每日一kun:成功就像鬼一样,只有别人遇到过。
使用ptyhon写个关于学院体测成绩的数据爬虫,并完成数据接口,爬虫模块主要是requests,数据分析使用lxml模块对xpath进行数据清洗提取拿到有用的数据,使用flask完成最后的数据接口返回。
user_agent 伪造浏览器访问,防止网站的反爬策略过滤我们的爬虫请求,结果返回空。
url ='本校体育测试网址'
user_agent={
"user-agent": 'Mozilla/5.0 (Windows NT 10.0 WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
默认访问接口文档,网站后面带/top后面<password>/<username>/<int:year>为体测网站的密码,用户名,学年,学年可以为空,为空返回所有学年的体测成绩,使用falsk模块完成。
@sanxia_tiche.route('/')
def hello():
return jsonify(home)
@sanxia_tiche.route('/top/<password>/<username>/<int:year>',methods=['GET'])
def top(password,username,year):
top01(password,username,year)
return jsonify(page02_list)
接口文档
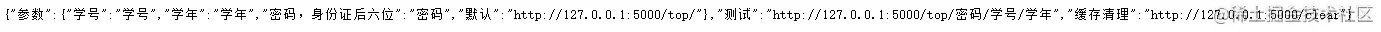
因为浏览器需要用到学号密码,返回的结果也会带上身份证姓名等隐私所以就不放这些截图了


