开启掘金成长之旅!这是我参与「掘金日新计划 · 12 月更文挑战」的第9天
本文首发于CSDN。
诸神缄默不语-个人CSDN博文目录
李宏毅2021春季机器学习课程视频笔记集合
@[toc]
1. 深度学习简介
本节是17年李宏毅机器学习课程中的一个章节。17年版我刷过一遍,但是看得不详细。大致来说,当时的逻辑是先介绍逻辑回归和softmax,然后引入深度学习。21版就直接从sigmoid曲线拟合函数的逻辑引入深度学习了,比那个版本要简单易懂得多。
本节就是引入部分。因此建议读者有逻辑回归和softmax基础。
逻辑回归用的是sigmoid函数,是softmax的一种二分类情况。具体的我也没搞清楚,就不写了。
- 深度学习的历史经历了一系列起起伏伏(蓝字为兴盛期,红字为衰落期)
1958年 提出线性感知器
1969年 提出线性感知器的局限性
1980年 提出多层感知器(已经类似于当代深度神经网络)
1986年提出反向传播算法
1989年 提出一层隐藏层就够了,不需要搞“深度”
2006年 发明RBM玻尔兹曼机(初始化梯度下降的方法,是一个非常复杂的graphical base模型。在对模型性能的提升上没什么用,但引起了大家对DL的兴趣)
2009年 应用GPU训练神经网络
2011年 在语音识别领域流行应用DL
2012年 DL方法赢得ILSVRC图像识别比赛

- 深度学习和机器学习一样分成三步走:定义函数集→定义函数优劣→选择最好的函数(和21版的 建立模型→定义损失函数→优化参数 是一回事,但是新版的更明确了优化参数的过程,更清晰了)

1.1 Step1:建立模型
- 将多个逻辑回归(一个逻辑回归就是一个神经元)连在一起,就组成了这样的神经网络:不同的连接方式就是不同的网络结构
神经网络中的参数 θ:所有神经元(逻辑回归)中的权重和偏置
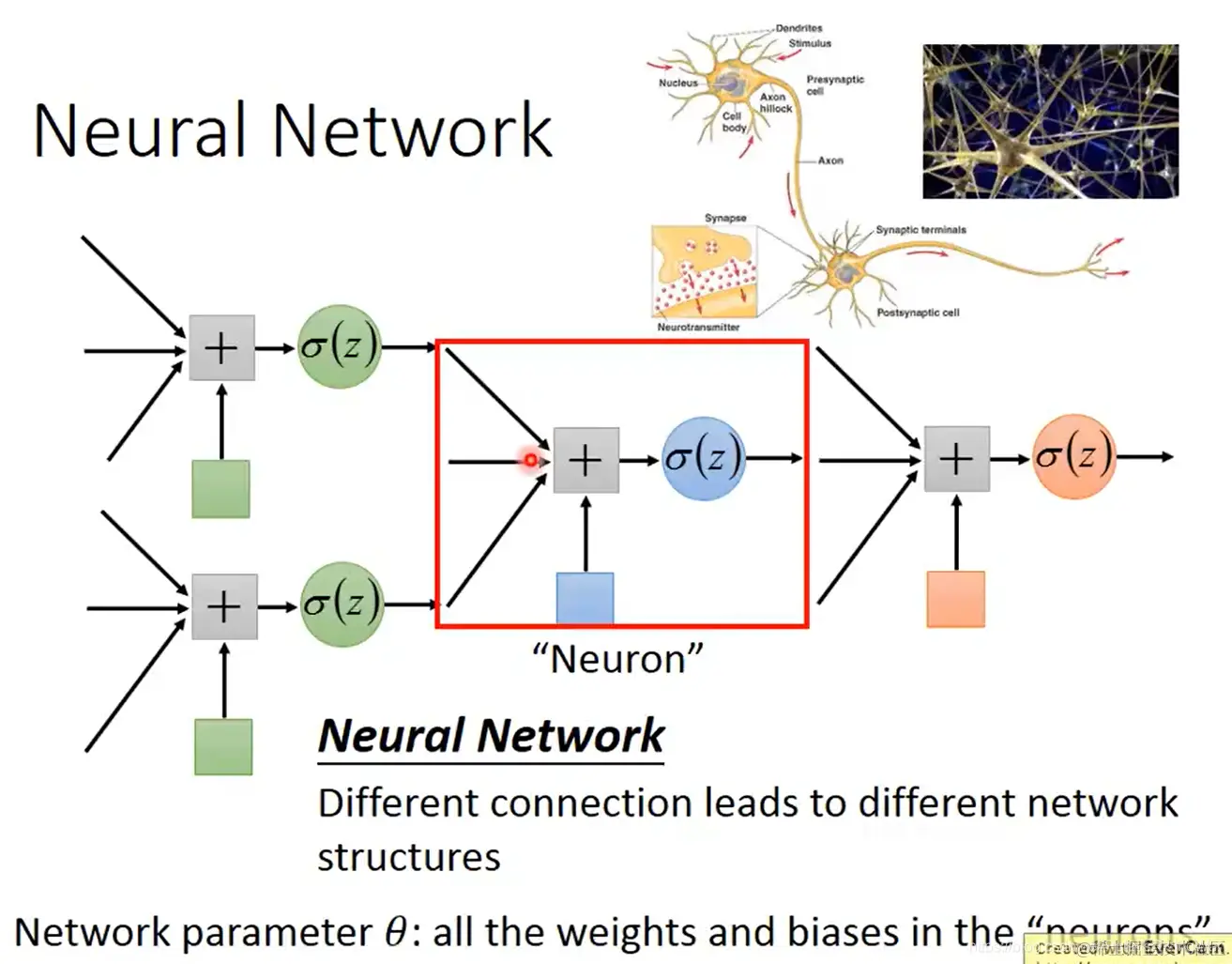
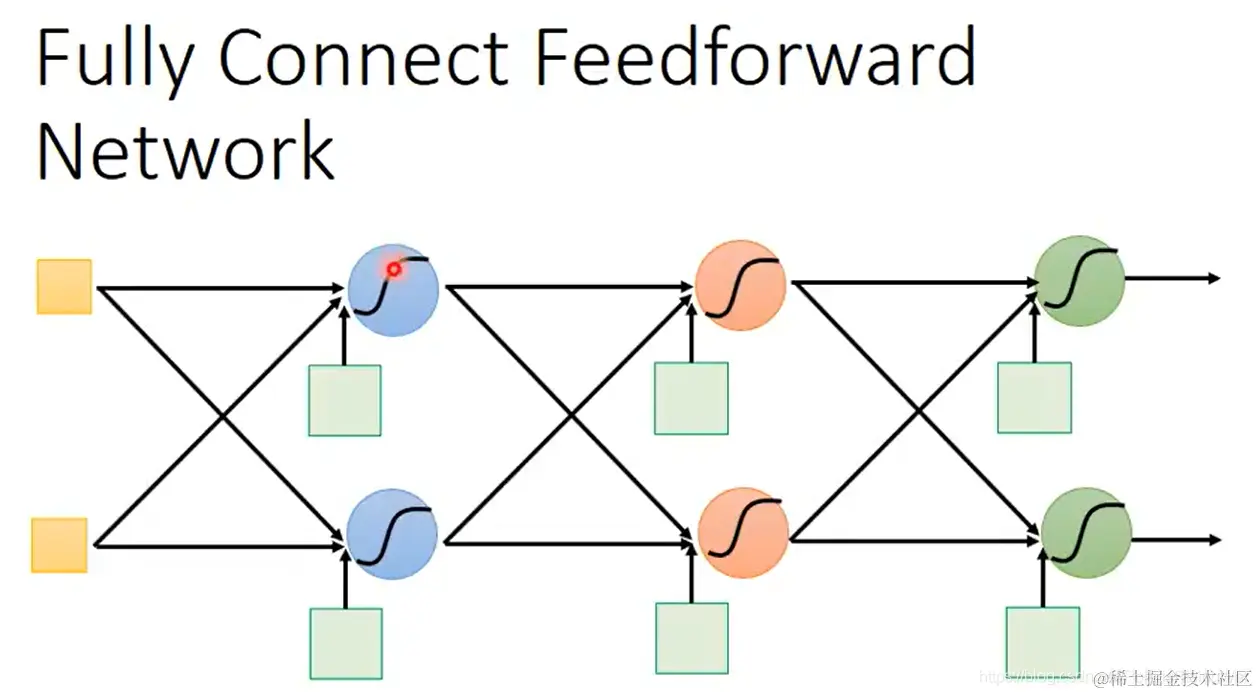
- 全连接网络,就是如图所示每一层所有神经元都与前后层所有神经元相连:
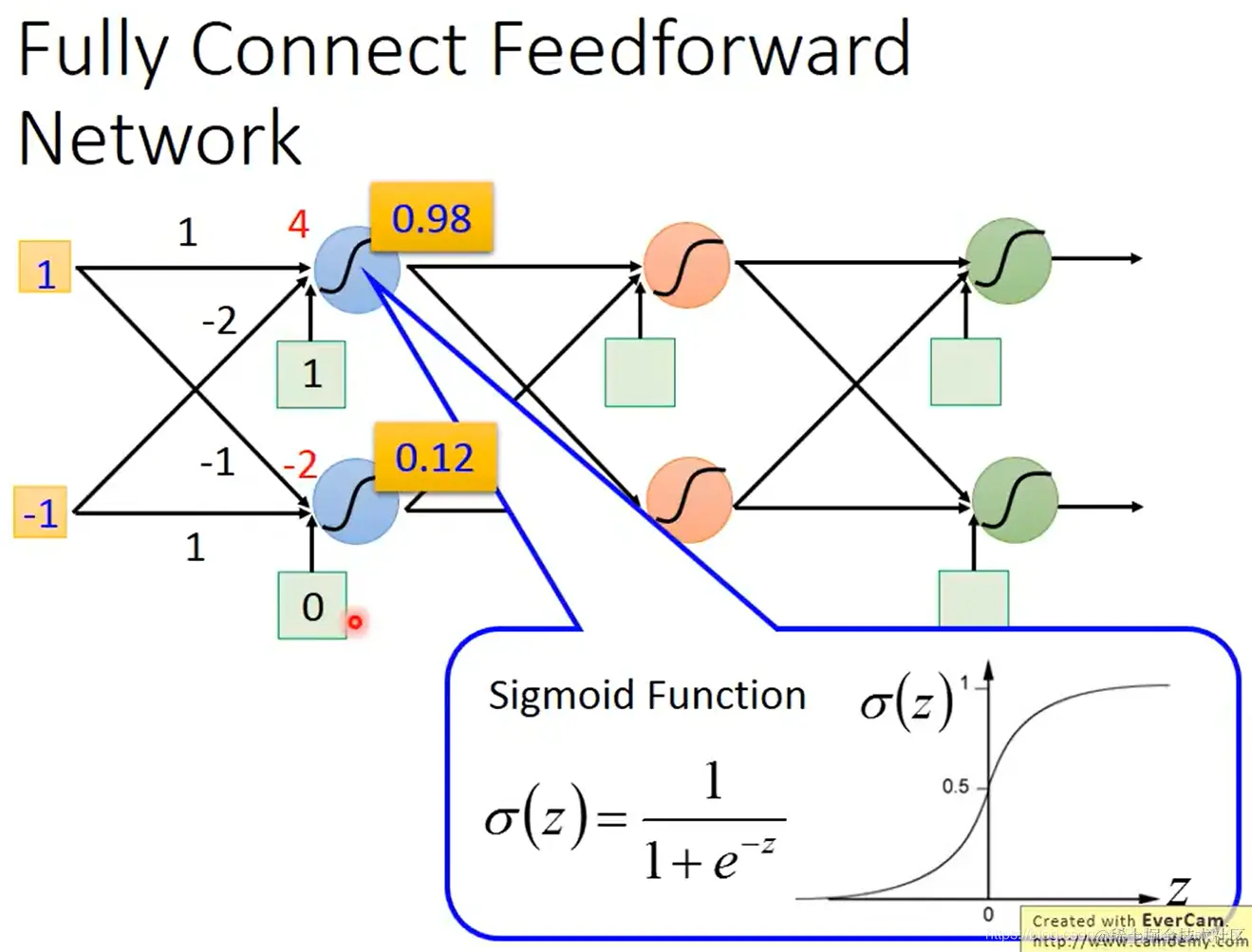
- 如图所示,每个神经元都有对应的权重、偏置,通过sigmoid函数得到输出值。
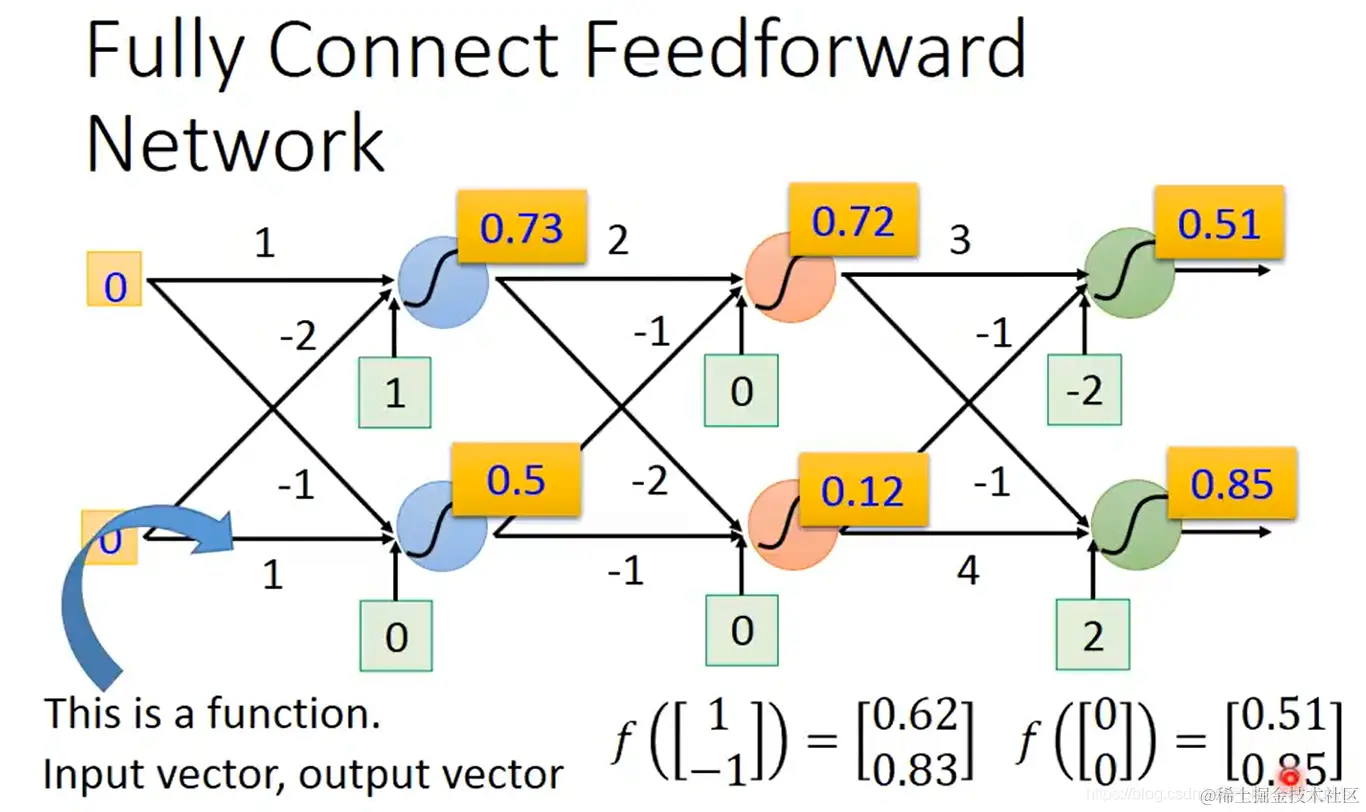
假如我们已知神经网络的参数,输入向量[1−1]
左上角第一个神经元的输出值为:sigmoid(1×1+(−1)×(−2)+1)=0.98。再将0.98作为下一层的输入。以此类推。最后得到输出[0.620.83]。
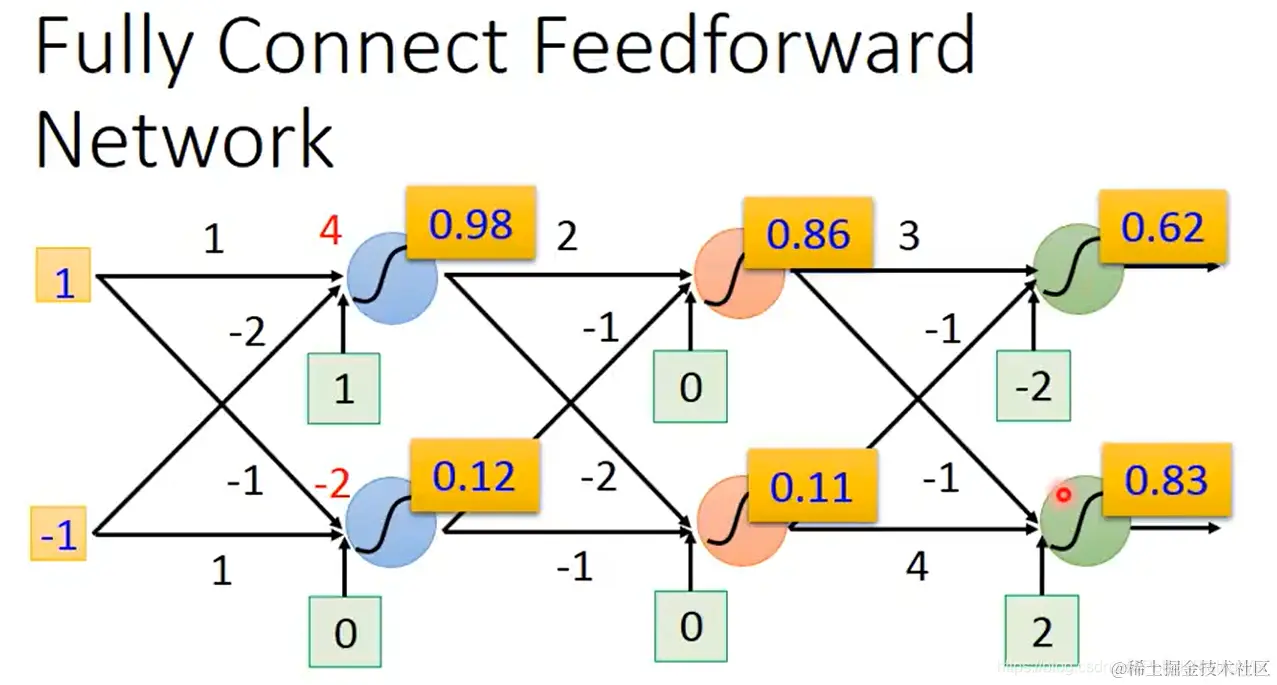
- 输入[00]向量也可以得到一个输出:[0.510.85]
从而,整个全连接网络可以写成一个输入输出都是向量的大函数:
f[1−1]=[0.620.83] f[00]=[0.510.85]
- 对于不知道参数的模型,就是一个可以优化参数、通过损失函数定义来找到最优函数(最优参数)的函数集。
全连接前馈网络结构如图所示,就是这样一个模型:
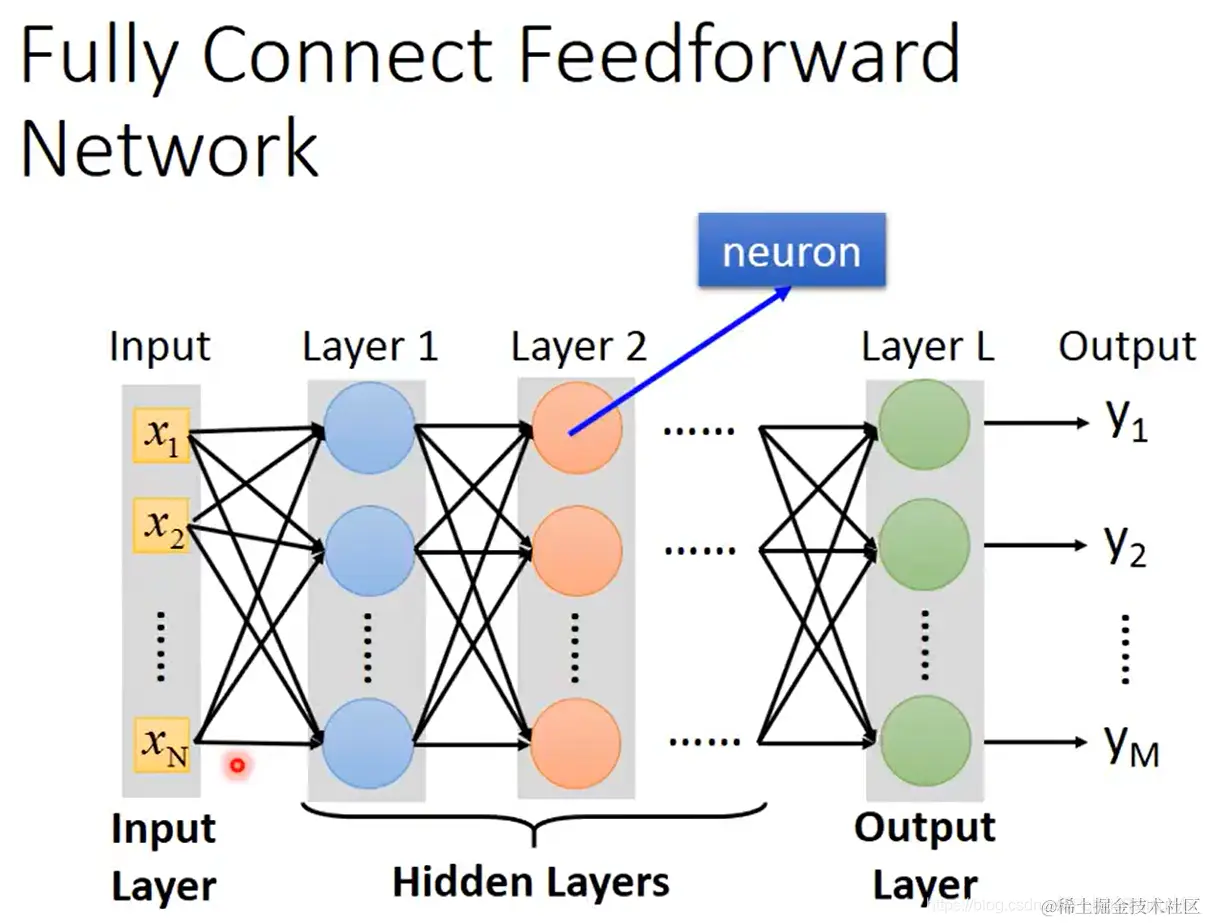 网络由输入层、隐藏层、输出层构成。
(其实输入层不算一层,因为没有神经元;但是我们也把它称呼为一层)
网络由输入层、隐藏层、输出层构成。
(其实输入层不算一层,因为没有神经元;但是我们也把它称呼为一层)
- 深度神经网络深就深在有很多层。
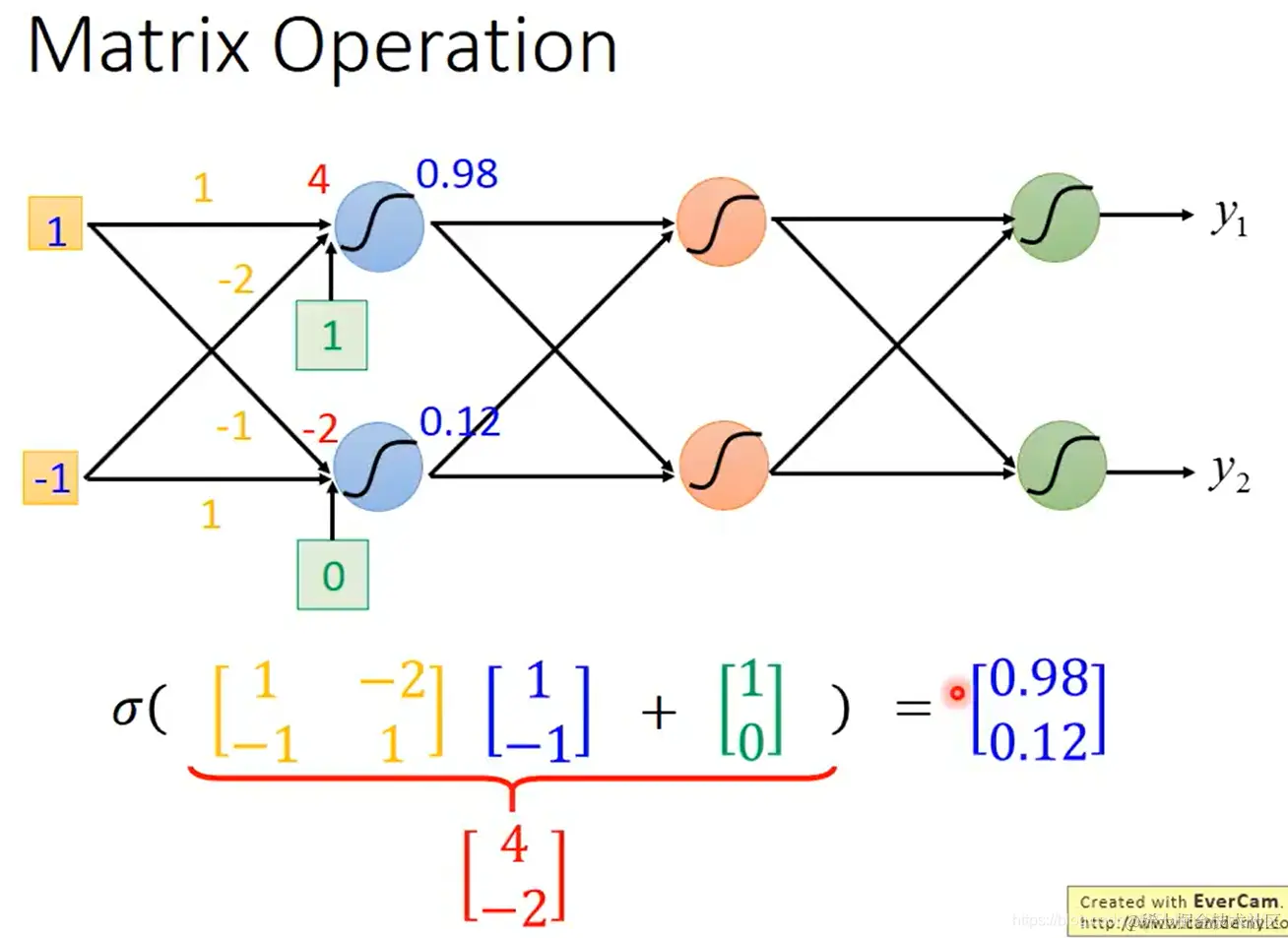
- 可以用矩阵运算来表示全连接网络的计算过程。单层:
- 整个神经网络,所有层:
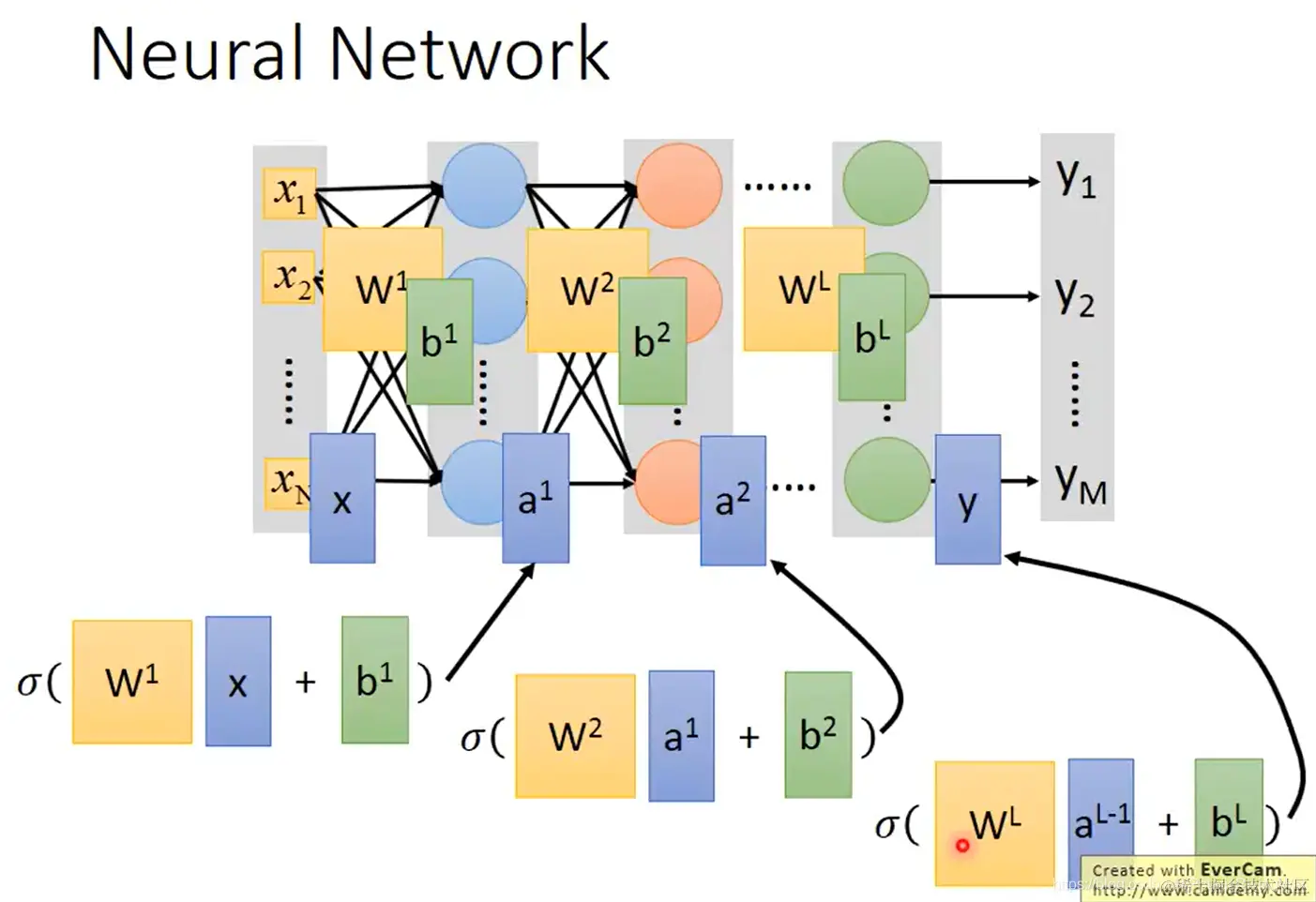
- 整个神经网络的函数 f(x) 就可以表示为:
 可以通过平行计算技术来加速矩阵运算(GPU就是在矩阵运算时用的)
可以通过平行计算技术来加速矩阵运算(GPU就是在矩阵运算时用的)
- 神经网络的输出层,如果是多标签分类任务,可以使用softmax输出一个概率分布。
隐藏层实现了特征抽取工作,相当于代替了传统机器学习中的特征工程任务。
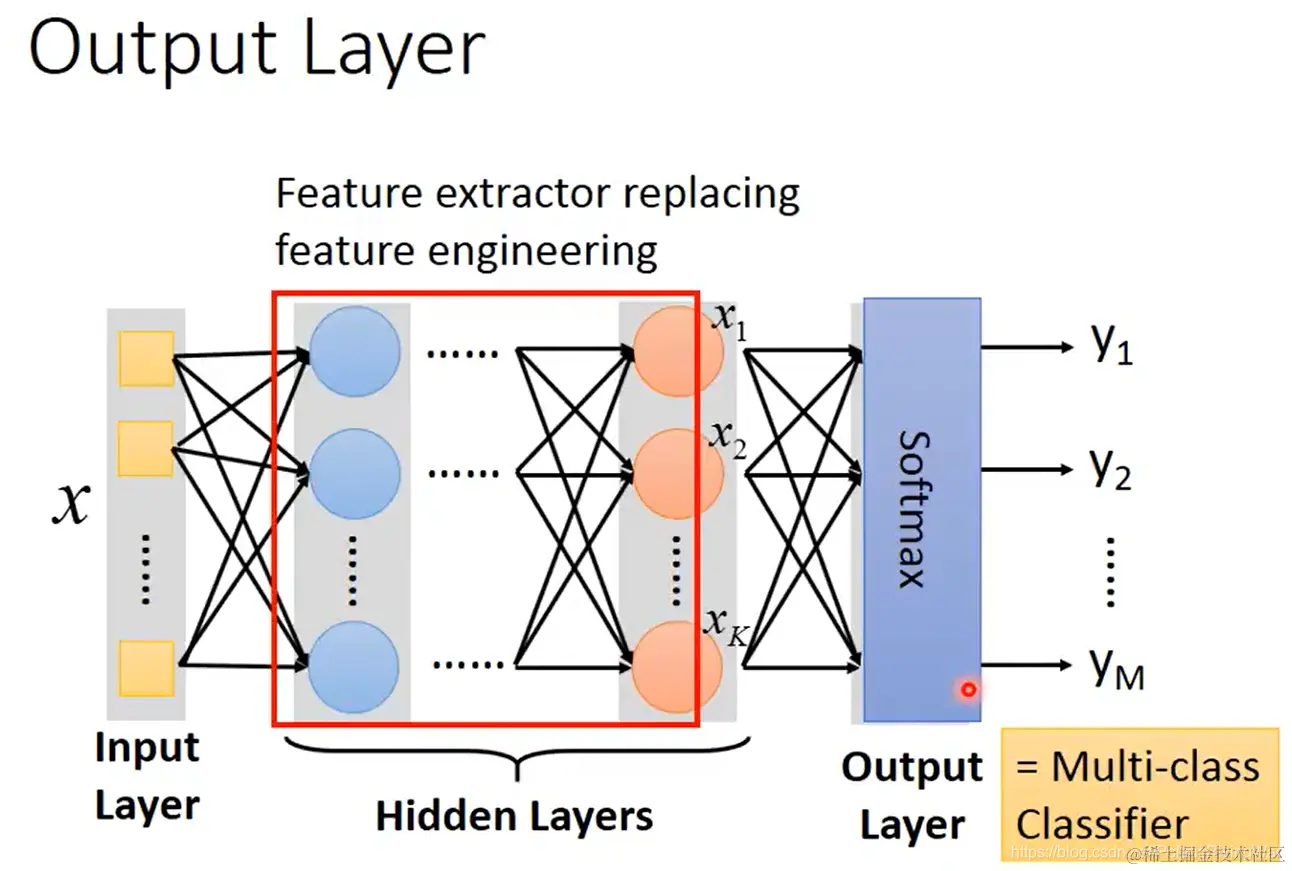
- 举例:手写数字识别任务
- 输入一张图片(表示为像素向量的格式),输出这张图片代表哪个数字(一个独热编码向量,该数字对应索引位置的元素置1、其他元素置0)

- 选择一个神经网络模型,输入图像数据
(注意,需要定义一个存在好函数的函数集)
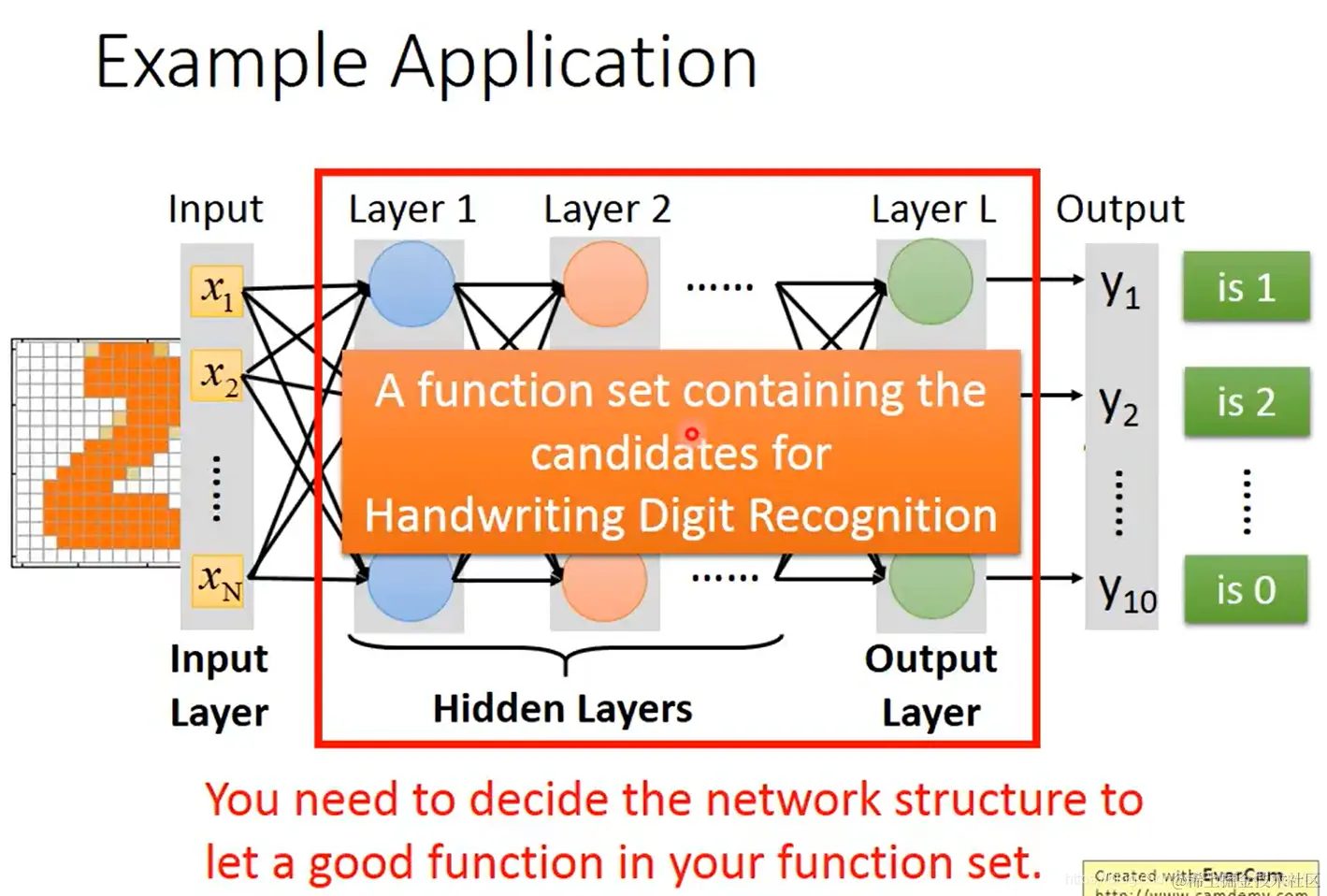
- 深度学习的好处在于不需要做过多的特征转换,比如影像识别任务可以直接将像素图作为输入进行训练;但与此同时,深度学习需要自己设计网络结构,设计出一个含有好函数的函数集(模型)。
因此,可以说,从机器学习到深度学习,就是将难点从如何抽取特征变成如何设计网络结构。
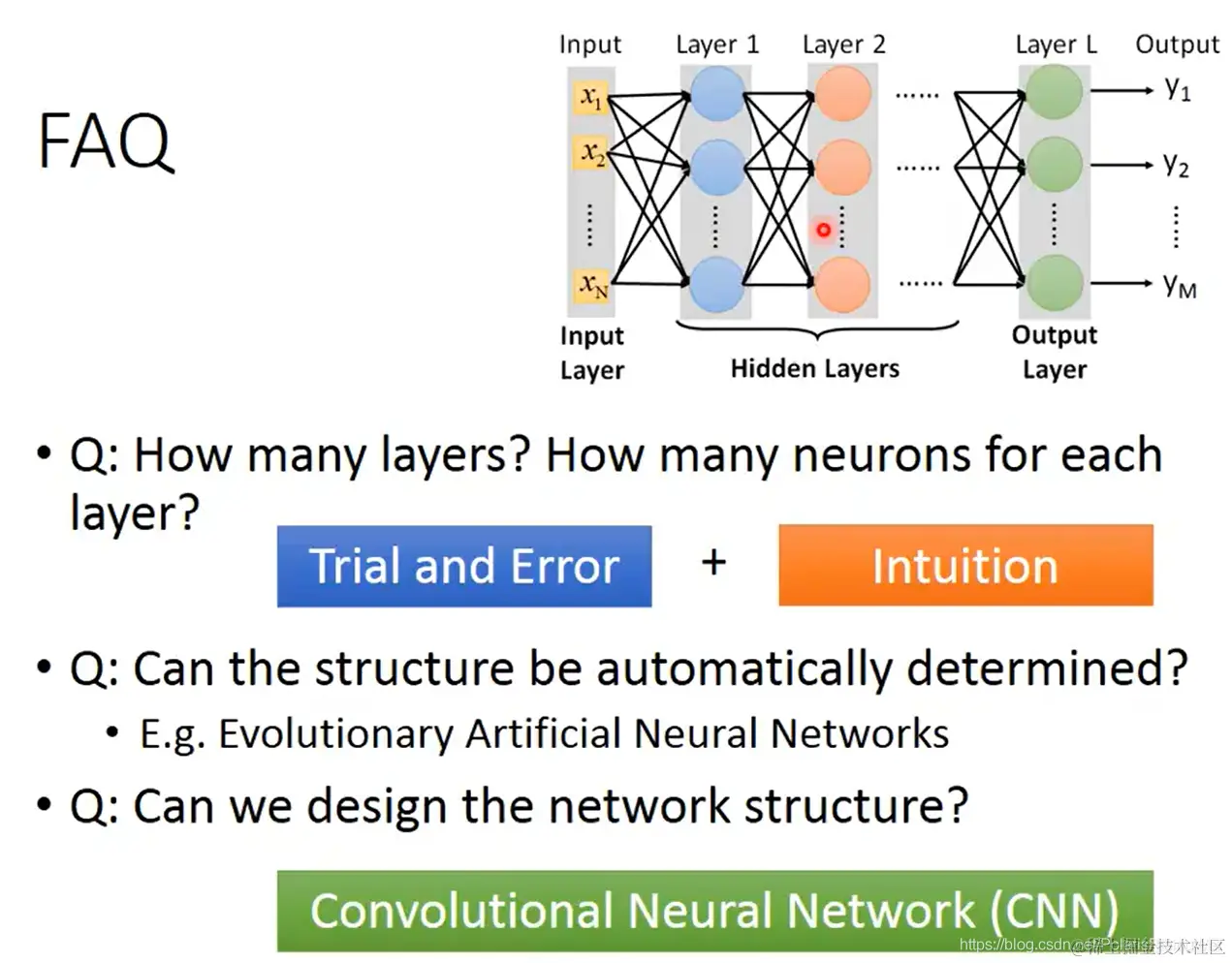
- Q:这个网络需要多少层?——A:凭多次实验和经验直觉。
Q:这个网络结构可以自动生成吗?——A:可以,比如用演化算法(evolutionary artificial neural networks (EANNs))。但是这种做法不常用。1
Q:除了全连接网络,我们还能定义别的网络结构吗?——A:可以,比如卷积神经网络CNN(后期课程会讲)。
1.2 Step2:定义函数优劣(损失函数)
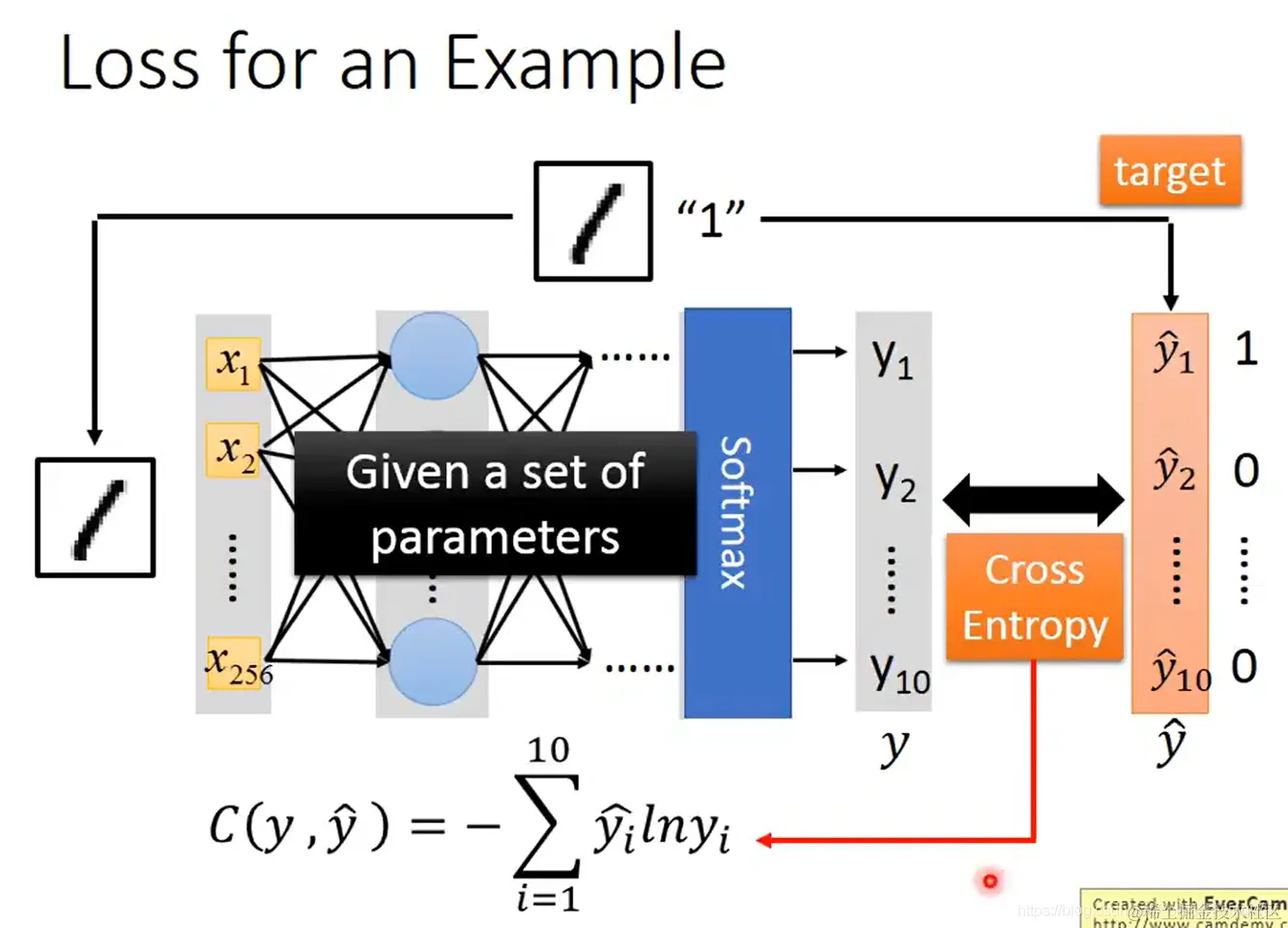
- 手写数字识别任务(分类任务)的示例损失函数:已知参数,通过模型得到输入数据的输出值 y;已知真实值(标签) y^:
交叉熵 C(y,y^)=−i=1∑10yi^lnyi
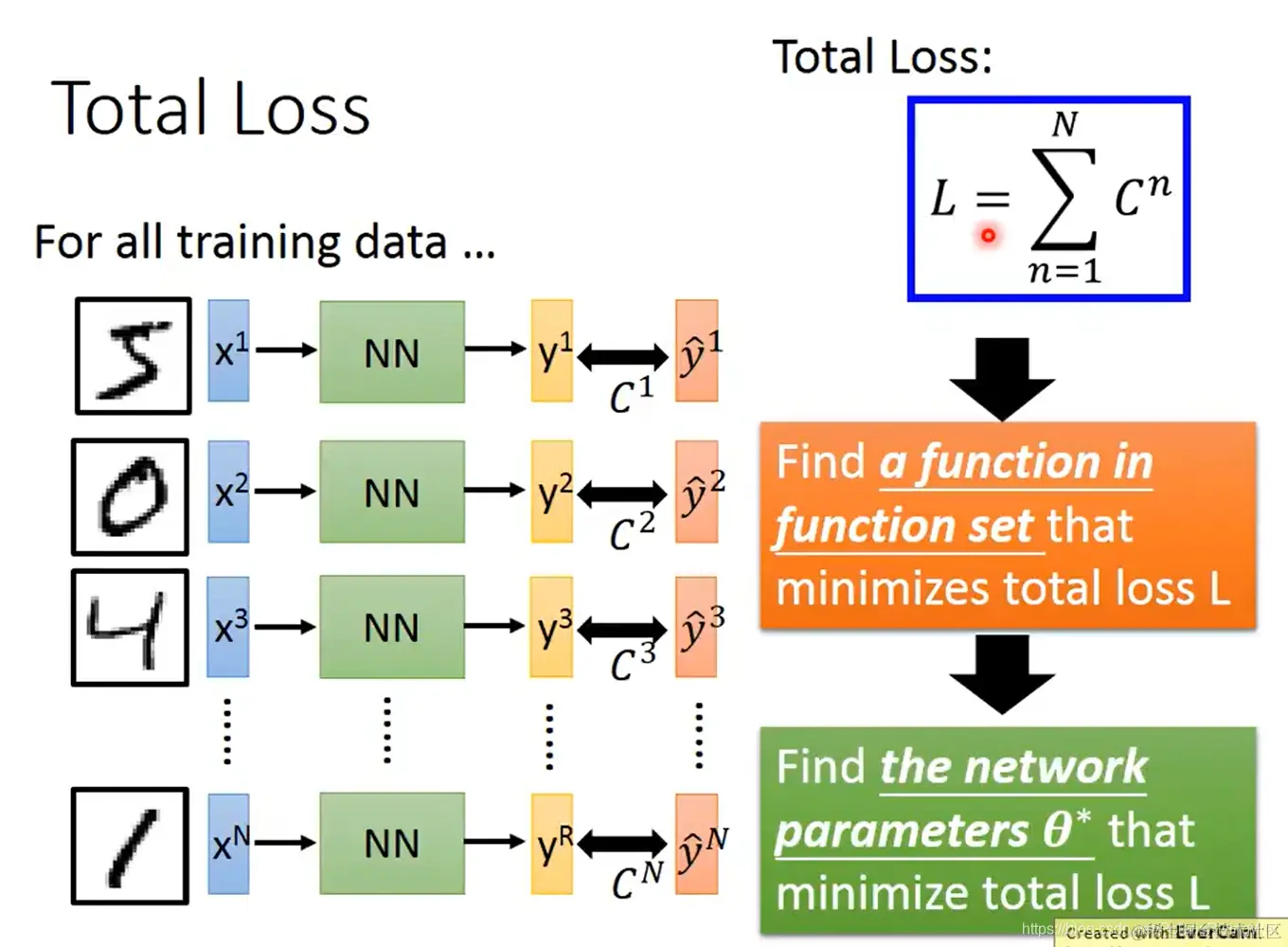
- 在所有训练数据上的损失函数,即将每个数据上的损失函数加总:L=n=1∑NCn
我们所要做的,就是在函数集(模型)里找到使总损失函数 L 最小的函数,也就是找到使 L 最小的参数集。
1.3 Step3:选择最好的函数(优化参数)
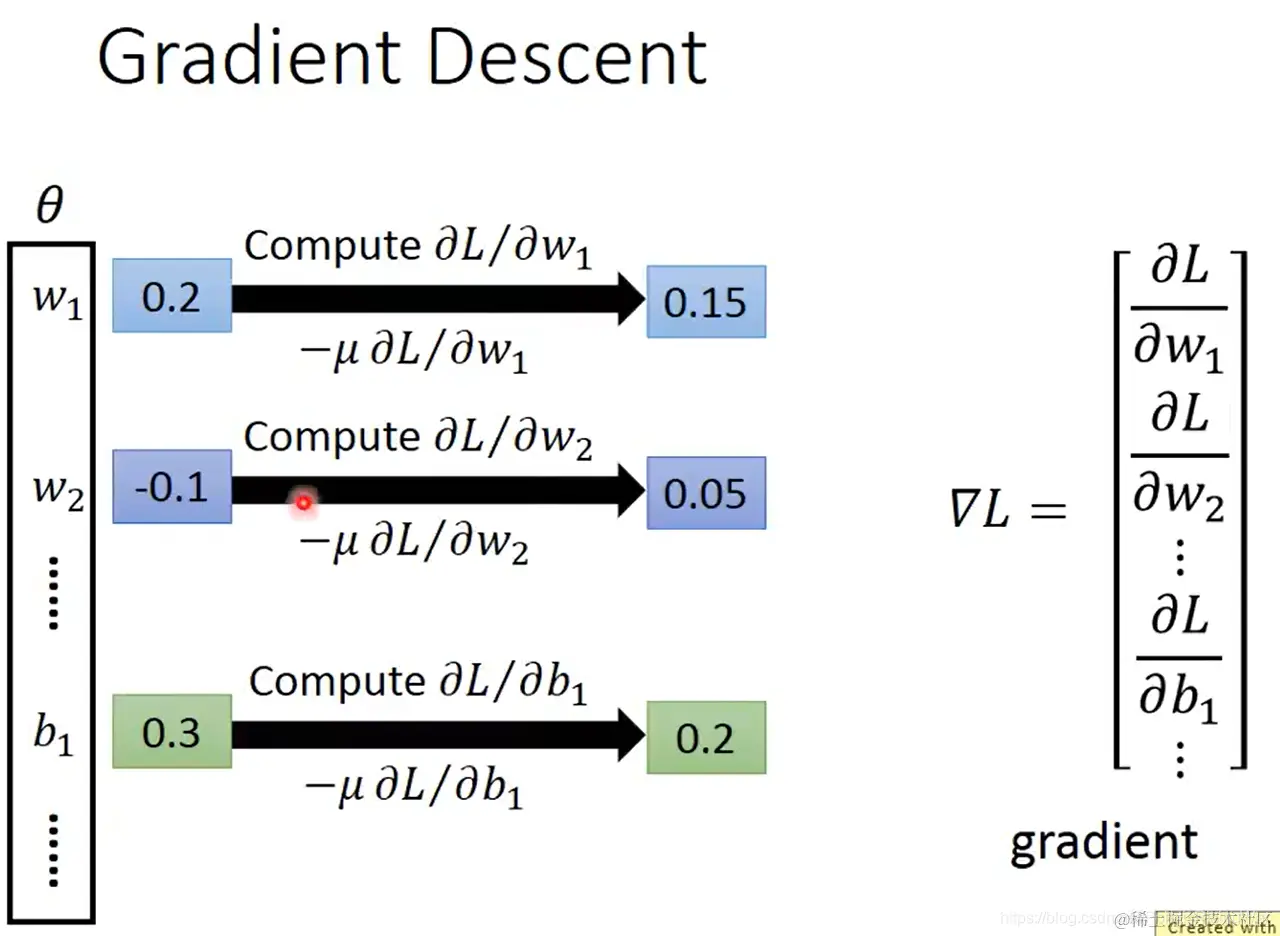
- 使用梯度下降法
梯度就是损失函数在每个参数上的偏微分 ∂L/∂w1,组成向量。对每个参数,每次先求导,然后将参数增加 −μ ∂L/∂w1(μ 是学习率),直至结束。

- 反向传播:一种在神经网络中计算梯度的有效方法(各深度学习框架都内置计算方法,编程时不用手动算)

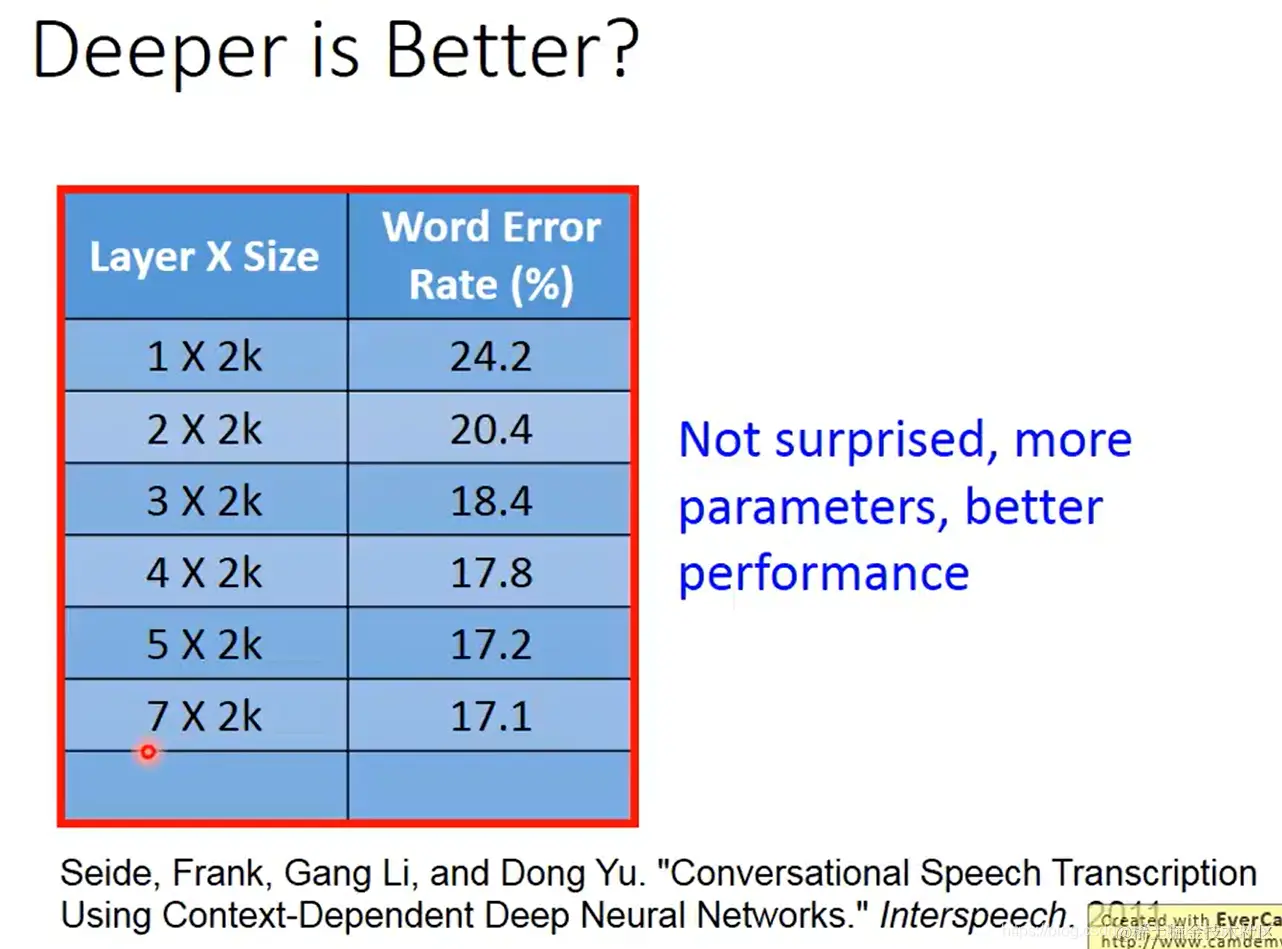
- 在实践中,神经网络越深(在不增加单层神经元数量的情况下)确实表现越好:
- universality theorem2:单层神经网络,只要神经元够多,可以拟合任何连续函数 f:RN→RM
 图中网址:neuralnetworksanddeeplearning.com/chap4.html
图中网址:neuralnetworksanddeeplearning.com/chap4.html
- 其他建议学习资料:
- 15版课程
- 15版课程-6小时版 (这是个2016年的PPT,slideshare网站可能不方便上,如有需要可以联系我下下来放到GitHub之类的平台上以供下载)
- Neural Networks and Deep Learning
- Deep Learning
2. 反向传播
- 网络中的参数:θ={w1,w2,⋯,b1,b1,⋯}
随着梯度下降,参数更新的过程为:θ0→θ1→θ2→⋯⋯
∇L(θ)=⎣⎡∂L(θ)/∂w1∂L(θ)/∂w2⋮∂L(θ)/∂b1∂L(θ)/∂b2⋮⎦⎤
每次迭代:首先计算 ∇L(θn),然后计算 θn+1=θn−μ∇L(θn)
为了高效计算梯度,需要使用反向传播算法

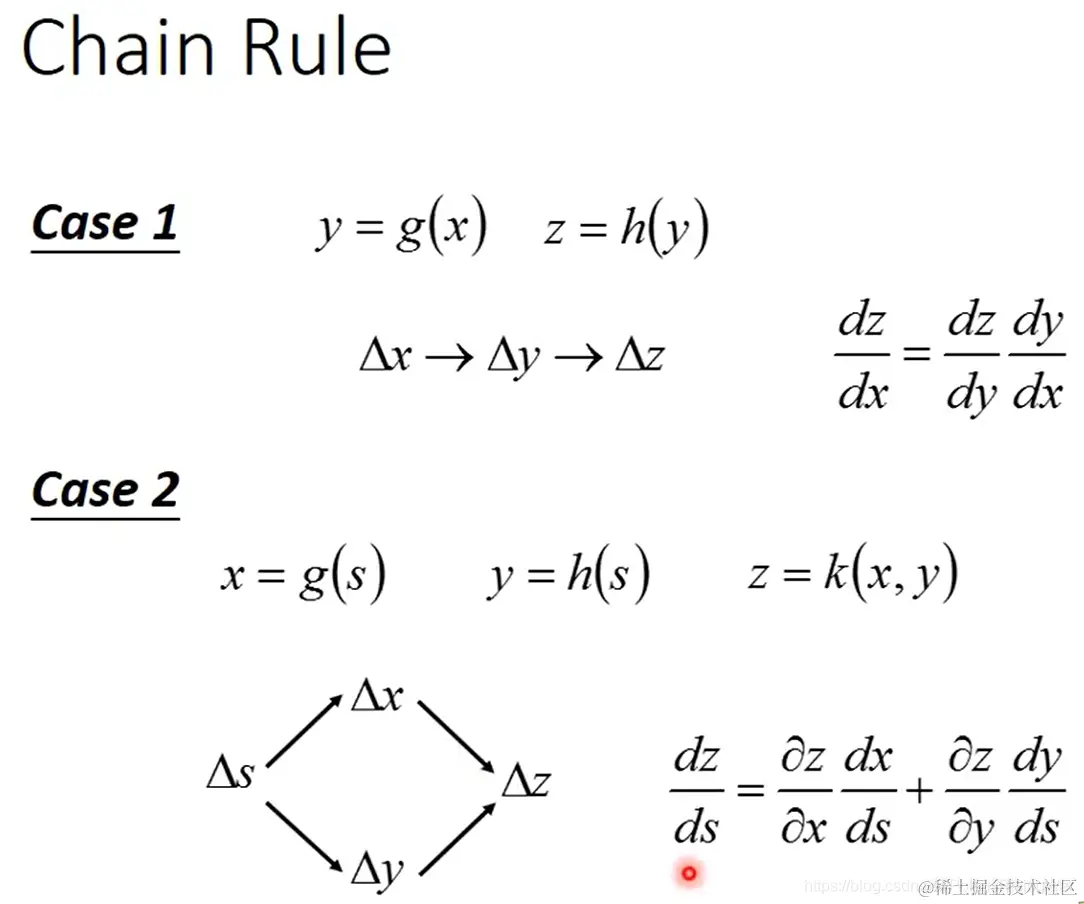
- 链式法则:
若 y=g(x),z=h(y),则其影响链是:Δx→Δy→Δz
公式为:dxdz=dydzdxdy
若x=g(s),y=h(s),z=k(x,y),则其影响链是: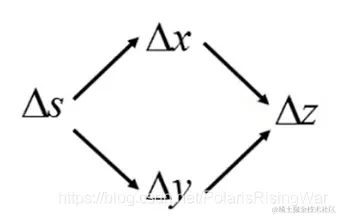 公式为:dsdz=∂x∂zdsdx+∂y∂zdsdy
公式为:dsdz=∂x∂zdsdx+∂y∂zdsdy
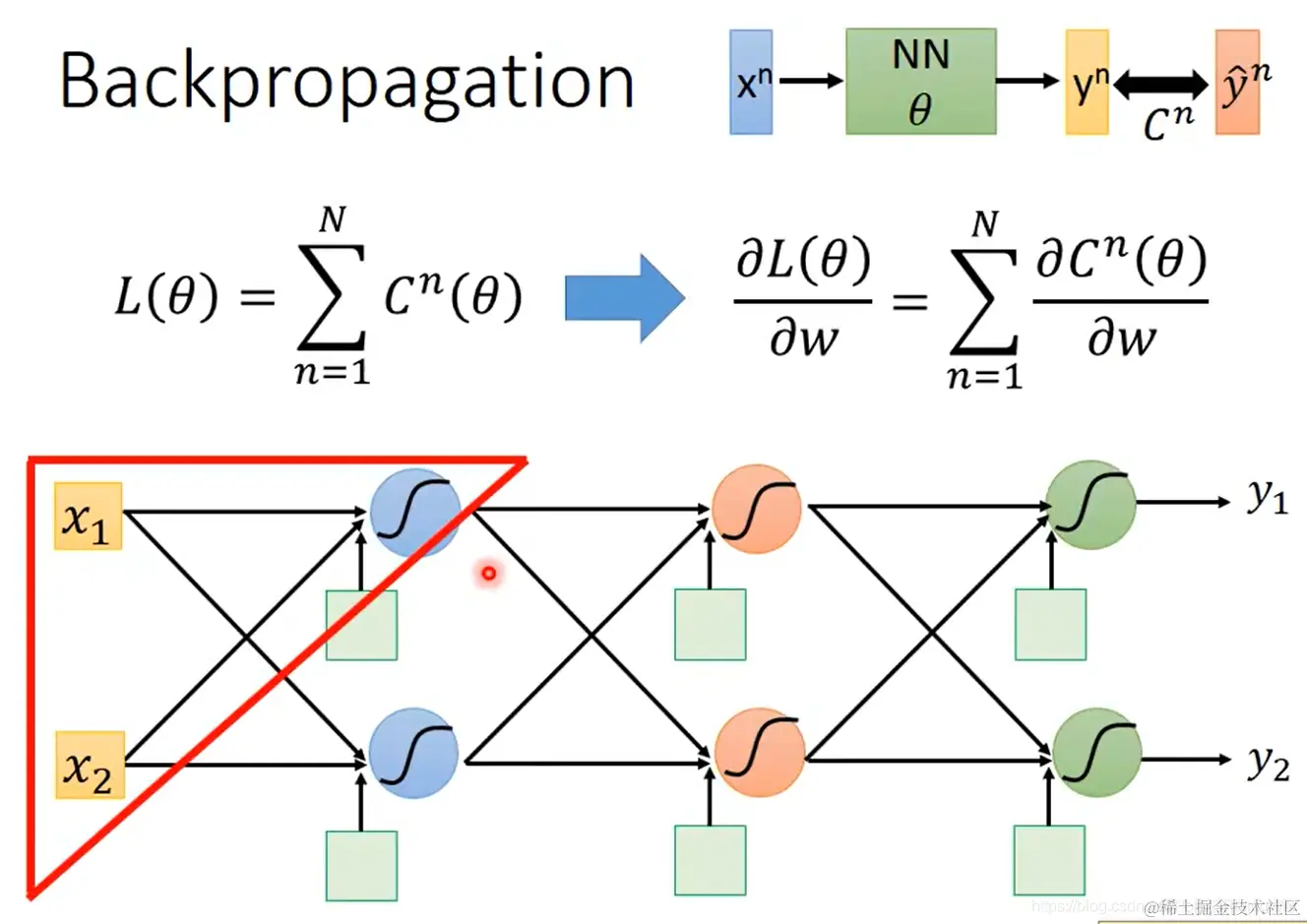
- 神经网络的结构是输入 xn,经网络NN(含参数 θ),输出 yn,与真实值 y^n 作比较得到误差 Cn,在数据集上求和得到损失函数 L(θ)=n=1∑NCn(θ)。
更新参数时使用损失函数对参数的偏导数:∂w∂L(θ)=n=1∑N∂w∂Cn(θ)。
以下介绍时首先以图中红色三角形内的神经元参数作为示例:
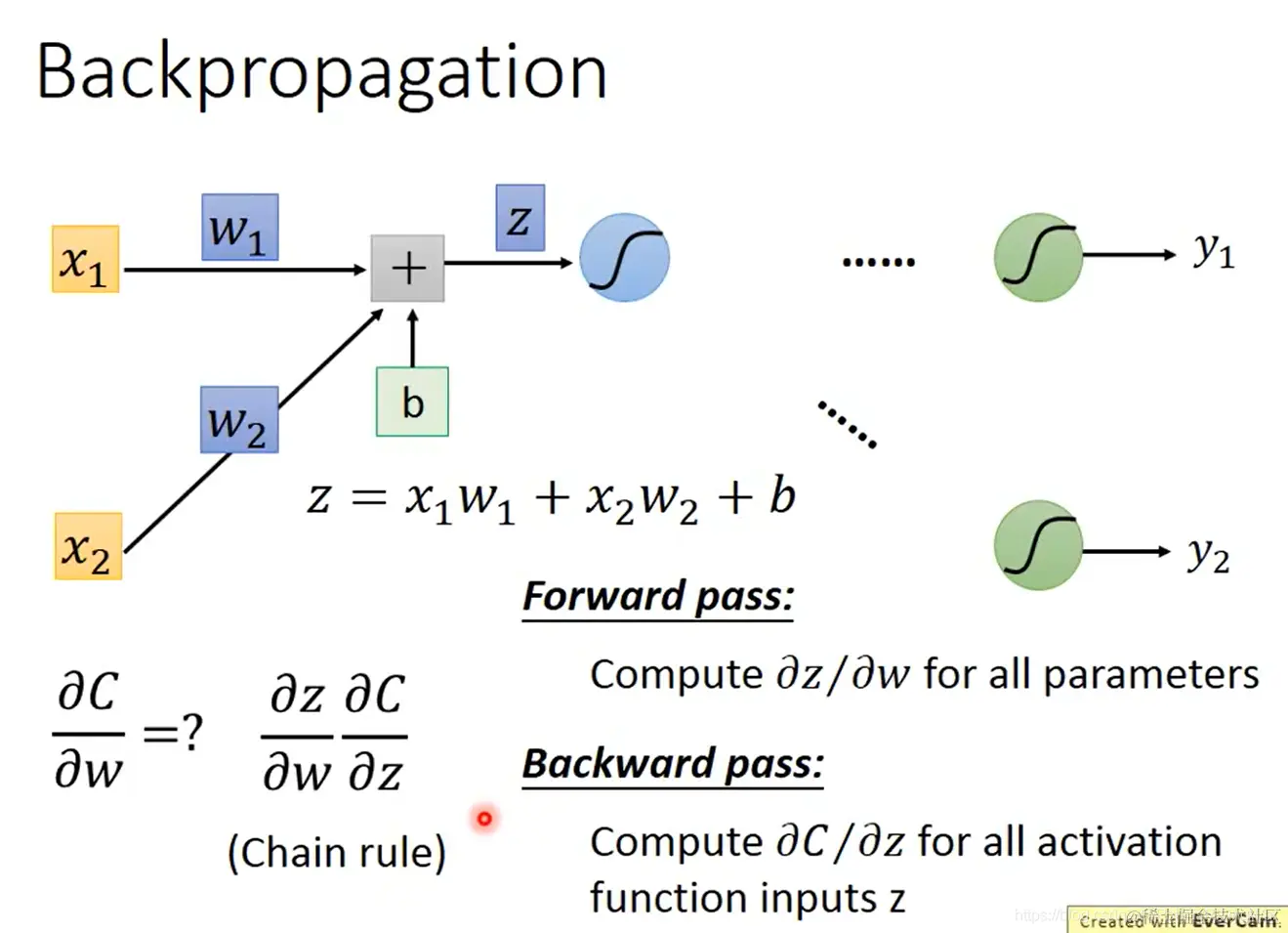
- 这个小三角的运算公式为:z=x1w1+x2w2+b
由链式法则可知,∂w∂C 的值取决于各个 ∂w∂z∂z∂C 的值。而分别对这两个值的计算分成如下两个步骤:
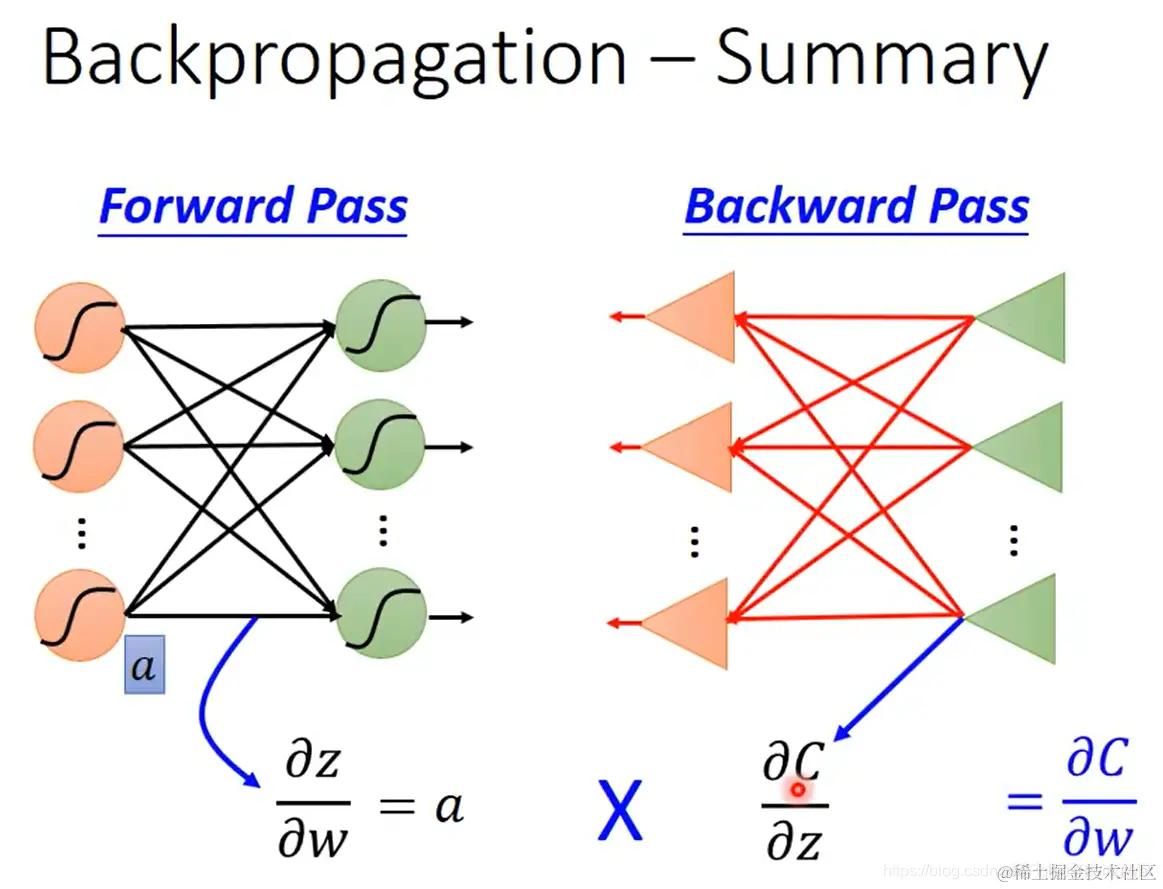
forward pass:对所有参数,计算 ∂w∂z
backward pass:对所有激活函数的输入值 z,计算 ∂z∂C
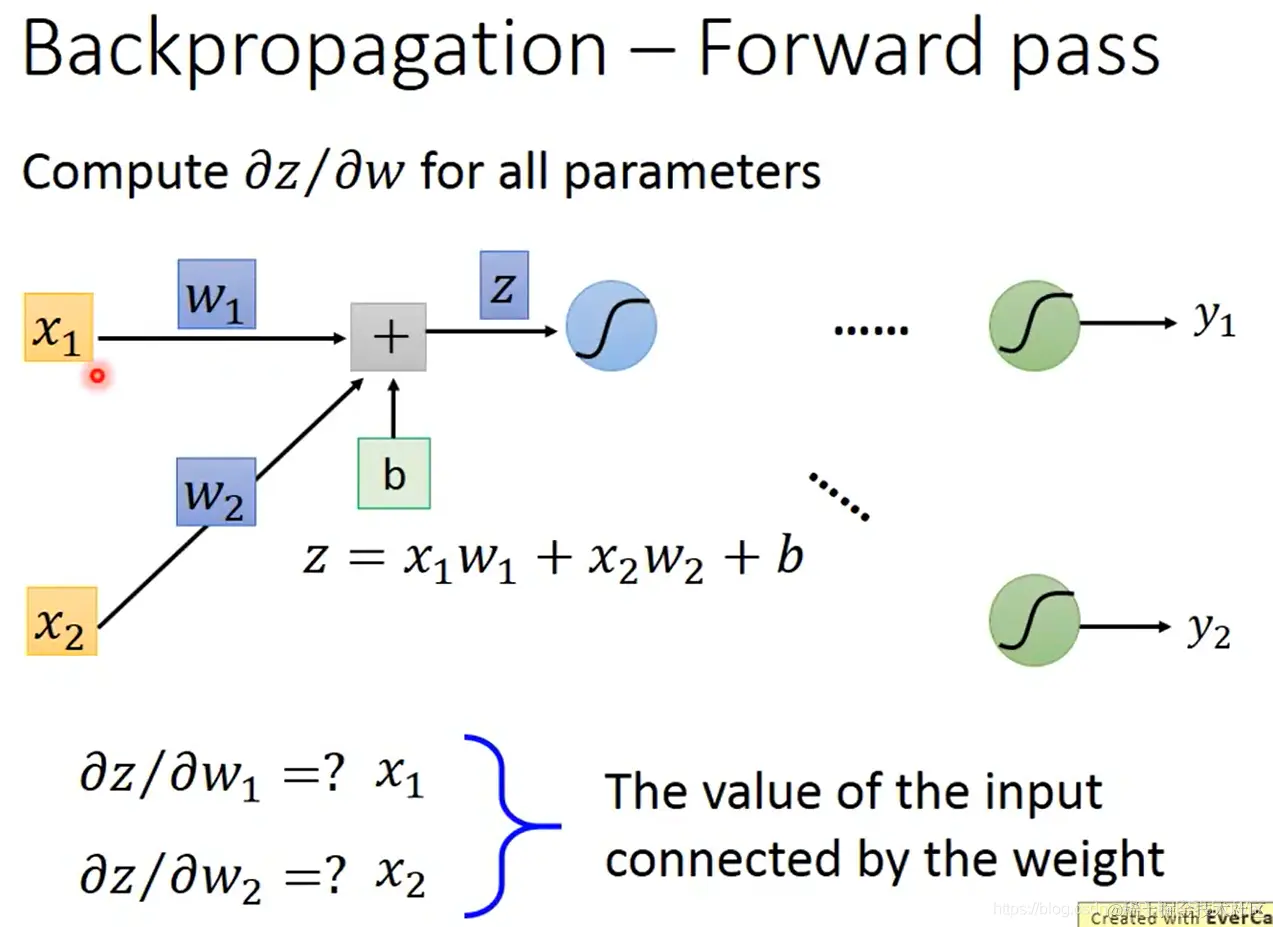
- 首先计算好算的 ∂w∂z:就是对应的输入 x
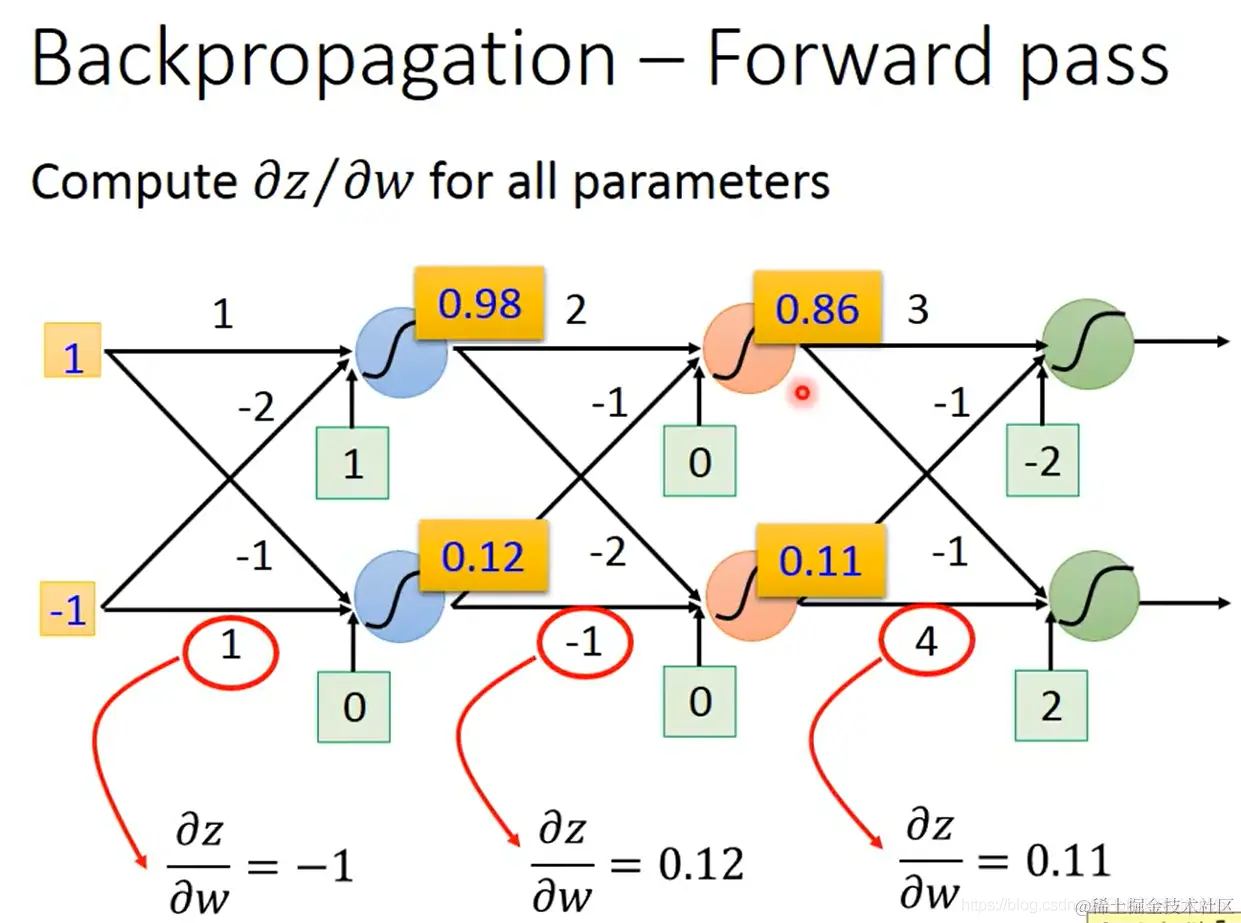
- 对于难算的 ∂z∂C:
a=σ(z)
由链式法则得:∂z∂C=∂z∂a∂a∂C
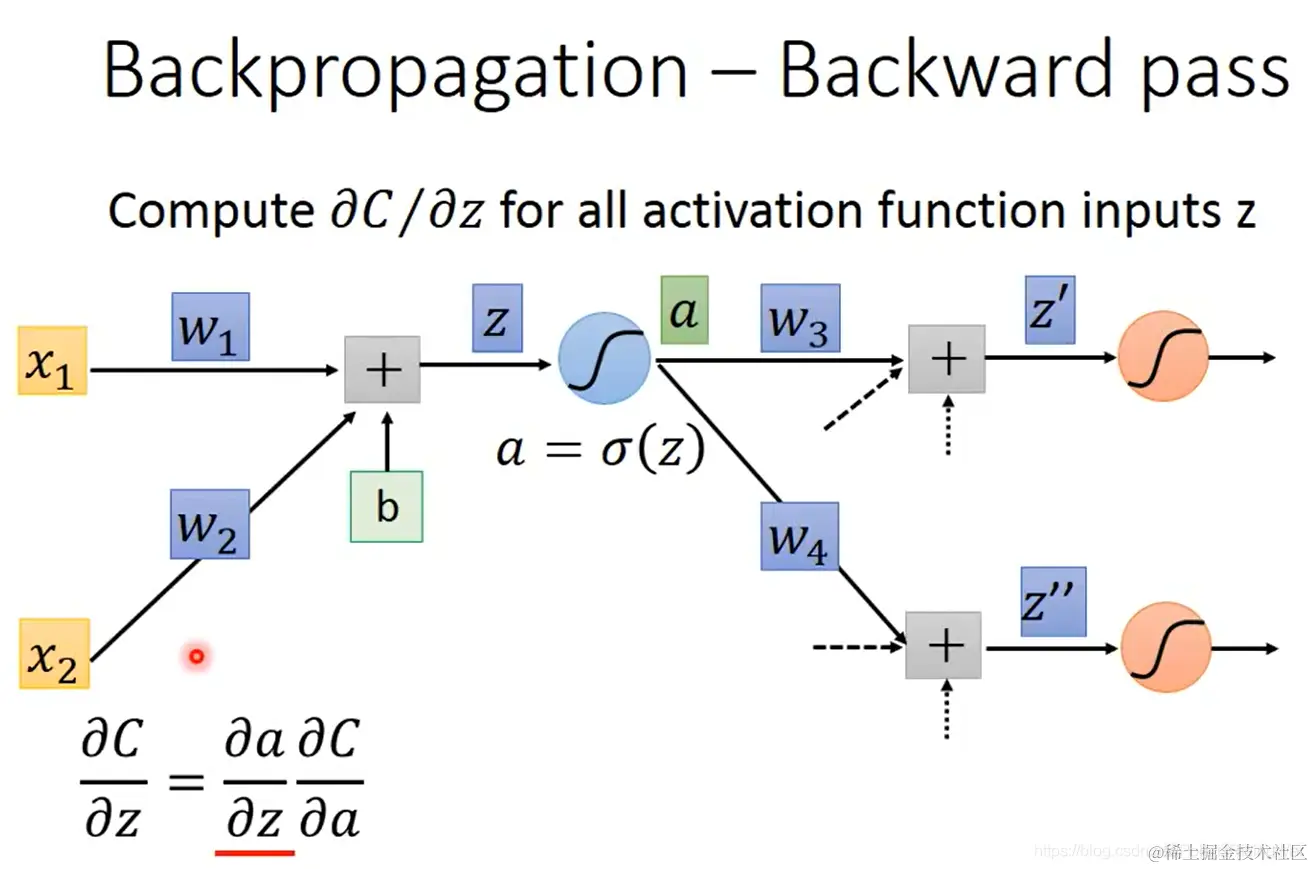
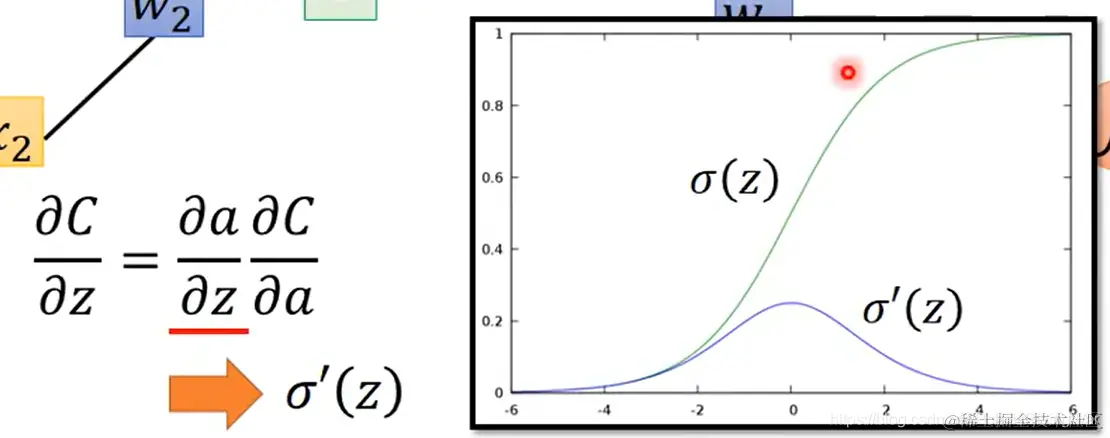
- 对等式右侧的两个分式,其中 ∂z∂a 也很好算,就是 σ′(z)
- 然后我们计算 ∂a∂C:
这就需要下一层神经元的激活函数输入 z′ 和 z′′:∂a∂C=∂a∂z′∂z′∂C+∂a∂z′′∂z′′∂C
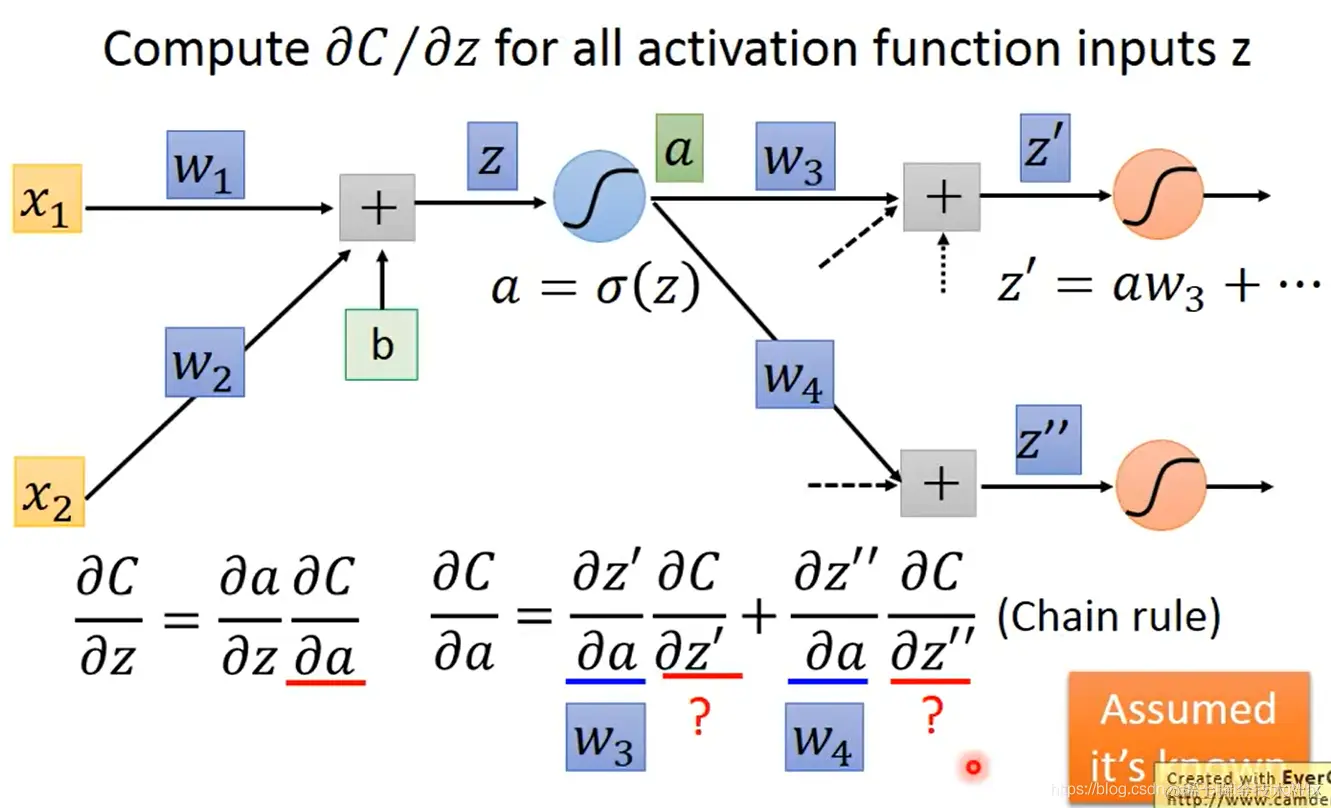
∂a∂z′=w3,∂a∂z′′=w4 都容易计算。
我们发现在这里的计算又需要 ∂z′∂C 和 ∂z′′∂C,所以我们首先假设我们已经计算出了这两个值。
这样 ∂z∂C 就能计算出来了:∂z∂C=σ′(z)[w3∂z′∂C+w4∂z′′∂C]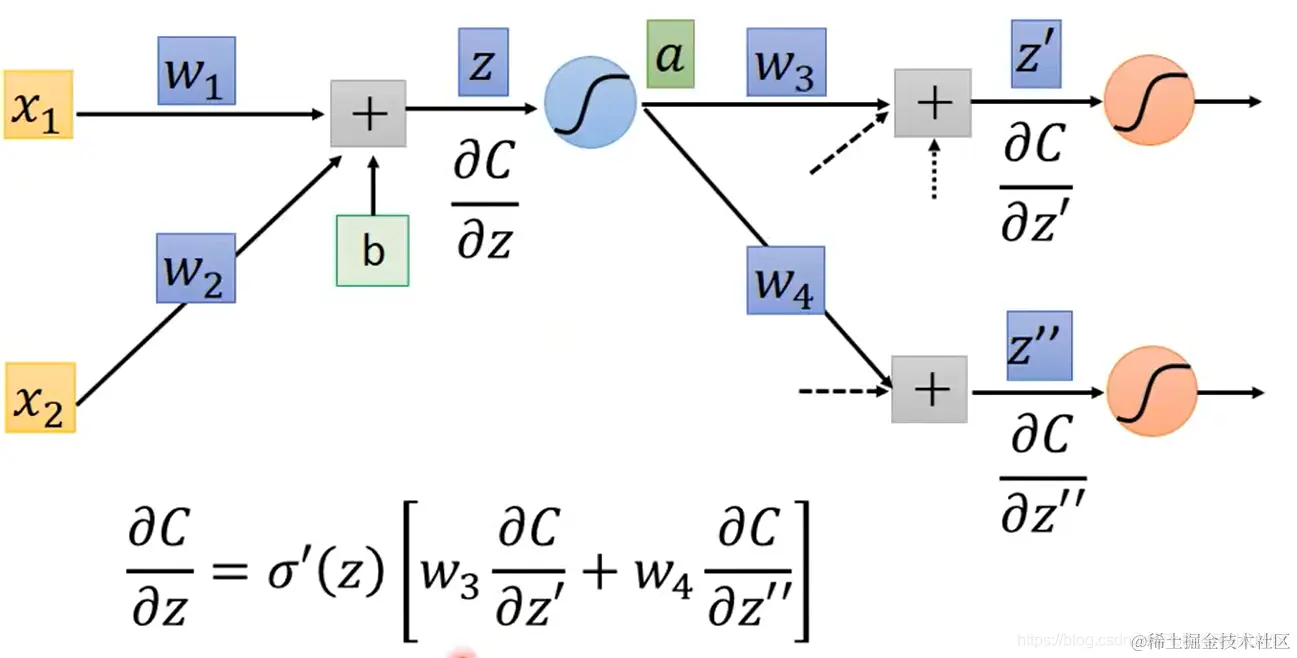
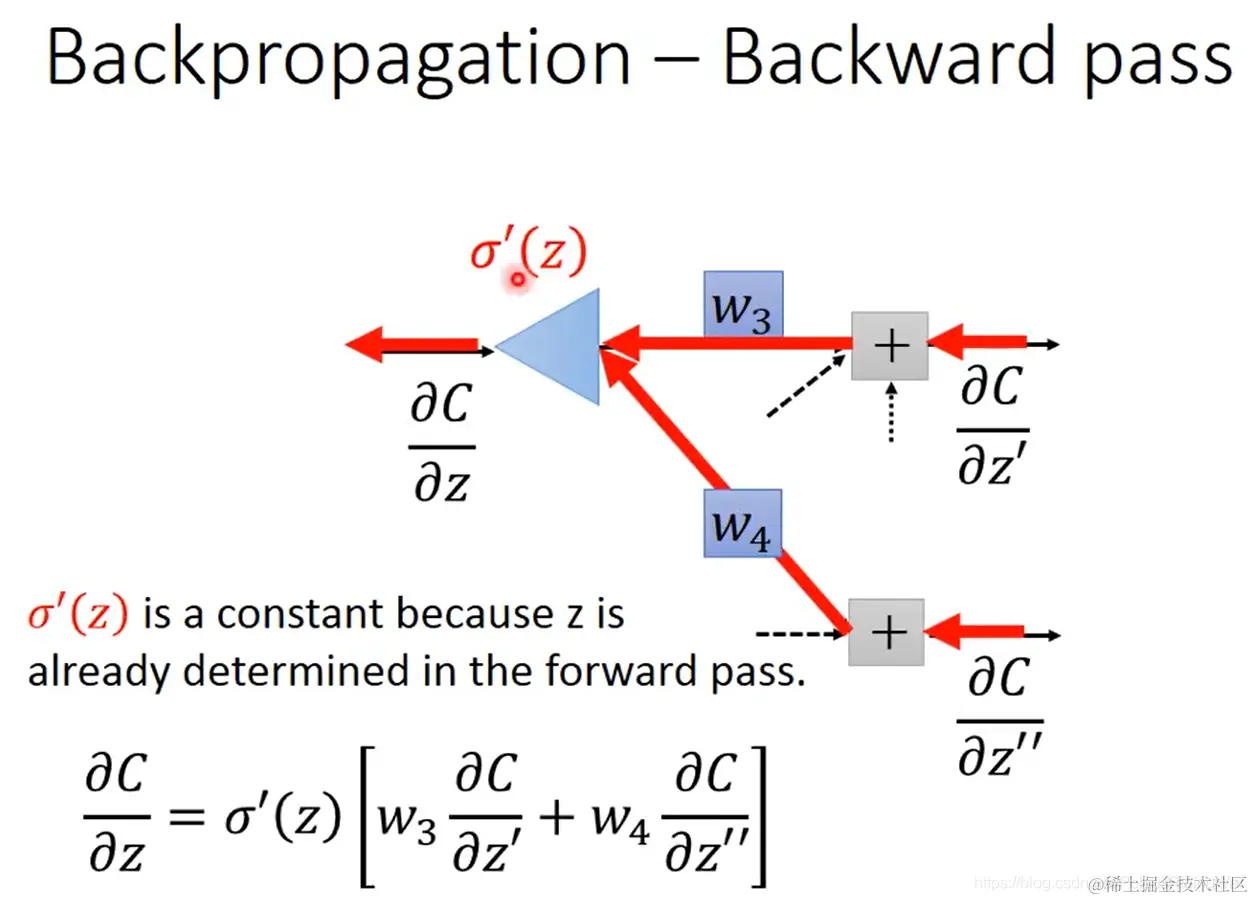
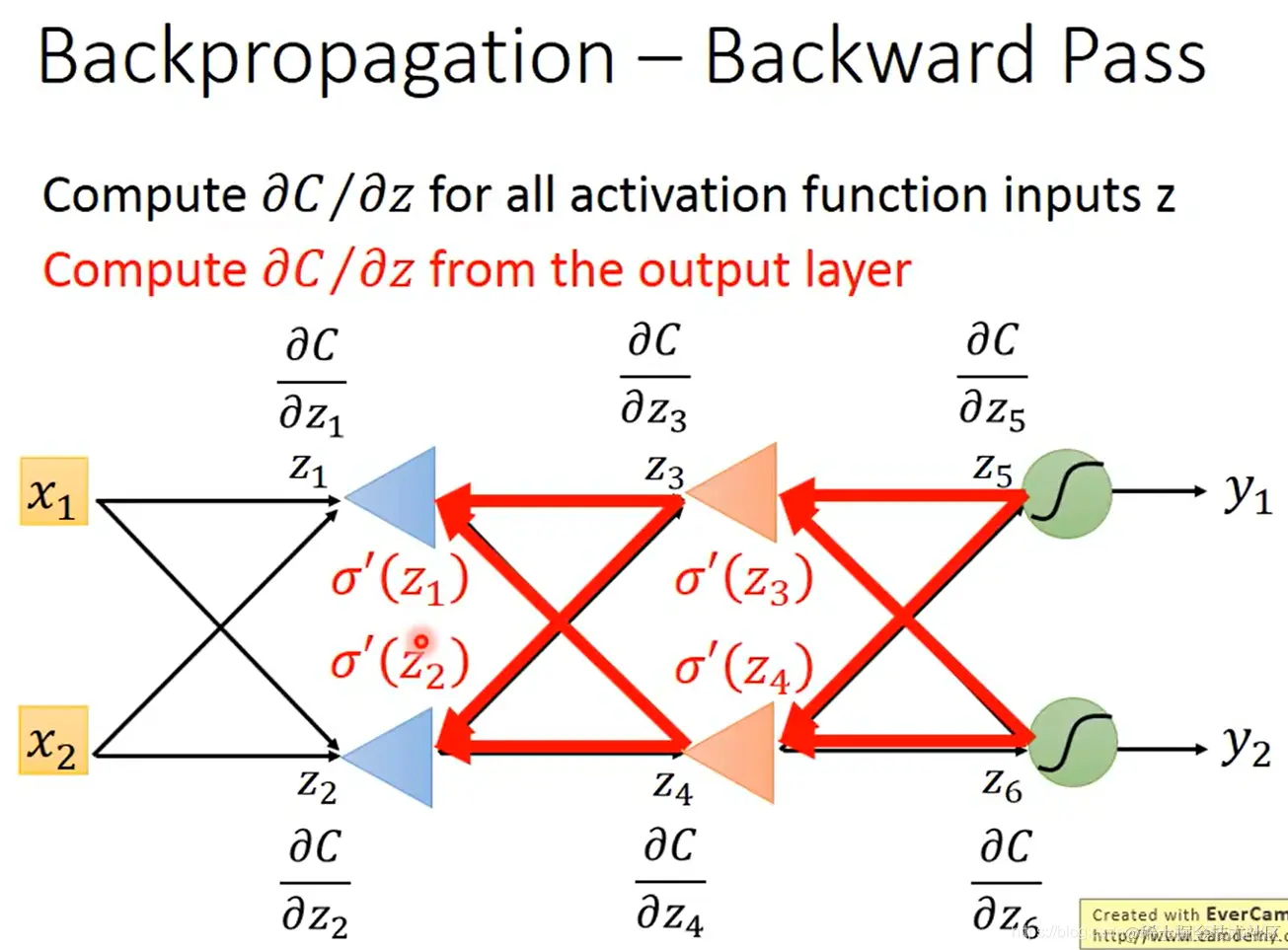
- 从另一侧的观点来看,backward pass可以视为这样的一个奇怪的neuron:
注意 σ′(z) 是个常数,因为 z 在前向传播的过程中已经确定了。
所以这个neuron不是用的激活函数,而可视为一个放大器(就乘以 σ′(z) 这个常数)
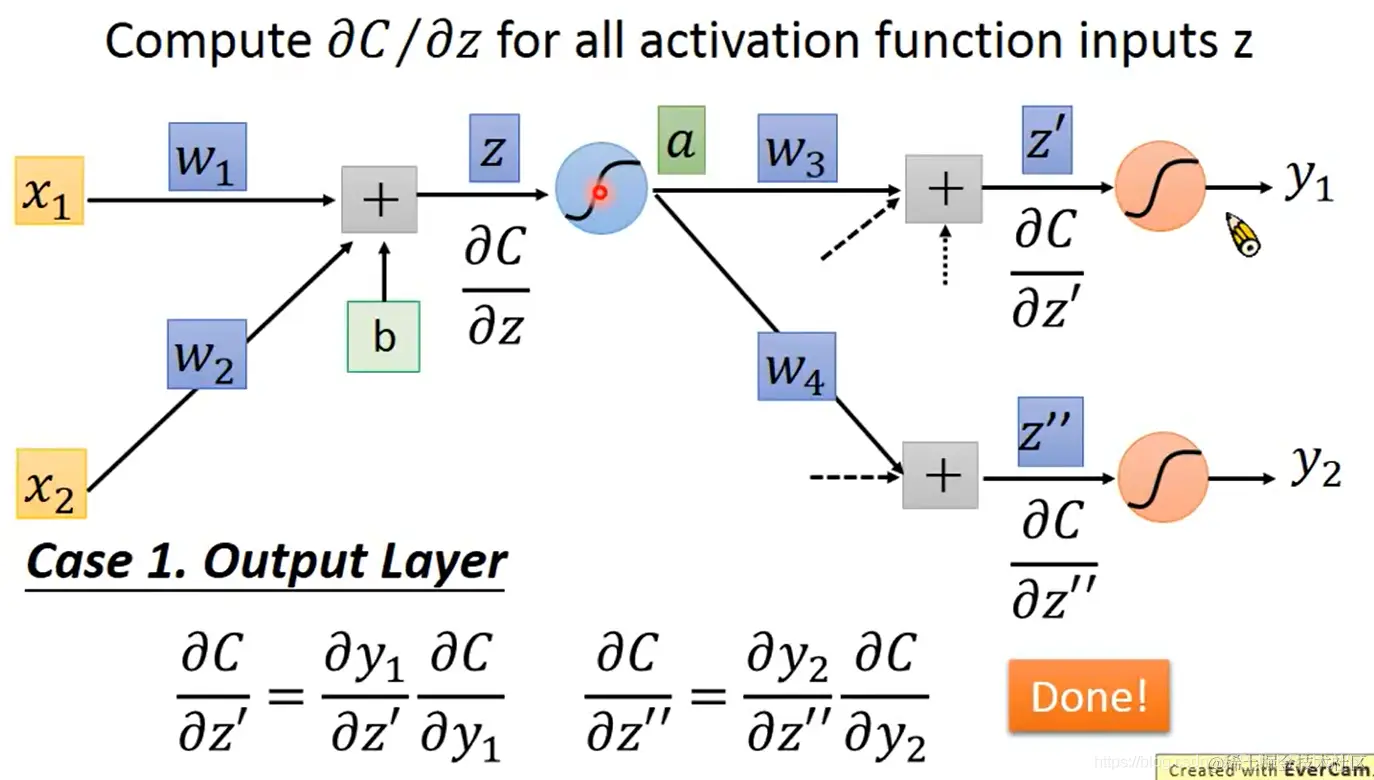
- 对于难算的 ∂z′∂C 和 ∂z′′∂C,如果神经元已经在输出层了,就会很好算:
∂z′∂C=∂z′∂y1∂y1∂C
∂z′′∂C=∂z′′∂y2∂y2∂C
如果它们还不在输出层,那计算它们就跟计算 ∂z∂C 一样,需要下一层对应的C对对应z的偏导数,如果能知道的话就能算出它们的值。(这时也可以将反向传播过程视作那个奇怪的放大器神经元的前向传播过程)
无限套娃,直至最终抵达输出层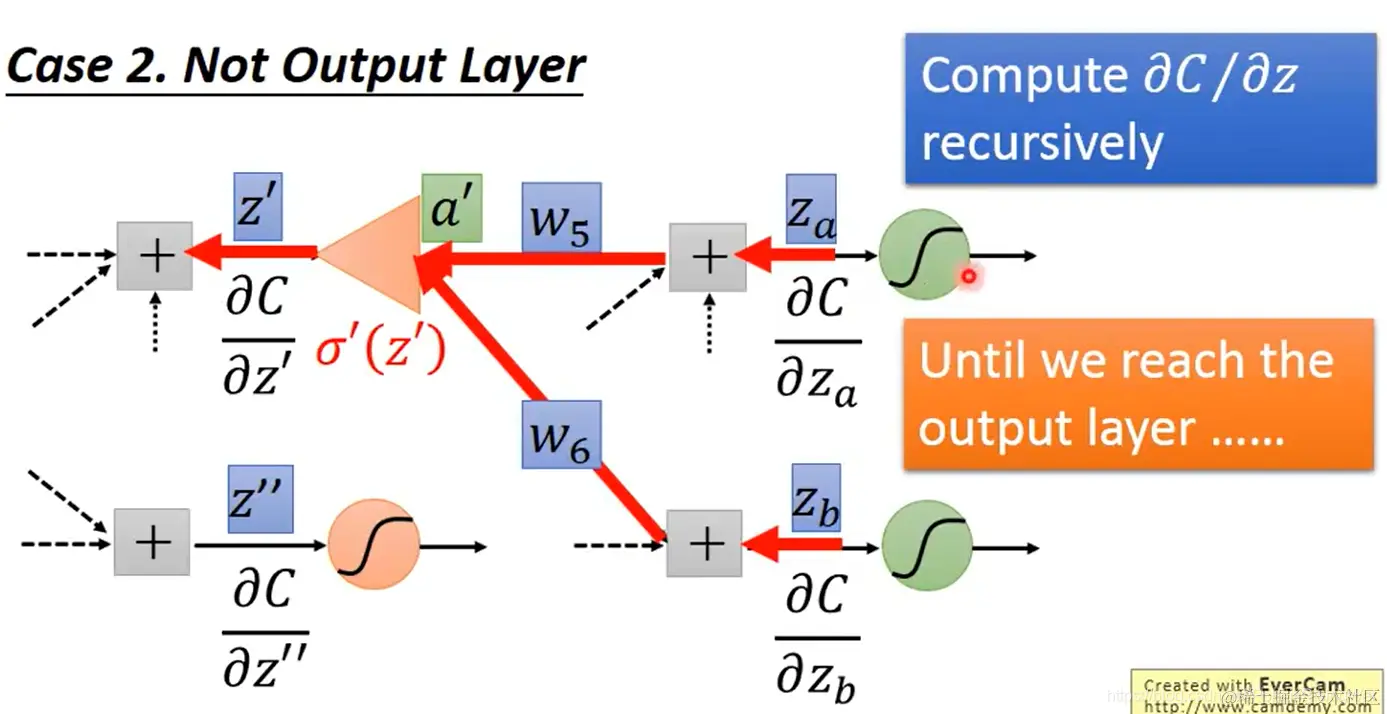
- 在实际计算过程中,就是从最后一层开始往前算偏导:
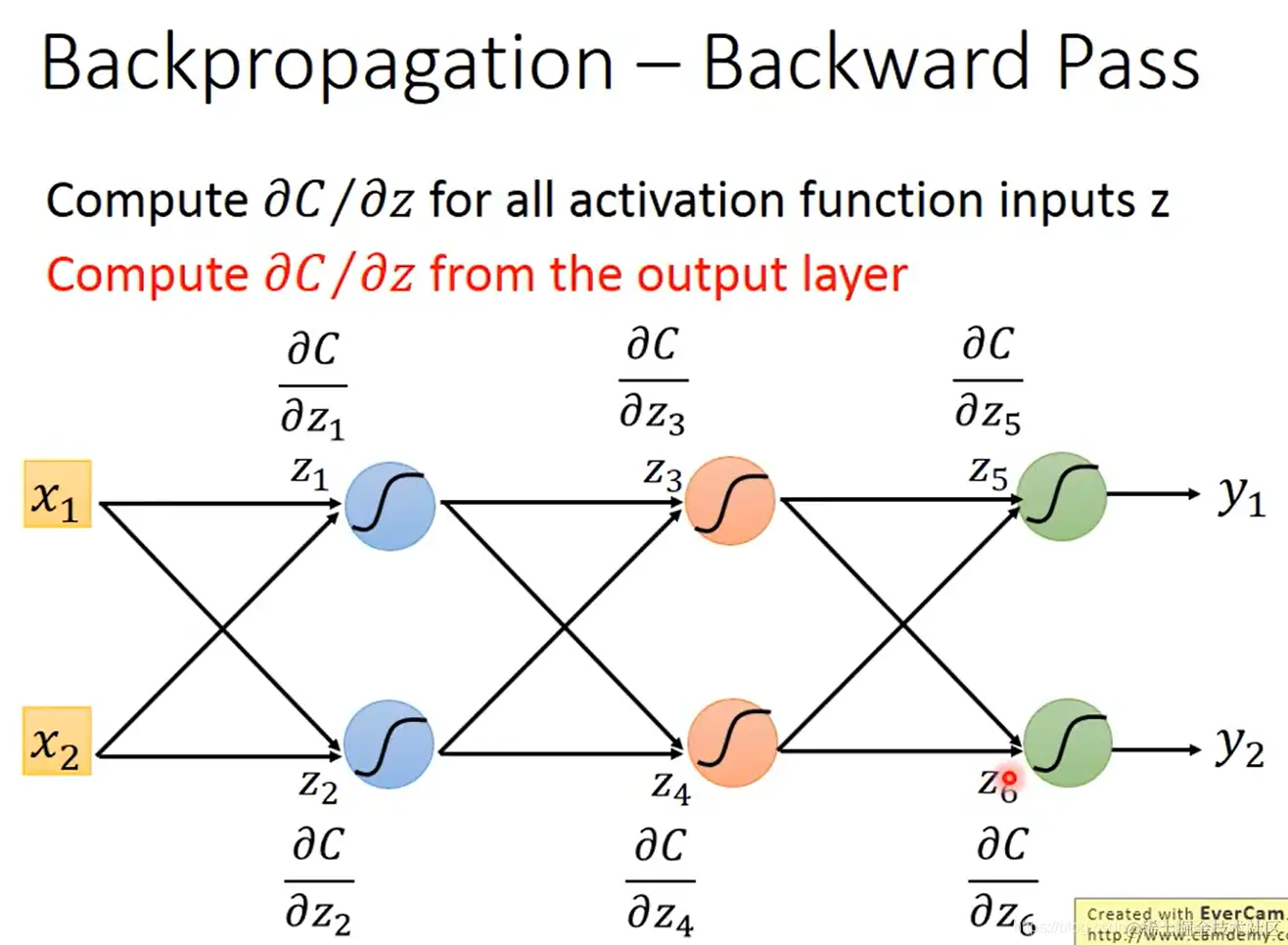
- 反向传播总结:通过前向传播计算 ∂w∂z,通过反向传播计算 ∂z∂C,从而得到我们所需的 ∂w∂C
-
话虽如此,顺带一提,周志华团队前年出了演化算法的书:Evolutionary Learning: Advances in Theories and Algorithms,近期好像已经翻译成中文版了。
有点期待这个领域的发展。
-
这个在cs224w Lecture 93 中也讲到过。那边参考的是这篇论文:Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
-
可参考我之前撰写的笔记:cs224w(图机器学习)2021冬季课程学习笔记11 Theory of Graph Neural Networks


