

我坚信,静态网站是非常棒的:它们比传统的服务器渲染的网站更快、更有弹性、更容易扩展。一个复杂的应用程序可以被烘烤成一堆HTML和JSON文件,通过CDN提供服务。
但是,当你试图采用全静态的方式时,某些事情会变得更具挑战性。例如,你如何建立一个动态的、互动的过滤器?

在一个典型的网络应用中,每当输入值发生变化时,你就会向API提出一个fetch 。但我们不能在静态网站中这样做,因为我们不想依赖运行时的API。
我们在Gatsby最近的一个项目中遇到了这个问题,我对我们想出的解决方案非常满意!它看起来和其他的网站一样。它看起来和感觉就像其他数据库驱动的网络应用程序,但有一些额外的惊喜。
在这篇博文中,我们将看到我们是如何做到这一点的,通过使用世界上最狡猾的路由变化🕵🏻♂️
背景
几周前,我在Gatsby的团队推出了Will it Build,这是一项基准服务,显示了构建Gatsby网站所需的时间。
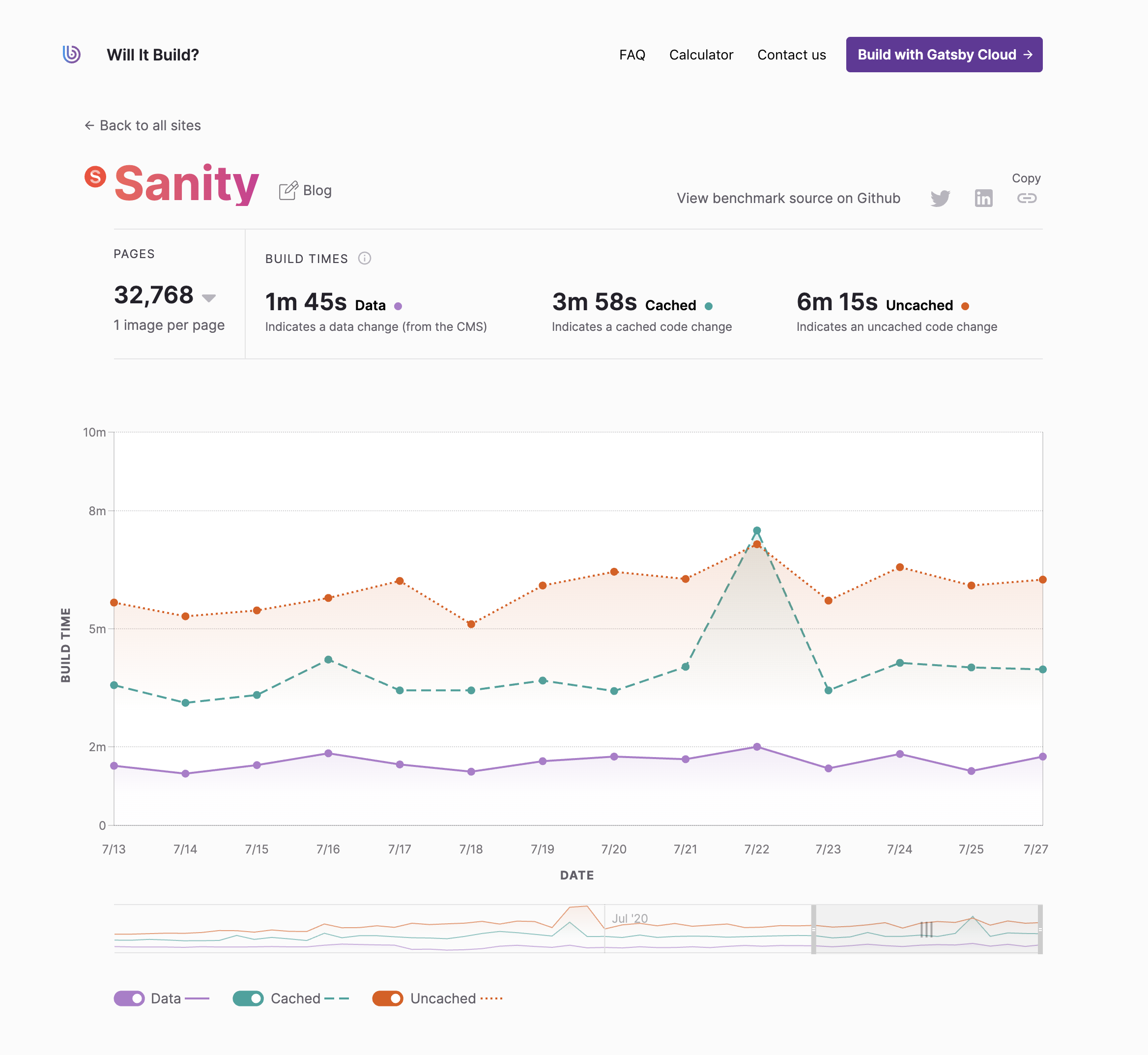
我们建立这个网站是为了回答我们在Gatsby经常收到的一个问题。
我有一个[Wordpress]网站,有[8000]个页面;用Gatsby建设需要多长时间?
细节各不相同,但故事都是一样的:开发人员担心,如果他们必须在编译时构建每个页面,他们的构建时间会膨胀。
这是一个合理的担忧;从历史上看,构建时间一直是Gatsby,以及更广泛的静态网站的 "阿喀琉斯之踵"。非常大的网站可能需要60分钟以上的时间来构建。
值得庆幸的是,在过去的一年里,情况已经发生了很大的变化。Gatsby的核心/云团队已经投入了大量的时间和精力来提高构建性能;通过增量构建,即使是非常大的网站也可以在一分钟内完成构建(有一个热缓存)。
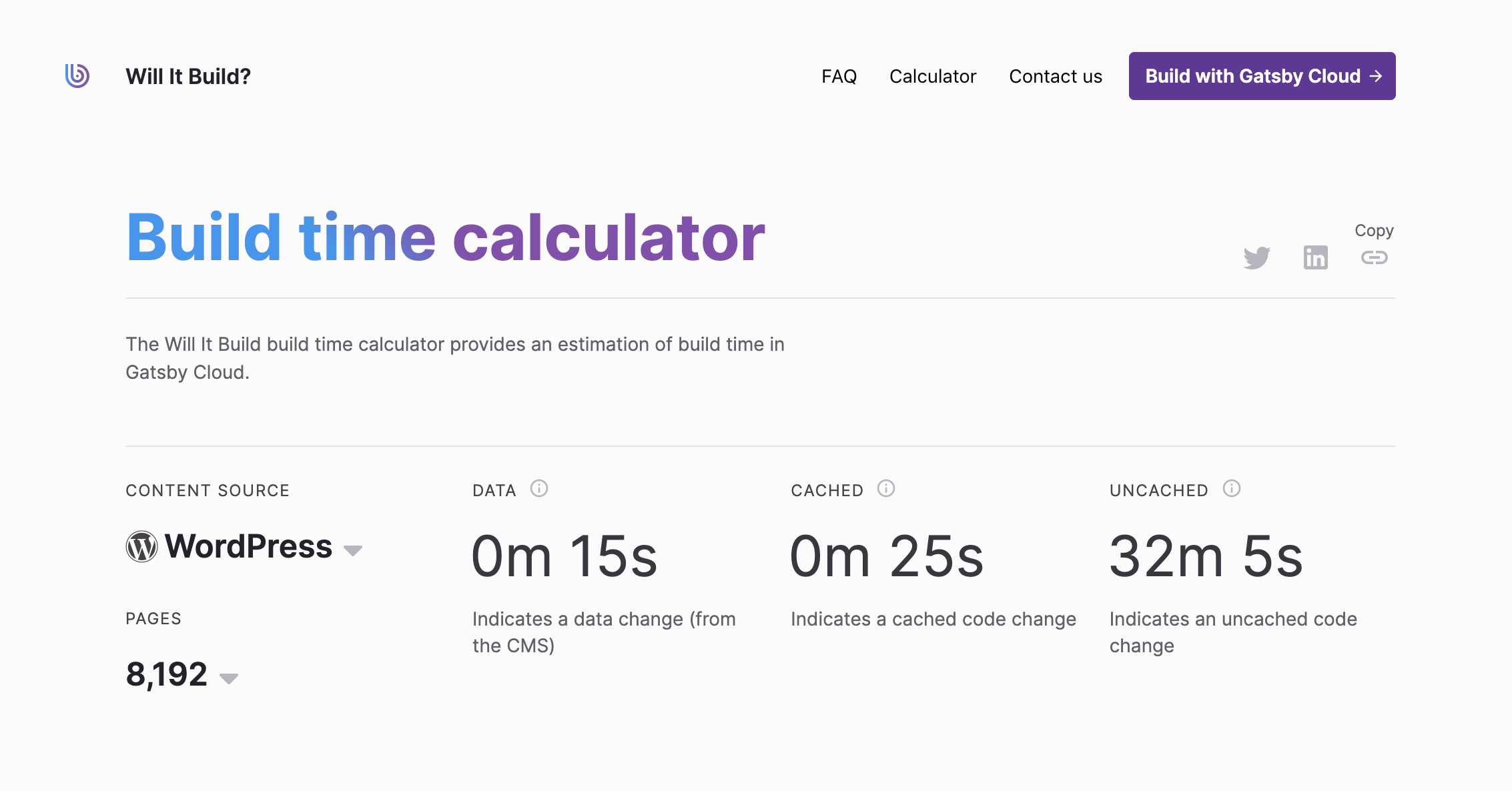
Will it Build每天运行几十个基准,范围从512页到超过32000页,跨越8个不同的内容源(包括Wordpress、Drupal、Markdown/MDX、Contentful和Sanity)。你可以使用其GraphQL API,自己玩弄这些数据。
Will it Build网站的前端自然是用Gatsby构建的。我很高兴地说,它是*完全静态的,*只有在我们建立网站时才从API中获取数据。
我们要解决的问题就是上面GIF中的问题。我们网站的特点是让用户调整参数的输入,以调整基准的类型和大小。
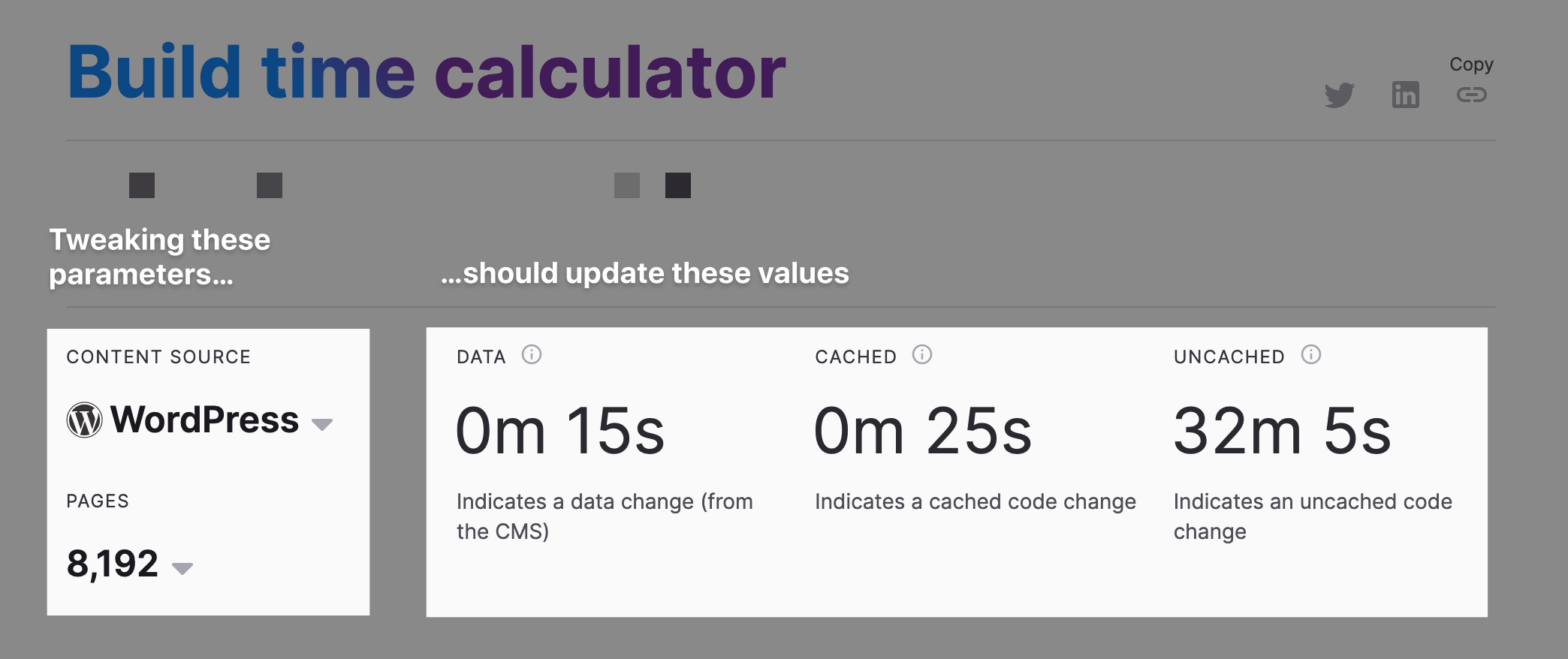
我们如何在一个静态网站上做到这一点?
页面导航
Will it Build的URL结构是:
/source/:contentSource/page-count/:numOfPages
我们为contentSource 和numOfPages 的每个组合生成一个不同的页面。
因此,实际上,我们想在用户改变这些参数之一时,将他们从一个页面导航到另一个页面。在其最简单的形式中,它看起来像这样。
<select
onChange={(ev) => {
const newPath =
`/source/${ev.target.value}/page-count/8192`;
window.location = newPath;
}}
>
{/* options omitted */}
</select>
不过,如果我们这样做,就不是最好的用户体验了。
-
在获取新的HTML文档时,我们会向用户展示一个空白的白屏
-
用户的滚动位置会丢失
-
焦点会被重置
-
扰乱了用户的历史记录
让我们依次解决这些问题。
客户端导航
我们可以使用Gatsby内置的路由器Reach Router,使用客户端导航进行过渡,而不是做window.location 。
import { navigate } from "gatsby"
<select
onChange={(ev) => {
const newPath =
`/source/${ev.target.value}/page-count/8192`;
navigate(newPath);
}}
>
{/* options omitted */}
</select>
有了这个变化,我们的过渡就会更迅速,而且不会出现通常在URL变化时出现的 "白色闪光"。
除了生成一个静态网站,Gatsby还具有SPA(单页应用程序)的功能。我们可以使用客户端路由从一个页面跳到另一个页面。
当我们调用navigate (或使用<Link /> )时,我们不是在加载一个全新的HTML文件;我们是从一个JSON文件中提取我们的页面组件需要的新道具。
保存滚动位置
一般来说,当我们从一个页面导航到另一个页面时,我们希望滚动位置被重置到顶部。这就是浏览器默认的工作方式,Reach Router也模仿了这种行为。
这种情况是一个特殊的例外;我们想让用户保持在他们所处的位置,因为滚动位置的改变会让人迷失方向。
令人高兴的是,Gatsby给了我们一个可以使用的逃生舱门。让我们先在我们的navigate 调用中加入一些位置状态。
navigate(newPath, {
state: {
disableScrollUpdate: true,
},
})
位置状态在概念上类似于查询参数,除了它不在URL中显示。就其本身而言,这没有任何影响,但我们可以在一个特殊的Gatsby浏览器API中访问这个状态。
navigate(newPath, {
state: {
disableScrollUpdate: true,
},
})
shouldUpdateScroll在每次路线改变时都会触发,它希望我们返回一个布尔值:如果我们应该滚动到顶部,true ,如果我们应该保持当前的滚动位置,false 。默认情况下,这总是返回true 。
我们使用位置状态来允许特定的路由变化来覆盖这种行为,并保持用户在页面上的正确位置。
焦点管理
一般来说,当用户跟随一个链接到一个新的页面时,焦点应该移动到body 元素。这对于使用鼠标以外的设备(如键盘)进行导航的人来说是必须的。
在这种情况下,我们希望保留对下拉元素的焦点。如果在与表单控件交互后焦点被重置,那将是令人惊讶和迷惑的。
为了管理这个,我们将使用另一个Gatsby浏览器API。 onRouteUpdate:
// gatsby-browser.js
export const onRouteUpdate = loc => {
const { state } = loc.location
if (state && state.refocusId) {
const elem = document.getElementById(state.refocusId)
if (elem) {
elem.focus()
}
}
}
onRouteUpdate 方法在路由改变时被调用,并允许我们添加一些副作用。我们将再次使用位置状态来传递一个特定的元素ID。如果提供了一个ID,我们就会找到那个元素并关注它。
这就要求每个select 有一个唯一的ID。
// gatsby-browser.js
export const onRouteUpdate = loc => {
const { state } = loc.location
if (state && state.refocusId) {
const elem = document.getElementById(state.refocusId)
if (elem) {
elem.focus()
}
}
}
凌乱的历史
每当用户调整一个参数时,就会在历史栈上推送一个新的条目。当他们点击后退按钮时,会把他们带到之前的设置,而不是之前的页面。这并不理想。
值得庆幸的是,Reach Router的navigate 功能对此有一个选项。
navigate(newPath, {
replace: true,
state: {
refocusId: ev.target.id,
disableScrollUpdate: true,
},
})
我们不会在历史堆栈中添加一个新的条目,而是替换当前的条目。这与人们所期望的一致。
结果
在解决了这些问题之后,我们已经成功地创造了一个感觉上不像路线变更的路线变更🎉。
一般来说,像这样滥用内置机制是不好的;从语义上讲,这并不是真正的路线变更。但我相信好处多于坏处。
因为我们正在改变路由,URL会随着每个参数的调整而更新。这非常酷用户可以复制链接来分享一个特定的配置。
另外,性能也很好。我们不需要在遥远的服务器上等待任何数据库调用。数据已经被编译成一个JSON文件,存放在你附近的CDN边缘。我们可以用缓存做类似的事情,但我觉得这样更简单。
可能有更好的方法?
当我们执行路由变更时,Gatsby从引擎盖下的一个JSON文件中获取我们需要的数据。据推测,我们可以自己请求这些数据。而不是从我们的API获取,我们将从我们的CDN获取。
老实说,在我们已经完成了目前的方法之前,我并没有想到这个想法😅。
但我不确定一种方法是否比另一种更好。权衡利弊是不同的。
-
赞成:我们不会因为偷偷地改变路线而违反语义。
-
缺点:Gatsby产生的
page-data.js文件是一个实现细节,在未来的版本中可能会毫无征兆地改变。该框架并不期望我们这样做。 -
优点:我们不需要担心滚动位置和焦点管理。我们不太可能意外地使某些人的体验变差。
-
缺点:当用户调整参数时,URL不会更新,这使得分享具体结果变得更加困难。
新出现的模式
随着静态网站变得越来越流行,我怀疑我们会在这个领域看到更多的创新。这很令人激动!随着静态地做越来越多的事情变得可行,我们的应用程序将变得更快,我们的工作将变得更容易。
