一、安装部署K8S准备
1.1 服务器准备
| 服务器 | IP地址 | 需要安装的服务/组件 |
|---|
| master(2C/4G,cpu核心数要求大于2) | 192.168.142.10 | docker、kubeadm、kubelet、kubectl、flannel |
| node01(2C/2G) | 192.168.142.20 | docker、kubeadm、kubelet、kubectl、flannel |
| node02(2C/2G) | 192.168.142.30 | docker、kubeadm、kubelet、kubectl、flannel |
| Harbor节点(hub.test.com) | 192.168.142.40 | docker、docker-compose、harbor-offline-v1.2.2 |
1.2 部署步骤
- 在所有节点上安装Docker和kubeadm
- 部署Kubernetes Master
- 部署容器网络插件
- 部署 Kubernetes Node,将节点加入Kubernetes集群中
- 部署 Dashboard Web 页面,可视化查看Kubernetes资源
- 部署 Harbor 私有仓库,存放镜像资源
二、环境准备
2.1 所有节点操作
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
hostnamectl set-hostname master01
hostnamectl set-hostname node01
hostnamectl set-hostname node02
vim /etc/hosts
192.168.142.10 master01
192.168.142.20 node01
192.168.142.30 node02
cat > /etc/sysctl.d/kubernetes.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
sysctl --system
2.2 所有节点安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://6ijb8ubo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
}
EOF
systemctl daemon-reload
systemctl restart docker.service
systemctl enable docker.service
docker info | grep "Cgroup Driver"
Cgroup Driver: systemd
2.3 所有节点安装kubeadm,kubelet和kubectl
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.20.15 kubeadm-1.20.15 kubectl-1.20.15
systemctl enable kubelet.service
三、部署K8S集群
3.1 初始化kubeadm
kubeadm config images list --kubernetes-version 1.20.15
mkdir /opt/k8s
cd /opt/k8s/
unzip v1.20.15.zip -d /opt/k8s
for i in $(ls *.tar); do docker load -i $i; done
scp -r /opt/k8s root@node01:/opt
scp -r /opt/k8s root@node02:/opt
cd /opt/k8s/
for i in $(ls *.tar); do docker load -i $i; done
kubeadm config print init-defaults > /opt/kubeadm-config.yaml
cd /opt/k8s
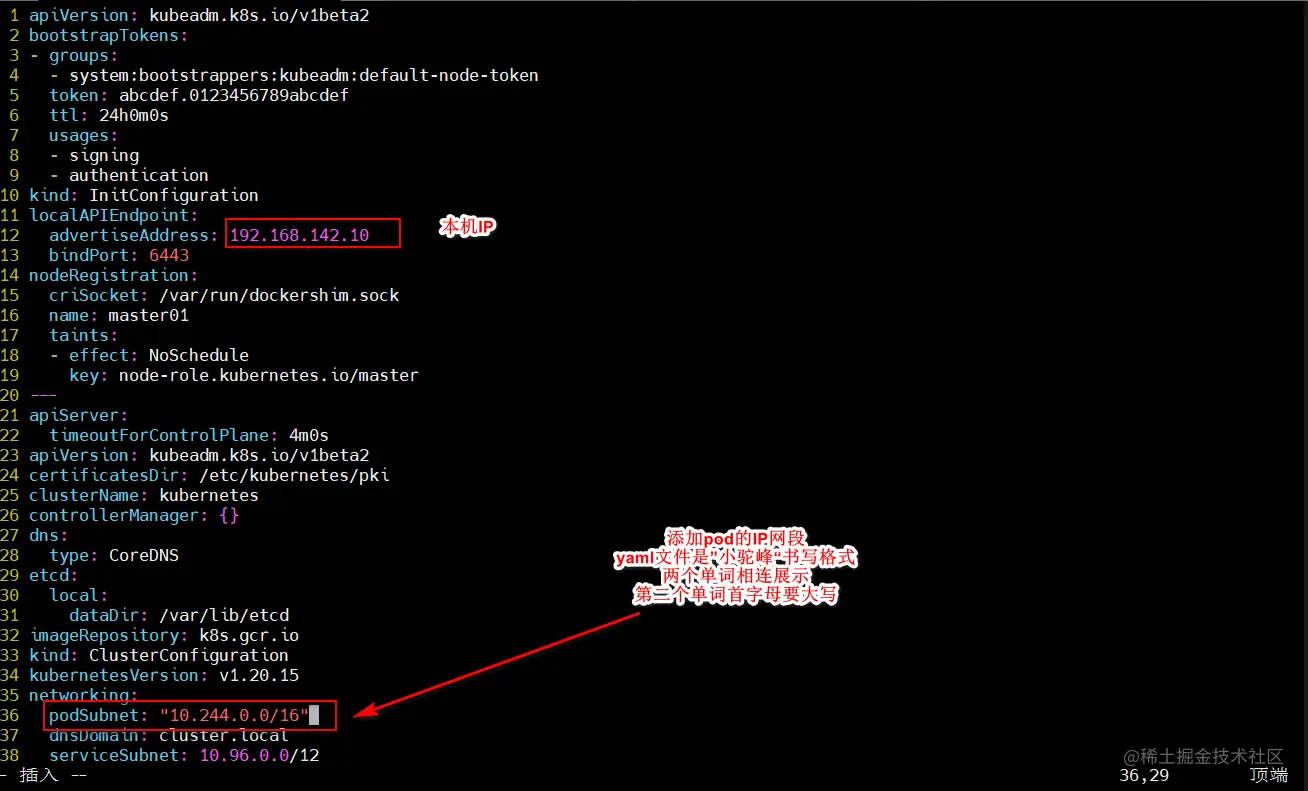
vim kubeadm-config.yaml
......
11 localAPIEndpoint:
12 advertiseAddress: 192.168.142.10
13 bindPort: 6443
......
34 kubernetesVersion: v1.20.15
35 networking:
36 dnsDomain: cluster.local
37 podSubnet: "10.244.0.0/16"
38 serviceSubnet: 10.96.0.0/16
39 scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
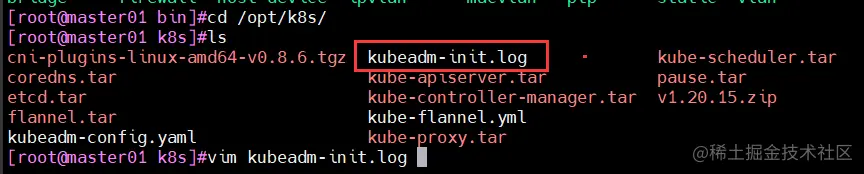
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log
less kubeadm-init.log
ls /etc/kubernetes/
ls /etc/kubernetes/pki
kubeadm init \
--apiserver-advertise-address=192.168.142.10 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.20.15 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--token-ttl=0
--------------------------------------------------------------------------------------------
初始化集群需使用kubeadm init命令,可以指定具体参数初始化,也可以指定配置文件初始化。
可选参数:
--apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址
--apiserver-bind-port:apiserver的监听端口,默认是6443
--cert-dir:通讯的ssl证书文件,默认/etc/kubernetes/pki
--control-plane-endpoint:控制台平面的共享终端,可以是负载均衡的ip地址或者dns域名,高可用集群时需要添加
--image-repository:拉取镜像的镜像仓库,默认是k8s.gcr.io
--kubernetes-version:指定kubernetes版本
--pod-network-cidr:pod资源的网段,需与pod网络插件的值设置一致。Flannel网络插件的默认为10.244.0.0/16,Calico插件的默认值为192.168.0.0/16;
--service-cidr:service资源的网段
--service-dns-domain:service全域名的后缀,默认是cluster.local
--token-ttl:默认token的有效期为24小时,如果不想过期,可以加上 --token-ttl=0 这个参数
---------------------------------------------------------------------------------------------
3.2 设定kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
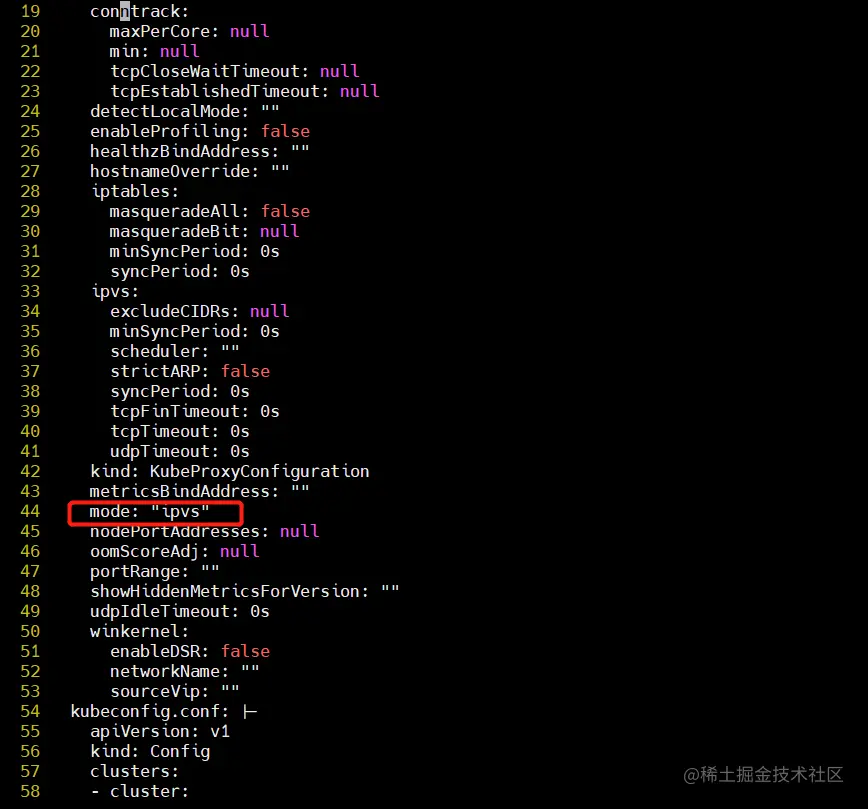
kubectl edit cm kube-proxy -n=kube-system
修改mode: ipvs
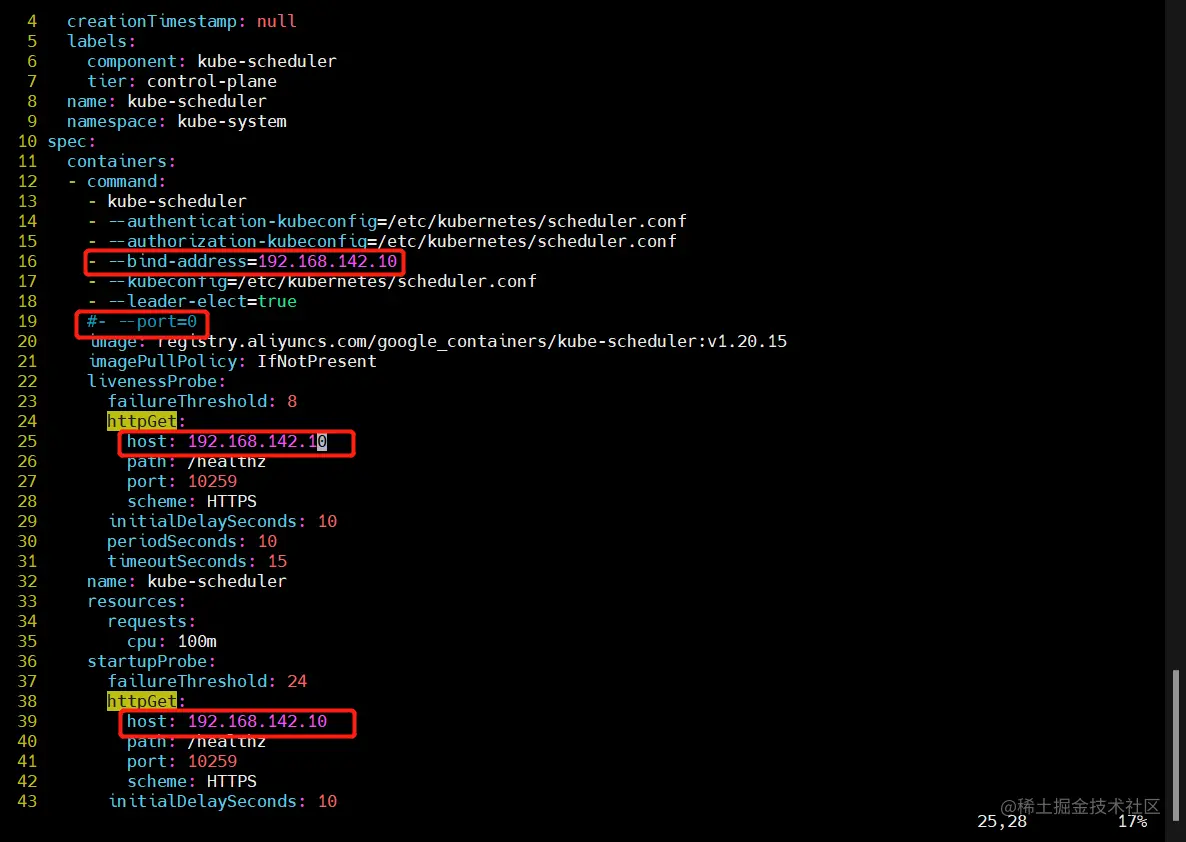
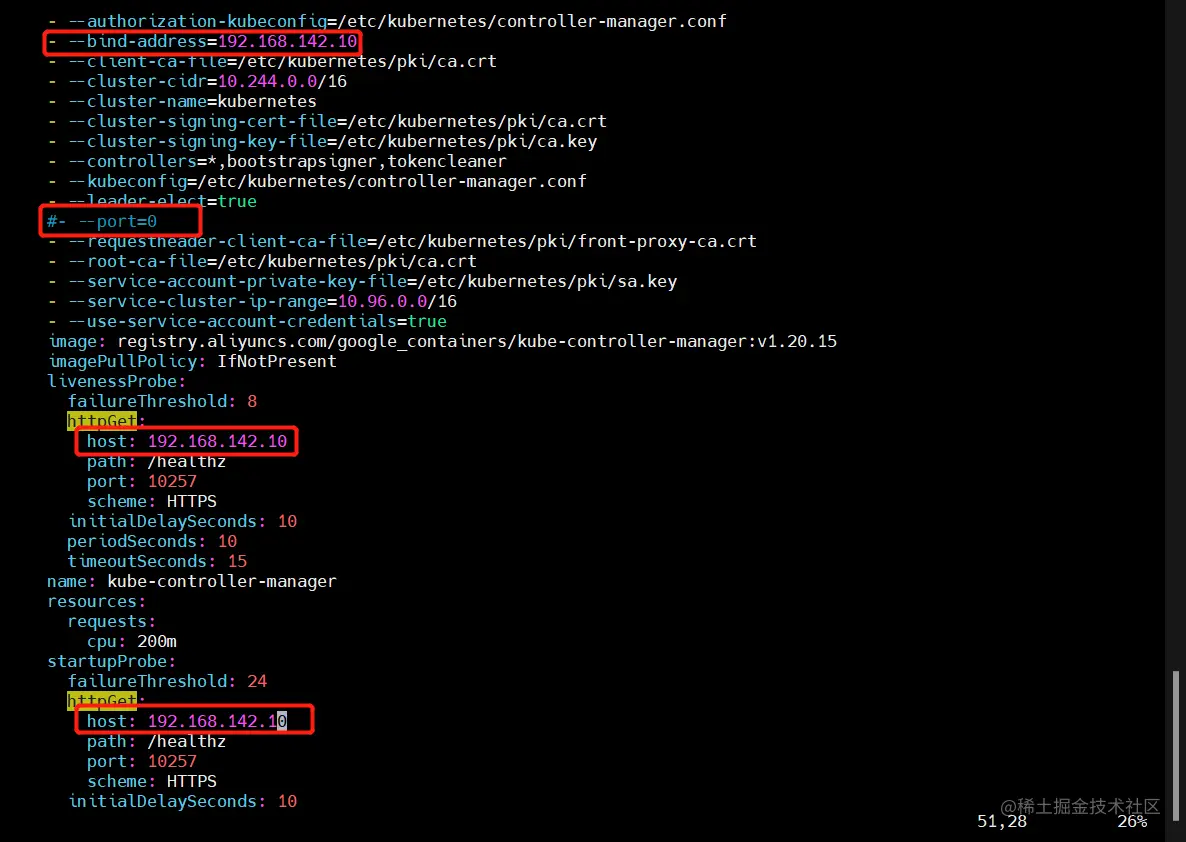
vim /etc/kubernetes/manifests/kube-scheduler.yaml
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
把--bind-address=127.0.0.1变成--bind-address=192.168.142.10
把httpGet:字段下的hosts由127.0.0.1变成192.168.142.10(有两处)
systemctl restart kubelet
3.3 所有节点部署网络插件flannel
cd /opt
docker load < flannel.tar
mv /opt/cni /opt/cni_bak
mkdir -p /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin

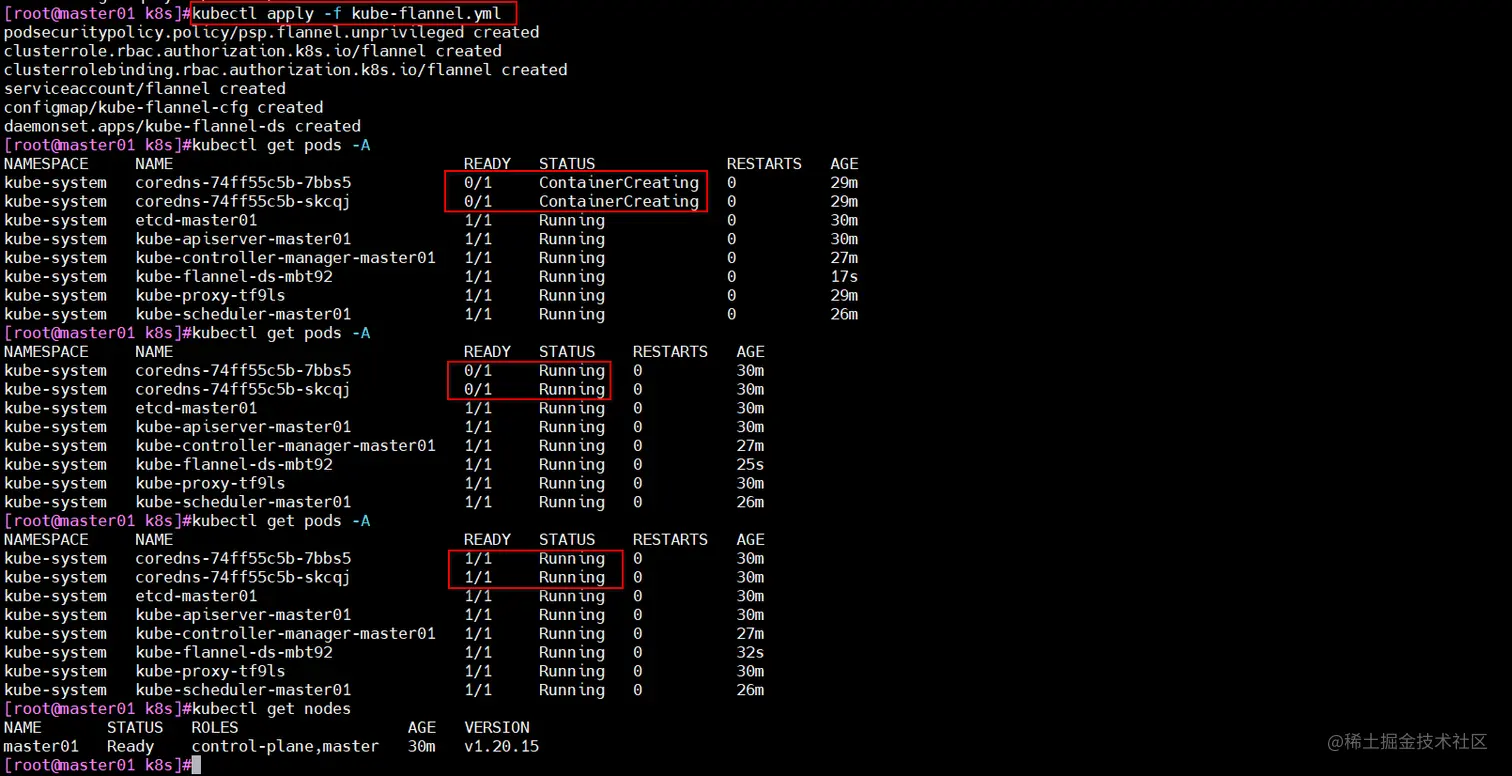
kubectl apply -f kube-flannel.yml
cd /opt/k8s/
vim kubeadm-init.log
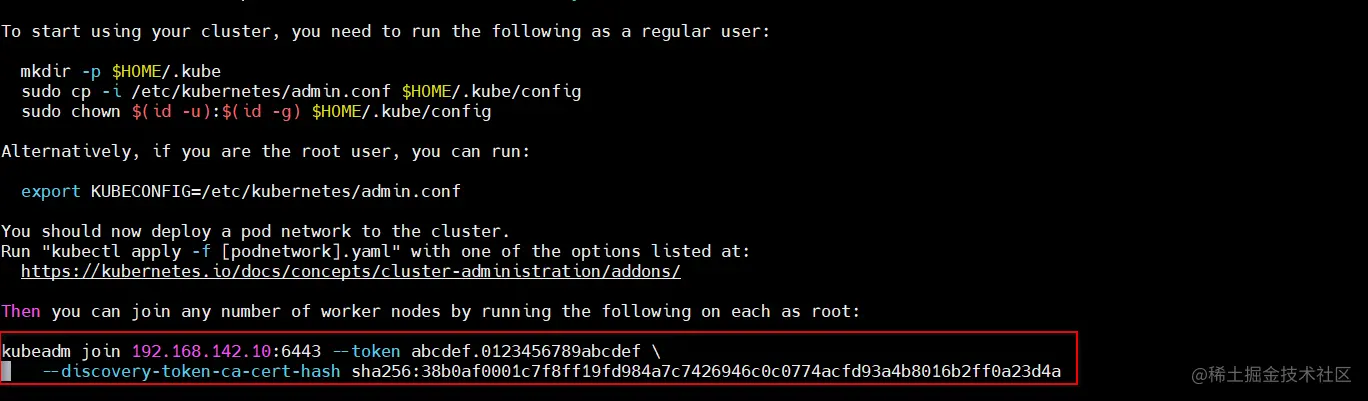
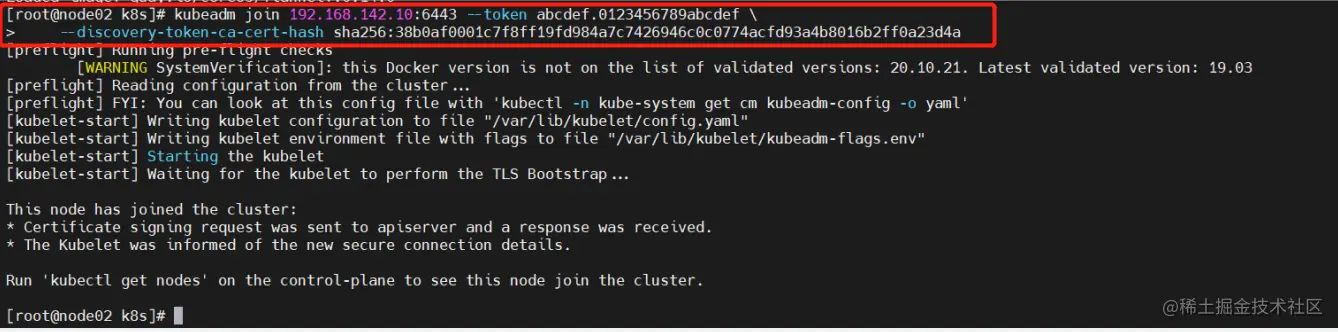
kubeadm join 192.168.142.10:6443 --token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:38b0af0001c7f8ff1gfd984a7c7426946c0c0774acfd93a4b8016b2ff0a23d4a
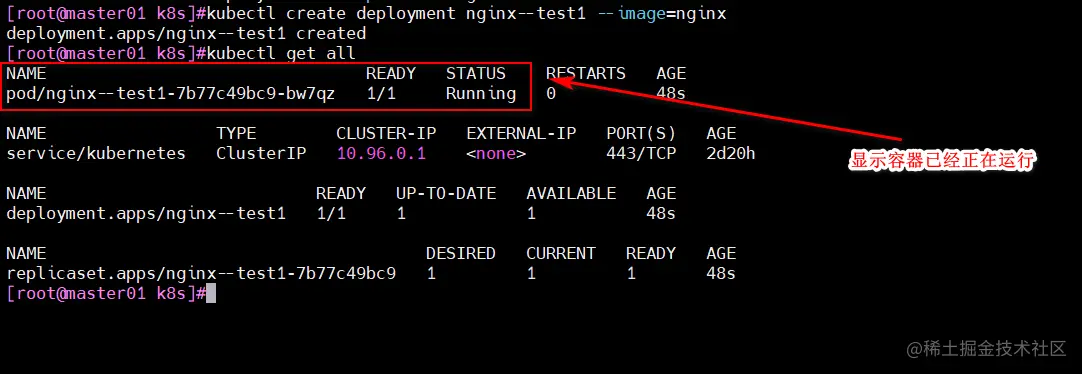
kubectl create deployment nginx--test1 --image=nginx
kubectl get all
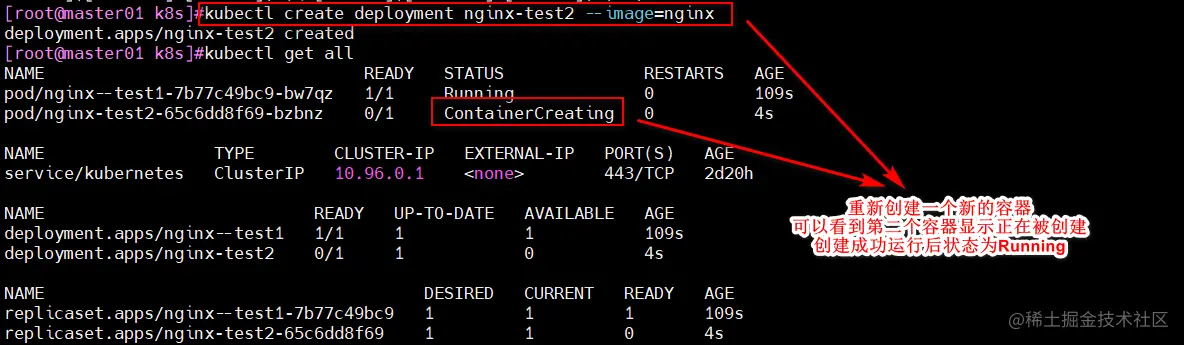
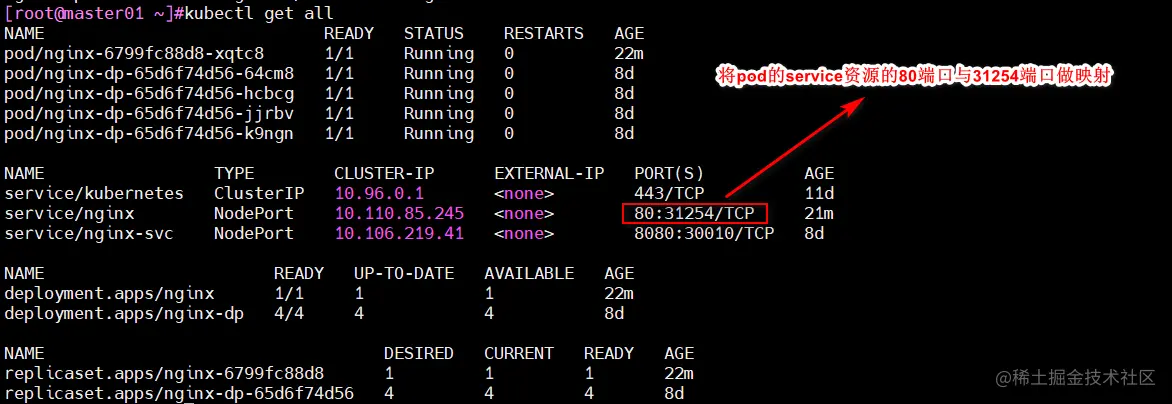
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get svc
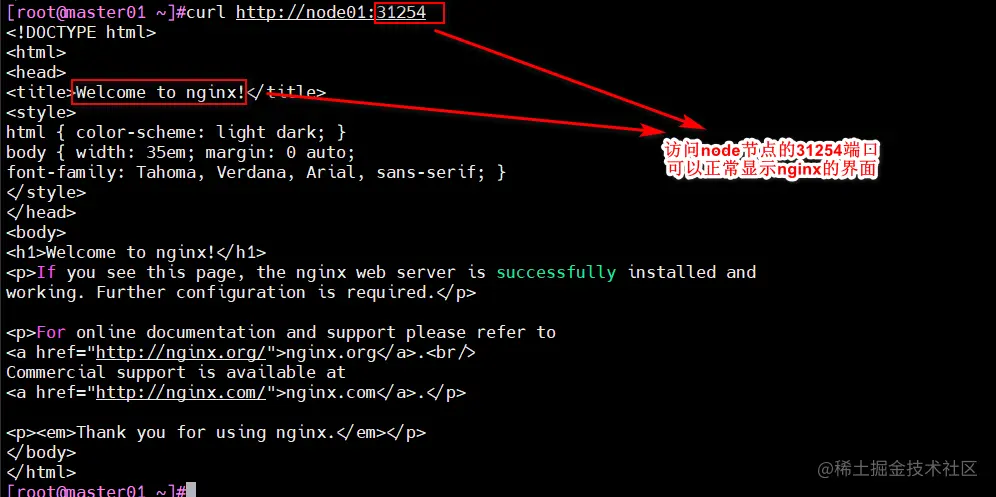
curl http://node01:31254
curl 10.110.85.245:80
四、部署 Dashboard
cd /opt/k8s
vim recommended.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30001
type: NodePort
selector:
k8s-app: kubernetes-dashboard
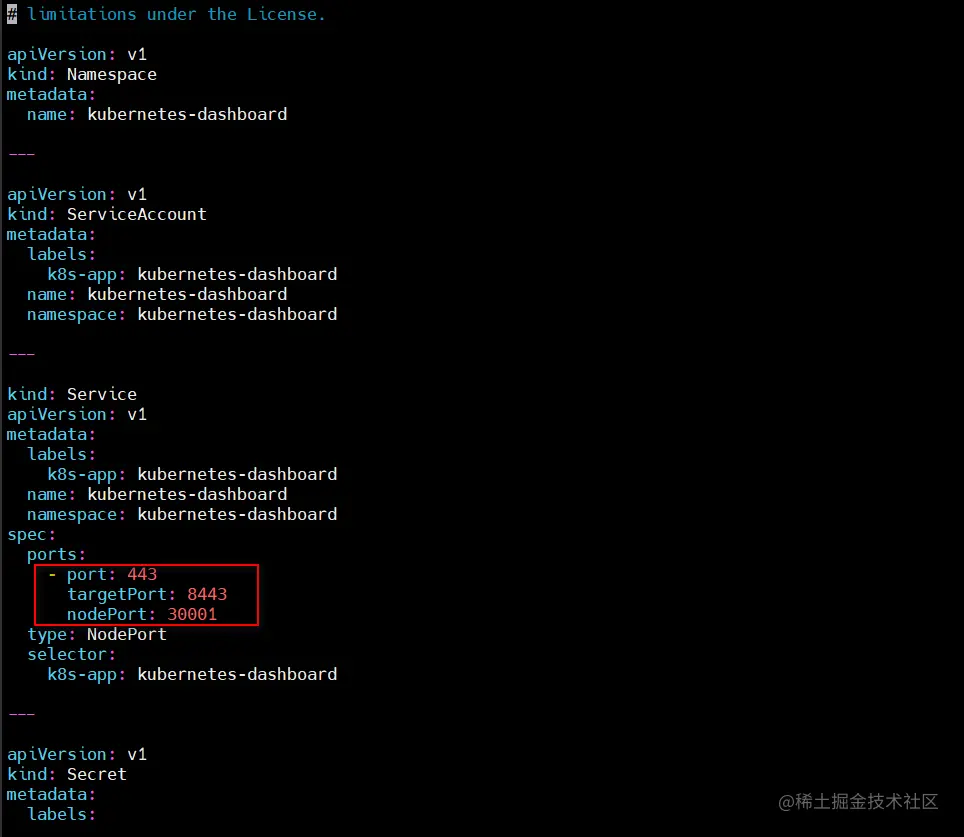
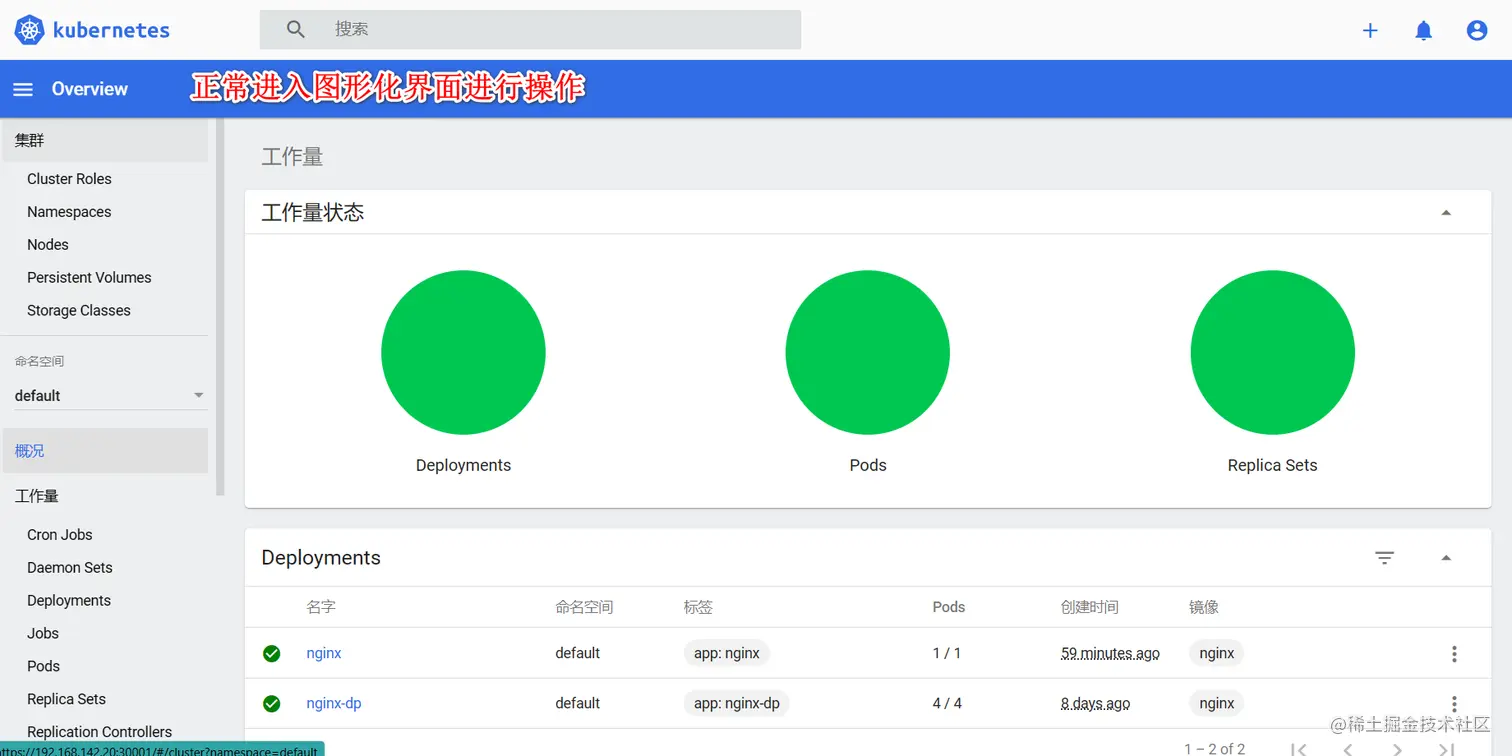
kubectl apply -f recommended.yaml
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
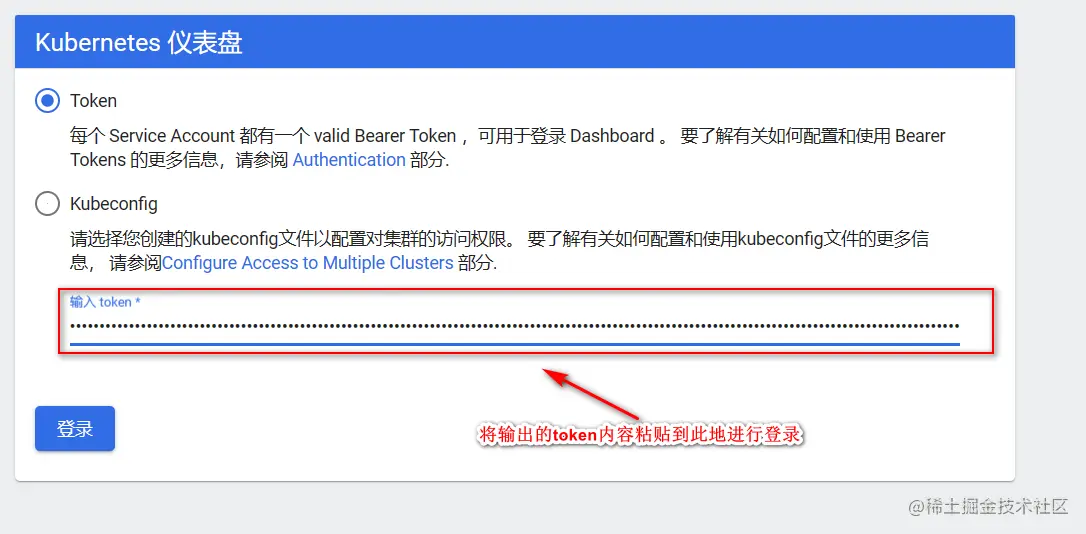
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
https://192.168.142.20:30001
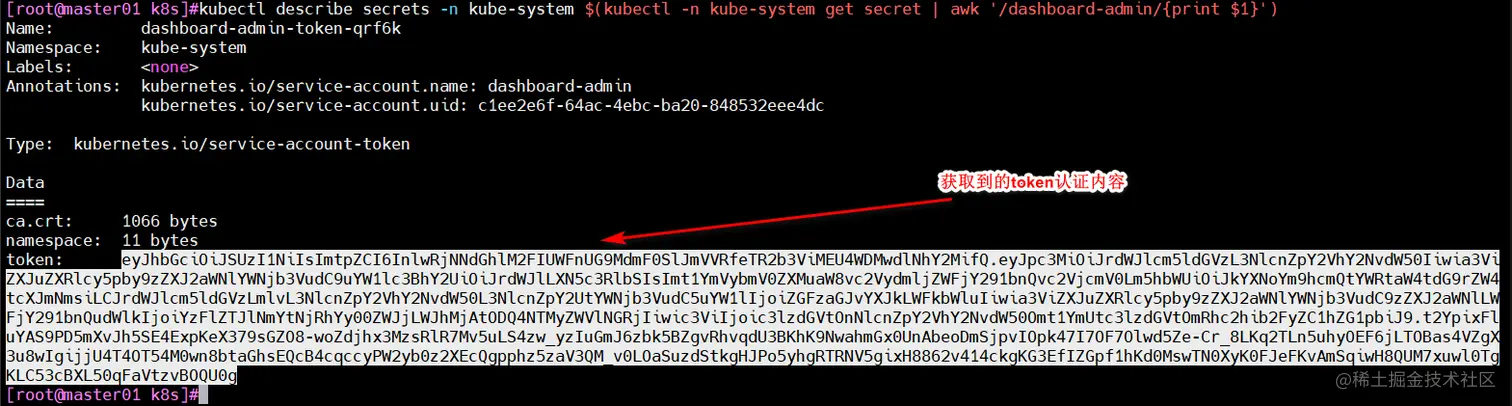
五、K8S集群对接Harbor仓库
5.1 准备服务器及环境
hostnamectl set-hostname hub.test.com
echo '192.168.142.80 hub.test.com' >> /etc/hosts
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
cd /etc/docker/
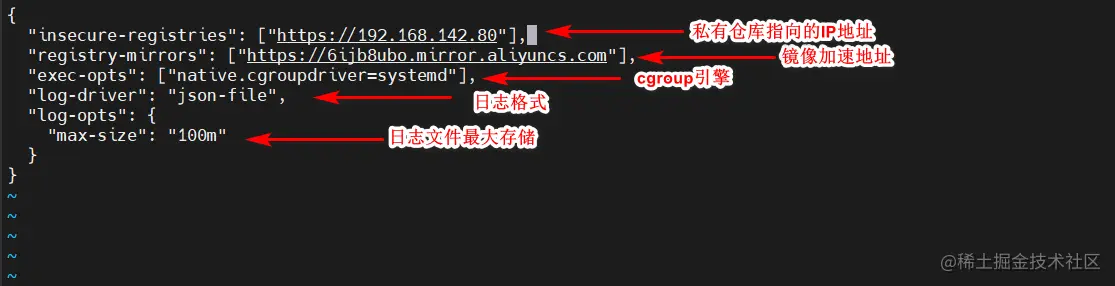
vim daemon.jaso
{
"insecure-registries": ["https://192.168.142.80"],
"registry-mirrors": ["https://6ijb8ubo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
systemctl restart docker
systemctl enable docker
5.2 搭建harbor仓库
cd /opt
cp docker-compose /usr/local/bin/
chmod +x /usr/local/bin/docker-compose
tar zxvf harbor-offline-installer-v1.2.2.tgz
cd harbor/
vim harbor.cfg
5行 hostname = hub.test.com
9行 ui_url_protocol = https
24行 ssl_cert = /data/cert/server.crt
25行 ssl_cert_key = /data/cert/server.key
59行 harbor_admin_password = Harbor12345
mkdir -p /data/cert
cd /data/cert
openssl genrsa -des3 -out server.key 2048
输入两遍密码:123456
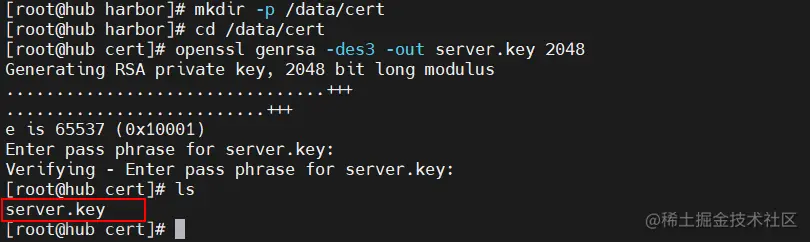
#生成证书签名请求文件
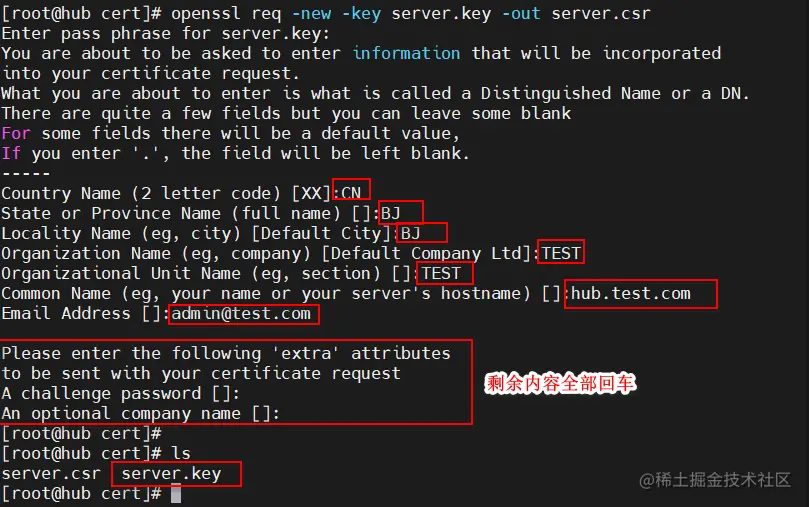
openssl req -new -key server.key -out server.csr
输入私钥密码:123456
输入国家名:CN
输入省名:BJ
输入市名:BJ
输入组织名:TEST
输入机构名:TEST
输入域名:hub.test.com
输入管理员邮箱:admin@test.com
其它全部直接回车
cp server.key server.key.org
openssl rsa -in server.key.org -out server.key
输入私钥密码:123456
openssl x509 -req -days 1000 -in server.csr -signkey server.key -out server.crt
chmod +x /data/cert/*
cd /opt/harbor/
./install.sh
用户名:admin
密码: Harbor12345
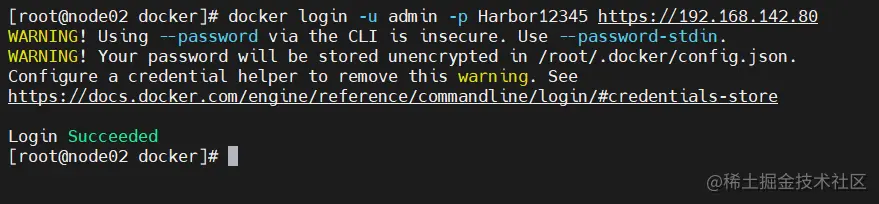
#在一个node节点上登录harbor
docker login -u admin -p Harbor12345 https:
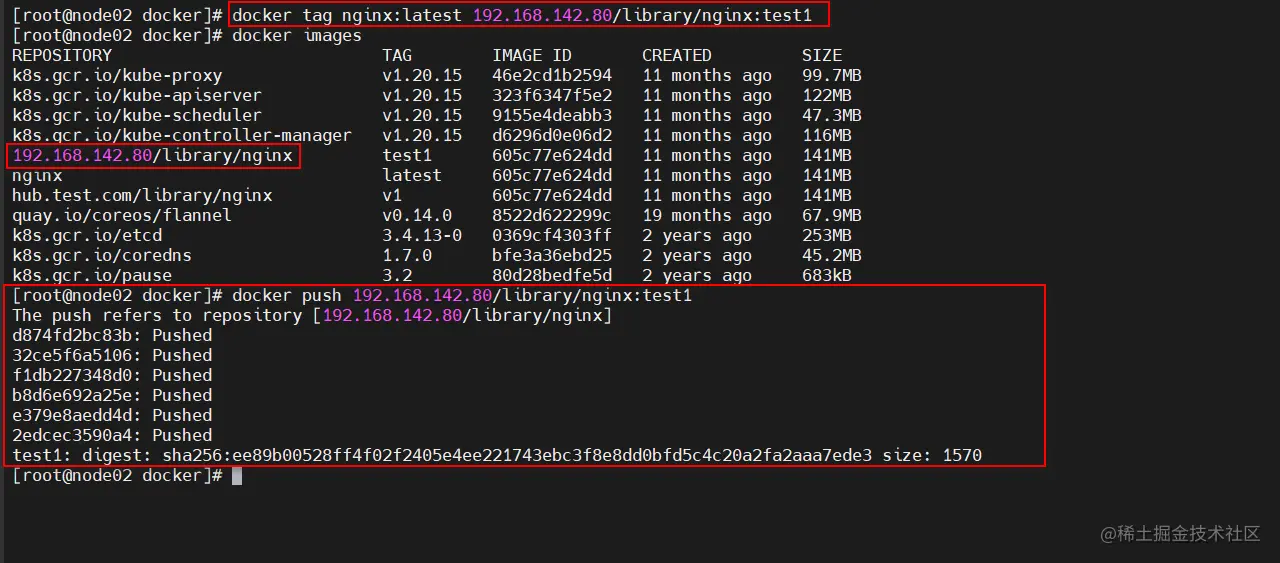
docker tag nginx:latest 192.168.142.80/library/nginx:test1
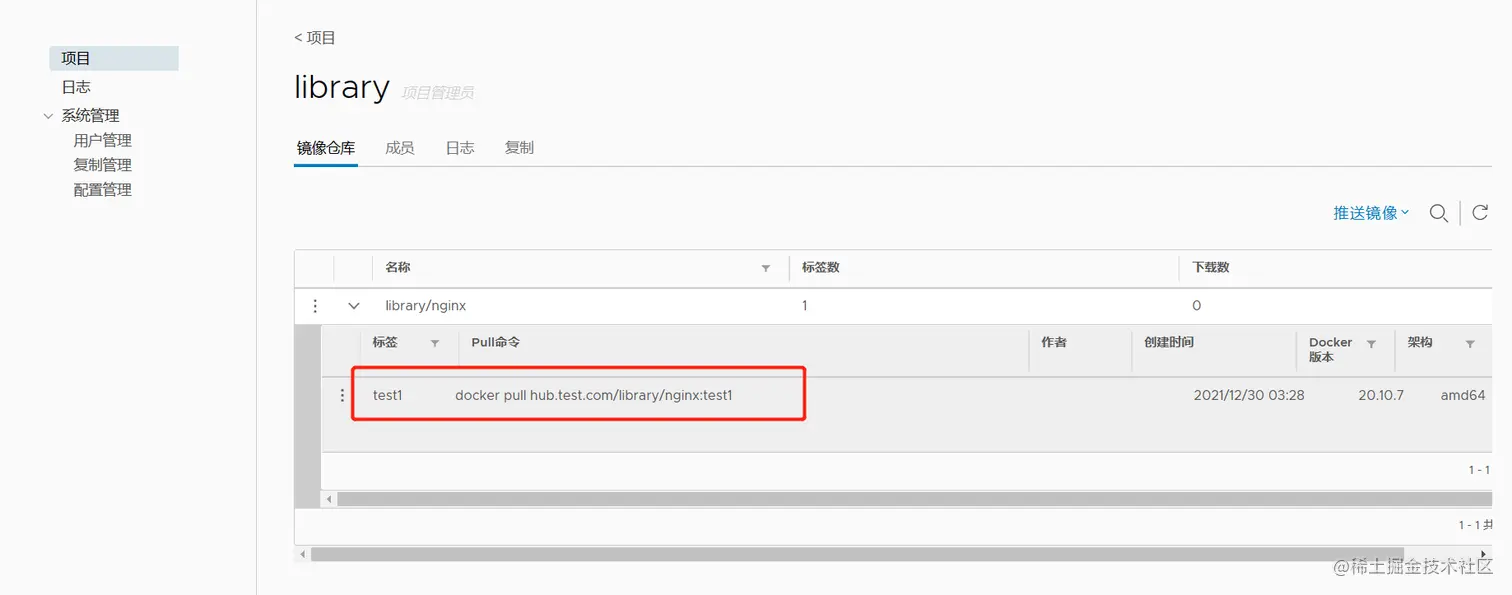
docker push 192.168.142.80/library/nginx:test1
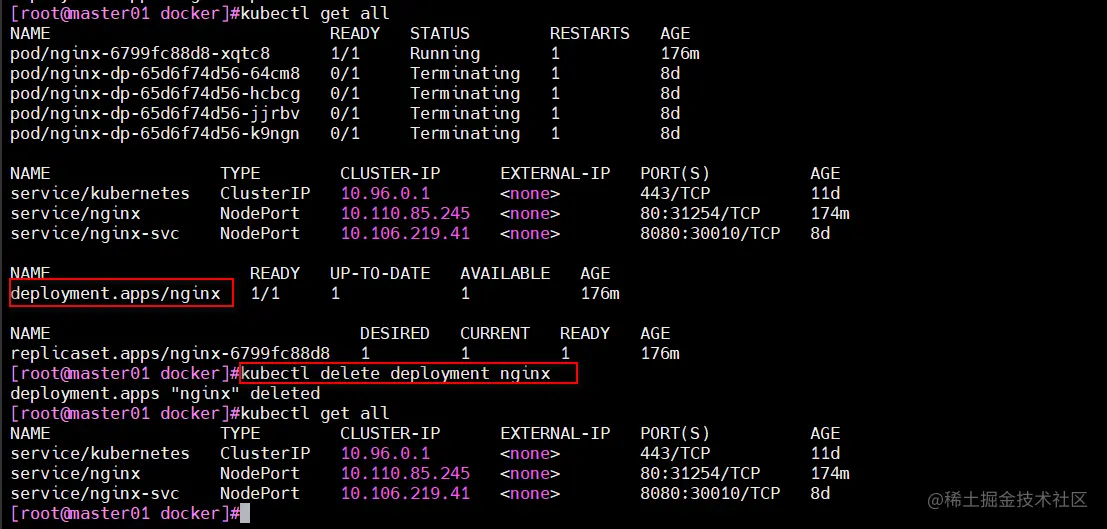
kubectl delete deployment nginx
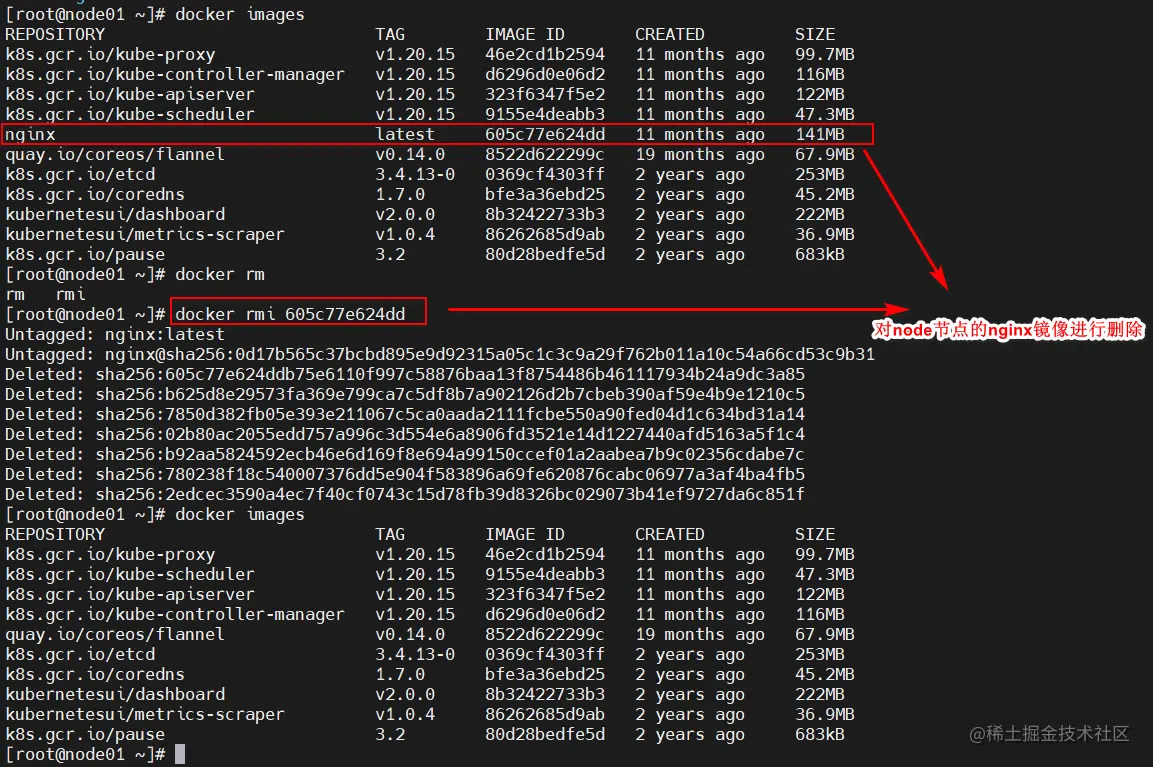
docker images
docker rmi 605c77e624dd
kubectl create deployment nginx-test --image=192.168.142.80/library/nginx:test1 --replicas=3 --port=80
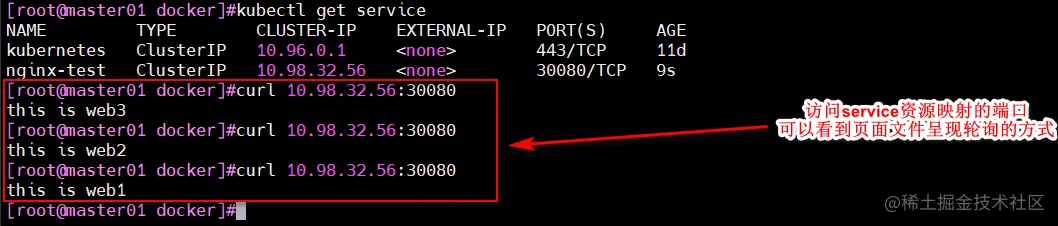
kubectl expose deployment nginx-test --port=30080 --target-port=80
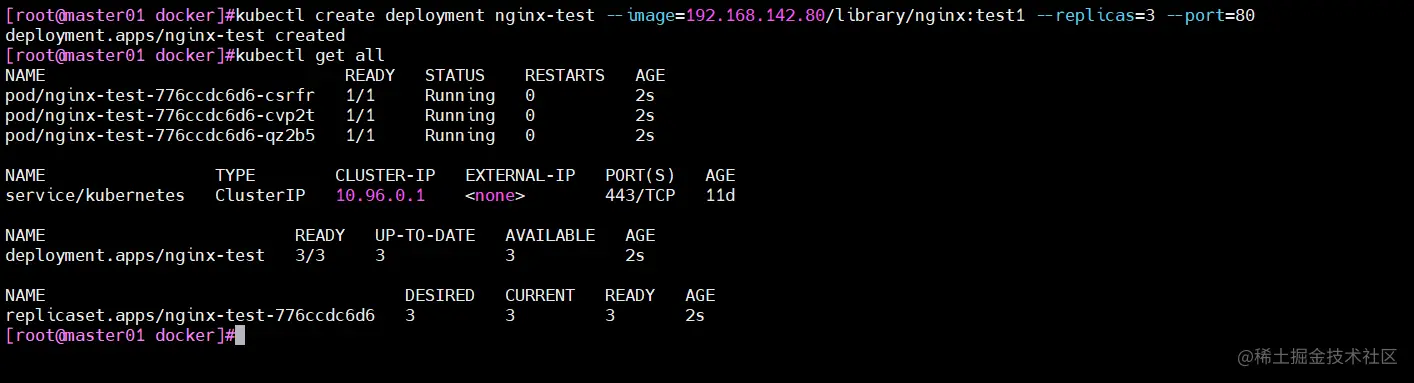
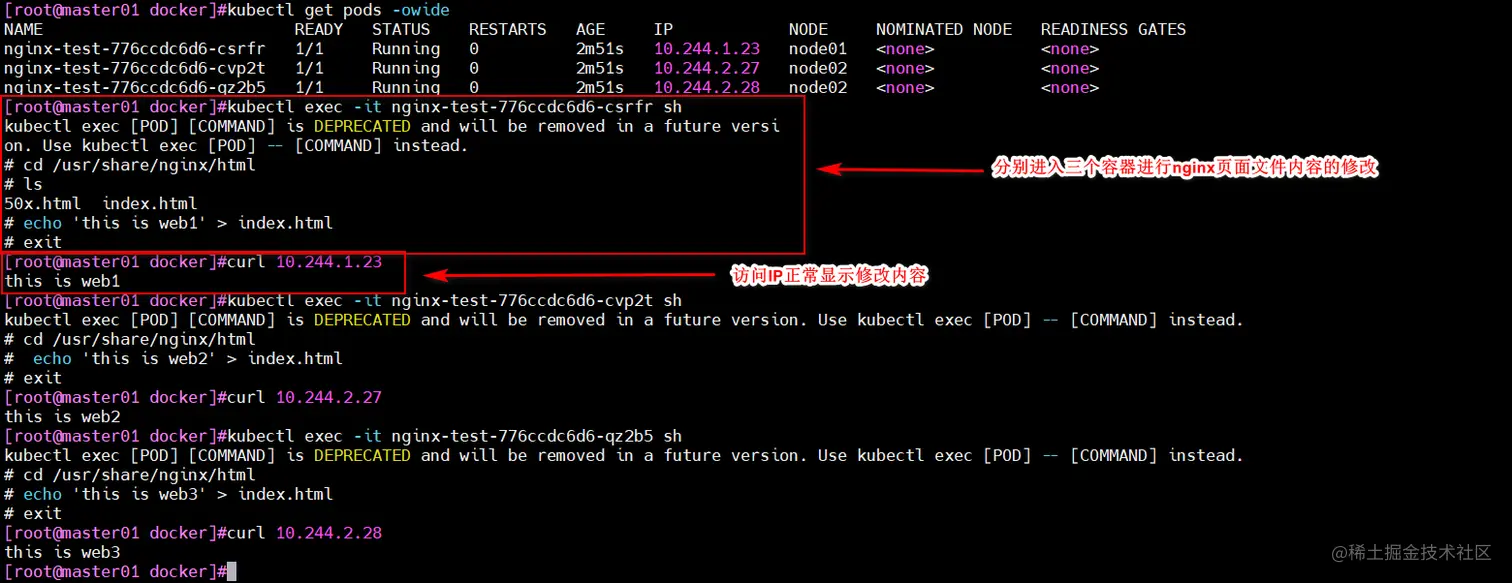
kubectl exec -it nginx-test-776ccdc6d6-csrfr sh
cd /usr/share/nginx/html
echo 'this is web1' > index.html
六、补充:内核参数优化方案
cat > /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
初始化失败,进行的操作


