

Design choices that make Kafka achieve high throughput and low latency
In my previous blog, I wrote about what Kafka is. In this blog, we will go through the design choices that make Kafka deliver high throughput with considerably low latencies.
Although Kafka stores data on Disk it provides high throughput at low latency due to 1. Sequential I/O 2. Page Cache 3. Memory Map 4. Zero Copy Data transfer.
Sequential I/O
Sequential Access in disk is faster than Random Access in memory.
Kafka takes advantage of the above fact and uses an append-only log as its primary data structure. It adds new data to the end of the file thus making writes sequential.
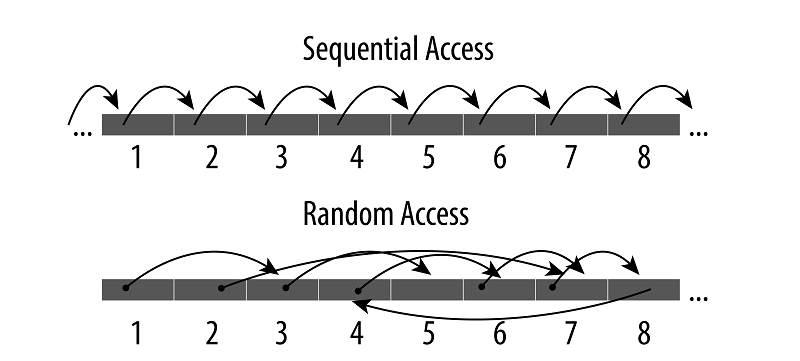
sequential vs Random access
Utilizing Linux Page cache
Page Cache is used to Cache file data on the file system, when a process is performing read/write operations on the file.
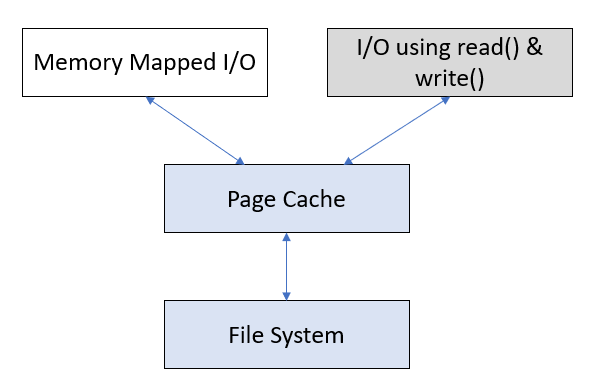
Page cache
Kafka takes advantage of the above fact. Kafka’s data is not written to the hard disk in real-time. When the Broker receives data, it writes the data to the Page Cache first and later on flushes it to disk asynchronously. Writing to Page cache has the following advantages:
- The I/O scheduler batches together consecutive small logical writes into bigger physical writes which improves throughput
- The I/O scheduler attempts to re-sequence writes to minimize the movement of the disk head which improves throughput
- It automatically uses all the free memory (non-JVM memory) on the machine.
- If the consumption and production rates are comparable, data does not even need to be exchanged through physical disks and can be directly read through the Page Cache.
Zero Copy Data Transfer
There are two ways to achieve Zero Copy Data transfer linked to Kafka.
sendFile + DMA
mmap + write
Since Kafka keeps the data in the same (binary) format during its lifecycle, it does not need to load the data in the application buffer, it directly copies data from the page cache to the NIC buffer. sendfile system call of Linux reduces byte copying (across kernel and user spaces) and context switches, hence making the process faster. This copy uses DMA (direct memory access) which means that the CPU is not involved and that makes the process way more efficient (bringing down the time by ~60 % ).
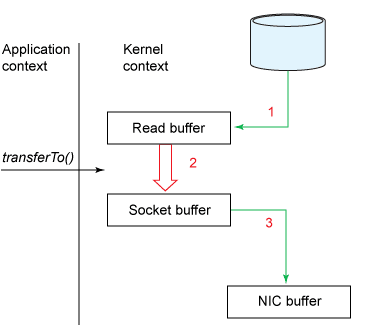
zero copy — Green Arrows are DMA Transfer
Memory Mapped Files — The operations on memory are reflected in disk files.
Mmap maps the read buffer in Kernel to user buffer in user space. This process eliminates the need of copying the data from kernal to user buffer. Mmap improves I/O for large files. Kafka uses Memory Mapped Files for index and timeindex.
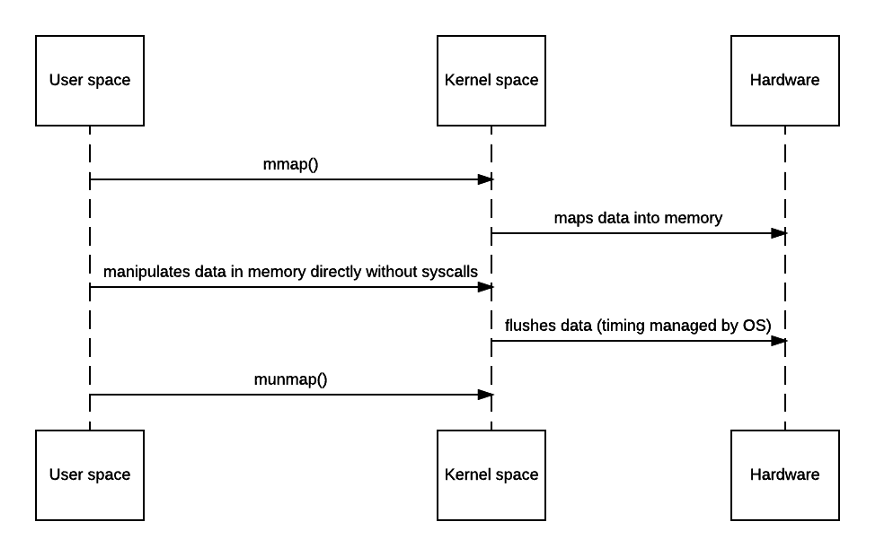
Memory Mapped Files
Note: When SSL is enabled, zero-copy optimization is lost, since the Broker needs to decrypt and encrypt the data.
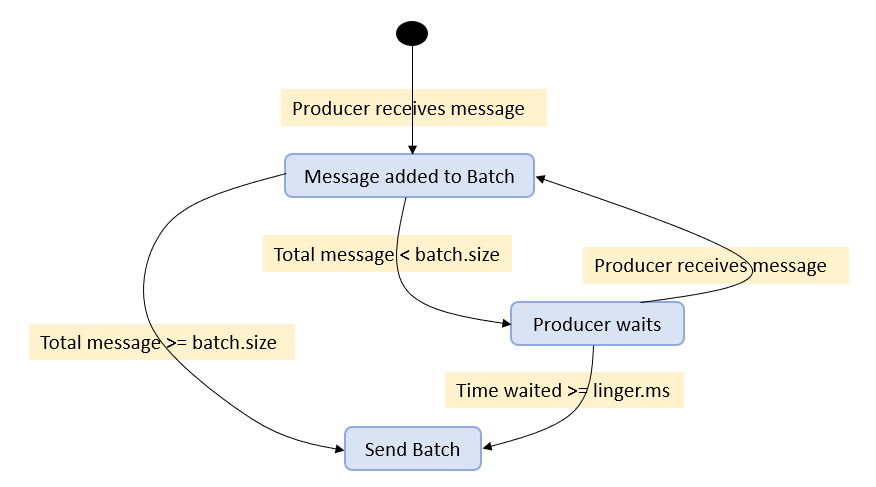
Batching
Kafka clients and brokers will accumulate multiple records in a batch — for both reading and writing — before sending them over the network. Batching of records amortizes the overhead of the network round-trip, using larger packets and improving bandwidth efficiency.
Compression
The Producer compresses data and sends it to the broker to reduce the cost of network transmission. Currently, the supported compression algorithms include Snappy, Gzip, and LZ4. Data compression is often used in conjunction with batch processing as an optimization tool.
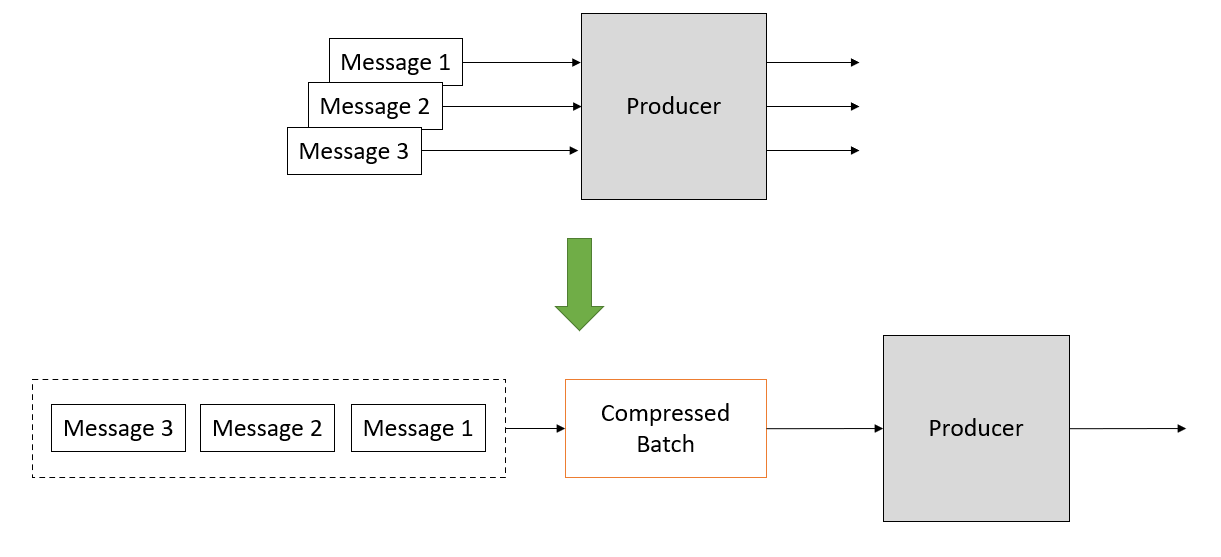
Producer batching & compressing before sending to broker
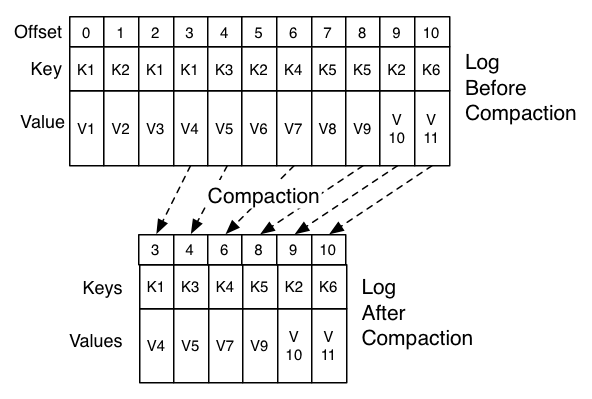
Compaction
Log compaction ensures that Kafka will only retain the latest known value for each message key within the log of data for a single topic partition.
Parallelism Based on Topic partitions
Every partition has a dedicated leader hence any nontrivial topic (with multiple partitions) can, therefore, utilize the entire cluster of brokers for writes and reads. Consumers also can consume messages from any partition which resides in any of the brokers hence efficiently using the whole cluster. We can even configure different partitions on the same node to reside on different disks. In this way, we can take advantage of the parallel processing of multiple disks.
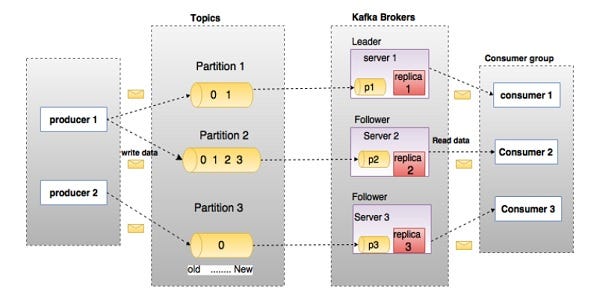
Image credit:
[
tutorial-point
](www.tutorialspoint.com/apache_kafk…)
No serialization/deserialization on the Broker
A significant amount of work is performed on the client side before records get to the server/broker. This includes the staging of records in an accumulator, hashing the record keys to arrive at the correct partition index, checksumming the records and the compression of the record batch. The client is aware of the cluster metadata and periodically refreshes this metadata to keep abreast of any changes to the broker topology. This lets the client make low-level forwarding decisions; rather than sending a record blindly to the cluster and relying on the latter to forward it to the appropriate broker node, a producer client will forward writes directly to partition masters. Similarly, consumer clients are able to make intelligent decisions when sourcing records, potentially using replicas that are geographically closer to the client when issuing read queries.
Summary of optimizations
- Sequential reading and writing to take the most out of commodity disks
- Zero copy tech for data transfer
- Mmap File mapping for index and timeindex files
- Batching, Bulk compression
- Buffered write operation
- Partition level parallelism to utilize broker hardware
