

医学图像处理是计算机视觉的一个重要应用,需要将图像分割成身体的各个部分。约瑟夫-布洛克和他在达勒姆大学的伙伴们提出了一个称为XNet的神经元网络,它适合这项任务。仅仅在一个小的数据集上进行了训练,XNet仍然超越了经典的方法,取得了最先进的结果。在这篇文章中,我将介绍该论文的主要内容。
相关工作
在探讨本文的内容之前,我们需要回顾一下XNet方法所基于的一些基础工作。以前,很多工作都集中在使用经典的图像处理技术,特别是基于某些参数的相似性的像素聚类。作者深入研究了这些方法,并在表1中得出了关键的见解。
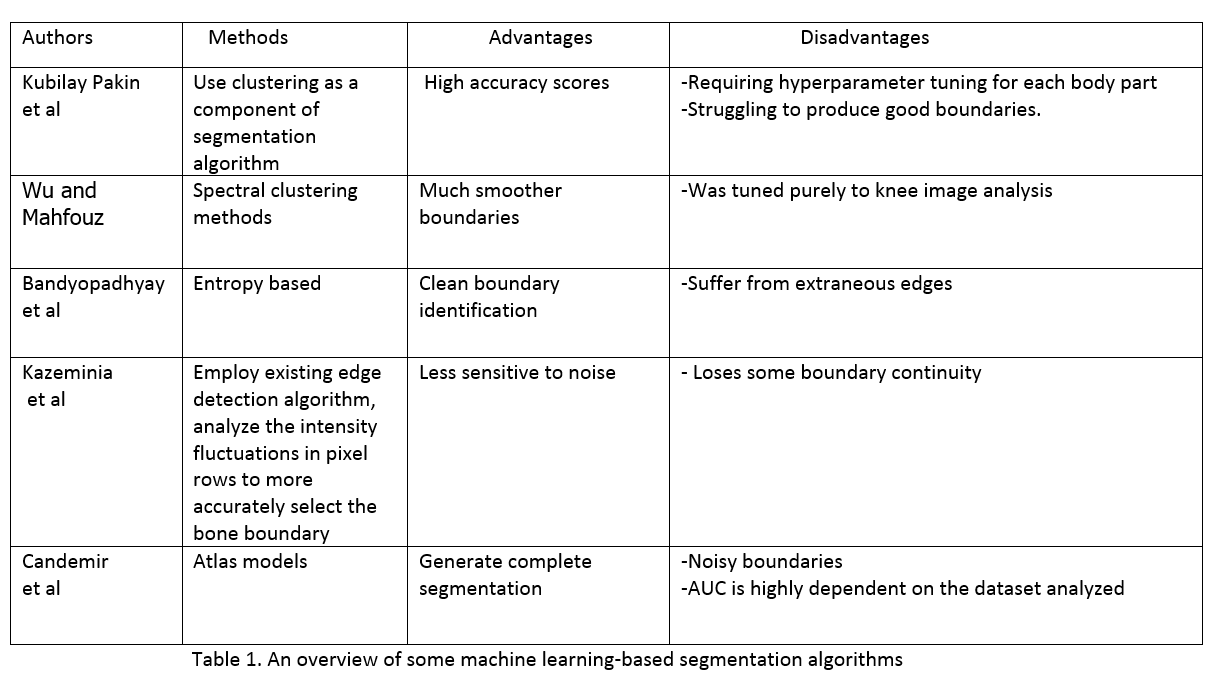
总的来说,经典技术由于其结构的原因,还不够好,不适合在X射线分析中广泛使用。因此,Joseph Bullock和他的同事们关注基于神经元网络的方法,这些方法目前表现出最先进的结果,并能满足他们的要求。本研究基于U-Net和Segnet模型,这些模型表现出良好的性能并被广泛应用。
数据
研究人员收集了150张图像,其中包括69张脚部、膝盖和幻影头部的CT扫描图像,以及81张不同身体和幻影身体部位的标准X射线图像,其中胸部的代表性最差。这些图像经过预处理,利用平均减法和像素值归一化,使其在[-1,1]范围内,同时调整为200x200像素,以匹配网络的输入形状。约瑟夫-布洛克(Joseph Bullock)和他的同事使用免费软件GIMP对图像进行标记,将每种颜色分配给这三个区域中的一个:黄色代表骨骼,绿色代表软组织,紫色代表软组织。
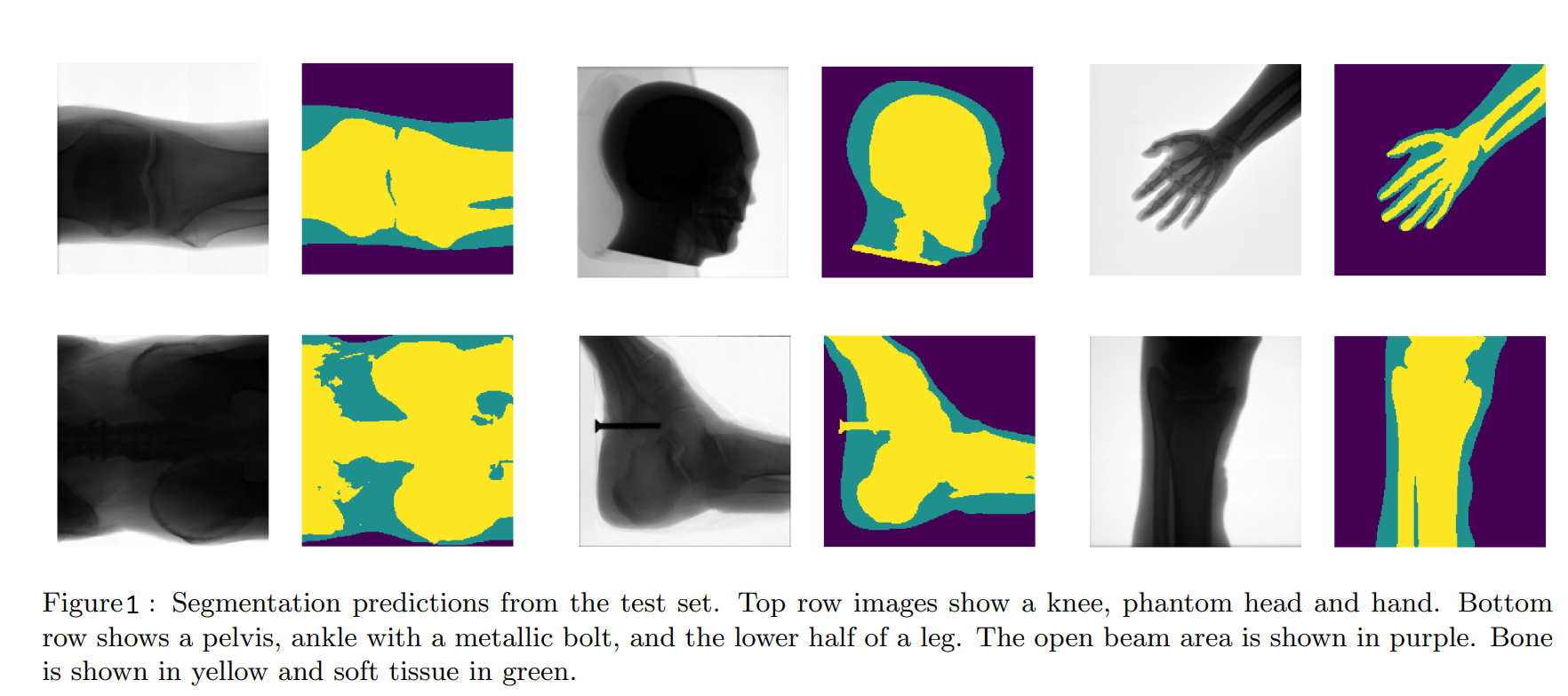
请注意,有几张图片含有外来的金属物体,我们把它们归类为骨头。
有19个不同的身体部位,它们的图片数量如表2所示。
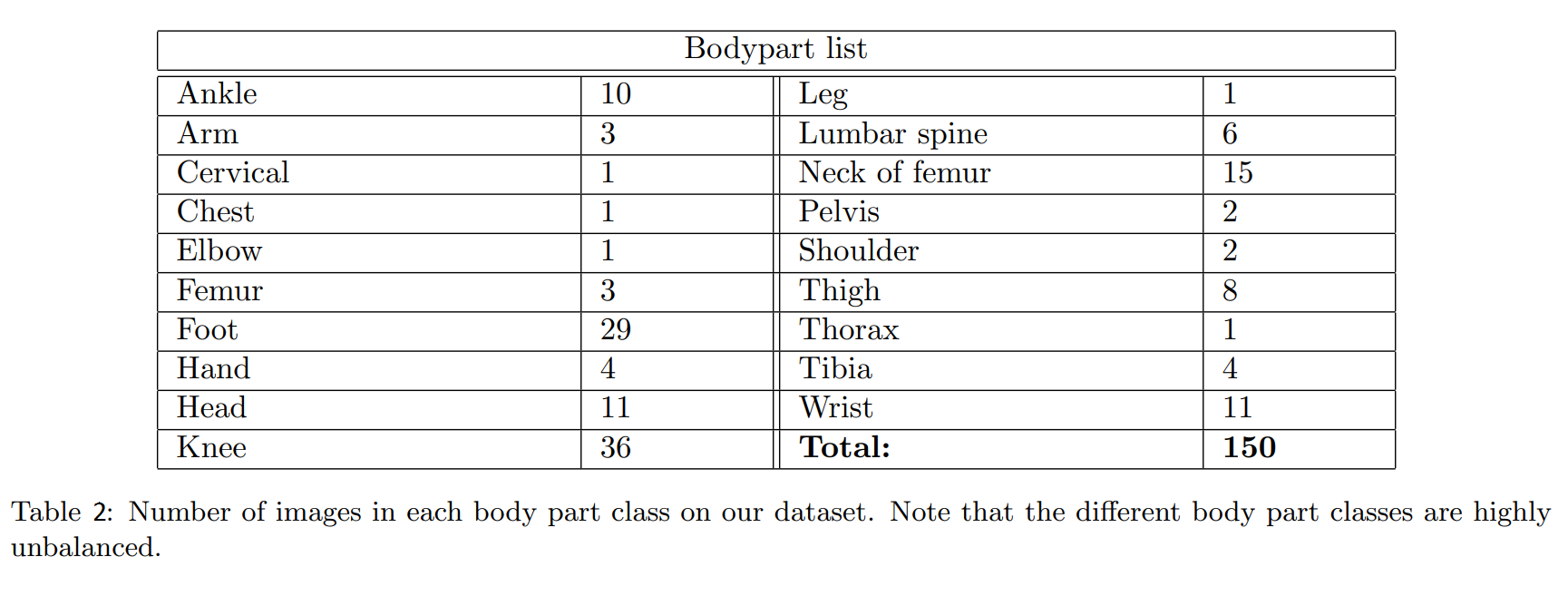
很明显,我们的数据集太小,而且不平衡。如果我们把这个数据集用于像XNet这样的复杂模型,可能会过度拟合。为了避免这种情况,研究人员增加了数据。在试验了各种过滤器后,他们选择了弹性变换,因为它对生成真实的增强图像非常重要,同时还结合了其他变换,如平移、裁剪、旋转和剪切。
这种技术为每个身体部位类别生成了500张图像。因此,总结来说,作者增强数据有两个目的:避免过度拟合和通过超量取样平衡不同的身体部位类别。
结构
XNet的结构由两部分组成:编码器和解码器,见下图。
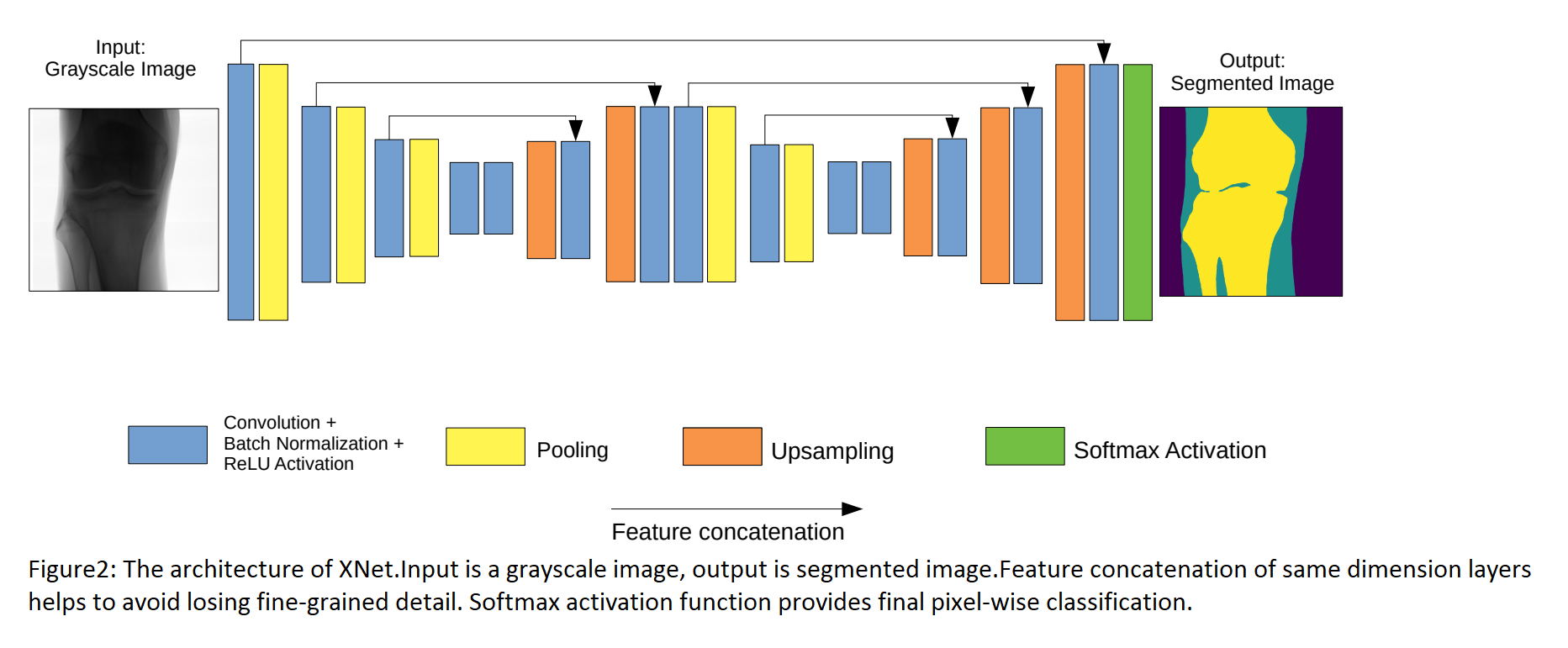
编码器
这个组件主要位于图片的左边。它由许多卷积层和集合层组成。在每个卷积层之后,特征图的数量增加,但它们的大小减少。这些层旨在提取图像的特征。此外,研究人员在多个阶段使用最大集合层进行下采样,这有助于模型在不同层次学习更多的特征。
解码器
解码器的目的是生成一个与输入图像具有相同维度的分割掩码。为了满足这一要求,使用升频过程与卷积层之间的结合。这种技术有助于重建细粒度的特征,从而生成密集的特征图。
解码器的输入是编码器的特征图。让我们退一步来了解解码器是如何使用编码器的特征图的。
在编码器的每个卷积层之后,我们存储特征图。同样,在每一对升频层和卷积层之后,我们得到其他特征图。我们把这两种特征图连接起来(当然它们必须有相同的维度),这意味着模型不太可能忘记它以前学过的东西,也不容易在反向传播过程中出现梯度消失的情况。
再一次,为了避免过度拟合,研究人员采用了L2准则的正则化技术。
校准
在论文中,作者提出了一个名为置信度的指标,以帮助模型避免校准不当,使其对自己的预测过于自信。 XNet的输出是一个3维概率图,其中每个像素被分配到属于我们之前提到的三个不同类别之一的概率。
网络置信度定义为:
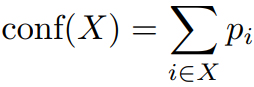
X是分配到一个类别(如骨,软组织)的像素集合,p_i是X中第i个像素属于所述类别的概率。
减少假阳性
作者希望减少软组织的假阳性,也就是说,如果模型将一个像素归类为软组织,我们希望这种情况的概率更高,更不可能是错误的。
结果
由于作者正在寻找减少假阳性和提高真阳性之间的平衡,"准确率 "可能不是一个合适的指标,相反,他们选择了F1得分来衡量网络性能。
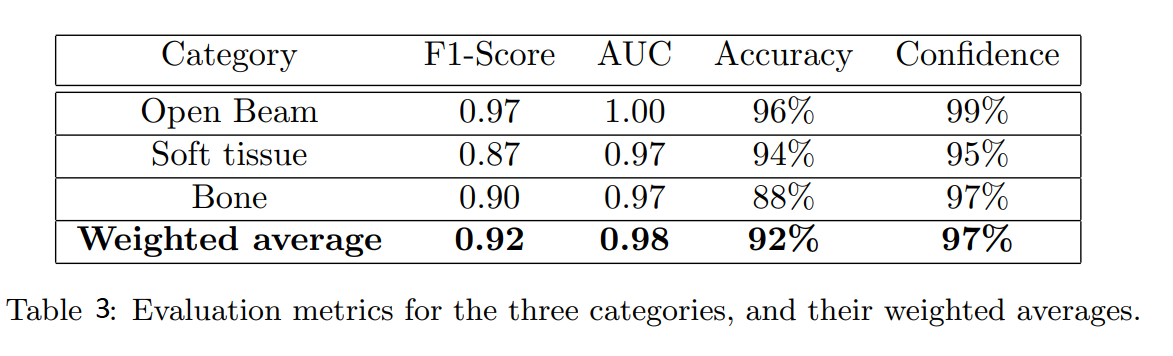
实际上,他们仍然比较了不同指标的网络性能。结果总结在表3中。
结论
XNet被设计成一个端到端的模型,具有一些优势:
- 在一个小的数据集上获得高的准确度并优于其他网络。这有助于医疗机构减少标签的成本,只需要少量的数据,但仍能得到一个好的结果。
- 它经过良好的校准,在不同的指标上进行评估,避免了偏见和过度自信。
- 由于这些优点,XNet有很大的潜力被广泛应用。
