

本文已参与「新人创作礼」活动,一起开启掘金创作之路。
本文首发于CSDN。
诸神缄默不语-个人CSDN博文目录 cs224w(图机器学习)2021冬季课程学习笔记集合
@[toc]
YouTube视频观看地址1 视频观看地址2 视频观看地址3
本章主要内容: 我们的任务是:已知图中一部分节点的标签,用图中节点之间的关系来将标签分配到所有节点上。属于半监督学习任务。 本节课我们学习message passing方法来完成这一任务。对某一节点的标签进行预测,需要其本身特征、邻居的标签和特征。 message passing的假设是图中相似的节点之间会存在链接,也就是相邻节点有标签相同的倾向。这种现象可以用homophily(相似节点倾向于聚集)、influence(关系会影响节点行为)、confounding(环境影响行为和关系)来解释。
collective classification给所有节点同时预测标签的概率分布,基于马尔科夫假设(某一点标签仅取决于其邻居的标签)。 local classifier(用节点特征预测标签)→ relational classifier(用邻居标签 和/或 特征,预测节点标签)→ collective inference(持续迭代)
本节课讲如下三种collective classification的实现技术:
- relational classification:用邻居标签概率的加权平均值来代表节点标签概率,循环迭代求解
- iterative classification:在训练集上训练用 (节点特征) 和 (节点特征,邻居标签summary ) 两种自变量预测标签的分类器 和 ,在测试集上用 赋予初始标签,循环迭代求解 用 重新预测标签
- belief propagation:在边上传递节点对邻居的标签概率的置信度(belief)的message/estimate,迭代计算边上的message,最终得到节点的belief。有环时可能出现问题。
1. Message Passing and Node Classification
- 本章重要问题:给定网络中部分节点的标签,如何用它们来分配整个网络中节点的标签?(举例:已知网络中有一些诈骗网页,有一些可信网页,如何找到其他诈骗和可信的网页节点?)
训练数据中一部分有标签,剩下的没标签,这种就是半监督学习1
对这个问题的一种解决方式:node embeddings2
- 本章我们介绍一个解决上述问题的方法3:message passing
使用message passing基于“网络中存在关系correlations”这一直觉,亦即相似节点间存在链接。
message passing是通过链接传递节点的信息,感觉上会比较类似于 PageRank4 将节点的vote通过链接传递到下一节点,但是在这里我们更新的不再是重要性的分数,而是对节点标签预测的概率。
核心概念 collective classification:同时将标签分配到网络中的所有节点上。
本章将讲述三种实现技术:
- relational classification
- iterative classification
- belief propagation
- 举例:节点分类
半监督学习问题:给出一部分节点的标签(如图中给出了一部分红色节点、一部分绿色节点的标签),预测其他节点的标签
- 网络中存在关系correlations:
相似的行为在网络中会互相关联。
correlation:相近的节点会具有相同标签
- 导致correlation的两种解释5:
homophily(同质性,趋同性,同类相吸原则):个体特征影响社交连接
influence:社交连接影响个体特征
- homophily:相似节点会倾向于交流、关联(物以类聚,人以群分)
在网络研究中得到了大量观察
举例:同领域的研究者更容易建立联系,因为他们参加相同的会议、学术演讲……等活动
Birds of a feather flock together 是句俗语
- homophily举例:一个在线社交网络,以人为节点,友谊为边,通过人们的兴趣将节点分为多类(用颜色区分)。
从图中可以看出,各种颜色都分别聚在一起,亦即有相同兴趣(同色)的人们更有聚集在一起的倾向。
图片出处书籍PDF版下载地址:D Easley, Kleinberg J . Networks, Crowds, and Markets[M]. Cambridge University Press, 2010.
- influence:社交链接会影响个人行为。
举例:用户将喜欢的音乐推荐给朋友。
- homophily:相似节点会倾向于交流、关联(物以类聚,人以群分)
在网络研究中得到了大量观察
举例:同领域的研究者更容易建立联系,因为他们参加相同的会议、学术演讲……等活动
- 既然知道了网络中关系的影响机制,我们就希望能够通过网络中的链接关系来辅助预测节点标签。
如图举例,我们希望根据已知的绿色(label 1)和红色(label 0)节点来预测灰色(标签未知)节点的标签。将各节点从 1-9 标注上node-id。
- 解决分类问题的逻辑:
我们已知相似节点会在网络中更加靠近,或者直接相连。
因此根据关联推定guilt-by-association:如果我与具有标签X的节点相连,那么我也很可能具有标签X(基于马尔科夫假设6)
举例:互联网中的恶意/善意网页:恶意网页往往会互相关联,以增加曝光,使其看起来更可靠,并在搜索引擎中提高排名。
预测节点 的标签需要:
- 的特征
- 邻居的标签
- 邻居的特征
- 半监督学习
- 任务:假设网络中存在homophily,根据一部分已知标签(红/绿)的节点预测剩余节点的标签
- 示例任务:
:n×n的邻接矩阵
:标签向量
目标:预测未知标签节点属于哪一类
- 任务:假设网络中存在homophily,根据一部分已知标签(红/绿)的节点预测剩余节点的标签
- 解决方法:collective classification
- collective classification的应用
- Document classification
- 词性标注Part of speech tagging
- Link prediction
- 光学字符识别Optical character recognition
- Image/3D data segmentation
- 实体解析Entity resolution in sensor networks
- 垃圾邮件Spam and fraud detection
- collective classification概述
直觉:使用网络中的关系同时对相连节点进行分类
概率框架propabilistic framework7
马尔科夫假设8:节点 的标签 取决于其邻居 的标签:
collective classification分成三步:
- local classifier:分配节点的初始标签(基于节点特征建立标准分类,不使用网络结构信息)
- relational classifier:捕获关系(基于邻居节点的标签 和/或 特征,建立预测节点标签的分类器模型)(应用了网络结构信息)
- collective inference:传播关系(在每个节点上迭代relational classifier,直至邻居间标签的不一致最小化。网络结构影响最终预测结果)
- local classifier:分配节点的初始标签(基于节点特征建立标准分类,不使用网络结构信息)
- collective classification的应用
- 问题设置:预测无标签(灰色)节点 的标签 。所有节点 具有特征向量 。部分节点的标签已给出(绿色是1,红色是0)
任务:求解
- 对本章后文内容的概述
2. Relational Classification / Probabilistic Relational Classifier
- 基础思想:节点 的类概率 是其邻居类概率的加权平均值。
对有标签节点 ,固定 为真实标签ground-truth label 。
对无标签节点 ,初始化 。(参考6,也可以用别的prior)
以随机顺序(参考6,不一定要是随机顺序,但实证上发现最好是。这个顺序会影响结果,尤其对小图而言)更新所有无标签节点,直至收敛或到达最大迭代次数
- 更新公式:
邻接矩阵 可以带权
分母是节点 的度数或入度9
是节点 标签为 的概率
问题:- 不一定能收敛
- 模型无法使用节点特征信息
- 举例
- 初始化:迭代顺序就是node-id的顺序。有标签节点赋原标签,无标签节点赋0()
- 第一轮迭代
- 更新节点3
- 更新节点4
- 更新节点5
- 更新完所有无标签节点
- 更新节点3
- 第二轮迭代:结束后发现节点9收敛
- 第三轮迭代:结束后发现节点8收敛
- 第四轮迭代
- 收敛后:预测概率>0.5的节点为1,<0.5的为0
- 初始化:迭代顺序就是node-id的顺序。有标签节点赋原标签,无标签节点赋0()
3. Iterative Classification
- relational classifiers没有使用节点特征信息,所以我们使用新方法iterative classification。
iterative classification主思路:基于节点特征及邻居节点标签对节点进行分类
- iterative classification的方法:训练两个分类器:
基于节点特征向量 预测节点标签
基于节点特征向量 和邻居节点标签summary 预测节点标签
- 计算summary
是个向量,可以是邻居标签的直方图(各标签数目或比例),邻居标签中出现次数最多的标签,邻居标签的类数
- iterative classifier的结构
- 第一步:基于节点特征建立分类器
在训练集上训练如下分类器(可以用线性分类器、神经网络等算法):
- 基于 预测
- 基于 和 ( 邻居标签的summary)预测
- 第二步:迭代至收敛
在测试集上,用 预测标签,根据 计算出的标签计算 并用 预测标签
对每个节点重复迭代计算 、用 预测标签这个过程,直至收敛或到达最大迭代次数(10, 50, 100……这样,不能太多10)
注意:模型不一定能收敛
- 第一步:基于节点特征建立分类器
在训练集上训练如下分类器(可以用线性分类器、神经网络等算法):
- 计算举例:网页分类问题
节点是网页,链接是超链接,链接有向。节点特征简化设置为2维二元向量。预测网页主题。
- 基于节点特征训练分类器():
可以假设分类器以特征第一个元素作为分类标准,于是对中间节点分类错误。
- 根据 得到的结果,计算 。
此处设置 为四维向量,四个元素分别为指向该节点的节点中标签为0和1的数目、该节点指向的节点中标签为0和1的数目。
在这一步应用了网络结构信息。
- 基于节点特征训练分类器():
- 过程举例
- 第一步:在训练集上训练 和
- 第二步:在测试集上预测标签
- 用 预测
- 循环迭代:
- 用 计算
- 用 预测标签
- 迭代直至收敛
- 用 计算
- 结束迭代(收敛或达到最大迭代次数),得到最终预测结果
- 用 预测
- 第一步:在训练集上训练 和
- 对relational classification和iterative classification的总结
4. Loopy Belief Propagation
名字叫loopy是因为loopy BP方法会应用在有很多环的情况下。
- belief propagation是一种动态规划方法,用于回答图中的概率问题(比如节点属于某类的概率)。
邻居节点之间迭代传递信息pass message(如传递相信对方属于某一类的概率),直至达成共识(大家都这么相信),计算最终置信度(也有翻译为信念的)belief。
参考6:问题中节点的状态并不取决于节点本身的belief,而取决于邻居节点的belief。
- message passing
- 例子介绍:
任务:计算图中的节点数(注意,如果图中有环会出现问题,后文会讲有环的情况。在这里不考虑)
限制:每个节点只能与邻居交互(传递信息)
举例:path graph(节点排成一条线) - 算法
- 定义节点顺序(生成一条路径)
- 基于节点顺序生成边方向,从而决定message passing的顺序
- 按节点顺序,计算其对下一节点的信息(至今数到的节点数),将该信息传递到下一节点
- 每个节点接收邻居信息,更新信息,传递信息
- 例子介绍:
任务:计算图中的节点数(注意,如果图中有环会出现问题,后文会讲有环的情况。在这里不考虑)
限制:每个节点只能与邻居交互(传递信息)
- 将path graph的情况泛化到树上:从叶子节点到根节点传递信息
在树结构上更新置信度:
- Loopy BP Algorithm
从 传递给 的信息,取决于 从邻居处接收的信息。每个邻居给 对其状态的置信度的信息。
- notation11
- label-label potential matrix :节点及其邻居间的dependency :节点 是节点 的邻居,已知 属于类 , 与 属于类 的概率成比例。
- prior belief : 与节点 属于类 的概率成比例。
- : 对 属于类 的message/estimate
- :所有类/标签的集合
- Loopy BP Algorithm
- 将所有信息初始化为1
- 对每个节点重复:
蓝框里面那个反斜杠指除了j
- 收敛后,计算 节点 属于类 的置信度
- 示例
- 现在我们考虑图中有环的情况,节点没有顺序了。我们采用上述算法,从随机节点开始,沿边更新邻居节点。
- 由于图中有环,来自各子图的信息就不独立了。信息会在圈子里加强(就像PageRank里的spider trap)
- 现在我们考虑图中有环的情况,节点没有顺序了。我们采用上述算法,从随机节点开始,沿边更新邻居节点。
- 可能出现的问题:置信度不收敛(如图,信息在环里被加强了)
但是由于现实世界的真实复杂图会更像树,就算有环也会有弱连接,所以还是能用Loopy BP
heuristic启发式的
- 置信度传播方法的特点
5. 本章总结
- 学习了如何利用图中的关系来对节点做预测
- 主要技术:
- relational classification
- iterative classification
- loopy belief propagation
6. 其他文中未提及的参考资料
- cs224w 图神经网络 学习笔记(七)Message Passing and Node Classification 信息传播与节点分类_喵木木的博客-CSDN博客 这篇是19年秋版cs224w的笔记
- CS224W 图机器学习 自学笔记7 - Node Classification - 知乎 同上
Footnotes
-
显然这是个非常简单粗暴的不严格定义。 我没有详细了解过半监督学习,谷歌了一下感觉如果有需可以参考一下这篇知乎文章:半监督深度学习小结 ↩
-
节点嵌入相关的知识可参考我之前写的Lecture 3笔记:cs224w(图机器学习)2021冬季课程学习笔记3: Node Embeddings 但是我其实没搞懂为什么说节点嵌入可以解决这个……半监督学习问题?这里的意思是说节点嵌入将节点表示为结构化向量,然后用结构化的半监督学习模型来解决这个问题吗?此外我上网查了一下,还看到有说node2vec是一种半监督学习的算法(它不是没标签吗,谁监督的啊?)…… ↩
-
PPT中说message passing是一个alternative framework。 alternative framework是什么玩意?我本来还以为只是字面解释,百度了一下发现这是个叫什么相异构想的学术概念,是教育理论上把学生由感性认识得出的偏离科学现象本质和科学概念的理解与想法(相异构想_百度百科)…… 什么玩意儿? 为便理解,我就认为是说message passing是解决该半监督学习问题的一种方法了。 ↩
-
PageRank相关的知识可参考我之前写的Lecture 4笔记:cs224w(图机器学习)2021冬季课程学习笔记4 Link Analysis: PageRank (Graph as Matrix) ↩
-
参考6,除homophily和influence外还有confounding
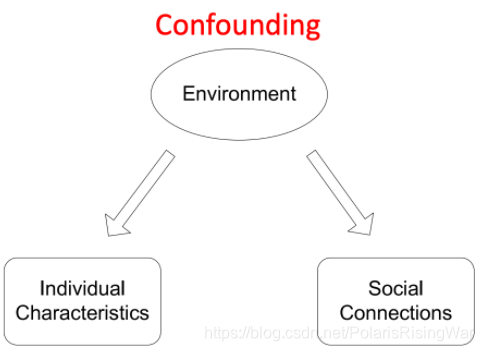 节点展现出相似性。例如环境影响我们的很多维度,说什么语言、听什么歌、有什么政治倾向等。 ↩
节点展现出相似性。例如环境影响我们的很多维度,说什么语言、听什么歌、有什么政治倾向等。 ↩ -
官方课程笔记本章部分:Message Passing and Node Classification ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
这又是什么玩意儿啊……反正我的理解就是,collective classification也是算的某一节点属于某一类的概率。 看到知乎上有篇文章,放了很多论文,显然我还没看,放这以供参考:机器学习中的概率框架 ↩
-
马尔科夫假设,我看了一下,好像大意是认为下一时间的概率只受上一时间的状态影响。然后根据这一点可以写出状态转移矩阵A()。 别的还没研究。反正在本课程中直接理解正文那个公式就够用的了,再看别的,未免太为难我小小的脑瓜了。 参考资料(虽然说是参考资料但是我完全没有看懂。哎这已经是我的日常了,我什么时候才能变成文献吞吐如流水的大佬呀!): ①理解Markov假设 - ybdesire - 博客园 ②条件独立 - 维基百科,自由的百科全书 ③MarkovModels马尔科夫模型读书笔记_辛明辉的专栏-CSDN博客 ④Markov property - Wikipedia ⑤Causal Markov condition - Wikipedia ↩
-
这部分是这样的,如果是无向图就没什么问题,但是如果是有向图!这个公式不就是聚合以 为source的邻居吗?那这个分母应该是 的出度啊…… 但问题在于既然是聚合邻居节点信息,那就不应该只考虑出度或者入度啊,又不像PageRank说明了就是算指向节点的邻居的vote。这部分我简单谷歌了一下,没找到。反正本文给的例子是无向图的,以后如有需要再仔细看吧…… 参考资料: Wang, Xi & Sukthankar, Gita. (2013). Multi-label relational neighbor classification using social context features. 464-472. 10.1145/2487575.2487610. 上一论文的KDD PPT:2013 KDD conference presentation--"Multi-Label Relational Neighbor Cl… ↩
-
没说为啥迭代次数不能太多,我也不知道为啥 ↩
-
对于这些东西是怎么来的,是来干啥的,还有底下那个Loopy BP的迭代公式,具体是怎么回事,我还没搞懂…… ↩
