

一种用于降低机器学习数据集维度的技术是特征选择器。特征选择器的选择过程是基于一个逻辑上的精确测量,确定数据中存在的每个特征的重要性。在OpenGenus的这篇文章中,我们探讨了使用LASSO原理构建的特征选择器比传统方法的优势。
目录
- 简介
- 实施
- 观察
简介
根据维基百科,建议新特征子集的搜索方法和对各种特征子集进行排序的评估指标的结合,就是所谓的特征选择算法。最简单的方法是测试每个潜在的特征子集,看哪个子集的错误率最低。除了最小的特征集之外,这是对可用空间的穷举搜索,在计算上是难以实现的。三种主要的特征选择算法可以通过使用的评价指标来区分,这些评价指标对算法有很大影响。 滤波器、嵌入方法和包装器。
进行特征选择的优势在于:
- 增强数据对一类学习模型的适用性。
- 对输入空间中的固有对称性进行编码。
- 减少训练次数。
- 简化模型,便于更好地解释
关于LASSO解决方案及其使用的其他细节可以在这里找到
实现这两种特征选择操作的方法如下。
1.非Lasso实施(传统的数据分析)
-
手动计算数据的每个特征与结果的相关值。
-
取每个相关值的绝对值,这样做是因为高相关和反相关
都是对模型预测的重要贡献。 -
将绝对相关的特征按降序排列(从高到低的顺序)。
2.2. LASSO的实施
- 使用LASSO模型来选择重要的特征。
- 将选定的相关特征按降序排列(从高到低的顺序)。
实施
本实验所需的包可以通过以下方式导入:
import numpy as np
import scipy.stats
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import Lasso
之后我们将使用sklearn的任何一个玩具数据集来进行特征选择,例如波士顿数据集可以通过以下方式导入:
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y=True)
features = load_boston()['feature_names']
你可以选择使用的其他类似的数据集,可以在这里找到
下一步将是在数据集中创建一个训练测试分割,可以这样做。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
在这之后,我们将创建一个用于缩放的管道。
pipeline = Pipeline([ ('scaler',StandardScaler()), ('model',Lasso()) ])
最后,我们可以开始搜索,这里我们要测试从0.1到10的几个值,以0.1为单位。对于每个值,我们计算5折交叉验证中的平均平方误差的平均值,并选择使这种平均性能指标最小的α值。
search = GridSearchCV(pipeline, {'model__alpha':np.arange(0.1,10,0.1)}, cv = 5, scoring="neg_mean_squared_error",verbose=3)
在上面的代码部分,我们使用了neg_mean_squared_error,因为网格搜索试图使性能指标最大化,所以我们加了一个减号来使平均平方误差最小化。
接下来,我们训练模型。
search.fit(X_train,y_train)
训练后,我们可以用获得α的最佳值。
best_alhpa = search.best_params_
print("Best value for alpha is = ", '%.6f'%float(best_alhpa['model__alpha']))
现在,我们要获得Lasso回归的系数值。一个特征的重要性是其系数的绝对值。
coefficients = search.best_estimator_.named_steps['model'].coef_
importance = np.abs(coefficients)
print(importance)
我们设置了一个阈值,以使我们能够控制特征所需的影响程度。
threshold = 0
根据设定的阈值。
可以找到拉索回归中幸存下来的特征。
np.array(features)[importance > threshold]
同样地,没有在拉索回归中存活下来的特征是。
np.array(features)[importance <= threshold]
这就完成了LASSO的实现,现在我们将在相同的数据上实现基于相关的方法。
r_col = y_train
n_ft = len(X_train[0])
n_cof = [None]*n_ft
for i in range(n_ft):
i_col = df = X_train[:,i]
n_cof[i] = scipy.stats.pearsonr(r_col, i_col)[0]
importance_corr = np.abs(np.round(n_cof,4))
print(importance_corr)
接下来,我们将选择一个小数字来检查是否总是选择最重要的。
!注意这一部分对于不同的数据集来说可能会有不同,基于所使用的特征。对于小的数据集来说,跟踪和错误应该是可以的。
n_imp = 5
接下来,我们可以通过以下方法找到对相关系数值影响最大的特征。
print(np.sort(importance_corr)[::-1][:n_imp])
现在我们可以用这两个选定的特征进行比较。
imp_arr = importance_corr*[importance > threshold]
rel_imp = imp_arr[np.nonzero(imp_arr)]
print(np.sort(importance_corr)[::-1][:n_imp])
print(np.sort(rel_imp)[::-1][:n_imp])
观察结果
在对4个常见的不同的玩具数据集(Boston, Wine, Digits, and Iris)运行同样的代码时,我们得到了以下输出。
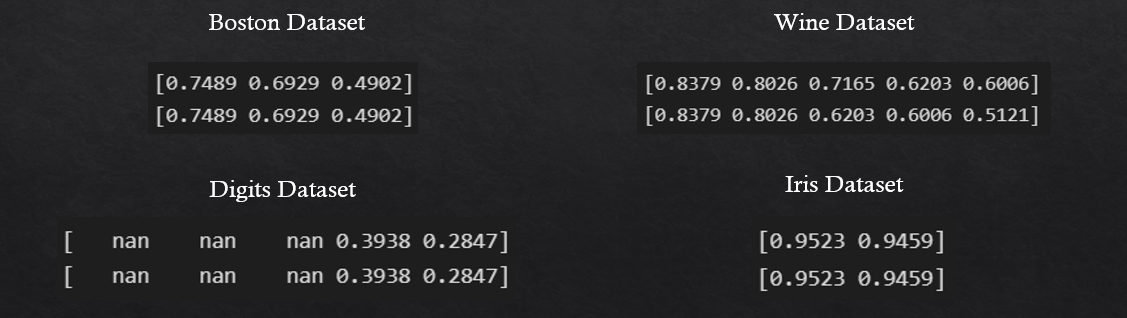
当手动计算所有特征中关于特征选择结果的最高绝对相关度时
,我们正在考虑最重要的特征。因此,当两个执行结果几乎相同时
,我们可以推断出,LASSO模型确实正确地选择了最重要的特征。
基于LASSO的特征选择器的主要优点是它可以扩展到具有大量特征的数据集,而人工实现则是计算成本高且繁琐的。
