字符编码
该知识点理论特别多 但是结论很少 代码使用也很短
1.字符编码只针对文本数据
2.回忆计算机内部存储数据的本质
3.既然计算机内部只认识01 为什么我们却可以敲出人类各式各样的字符
肯定存在一个数字跟字符的对应关系 存储该关系的地方称为>>>:字符编码本
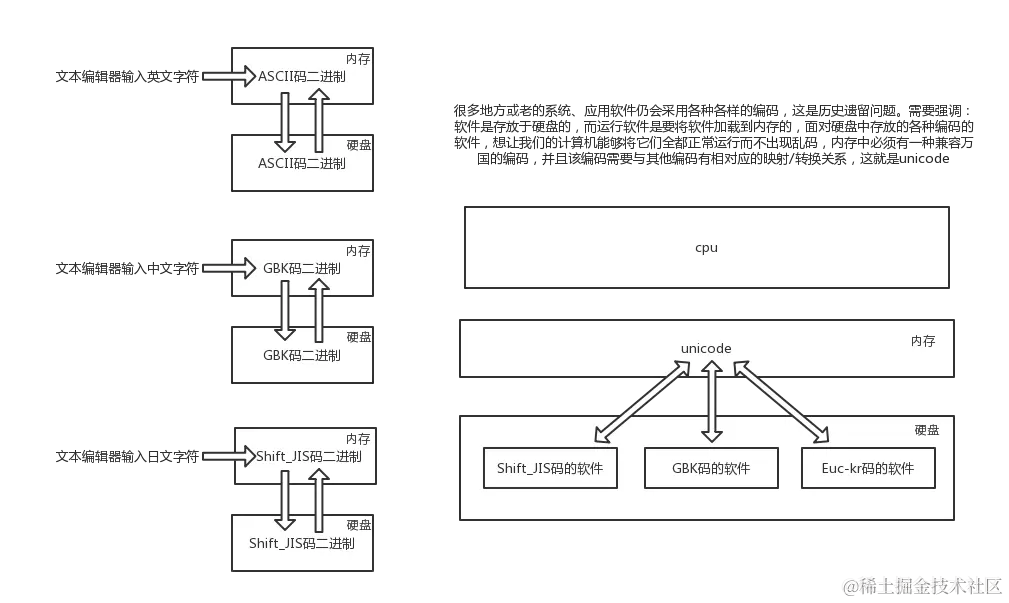
4.字符编码发展史
4.1.一家独大
计算机是由美国人发明的 为了能够让计算机识别英文
需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符
4.2.群雄割据
中国人
GBK码:记录了英文、中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人
shift_JIS码:记录了英文、日文与数字的对应关系
韩国人
Euc_kr码:记录了英文、韩文与数字的对应关系
"""
每个国家的计算机使用的都是自己定制的编码本
不同国家的文本数据无法直接交互 会出现"乱码"
"""
4.3.天下一统
unicode万国码
兼容所有国家语言字符
起步就是两个字节来表示字符
utf系列:utf8 utf16 ...
专门用于优化unocide存储问题
英文还是采用一个字节 中文三个字节
字符编码实操
1.针对乱码不要慌 切换编码慢慢试即可
2.编码与解码
编码:将人类的字符按照指定的编码编码成计算机能够读懂的数据
字符串.encode()
解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂
bytes类型数据.decode()
3.python2与python3差异
python2默认的编码是ASCII
1.文件头
2.字符串前面加u
u'你好啊'
python3默认的编码是utf系列(unicode)
字典操作练习
```python
1.员工管理系统
字典或者数据的嵌套使用完成更加完善的员工管理
2.去重下列列表并保留数据值原来的顺序
eg: [1,2,3,2,1] 去重之后 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]
3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
4.统计列表中每个数据值出现的次数并组织成字典战士
eg: l1 = ['jason','jason','kevin','oscar']
结果:{'jason':2,'kevin':1,'oscar':1}
真实数据
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
题解
"""用户系统 """
user_number = 1
user_massage = {
0: {'name': 'jason', 'password': '123', 'age': '20'}}
while True:
user_choose = input('''
————————————————————
输入1执行添加用户名功能
输入2执行查看所有用户名功能
输入3执行删除指定用户名功能
————————————————————-
请输入>>>:\
''').strip()
if user_choose == '1':
name = input('请输入姓名:').strip()
password = input('定义一个密码:').strip()
age = input('请输入您的年龄:').strip()
one_user_massage = {}
one_user_massage['name'] = name
one_user_massage['password'] = password
one_user_massage['age'] = age
user_massage[user_number] = one_user_massage
print(user_massage)
user_number += 1
print(f'当前有{user_number}个用户')
elif user_choose == '2':
print('姓名 密码 年龄')
for i in user_massage:
temporary_dict = user_massage[i]
print(f"{temporary_dict['name']} {temporary_dict['password']} {temporary_dict['age']}")
elif user_choose == '3':
for i in user_massage:
temporary_dict = user_massage[i]
print(f"{temporary_dict['name']}", end=' ')
print()
del_name = input('请输入你要删除的用户名字>>:').strip()
for i in list(user_massage):
if del_name == user_massage[i]['name']:
del user_massage[i]
print('已删除=。=')
old_list = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
new_list = []
for num in old_list:
if num not in new_list:
new_list.append(num)
print(new_list)
pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
print(pythons & linuxs)
print(pythons | linuxs)
print(pythons - linuxs)
print(pythons ^ linuxs)
mixed_list = ['jason', 'jason', 'kevin', 'oscar', 'kevin', 'tony', 'kevin']
clear_list = []
times = 0
user_dict = {}
for user in mixed_list:
if user not in clear_list:
clear_list.append(user)
for user in clear_list:
for mix_user in mixed_list:
if user == mix_user:
times += 1
user_dict[user] = times
times = 0
print(user_dict)


