

有用的内置Node.js APIs
我们编制了一个清单,列出了标准Node.js运行时内置的最常用和最有用的API。对于每个模块,你会发现简单的英文解释和例子来帮助你理解。
本指南改编自我的课程**Node.js: Novice to Ninja**。请看那里的综合课程,以建立你自己的多用户实时聊天应用程序。它还包括测验、视频、运行你自己的docker容器的代码。
当建立你的第一个Node.js应用程序时,了解node提供的实用程序和API对满足常见的使用情况和开发需求很有帮助。
有用的Node.js APIs
- 过程:检索环境变量、args、CPU使用率和报告等信息。
- 操作系统:检索Node正在运行的操作系统和系统相关信息。CPU、操作系统版本、主目录等。
- 利用:一组有用的和常见的方法,帮助解码文本、类型检查和比较对象。
- URL:轻松地创建和解析URL。
- 文件系统API:与文件系统互动,创建、读取、更新和删除文件、目录和权限。
- 事件:用于在Node.js中发射和订阅事件。与客户端事件监听器的工作原理类似。
- 流:用于在更小和更容易管理的块中处理大量的数据,以避免内存问题。
- 工作线程:用于在不同的线程上分离函数的执行,以避免瓶颈。对于CPU密集型的JavaScript操作很有用。
- 子进程:允许你运行子进程,你可以监测并在必要时终止子进程。
- 集群:允许你在各核心之间分叉任何数量的相同的进程,以更有效地处理负载。
进程
process 对象提供关于你的Node.js应用程序的信息以及控制方法。使用它可以获得环境变量以及CPU和内存使用情况等信息。process 是全局可用的:你可以在没有import 的情况下使用它,尽管Node.js文档建议你明确引用它。
import process from 'process';
process.argv返回一个数组,前两项是Node.js可执行路径和脚本名称。索引2的项目是传递的第一个参数。process.env:返回一个包含环境名称/值对的对象--例如process.env.NODE_ENV。process.cwd():返回当前工作目录。process.platform:返回一个识别操作系统的字符串。'aix','darwin'(macOS),'freebsd','linux','openbsd','sunos', 或'win32'(Windows)。process.uptime(): 返回Node.js进程已经运行的秒数。process.cpuUsage(): 返回当前进程的用户和系统CPU时间的使用情况--如{ user: 12345, system: 9876 }。将该对象传回给该方法,以获得一个相对的读数。process.memoryUsage(): 返回一个描述内存使用情况的对象,单位为字节。process.version:返回Node.js版本字符串--如18.0.0。process.report:生成一个诊断报告。process.exit(code):退出当前应用程序。使用退出代码0来表示成功,或者在必要时使用适当的错误代码。
OS
os API与process (见上面的 "进程 "部分)有相似之处,但它也可以返回Node.js运行的操作系统的信息。这提供了诸如什么操作系统版本、CPU和运行时间等信息。
os.cpus():返回一个包含每个逻辑CPU核信息的对象数组。下面的 "集群 "部分引用os.cpus()来分叉进程。在一个16核的CPU上,你会有16个Node.js应用程序的实例运行以提高性能。os.hostname():操作系统的主机名。os.version(): 一个识别操作系统内核版本的字符串。os.homedir(): 用户的主目录的完整路径。os.tmpdir():操作系统的默认临时文件目录的完整路径。os.uptime():操作系统已经运行的秒数。
利用
util 模块提供了各种各样的有用的JavaScript方法。其中最有用的一个是 util.promisify(function),它接收一个错误优先的回调函数并返回一个基于承诺的函数。Util模块还可以帮助处理一些常见的模式,如解码文本、类型检查和检查对象。
util.callbackify(function): 接收一个返回承诺的函数,并返回一个基于回调的函数。util.isDeepStrictEqual(object1, object2): 当两个对象之间存在深度相等时返回true(所有子属性必须匹配)。util.format(format, [args]):使用类似 printf 的格式返回一个字符串。util.inspect(object, options):返回一个对象的字符串表示,用于调试。这类似于使用console.dir(object, { depth: null, color: true });。util.stripVTControlCharacters(str):从字符串中剥离ANSI转义代码。util.types为常见的JavaScript和Node.js值提供类型检查。比如说。
import util from 'util';
util.types.isDate( new Date() ); // true
util.types.isMap( new Map() ); // true
util.types.isRegExp( /abc/ ); // true
util.types.isAsyncFunction( async () => {} ); // true
URL
URL是另一个全局对象,让你安全地创建、解析和修改网络URL。它对快速从URL中提取协议、端口、参数和哈希值非常有用,而不需要求助于重合码。比如说。
{
href: 'https://example.org:8000/path/?abc=123#target',
origin: 'https://example.org:8000',
protocol: 'https:',
username: '',
password: '',
host: 'example.org:8000',
hostname: 'example.org',
port: '8000',
pathname: '/path/',
search: '?abc=123',
searchParams: URLSearchParams { 'abc' => '123' },
hash: '#target'
}
你可以查看和改变任何属性。比如说。
myURL.port = 8001;
console.log( myURL.href );
// https://example.org:8001/path/?abc=123#target
然后你可以使用URLSearchParams API来修改查询字符串值。例如:你可以使用 API来修改查询字符串的值。
myURL.searchParams.delete('abc');
myURL.searchParams.append('xyz', 987);
console.log( myURL.search );
// ?xyz=987
还有一些方法可以将文件系统路径转换为URL,然后再转换回来。
dns 模块提供名称解析功能,因此你可以查询IP地址、名称服务器、TXT记录和其他域名信息。
文件系统API
fs API可以创建、读取、更新和删除文件、目录和权限。最近发布的Node.js运行时在fs/promises ,提供了基于承诺的函数,这使得管理异步文件操作变得更加容易。
你经常使用fs ,并与 path来解决不同操作系统上的文件名。
下面的示例模块使用 stat和 access方法返回一个文件系统对象的信息。
// fetch file information
import { constants as fsConstants } from 'fs';
import { access, stat } from 'fs/promises';
export async function getFileInfo(file) {
const fileInfo = {};
try {
const info = await stat(file);
fileInfo.isFile = info.isFile();
fileInfo.isDir = info.isDirectory();
}
catch (e) {
return { new: true };
}
try {
await access(file, fsConstants.R_OK);
fileInfo.canRead = true;
}
catch (e) {}
try {
await access(file, fsConstants.W_OK);
fileInfo.canWrite = true;
}
catch (e) {}
return fileInfo;
}
当传递一个文件名时,该函数返回一个包含该文件信息的对象。比如说。
{
isFile: true,
isDir: false,
canRead: true,
canWrite: true
}
主filecompress.js 脚本使用path.resolve() ,将命令行上传递的输入和输出文件名解析为绝对文件路径,然后使用上面的getFileInfo() 获取信息。
#!/usr/bin/env node
import path from 'path';
import { readFile, writeFile } from 'fs/promises';
import { getFileInfo } from './lib/fileinfo.js';
// check files
let
input = path.resolve(process.argv[2] || ''),
output = path.resolve(process.argv[3] || ''),
[ inputInfo, outputInfo ] = await Promise.all([ getFileInfo(input), getFileInfo(output) ]),
error = [];
代码对路径进行验证,必要时以错误信息终止。
// use input file name when output is a directory
if (outputInfo.isDir && outputInfo.canWrite && inputInfo.isFile) {
output = path.resolve(output, path.basename(input));
}
// check for errors
if (!inputInfo.isFile || !inputInfo.canRead) error.push(`cannot read input file ${ input }`);
if (input === output) error.push('input and output files cannot be the same');
if (error.length) {
console.log('Usage: ./filecompress.js [input file] [output file|dir]');
console.error('\n ' + error.join('\n '));
process.exit(1);
}
然后,整个文件被读入一个名为content 的字符串,使用 readFile():
// read file
console.log(`processing ${ input }`);
let content;
try {
content = await readFile(input, { encoding: 'utf8' });
}
catch (e) {
console.log(e);
process.exit(1);
}
let lengthOrig = content.length;
console.log(`file size ${ lengthOrig }`);
JavaScript正则表达式然后删除注释和空白。
// compress content
content = content
.replace(/\n\s+/g, '\n') // trim leading space from lines
.replace(/\/\/.*?\n/g, '') // remove inline // comments
.replace(/\s+/g, ' ') // remove whitespace
.replace(/\/\*.*?\*\//g, '') // remove /* comments */
.replace(/<!--.*?-->/g, '') // remove <!-- comments -->
.replace(/\s*([<>(){}}[\]])\s*/g, '$1') // remove space around brackets
.trim();
let lengthNew = content.length;
结果字符串被输出到一个文件中,使用 writeFile()的方式输出到文件中,并有一条状态信息显示保存情况。
let lengthNew = content.length;
// write file
console.log(`outputting ${output}`);
console.log(`file size ${ lengthNew } - saved ${ Math.round((lengthOrig - lengthNew) / lengthOrig * 100) }%`);
try {
content = await writeFile(output, content);
}
catch (e) {
console.log(e);
process.exit(1);
}
用一个例子的HTML文件运行项目代码。
node filecompress.js ./test/example.html ./test/output.html
事件
你经常需要在事情发生时执行多个函数。例如,一个用户在你的应用程序上注册,所以代码必须将他们的详细资料添加到数据库中,开始一个新的登录会话,并发送一封欢迎邮件。事件模块。
// example pseudo code
async function userRegister(name, email, password) {
try {
await dbAddUser(name, email, password);
await new UserSession(email);
await emailRegister(name, email);
}
catch (e) {
// handle error
}
}
这一系列的函数调用是与用户注册紧密相连的。进一步的活动会引起进一步的函数调用。比如说。
// updated pseudo code
try {
await dbAddUser(name, email, password);
await new UserSession(email);
await emailRegister(name, email);
await crmRegister(name, email); // register on customer system
await emailSales(name, email); // alert sales team
}
你可以在这个单一的、不断增长的代码块中管理几十个调用。
Node.jsEvents API提供了一种替代方式,使用发布-订阅模式来结构代码。userRegister() 函数可以在用户的数据库记录被创建后发出一个事件--也许名为newuser 。
任何数量的事件处理函数都可以订阅并对newuser 事件作出反应;不需要改变userRegister() 函数。每个处理程序都是独立运行的,所以它们可以按任何顺序执行。
客户端JavaScript中的事件
事件和处理函数在客户端JavaScript中经常被使用--例如,当用户点击一个元素时运行一个函数。
// client-side JS click handler
document.getElementById('myelement').addEventListener('click', e => {
// output information about the event
console.dir(e);
});
在大多数情况下,你要为用户或浏览器事件附加处理程序,尽管你可以提出你自己的自定义事件。Node.js的事件处理在概念上是相似的,但API是不同的。
发出事件的对象必须是Node.jsEventEmitter 类的实例。这些对象有一个 emit()方法来引发新的事件,还有一个on() 方法来附加处理程序。
事件示例项目提供了一个类,可以在预定的时间间隔内触发tick 事件。./lib/ticker.js 模块导出一个default class ,extends EventEmitter 。
// emits a 'tick' event every interval
import EventEmitter from 'events';
import { setInterval, clearInterval } from 'timers';
export default class extends EventEmitter {
它的constructor 必须调用父级构造函数。然后它将delay 参数传递给一个start() 方法。
constructor(delay) {
super();
this.start(delay);
}
start() 方法检查延迟是否有效,必要时重置当前的定时器,并设置新的delay 属性。
start(delay) {
if (!delay || delay == this.delay) return;
if (this.interval) {
clearInterval(this.interval);
}
this.delay = delay;
然后它启动一个新的间隔定时器,运行emit() 方法,事件名称为"tick" 。该事件的订阅者会收到一个带有延迟值和Node.js应用程序启动后的秒数的对象:C
// start timer
this.interval = setInterval(() => {
// raise event
this.emit('tick', {
delay: this.delay,
time: performance.now()
});
}, this.delay);
}
}
主event.js 入口脚本导入了该模块,并设置了一个delay ,周期为一秒(1000 milliseconds):Copy
// create a ticker
import Ticker from './lib/ticker.js';
// trigger a new event every second
const ticker = new Ticker(1000);
它附加了每次tick 事件发生时触发的处理函数。
// add handler
ticker.on('tick', e => {
console.log('handler 1 tick!', e);
});
// add handler
ticker.on('tick', e => {
console.log('handler 2 tick!', e);
});
第三个处理程序只在第一个tick 事件上触发,使用的是 once()方法触发第一个事件。
// add handler
ticker.once('tick', e => {
console.log('handler 3 tick!', e);
});
最后,输出当前听众的数量。
// show number of listenersconsole.log(`listeners: ${ // show number of listeners
console.log(`listeners: ${ ticker.listenerCount('tick') }`);
用node event.js ,运行项目代码。
输出显示处理程序3触发一次,而处理程序1和2在每一个tick ,直到应用程序被终止。
流
上面的文件系统示例代码(在 "文件系统 "部分)在输出最小化的结果之前将整个文件读入内存。如果该文件大于可用的RAM怎么办?Node.js应用程序将以 "内存不足 "的错误失败。
解决方案是流式处理。它以更小、更容易管理的块来处理传入的数据。一个流可以是。
- 可读:从一个文件、一个HTTP请求、一个TCP套接字、stdin等。
- 可写:对文件、HTTP响应、TCP套接字、stdout等。
- 双工:一个既可读又可写的流
- 转换:一个对数据进行转换的双工流
每个数据块都会以Buffer 对象的形式返回,它代表一个固定长度的字节序列。你可能需要将其转换为字符串或其他适当的类型进行处理。
示例代码中有一个filestream 项目,它使用一个转换流来解决filecompress 项目中的文件大小问题。和以前一样,在声明一个Compress 类之前,它接受并验证了input 和output 文件名,该类扩展了 Transform:
import { createReadStream, createWriteStream } from 'fs';
import { Transform } from 'stream';
// compression Transform
class Compress extends Transform {
constructor(opts) {
super(opts);
this.chunks = 0;
this.lengthOrig = 0;
this.lengthNew = 0;
}
_transform(chunk, encoding, callback) {
const
data = chunk.toString(), // buffer to string
content = data
.replace(/\n\s+/g, '\n') // trim leading spaces
.replace(/\/\/.*?\n/g, '') // remove // comments
.replace(/\s+/g, ' ') // remove whitespace
.replace(/\/\*.*?\*\//g, '') // remove /* comments */
.replace(/<!--.*?-->/g, '') // remove <!-- comments -->
.replace(/\s*([<>(){}}[\]])\s*/g, '$1') // remove bracket spaces
.trim();
this.chunks++;
this.lengthOrig += data.length;
this.lengthNew += content.length;
this.push( content );
callback();
}
}
当一个新的chunk 的数据准备好时,_transform 方法被调用。它作为一个Buffer 对象被接收,该对象被转换为字符串,被最小化,并使用push() 方法输出。一旦分块处理完成,就会调用一个callback() 函数。
应用程序启动文件读和写流,并实例化一个新的compress 对象。
// process streamconst readStream = createReadStream(input), wr// process stream
const
readStream = createReadStream(input),
writeStream = createWriteStream(output),
compress = new Compress();
console.log(`processing ${ input }`)
传入的文件读取流定义了.pipe() 方法,这些方法通过一系列可能(或可能不)改变内容的函数将传入的数据送入。在输出到可写文件之前,数据通过compress 变换的管道。一旦数据流结束,最后一个on('finish') 事件处理函数就会执行。
readStream.pipe(compress).pipe(writeStream).on('finish', () => {
console.log(`file size ${ compress.lengthOrig }`); console.log(`output ${ output }`); console.log(`chunks readStream.pipe(compress).pipe(writeStream).on('finish', () => {
console.log(`file size ${ compress.lengthOrig }`);
console.log(`output ${ output }`);
console.log(`chunks ${ compress.chunks }`);
console.log(`file size ${ compress.lengthNew } - saved ${ Math.round((compress.lengthOrig - compress.lengthNew) / compress.lengthOrig * 100) }%`);
});
用一个任何大小的HTML文件的例子运行项目代码。
node filestream.js ./test/example.html ./test/output.html
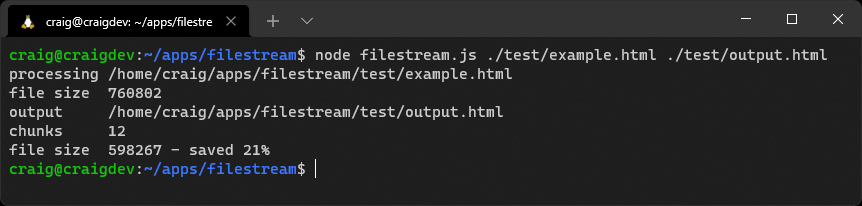
这是对Node.js流的一个小演示。流处理是一个复杂的话题,你可能不会经常使用它们。在某些情况下,像Express这样的模块在引擎盖下使用流,但对你的复杂性进行了抽象。
你还应该注意到数据分块的挑战。一个分块可能是任何大小,并以不方便的方式分割传入的数据。考虑将这段代码最小化。
<script type="module">
// example script
console.log('loaded');
</script>
两个分块可能依次到达。
<script type="module">
// example
和。
<script>
console.log('loaded');
</script>
独立处理每个分块的结果是以下无效的最小化脚本。
<script type="module">script console.log('loaded');</script>
解决办法是预先解析每个块,并将其分割成可以处理的整个部分。在某些情况下,块(或块的一部分)会被添加到下一个块的开始。
最小化最好应用于整行,尽管会出现一个额外的复杂情况,因为<!-- --> 和/* */ 注释可以跨越不止一行。下面是对每个传入块的可能算法。
- 将前一个块中保存的任何数据追加到新块的开头。
- 从该块中删除任何完整的
<!--到-->和/*到*/部分。 - 将剩余的块分成两部分,其中
part2以发现的第一个<!--或/*开始。如果两者都存在,则从part2中删除除该符号以外的其他内容。如果两者都没有找到,则在最后一个回车字符处分割。如果没有找到,将part1设为空字符串,将part2设为整个块。如果part2变得非常大--也许超过100,000个字符,因为没有回车符--将part2添加到part1,将part2设为空字符串。这将确保保存的部分不能无限地增长。 - 缩小并输出
part1。 - 保存
part2(它被添加到下一个分块的开始)。
这个过程对每个传入的分块都会再次运行。
这就是你的下一个编码挑战--如果你愿意接受它的话!
工作线程
来自文档。"工人(线程)对于执行CPU密集型的JavaScript操作很有用。它们对I/O密集型的工作帮助不大。Node.js内置的异步I/O操作比Worker更有效"。
假设一个用户可以在你的Express应用程序中触发一个复杂的、十秒钟的JavaScript计算。该计算将成为一个瓶颈,使所有用户的处理都停止了。你的应用程序不能处理任何请求或运行其他功能,直到它完成。
异步计算
处理来自文件或数据库的数据的复杂计算可能问题不大,因为每个阶段在等待数据到达时都是异步运行。处理发生在事件循环的单独迭代中。
然而,仅用JavaScript编写的长期运行的计算,如图像处理或机器学习算法,将占用事件循环的当前迭代。
一个解决方案是工作线程。这些线程类似于浏览器的网络工作者,在一个单独的线程上启动一个JavaScript进程。主线程和工作线程可以交换消息以触发或终止处理。
工作者和事件循环
工作者对于CPU密集型的JavaScript操作非常有用,尽管Node.js的主事件循环仍应用于异步I/O活动。
示例代码中有一个worker 项目,在lib/dice.js 中导出一个diceRun() 函数。这将任意数量的N面骰子抛出若干次,并记录总分的计数(应该会产生一个正态分布曲线)。
// dice throwing
export function diceRun(runs = 1, dice = 2, sides = 6) {
const stat = [];
while (runs > 0) {
let sum = 0;
for (let d = dice; d > 0; d--) {
sum += Math.floor( Math.random() * sides ) + 1;
}
stat[sum] = (stat[sum] || 0) + 1;
runs--;
}
return stat;
}
index.js 中的代码启动一个进程,每秒钟运行一次,并输出一条信息。
// run process every second
const timer = setInterval(() => {
console.log(' another process');
}, 1000);
然后使用diceRun() 函数的标准调用,将两个骰子投掷10亿次。
import { diceRun } from './lib/dice.js';
// throw 2 dice 1 billion times
const
numberOfDice = 2,
runs = 999_999_999;
const stat1 = diceRun(runs, numberOfDice);
这就停止了计时器,因为在计算完成之前,Node.js的事件循环不能继续进行下一次迭代。
然后代码尝试在一个新的 Worker.这将加载一个名为worker.js 的脚本,并在选项对象的workerData 属性中传递计算参数。
import { Worker } from 'worker_threads';
const worker = new Worker('./worker.js', { workerData: { runs, numberOfDice } });
事件处理程序被附加到运行worker.js 脚本的worker 对象上,这样它就可以接收传入的结果。
// result returned
worker.on('message', result => {
console.table(result);
});
...并处理错误。
// worker error
worker.on('error', e => {
console.log(e);
});
...并在处理完成后进行整理。
// worker complete
worker.on('exit', code => {
// tidy up
});
worker.js 脚本开始进行diceRun() 计算,并在计算完成后向父对象发布一条消息--该消息由上面的"message" 处理程序接收。
// worker threadimport { workerData, parentPort } from 'worker_threads';import { diceRun } from './lib/dice.js';
// worker thread
import { workerData, parentPort } from 'worker_threads';
import { diceRun } from './lib/dice.js';
// start calculation
const stat = diceRun( workerData.runs, workerData.numberOfDice );
// post message to parent script
parentPort.postMessage( stat );
在Worker运行时,计时器并没有暂停,因为它是在另一个CPU线程上执行的。换句话说,Node.js的事件循环继续迭代,不会出现长时间的延迟。
用node index.js 运行项目代码。
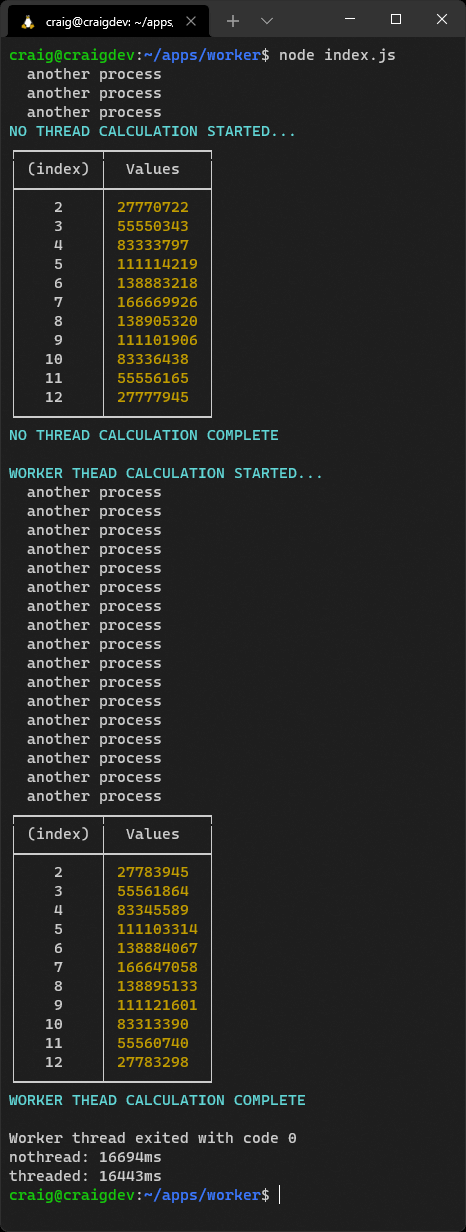
你应该注意到,基于工作者的计算运行速度略快,因为线程完全致力于该进程。如果你在应用中遇到性能瓶颈,可以考虑使用工作者。
子进程
有时需要调用那些不是用Node.js编写的或者有失败风险的应用程序。
一个真实世界的例子
我曾在一个Express应用程序上工作,它生成了一个模糊的图像哈希,用于识别类似的图形。它以异步方式运行,并且运行良好,直到有人上传了一个包含循环参考的畸形GIF(动画帧A参考了帧B,而帧B参考了帧A)。
哈希值的计算从未结束。该用户放弃了,并尝试再次上传。又一次。一次又一次。整个应用程序最终因内存错误而崩溃。
这个问题通过在一个子进程中运行散列算法得到了解决。Express应用程序保持稳定,因为它启动、监控并在计算时间过长时终止了计算。
子进程API允许你运行子进程,你可以监控并在必要时终止子进程。有三个选项。
与工作线程不同,子进程是独立于主Node.js脚本的,不能访问相同的内存。
集群
当你的Node.js应用程序在单核上运行时,你的64核服务器CPU是否没有得到充分利用?**集群**允许你分叉任何数量的相同进程来更有效地处理负载。
最初的主进程可以分叉自己--也许是为每个由.NET返回的CPU分叉一次。 os.cpus().当一个进程失败时,它也可以处理重启,并在分叉的进程之间代理通信信息。
集群工作得非常好,但你的代码可能会变得复杂。更简单和更强大的选择包括:
- 进程管理器,如PM2,它提供了一个自动集群模式
- 容器管理系统,如Docker或Kubernetes
两者都可以启动、监控和重启同一Node.js应用程序的多个隔离实例。即使有一个失败了,应用程序也会保持活跃。
编写无状态应用程序
值得一提的是:让你的应用程序无状态,以确保它可以扩展并更有弹性。应该可以启动任何数量的实例并分担处理负载。
总结
本文提供了一个比较有用的Node.js API的例子,但我鼓励你浏览文档,自己去发现它们。文档总体上是好的,并展示了简单的例子,但有些地方可能很简练。
