

我们将讨论神经网络中的Delta规则,该规则用于在训练神经网络时更新权重。
目录
- 简介
- 数学定义
- 应用
- 德尔塔规则的推导
简介
delta规则是一个在训练期间更新神经网络权重的公式。它被认为是反向传播算法的一个特例。德尔塔规则实际上是一个梯度下降学习规则。
回顾一下,神经网络的训练过程包括以下步骤的迭代:
- 一组输入和输出样本对被随机选择并通过神经网络运行。该网络对这些样本进行预测。
- 计算出预测值和真实值之间的损失。
- 按照使损失变小的方向调整权重。
德尔塔规则是一种算法,可以在训练过程中反复使用,以修改网络权重来减少损失误差。
数学定义
对于具有激活函数\(g(x)\)的神经网络的第(j)个神经元,更新神经元的第(i)个权重,\(w_{ji}\)的delta规则由以下公式给出。
其中
\(\alpha\)是学习率,
\(g'\)是激活函数\(g\)的导数,
\(t_{j}\)是目标输出。
\h_{j}\)是神经元输入的加权和,即为 \sum x_{i}w_{ji}\),
\(y_{j}\)是预测输出,
\(x_{i}\)是第 i 个输入。
对于具有线性激活函数的神经元来说,激活函数的导数是恒定的,因此这种情况下的德尔塔规则可以简化为:
应用
广义delta规则对于创建能够学习输入和输出之间复杂关系的有用网络非常重要。与其他早期学习规则如Hebbian学习规则或相关学习规则相比,delta规则的优势在于它是由数学推导出来的,直接适用于监督学习。此外,与Perceptron学习规则不同,它依赖于使用Heaviside阶梯函数作为激活函数,这意味着导数在零处不存在,在其他地方等于零,Delta规则适用于可微调的激活函数,如(\tanh\)和sigmoid函数。
让我们考虑Delta规则在神经网络训练步骤的具体应用。对于这个例子,我们定义了神经网络的特征(见下面的图片)。
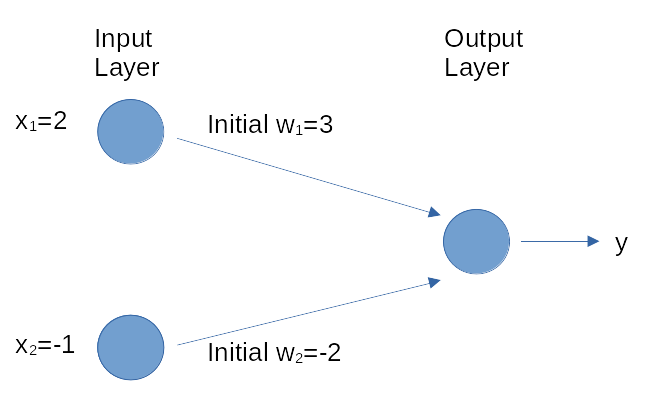
我们假设任务是一个涉及两个特征的二元分类问题,神经网络使用整流线性(ReLU)单元作为激活函数,并具有零偏置。此外,学习率是(0.01\),当前的权重(是一个向量)是((3,-2)\),而下一个训练批次只包括一个输入-输出对(x=(2,-1)\)和目标输出(y=0\)。在样本(x\)上运行神经网络会得到一个预测的输出(y=1\)。网络权重将被更新如下:
数学上,ReLU定义为:\(g(x)=max(x, 0)\)及其导数
$\begin{equation}
g'(x)=
\begin{cases}
1 & \text{if }xgt 0,
0 & \text{otherwise }
end{cases
}
end{equation} $$
New weights = \((3, -2) - (-0.02, 0) = (2.98, -2) \).
德尔塔规则的推导
这个处理方法是按照维基百科上德尔塔规则的推导进行的。德尔塔规则是通过梯度下降试图最小化神经网络的输出误差而得出的。神经网络输出的误差可以测量为:
$ E =\sum_{j}{frac {1}{2}(t_{j}-y_{j})^{2} $$
在这种情况下,我们希望在神经元的 "权重空间"(神经元所有权重的所有可能值的空间)中,按照与每个权重有关的误差函数的梯度比例移动。为了做到这一点,我们计算误差相对于每个权重的偏导。对于第(i)个权重,这个导数可以写为
{frac {partial E}{partial w\_{ji}}.
因为我们只关注第j个神经元,所以我们可以用上面的误差公式代替,同时省略求和。
{\\frac {partial E}{partial w\_{ji}}={frac {partial \\left({1}{2}}\\left(t\_{j}-y\_{j}right)^{2}\\right)}{\\partial w\_{ji}}
接下来我们用连锁规则将其分为两个导数。
{frac {partial \left({\frac {1}{2}}\left(t_{j}-y_{j}\right)^{2}\right)}{partial y_{j}}}{frac {partial y_{j}}{partial w_{ji}} $$
为了找到左导数,我们简单应用链式规则。
=-\\left(t\_{j}-y\_{j}\\right){frac {partial y\_{j}}{partial w\_{ji}}
为了找到右导数,我们再次应用连锁法则,这次是相对于总输入的(j\),(h_{j}\)进行微分。
=-\\left(t\_{j}-y\_{j}\\right){\\frac {partial y\_{j}}{partial h\_{j}}}{\\frac {partial h\_{j}}{partial w\_{ji}}
请注意,第j个神经元的输出,即y_{j}\,只是神经元的激活函数\(g\)应用于神经元的输入h_{j}\。因此,我们可以把y(y_{j}\)相对于h(h_{j}\)的导数简单写成g(g\)的一阶导数。
=-\\left(t\_{j}-y\_{j}\\right)g'(h\_{j}){\\frac {partial h\_{j}}{\\partial w\_{ji}}
接下来我们把最后一项中的h_{j}\改写为所有的k_{k}权重之和,即每个权重(w_{jk}\)乘其相应的输入(x_{k}\) 。
因为我们只关注第i个权重,所以求和中唯一相关的项是(x_{i}w_{ji}\)。很明显。
给我们的梯度的最终方程。
$$\frac {partial E}{partial w_{ji}}=-\left(t_{j}-y_{j}right)g'(h_{j})x_{i} $
如上所述,梯度下降告诉我们,我们对每个权重的改变应该与梯度成正比。选择一个比例常数\(alpha\)并去掉减号,使我们能够在梯度的负方向上移动权重以最小化误差,我们就得到了我们的目标方程式。
