本文章参考了Lilian Weng的《From GAN to WGAN》这篇文章,原文链接《From GAN to WGAN》,可以去看看
KL散度和JL散度
在机器学习中,常常用KL散度(Kullback-Leibler Divergence)和JL散度(Jensen-Shannon Divergence)来衡量两个分布的近似程度
KL散度
KL散度是用来,评价p与目标分布q之间的相似程度
DKL(p∣∣q)=x∈X∑p(x)logq(x)p(x)
通过这个公式,我们可以知道,KL散度越大,代表着q(x)表达p(x)的能力越差
当p(x)与q(x)完全相同时, DKL=0,且KL散度不具有对称性
JL散度
JS散度是对称的,取值在0到1。如果两个分布完全没有重叠,此时KL散度是完全没有意义的,也就意味着这一点梯度为0,这时就需要JS散度
DJS(p∣∣q)=21DKL(p∣∣2p+q)+21DKL(q∣∣2p+q)
JS散度更为平滑,GAN取得成功背后的一个原因是将传统最大似然估计中不对称的KL散度改为对称的JS散度。
Wasserstein距离
Wasserstein距离还有一个名字叫推土机距离,这是因为计算Wasserstein距离的过程跟推土填土的过程很像。
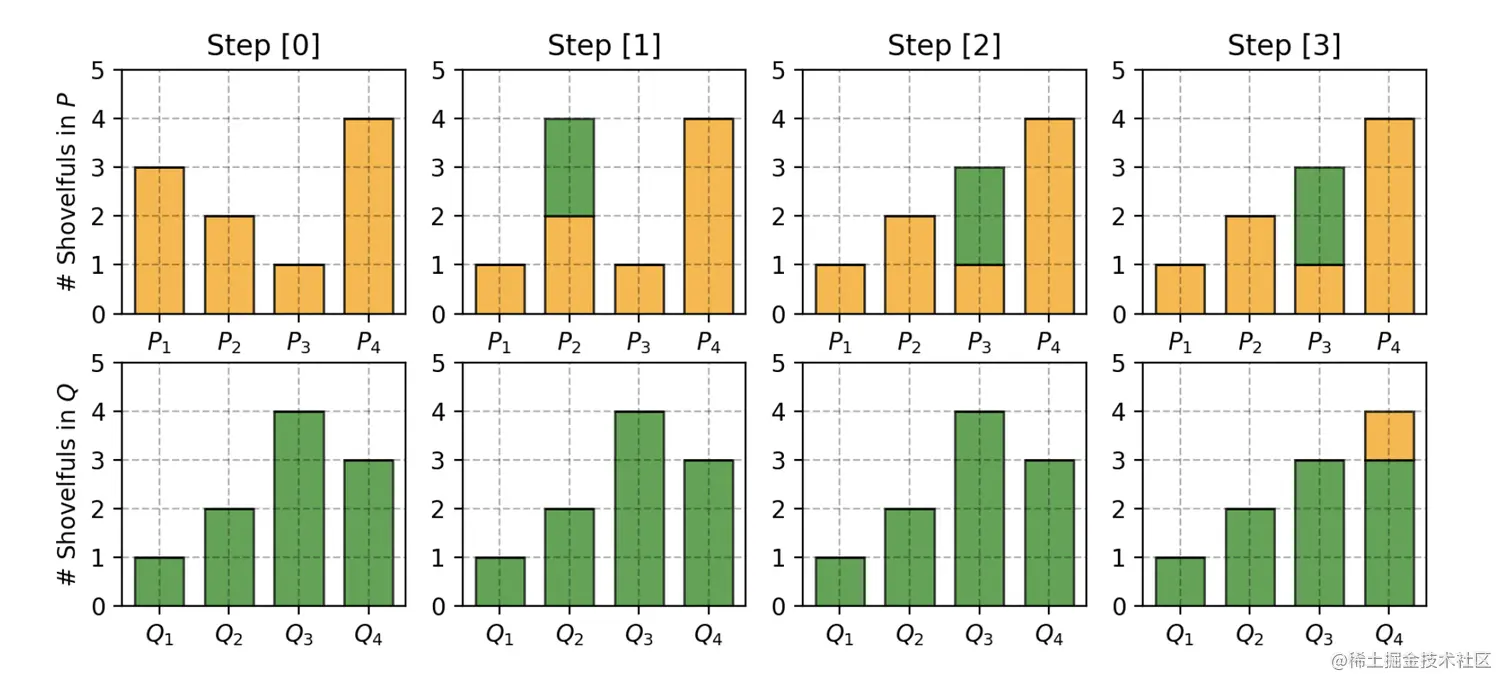
让我们来看一个很简单的例子,假设有两个分布P和Q,P和Q共有4堆泥土
P1=3,P2=2,P3=1,P4=1
Q1=1,Q2=2,Q3=4,Q4=3
两个分布相等的意思,就是P1和Q1相等,P2和Q2相等,依此类推。我们逐个观察。
- 为了让P1和Q1相等,P1要分2份土给P2,此时P2=4
- 为了让P2和Q2相等,P2要分2份土给P3,此时P3=3
- 为了让P3和Q3相等,Q3要分1份土给Q4,此时Q4=4
- P4和Q4相等
代价计算函数为δi+1=δi+Pi−Qi。在这个例子中
δ0δ1δ2δ3δ4=0=0+3−1=2=2+2−2=2=2+1−4=−1=−1+4−3=0
最终的Wasserstein距离W=∑|δi|=5
为什么Wasserstein距离比KL散度和JS散度更加优秀
即使两个分布在低维且分布之间没有重叠,Wasserstein距离仍然有意义且可以平滑的表示两者之间的距离。


