

最小 绝对 偏差(LAD)是一种解决优化问题的强大方法,对离群值有很好的容忍度。因此,解决它以获得一个实际适用的形式是利用其理论优势的关键。为了更好地理解,建议对ADMM有一个良好的掌握。
目录
- 简介
- 机器学习的背景
- 使用ADMM解决LAD问题
- 实施
简介
"最小绝对偏差"(LAD)、"最小绝对误差"(LAE)、"最小绝对残差"(LAR)和 "最小绝对值"(LAV)等名称都是指同一个基本方法。1757年,Roger Joseph Boscovich确立了LAD的思想,比其他基于绝对差值的方法如最小平方(LS)早了大约50年。对 "绝对值 "的考虑为预测值与现实的比较问题提供了一个直接的答案。
更具体地说,LAD是一种统计优化标准和统计优化技术,基于最小化绝对偏差之和(也被称为绝对残差之和或绝对错误之和)或这种值的L1规范。
机器学习的背景
在机器学习中,当试图估计回归参数时,替代最小二乘法(∥Ax-b∥2^2)的主要方法之一是LAD(∥Ax-b1∥1)法。使用绝对值的结果是处理异常值的更稳健的解决方案,并且有多种解决方案的可能性。LAD的成本表述为:。
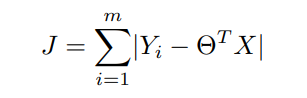
现在通过使用加权最小二乘法,我们可以将相同的函数写成。
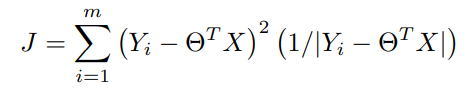
在重新排列这些条款以获得Θnew。
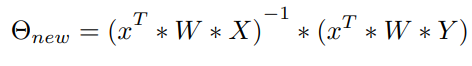
这可以作为Θ的更新。
在很大的数值范围内比较L1规范和L2规范
考虑一下两种规范的损失与误差的关系。
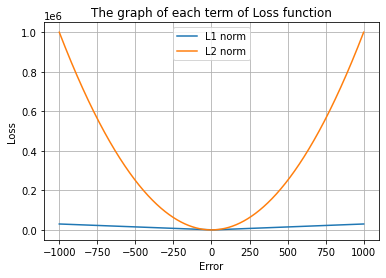
该图支持通过对模型的惩罚小于L2准则来处理数据中包含的异常值的假设,该图显示在很大的误差值范围内L1准则的损失要比L2准则的损失小得多。因此,不再需要对数据进行严格的预处理。因此,从数学上分析这个问题是有意义的。
使用ADMM解决LAD问题
因此,LAD问题可以定义为。
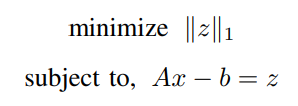
ADMM解决方案。
相应的增强拉格朗日形式可以写为。
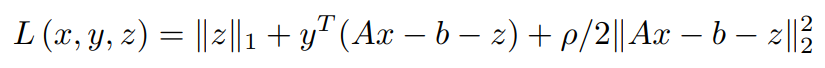
将依赖y的项合并为L2规范项。
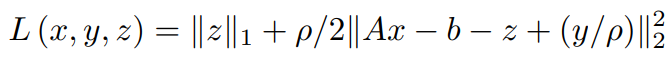
用u代替y/ρ(这一步可以在求解过程中的任何地方进行,但通常是为了保持惯例)。
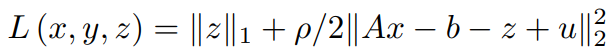
为了找到x的更新,
假设z^k和u^k是已知的
,那么关于x的拉格朗日的最小化是这样做的
。
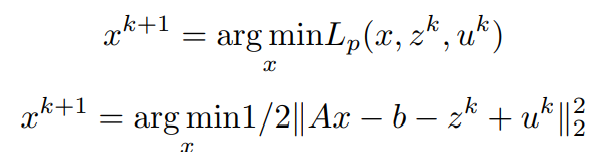
将关于x的一阶偏微分项等价为0(0矢量),简化后得到x^(k+1)
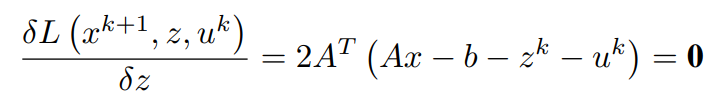
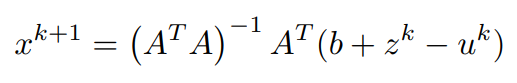
同样地,为了找到z的更新,对拉格朗日的最小化是这样做的:
x^(k+1)已经被计算出来,u^k被假设为已知。
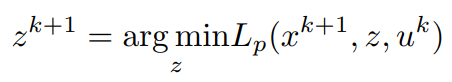
考虑与z有关的条款。
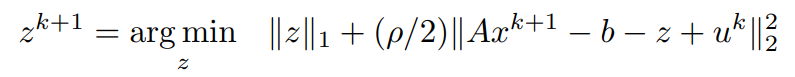
将ρ带入一个共同的分母常数。
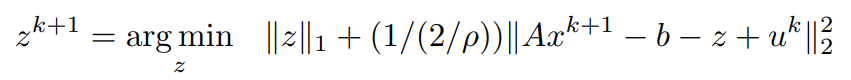
近似算子。考虑到变量v上的近似算子与某个常数α的定义为:。
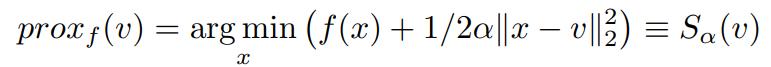
在比较最新的方程和近似算子时,右手边的相似性导致我们将得到的z^(k+1)简化为更紧凑的形式,如。
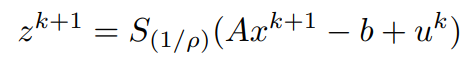
x^(k+1)和z^(k+1)都已经计算出来了,利用它们,y的更新可以写成。
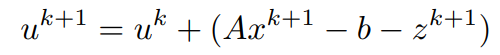
在本质上。
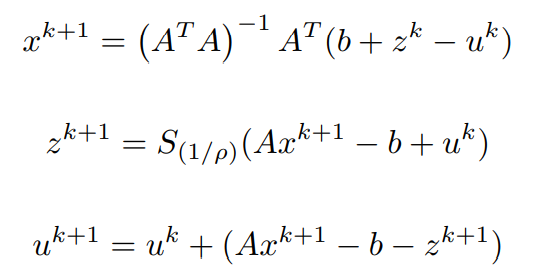
实施
在Matlab中,可以通过以下基本步骤对合成数据的更新步骤进行简单而直观的代码实现。
- 创建一个玩具数据集(可能是像下面这样的线性数据集),我们的目的是验证更新是否按预期进行。
- 决定一个目标变量(在下面的实现中,它将是变量x0),并向系统添加噪声,这是为了模仿更真实的观察。
- 将所需的变量随机初始化/归零。
- 对更新方程进行编码,并在其中循环足够多的次数/直到收敛。
- 输出由更新得到的最终值,如果做得正确,我们应该观察到一个相对接近的curated值和由系统定义的更新得到的预测值。
rand('seed', 0);
randn('seed', 0);
m = 1000; % number of examples
n = 100; % number of features
% synthesizing required coditions
A = randn(m,n);
x0 = 10*randn(n,1);
b = A*x0;
idx = randsample(m,ceil(m/50));
b(idx) = b(idx) + 1e2*randn(size(idx)); % adding deviations
rho = 1;
% maximum iterations set instead of convergence
MAX_ITER = 1000;
[m, n] = size(A);
x = zeros(n,1);
z = zeros(m,1);
u = zeros(m,1);
P = inv(A'*A)*A'
for k = 1:MAX_ITER
% x-update
x = P*(b + z - u);
e = A*x;
% z-update
z = shrinkage(e - b + u, 1/rho);
% u-update
u = u + (e - z - b);
end
h = {'x0' 'x'};
v = [x0, x];
R = [h;num2cell(v)]
oh = {'z' 'u'};
ov = [z, u];
oR = [oh;num2cell(ov)]
Matlab对辅助函数缩减的定义是:
function z = shrinkage(x, kappa)
z = pos(1 - kappa./abs(x)).*x;
end
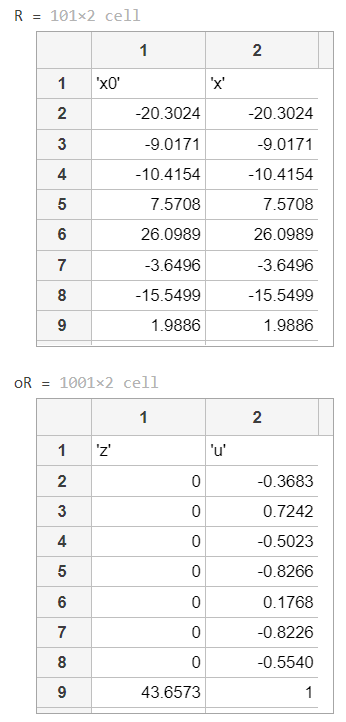
输出
得到以下输出。
这里:
- x0代表我们期望通过更新在x中实现的综合数据
- 而z和u是相应的更新支持性变量值
L1-Norm与L2-Norm损失与误差图的附加代码
下面的代码是用python编写的
import numpy as np
import matplotlib.pyplot as plt
def SE(x,y,intc,beta):
return (1./len(x))*(0.5)*sum(y - beta * x - intc)**2
def L1(intc,beta,lam):
return lam*(np.abs(intc)+np.abs(beta))
def L2(intc,beta,lam):
return lam*(intc**2 + beta**2)
N = 100
x = np.random.randn(N)
y = 2 * x + np.random.randn(N)
beta_N = 10000
beta = np.linspace(-1000,1000,beta_N)
intc = 0.0
L1_array = np.array([L1(intc,i,lam=30) for i in beta])
L2_array = np.array([L2(intc,i,lam=1) for i in beta])
fig1 = plt.figure()
ax1 = fig1.add_subplot(1,1,1)
plt.ylabel("Loss")
plt.xlabel("Error")
plt.grid()
ax1.plot(beta,L1_array,label='L1 norm')
ax1.plot(beta,L2_array,label='L2 norm')
plt.title('The graph of each term of Loss function')
plt.legend()
fig1.show()
