

我们都知道,在我们的应用程序中管理数据常常是一件苦差事,因为它们需要:
- 独立的前端客户端来管理各种平台,如Web、移动(iOS、Android等),而且更多时候,这些客户端需要不同的数据集。
- 一个后端系统,可能从不同的存储入口获取数据,如PostgreSQL、Redis、Firebase等。
- 堆栈两边的复杂状态和缓存管理(前端和后端)。
- 为查询提供单独的文档
幸运的是,有一种更现代的方式来管理这些杂事,它以GraphQL的形式出现。
所以,你可能会问,GraphQL到底是什么?好吧,我们将直接进入这个话题。
什么是GraphQL?
GraphQL最初是作为一种API机制被创造出来的,用于处理Facebook的复杂查询任务,这不仅易于学习如何工作,而且也是加快开发新产品的好方法,这些产品将严重依赖数据和各种系统之间的通信。(因此,它相当普遍地被用于 以服务为导向 & 微服务架构)。
在Facebook的使用案例中,一个很好的例子是其移动应用程序,如Facebook和Instagram。
因此,基本上,在其核心,GraphQL是一种查询语言,为前端和后端提供关于如何发送和检索数据的双向指令。
这意味着,它允许前端开发人员 准确地要求他们从一个可访问的数据条目池中获得所需的数据。,这比每次客户端需要新的特定数据批处理时定义一个新的端点要方便得多,作为对经典的 低度查询和 过度查询问题。
GraphQL是如何工作的?
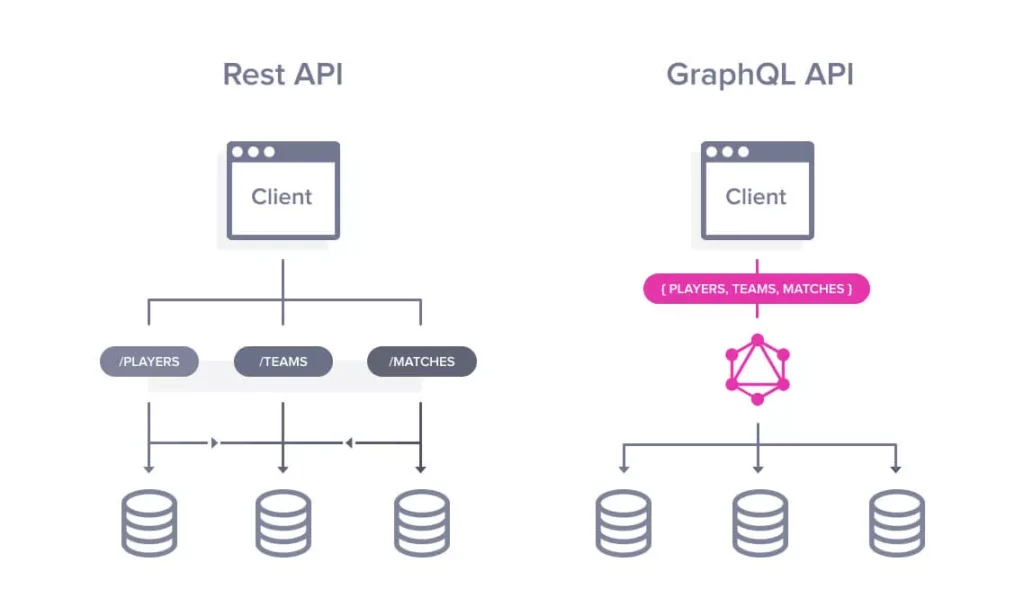
几个REST端点请求可以用一个GraphQL查询代替。资料来源:AltexSoft 2019。Poirier-Ginter 2019。
GraphQL在客户端和服务器之间的连接中起到了封装作用,因此,它为你的客户端提供了一个单一的端点,以访问服务器上的数据池,并选择他们可能需要的任何东西。
不仅如此,它还为数据的进入提供了多个入口,因此我们可以从不同的来源访问数据,当考虑到与系统内已有的服务整合的便利性时,这就非常方便了。
就GraphQL使用的抽象而言,我们会参考GraphQL将数据点/模型解释为 节点,而这些节点之间的关系将被引用为 边缘.因此,数据被表示为一个 图形的相互连接的对象/数据点,而不是我们通过RESTful端点访问的资源。整个图就是我们所说的 应用数据图.
GraphQL与RESTful APIs
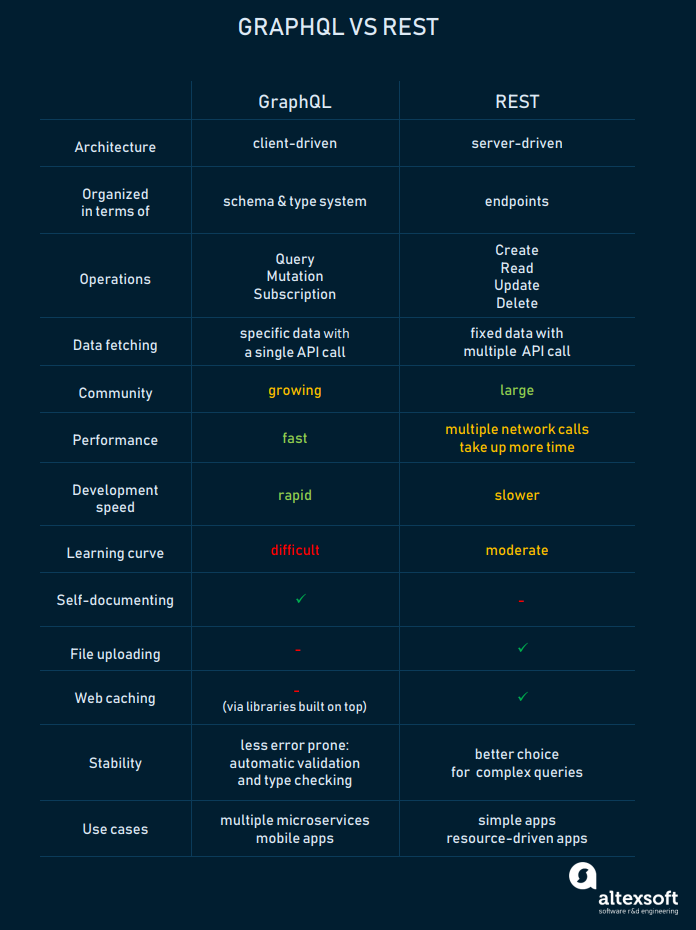
GraphQL和REST的比较。源于此。AltexSoft 2019年。
优势。
1.速度
GraphQL比其他任何通信API都快,因为它迫使你通过只选择你想查询的特定字段来减少你的请求查询,这就解决了前面提到的查询不足和过度查询的问题。
2.最适合复杂的系统
它最适合复杂的系统,如那些实施SOA或微服务架构的系统,因为它允许将系统的所有服务合并在一个单一的保护伞下,这意味着在整个系统中,数据将更容易被访问,如前所述,这非常方便。
3.分层结构的方法
GraphQL遵循分层结构,对象之间的关系以图形结构的方式定义。在这里,每个对象类型代表一个组件,每个从一个对象类型到另一个对象类型的关系字段代表一个组件包裹另一个组件。
4.为客户提供的形状化数据
给我们的数据添加了一个形状。当我们向服务器请求GraphQL查询时,服务器会以一种简单、安全和可预测的形状返回响应。因此,它有利于你根据你的要求写一个特定的查询。这使得GraphQL非常容易学习和使用。
5.客户端/服务器不可知
由于GraphQL是一个协议,它并不关心你在应用程序的前端或后端使用什么技术,只要支持实现GraphQL客户端来处理协议的实现。比如说。用于JavaScript的Apollo,用于C#/.NET的Hot Chocolate,等等。
缺点
1.查询的复杂性
当我们必须在一个查询中访问多个字段时,无论它是通过RESTfully还是通过GraphQL请求,不同的资源和字段仍然必须从数据源中获取。因此,当客户端一次请求太多的嵌套字段数据时,也会出现同样的问题。
因此,必须有一个机制,如最大查询深度、查询复杂度加权、避免递归或持久性查询,以阻止来自客户端的低效和破坏性请求。
2.缓存
用GraphQL实现一个简化的缓存比在REST中实现它要复杂得多。在REST API中,我们用URL访问资源,所以我们可以在资源层面上进行缓存,因为我们有资源的URL作为标识。
另一方面,在GraphQL中,是非常复杂的,因为每个查询都可能是不同的,即使它在同一个实体上操作。但大多数建立在GraphQL之上的库都提供了一个有效的缓存机制。
GraphQL常用术语词汇表
- 查询:一个只读操作,从GraphQL服务中获取数据。
- 突变:虽然查询可以被设计为进行数据写入,但不建议这样做。建议使用一个明确的突变。
- 字段:我们可以获得的数据的基本单位。GraphQL实际上是在对象上选择字段。你可以把字段看作是你希望查询或突变的数据模型的属性。
- 片段:一组字段,可以在多个查询中重复使用。
- 论据:每个字段和嵌套对象都可以有一个参数,从而使我们能够过滤或定制结果。参数基本上是键:值对,我们可以用它来过滤数据。
- 别名:为了避免在结果中出现命名冲突,别名是有用的。例如,我们可以用不同的参数查询同一个对象,并在不同的别名中得到结果。
- 指令(Directive):可以附在字段或片段上,动态地影响数据的形状。强制性指令是
@include,@skip,根据条件包括或跳过一个字段。指令通常用于分页。
最后的话
我相信GraphQL是管理更复杂系统的好方法,在处理更大的应用程序时可能会遇到这种情况。
如果你遇到的情况是,你看到自己的试图协调一个 各种前端客户之间的关系,和/或多个后端数据输入源,这可能是一个很好的迹象,GraphQL可能很适合你的用例。
如果你想看看我们如何用Node.js和Express建立一个GraphQL服务器,你可以在这里查看这篇文章。如果你还想看看我们如何在React应用程序中通过Apollo客户端实现GraphQL,并与GraphQL服务器互动,你可以查看这篇文章。
如果你觉得我遗漏了什么,或者你想进一步讨论我在这篇文章中提到的任何东西,请随时留言,以便我们可以接下去。这将是非常感激的。
干杯!
