

简介
我已经在这个博客上洒下了很多数字墨水,谈论编译时工作流的魔力,使用Gatsby等工具来构建丰富的动态网络应用,而不需要运行时Node服务器。
这对于不经常变化的静态内容(如博客文章)来说非常有效,但我们如何构建依赖于快速变化的用户生成的数据的东西,如点击率计数器?
在本教程中,我们将介绍如何使用无服务器函数来驱动一个点击率计数器,比如我博客上的那个。
一个真实的命中率计数器!点击获取惊喜✨
预期受众
本教程假设你已经有一个静态的React网站(Gatsby/Next)被部署在Vercel或Netlify上。
它是为中级React开发者编写的;如果你是现代JS生态系统的新手,可能会有点难以理解。
为什么我想要一个点击率计数器?
事情是这样的:时间已经过去了,90年代的东西现在已经很酷、很复古了。* 这是 "潮流"--今年有一堆很酷的怀旧软件。
-
Webrings又回来了!有Sidebar Webring和Weird Wide Webring,还有其他的。
-
Vistaserv的创始人在浏览器中实现了90年代风格的文本渲染。
-
互联网名人Jordan Scales建立了98.css,这个设计系统忠实地再现了我一直以来第三喜欢的操作系统。
点击量计数器是 "早期网络 "的典型。你的Geocities网站没有一个是不完整的!
即使你不想建立一个点击率计数器,我也鼓励你继续阅读;点击率计数器是一个有趣的例子,但我们将在这篇文章中学习的工具将为你的静态网站打开各种大门。
工具
这里有几个活动部分需要结合起来。让我们对地形有一个高层次的了解。
前台
我将在本教程中使用Gatsby,但任何基于React的前端都可以使用(如Next.js或create-react-app)。
对于用户界面,我们将使用React Retro Hit Counter,这是我几年前创建的一个软件包。它给了我们一个React组件,我们可以用它来显示点击次数。它也是非常可定制的,如果你想要一个更简约/现代的审美。
这个包暴露了一个展示/视觉组件,但它没有为我们处理任何数据获取和状态管理。这个拼图还有更多的碎片。
后台
我们正在建立一个静态网站,所以我们没有机会接触到运行中的Node/Express服务器。
像Netlify和Vercel这样的平台提供 "功能即服务"。你不需要将一个持久的应用程序部署到特定的服务器上,而是部署单独的功能,根据请求启动。
这些平台都在引擎盖下使用AWS Lambda,并且它们磨掉了一些更尖锐的边缘。例如,当直接使用AWS Lambda时,你需要做大量的处理和捆绑,以确保每个功能是它自己独立的小应用程序;Netlify和Vercel都为你处理这个问题,并且它们直接整合到构建和部署过程中。
数据库
我选择了FaunaDB,一个为无服务器环境构建的现代NoSQL托管数据库。
对数据库的选择感觉有点武断;我们的需求非常小,我们真的只需要一个地方来存储和检索一组数字!但我对FaunaDB的印象非常好。但我对FaunaDB印象深刻。它有一个很棒的管理面板,而且它是专门为无服务器功能而设计的。我想它的扩展性会非常好。
下面是一个快速的例子,显示FaunaDB的JS API是如何工作的。
const faunadb = require('faunadb');
async function getArticleById(id) {
const q = faunadb.query;
// We connect to the database on every request.
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET_KEY,
});
// The `faunadb.query` object aliased to `q` has a bunch
// of helper methods to create a query.
const query = q.Get(q.Match(q.Index('article'), id));
// A query on its own is a description of what we want.
// To execute it, we have to pass it to `client.query`:
const document = await client.query(query);
return document;
}
FaunaDB是一个 "数据库即服务";他们托管数据库,你为你所使用的数据库付费。
这篇文章没有得到FaunaDB或其他任何人的赞助。我只是碰巧在这个项目中使用了它,并认为它工作得相当好但最终,你应该使用你已经熟悉的任何数据库。这并没有什么大的影响。
我们的数据模型
下面是Fauna数据库的结构。
-
一个数据库类似于一个SQL数据库。我为我的整个网站创建了一个数据库,它持有多种类型的数据。
-
一个集合是一组单独的项目,像一个SQL表。
-
一个文档是一个单一的数据,像一个SQL行。
-
索引让我们可以查询一个集合,根据一个特定的字段来查找文档。
这与MongoDB的工作方式非常相似,如果你以前使用过它的话。
对于我们的数据模型,我们希望每篇博客文章有一个文档,并且它应该跟踪该文章的标题以及点击率。下面是一个文档的例子。
{
"slug": "persisting-react-state-in-localstorage",
"hits": 21097
}
每篇文章都将被存储在一个集合中,并由slug 。
使用Fauna进行设置
如果你还没有,在Fauna注册一个帐户。
创建一个新的数据库,以你的网站命名,并创建一个新的集合,名为hits 。你可以把其他每一个字段都保留为它的默认值。
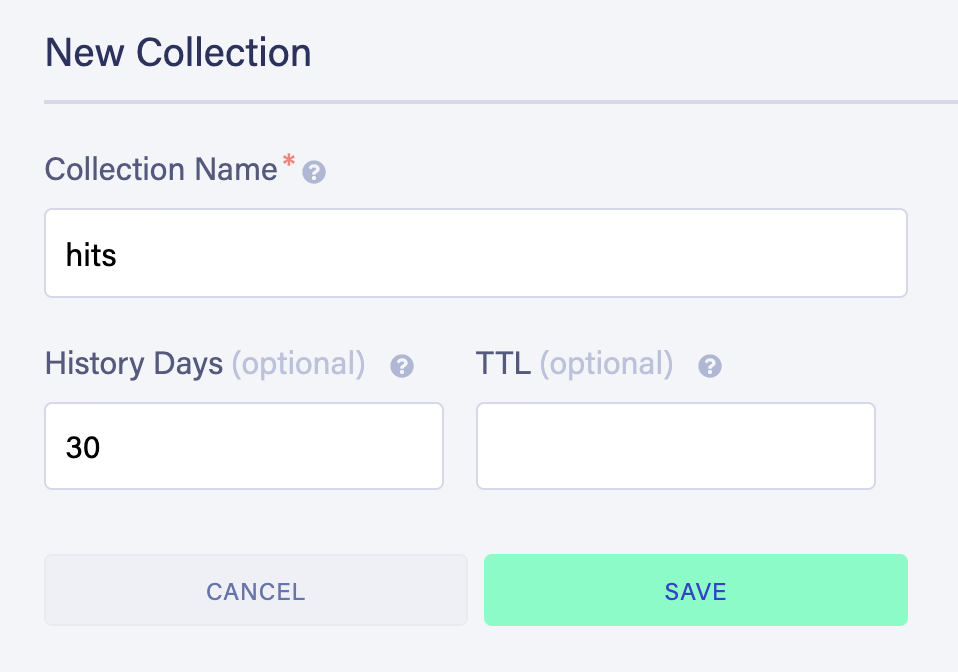
我们也来创建一个新的索引。索引在FaunaDB中是非常关键的;你不是在查询一个集合,而是在查询索引。
在这种情况下,我们将从我们的hits 集合中获取它,并将其命名为hits_by_slug 。我们可以用 "Terms "来指定我们要查询的字段:我们将它设置为data.slug 。
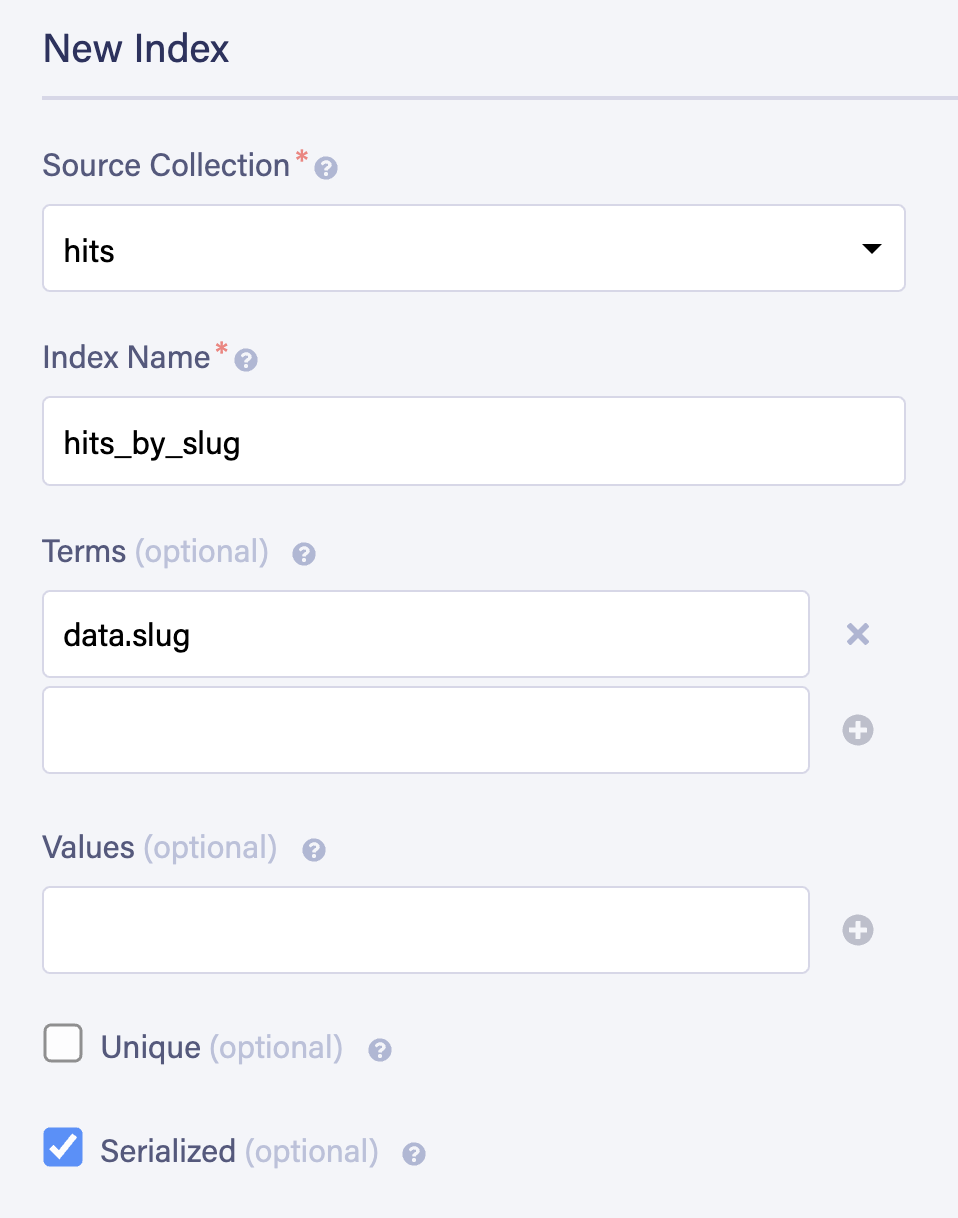
我们需要FaunaDB的密匙来授权访问这个数据库的能力。点击左侧导航中的 "安全",然后点击标题中的 "新密钥"。点击 "保存"。
我们要把我们的密匙存储在一个环境变量中,叫做FAUNA_SECRET_KEY 。
最后,我们需要安装FaunaDB的依赖关系。
yarn add faunadb
设置功能
在开始编写我们的无服务器函数之前,我们需要弄清楚把它放在哪里!Netlify和Vercel都有自己的标准化的地方。
-
Netlify有一个顶级的
functions目录 -
Vercel的
api目录中的pages。
你的函数文件的名字将在路由中使用。创建一个名为register-hit.js 的新文件。你可以通过以下网址访问它。
-
对于Netlify,
/functions/register-hit.js将在以下网址提供服务/.netlify/functions/register-hit -
对Vercel来说,
/pages/api/register-hit.js将在以下地址提供服务/api/register-hit
Netlify和Vercel都提供了开发工具,让你在本地进行测试。
编写我们的 "寄存器命中 "函数
让我们写一些伪代码来弄清楚我们的函数应该如何工作。
function visitPage(request) {
connect to database;
let slug = some parameter from the request
if (slug is missing) {
return 404 error;
}
if (!collection.exists(slug)) {
database.createDocument({
slug: slug,
hits: 0,
})
}
document = database.query(slug);
// Increment the # of hits, to account for
// this current visitor
document.update({
hits: document.hits + 1,
})
// Return the number of hits
return document.hits;
}
我们的函数有3个职责。
-
创建一个文件,如果它还不存在的话
-
递增
hits的值 -
返回将在页面上显示的
hits值。
你可能会对1个函数同时设置和获取值感到困扰;我们违反了单一责任原则!但我认为这是合理的。但我认为这是有道理的。另一个选择是有两个独立的端点,这意味着两倍的函数调用,这要花两倍的钱。
下面是JS中的情况。业务逻辑是相同的,但包装器因平台而异。
const faunadb = require('faunadb');
exports.handler = async (event) => {
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET_KEY,
});
const { slug } = event.queryStringParameters;
if (!slug) {
return {
statusCode: 400,
body: JSON.stringify({
message: 'Article slug not provided',
}),
};
}
// Check and see if the doc exists.
const doesDocExist = await client.query(
q.Exists(q.Match(q.Index('hits_by_slug'), slug))
);
if (!doesDocExist) {
await client.query(
q.Create(q.Collection('hits'), {
data: { slug: slug, hits: 0 },
})
);
}
// Fetch the document for-real
const document = await client.query(
q.Get(q.Match(q.Index('hits_by_slug'), slug))
);
await client.query(
q.Update(document.ref, {
data: {
hits: document.data.hits + 1,
},
})
);
return {
statusCode: 200,
body: JSON.stringify({
hits: document.data.hits,
}),
};
};
交易
如果两个请求在完全相同的时间进来,它们可能不会都被计算在内。不能保证数据库会在另一个请求读取新值之前完成写入。
为了解决这个问题,我们需要使用事务。
在前台进行布线
当我们的页面加载时,我们将向这个函数端点发出请求,以增加数字,并检索到它来显示。
如上所述,我们将使用一个包来实现实际的用户界面。安装该依赖性。
yarn add react-retro-hit-counter
创建一个名为HitCounter 的新组件,并在其中添加这段代码。
// src/components/HitCounter
import RetroHitCounter from 'react-retro-hit-counter';
function HitCounter({ slug }) {
const [hits, setHits] = React.useState(undefined);
React.useEffect(() => {
// Don't count hits on localhost
if (process.env.NODE_ENV !== 'production') {
return;
}
// Invoke the function by making a request.
// Update the URL to match the format of your platform.
fetch(`/api/register-hit?slug=${slug}`)
.then((res) => res.json())
.then((json) => {
if (typeof json.hits === 'number') {
setHits(json.hits);
}
});
}, [slug]);
if (typeof hits === 'undefined') {
return null;
}
return <RetroHitCounter hits={hits} />;
}
这里有很多事情要做,所以让我们把它分解一下。
从本质上讲,我们正在创建一个智能的HitCounter 组件,它围绕着我们从NPM得到的展示性组件。它将从我们的无服务器函数中获取数据,并将其传递给该组件。
我们跟踪React状态下的点击数。我们将其初始化为undefined 。在我们的组件第一次渲染时,我们还没有得到数据,所以我们有一个提前返回的null 。我们只想在我们知道页面有多少次点击时显示点击计数器。
我们使用useEffect ,在加载后立即请求我们的数据。它将调用我们之前写的函数,并返回当前的点击数,我们将其设置为状态。这将导致重新渲染,由于hits 不再是undefined ,我们将渲染RetroHitCounter 。
我们的组件需要一个道具:slug 。这是一个特定文章或页面的唯一标识符。它成为我们获取请求中的一个查询参数。如果我们想追踪个别的内容,这是很关键的。我们在useEffect 依赖数组中使用slug ,但这更多的是一种形式;我们并不期望lug真的发生变化。
为我们的组件找到一个家
我们有一个闪亮的包含电池的HitCounter 组件,现在怎么办?
你需要在你的项目中找到一个地方来渲染它。在Gatsby/Next上下文中,你可以把它放在你关心的每一个页面-组件中。你也可以把它放在一个布局组件中。
你需要找到一种方法,将lug传递给你的组件。这不在本教程的范围内,因为这完全取决于你的项目结构。在Gatsby应用程序中,你应该能够用GraphQL来获取这个。
耦合和权衡
我们所选择的方法是将数据获取与展示结合起来。这是一把双刃剑:它使用起来很方便,但也有潜在的危险。如果你不小心渲染了多个实例,你的数字会激增,因为每一个页面浏览都会增加2个计数。
这是一个令人惊讶的容易犯的错误:也许你有一个桌面页脚和一个移动页脚,你使用媒体查询来确保只有一个是可见的。即使它没有显示给用户,这些组件仍然在被渲染,所以每次访问都会有两个获取请求!这就是为什么我们要把它分开。
把这两者分开也许是明智的。当页面加载时,你可以发出一个请求来设置和获取点击率,然后将这些数据存储在上下文中。你的HitCounter 组件将消费该上下文,而不提出任何网络请求。
至于哪种策略最适合你的项目,就看你自己了
总结
本教程涵盖了如何创建一个点击计数器,这是一个令人愉快的亮点,肯定会给千禧一代的脸上带来笑容。
不过其核心思想要广泛得多。有了FaunaDB和无服务器函数,我们就可以建立各种东西了在这个博客上,我对 "喜欢 "按钮使用了类似的技术,我还建立了一个管理面板,让我可以查看我所有文章的喜欢/点击情况。
使用无服务器功能从未如此简单,而且使用这些功能你可以 "免费 "获得很多东西:你不必担心服务器、维护、扩展等问题。
对于前端开发人员来说,无服务器函数和FaunaDB可以成为进入全栈开发的入口药物。这么多的新门打开了
