

在这篇文章中,我们讨论了由递归和迭代解释器对中间代码进行独立于机器和范式的处理。
目录
- 简介
- 解释器
- 递归解释器
- 迭代解释器
- 总结
- 参考文献
简介
处理中间代码包括选择少量的预处理,然后在解释器上执行,或者大量的预处理*(机器代码生成*),然后在硬件上执行生成的代码。
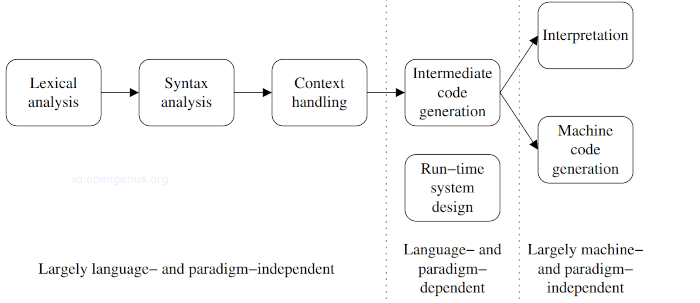
解释器不需要去除所有的语言特征,因此,例如它可以直接解释一个for-loop节点,或者如果解释器集成了中间代码生成和目标代码生成,for-loop子树将被直接改写为目标代码。
在这篇文章中,我们讨论这两种类型的解释器。
解释器。
解释器是让源程序所表达的动作得到执行的最简单方法。这是由处理AST来完成的。
解释器按照正确的顺序考虑AST的节点,并按照语言语义对这些节点执行规定的动作。
与编译不同,这需要输入的存在。
理想情况下,解释器的工作就像CPU一样,不同的是,CPU在指令集上工作,而解释器在AST上工作。
解释器可以是
- 递归--直接在AST上工作,从而减少预处理
- 迭代--在一个线性化的AST上工作。
递归解释器
递归解释器对AST中的每个节点类型都有一个例程。这些例程会调用其他类似的例程。
这是有可能的,因为语言结构的含义被定义为其组成部分的含义的函数。
一个例子
procedure ExecuteIfStatement (IfNode):
Result ← EvaluateExpression (IfNode.condition);
if Status.mode != NormalMode: return;
if Result.type != Boolean:
error "Condition in if-statement is not of type Boolean";
return;
if Result.boolean.value = True:
−− Check if the then-part exists:
if IfNode.thenPart != NoNode:
ExecuteStatement (IfNode.thenPart);
else −− Result.boolean.value = False:
−− Check if the else-part exists:
if IfNode.elsePart != NoNode:
ExecuteStatement (IfNode.elsePart);
从上面的例程可以看出,首先解释条件,然后根据结果,解释then部分或else部分。
then和else部分可以包含if语句,因此if语句的例程将是递归的。
统一的自我识别数据表示是递归解释的一个重要成分。
解释器必须操作被执行的程序中定义的数据值,但在编写解释器时,这些数据的类型和大小是不知道的,这使得有必要将这些值实现为可变大小的记录,这些记录在解释器中指定运行时值的类型、大小和值本身。在解释过程中,这个记录的指针将作为 "值 "的服务器。
下面的图片显示了程序员是如何看待一个Complex_Number类型的值的。

下面的图片显示了解释器是如何看待同一个值的。
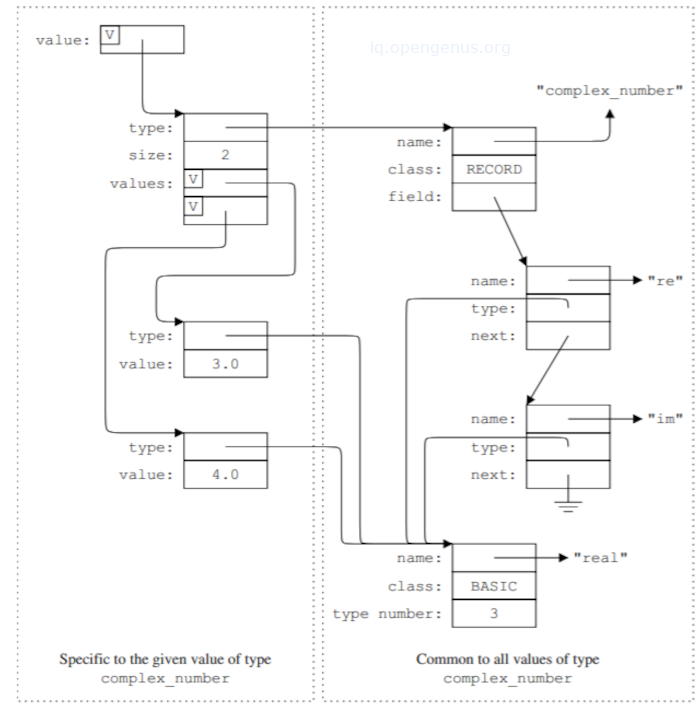
V对应于运行时的值,每个值都是通过其类型字段自我识别的。
数据表示由两部分组成,特定值部分提供实例的实际值,公共部分描述所有Complex_Number类型的值所共有的值的类型。
状态指示器是递归解释器的另一个特征,它引导控制流。
它的主要组成部分是操作模式,这是一个枚举值,正常值是NormalMode,表示控制的顺序流,其他值也是可用的,例如表示跳转、函数返回、异常等等
。它可以是一个ReturnMode的值,一个异常名称加上ExceptionMode的可能值和一个JumpMode的标签。
它还包含创建它的文件名和文本行数。
它还可以保存其他调试信息。
每个例程都会检查状态指示器,以确定如何进行。即如果它是在NormalMode中,例程正常进行,否则检查如何处理当前模式,如果可以,它就处理,否则让父例程处理。
从前面的例子来看,条件的评估可能会异常终止,从而导致ExecuteIfStatement立即返回。
结果可能是一个错误的类型,如果是这样的话,就会发出一个错误并返回。负责出错的例程将终止解释或组成一个ErroneousMode状态指示器。
如果我们有一个正确的布尔值,我们解释then部分或else部分,并留下状态指示器。如果这两部分都不存在,则不需要任何行动,状态指示器处于NormalMode。
迭代解释器
迭代解释器的结构更接近于CPU。它由一个case语句的平面循环组成,包含AST的每个节点类型的代码段。
它为活动节点指针所指向的节点运行代码段,最后,当前代码将活动节点指针设置为下一个节点。
活动节点指针可以与CPU中的指令指针相比较。
一个例子
while ActiveNode.type != EndOfProgramType:
select ActiveNode.type:
case ...
case IfType:
−− We arrive here after the condition has been evaluated
−− the boolean result is on the working stack.
Value ← Pop (WorkingStack);
if Value.boolean.value = True:
ActiveNode ← ActiveNode.trueSuccessor;
else −− Value.boolean.value = False:
if ActiveNode.falseSuccessor != NoNode:
ActiveNode ← ActiveNode.falseSuccessor;
else −− ActiveNode.falseSuccessor = NoNode:
ActiveNode ← ActiveNode.successor;
case ...
上面是一个迭代解释器的主循环的概要。我们可以看到它包含一个单一的case语句,根据类型为活动节点选择合适的代码段。在这种情况下,我们有一个代码段--用于if语句。
条件代码已经被评估了,因为它在线程AST的if节点之前。条件的类型没有被检查,因为完整的注释已经做了完整的类型检查。调用解释器的适当分支被正确设置活动节点指针所取代。
这里的数据结构类似于编译程序中的数据结构,而不是递归解释器的数据结构。它们包括一个容纳全局数据的数组,如果源语言允许数组的话,如果是面向堆栈的,就会维护一个堆栈,它将容纳局部变量,堆栈也容纳堆栈和范围信息。它被实现为一个可扩展的数组。
如果使用符号表,是为了给出更好的错误信息。
迭代解释器与编译程序相比,在程序中存储了大量的运行时信息,但比递归解释器要少。
递归解释器通过将变量存储在符号表中来维护任意数量的信息,而迭代解释器将只在给定的地址上有一个值。
一个与解释器维护的内存数组平行的数组形式的影子内存弥补了这种情况。
影子数组中的每个字节将持有内存数组中相应字节的属性。
影子数据可以用于解释时的检查,例如检测未初始化内存的使用、不正确对齐的数据访问和其他问题。
影子内存的一个优点是,当人们需要更快的处理时,可以很容易地禁用它。
一些迭代解释器将AST存储在一个数组中,例如,这使得它更容易写入文件,这反过来又允许程序被多次解释,而不需要每次都从源文本中重新创建AST。
而且,这种方式可以使表示更加紧凑。
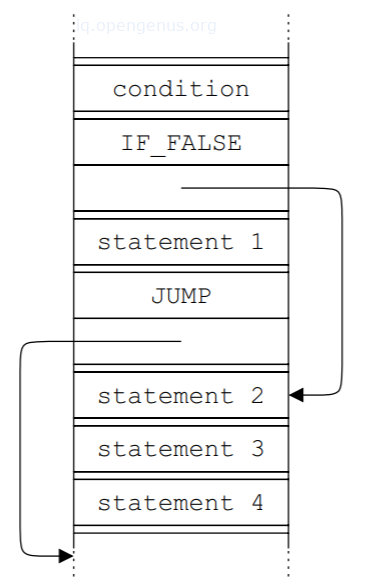
构建AST时,会把节点的后继者放在该节点之后,如果这种情况经常发生,最好是省略节点的后继者指针,指定节点N之后的节点为N的后继者。
存储AST的形式
将AST存储为一个图。
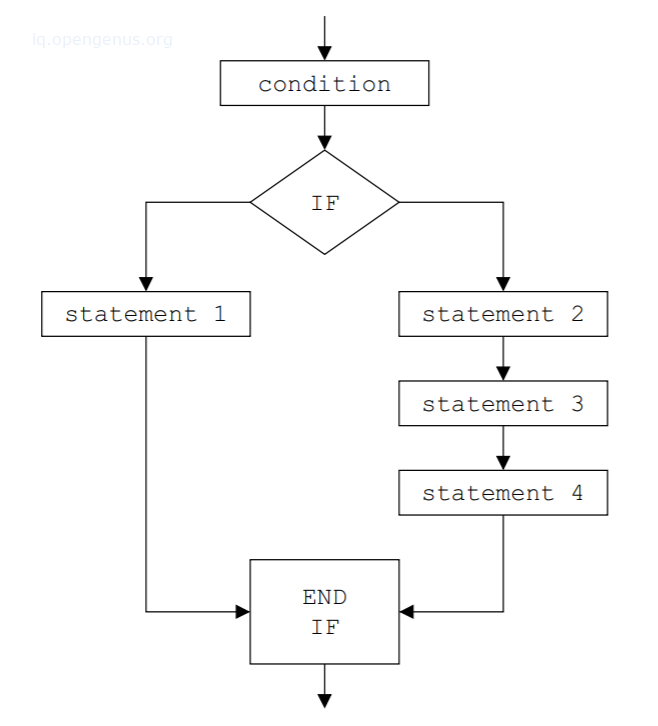
将AST存储在一个数组中。
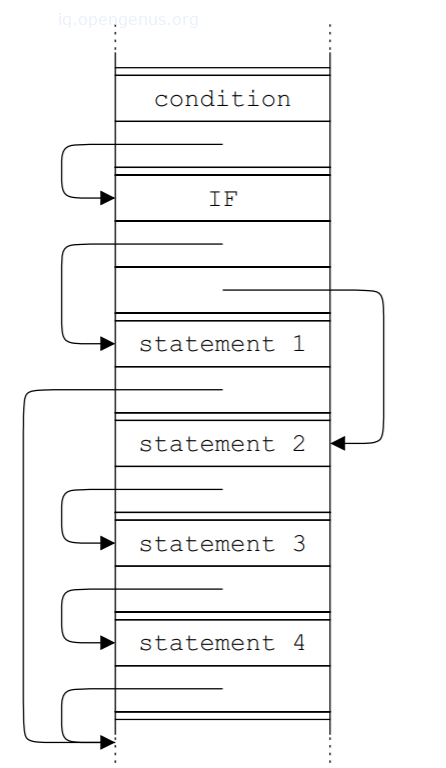
将AST存储为伪指令。
总结。
解释器认为AST的节点是有序的,并执行语言语义所规定的那些节点的动作。
解释器可以是递归的,也可以是迭代的,前者对AST中的每个节点类型都有一个例程,后者由一个包含每个节点类型的代码段的case语句的平循环组成。
由于递归解释器可以快速编写,它被用于快速原型设计
解释的代码要比编译的慢得多。
