsg("pcm_data_size=0x%x",chunk_header->length); //这个长度就是wav文件中的纯数据的长度.
free(pbuf);
pbuf = NULL;
return -1;
}
int main ( int argc, char *argv[] )
{
int fd;
if(argc < 2)
{
dbmsg("usage: ./waveinfo ");
return -1;
}
fd = open(argv[1], O_RDWR);
if(fd<0)
{
dbmsg("open error");
return -1;
}
check_wavfile(fd);
return EXIT_SUCCESS;
}
3.2 运行结果
cong@msi:/work/ffmpeg/test/alsa/testalsa/1wave$ make run
./wave /work/ffmpeg/test/resource//test.wav
wave.c:check_wavfile[86]: format=0x1, channels=0x2,sample_fq=44100,byte_p_sec=176400,byte_p_sample=4,bit_p_sample=16
wave.c:check_wavfile[100]: pcm_data_size=0x25c9b20


